




即使您在强大的基础架构上采用最快的数据库,除非您正确地进行数据建模,否则您将无法充分挖掘其潜力。
数据建模错误是破坏性能的最简单方法之一。当你使用NoSQL时,特别容易搞砸它,具有讽刺意味的是,NoSQL往往用于对性能最敏感的工作负载。NoSQL 数据建模最初可能看起来很简单:只需对数据进行建模以适应应用程序的访问模式即可。但在实践中,这说起来容易做起来难。
修复数据建模并不好玩,但它通常是一种必要的邪恶。如果数据建模从根本上是低效的,那么一旦扩展到某个临界点,性能就会受到影响,而临界点会因特定的工作负载和部署而异。即使您在最强大的基础架构上采用最快的数据库,除非您正确地进行数据建模,否则您将无法充分挖掘其潜力。
本文探讨了破坏 NoSQL 数据库性能的三种最常见方法,以及如何避免或解决这些方法的提示。
不寻址大型分区
当团队扩展其分布式数据库时,通常会出现大型分区。大型分区是当它们开始在群集的副本中引入性能问题时,它们会变得太大的分区。
我们经常听到的问题之一——至少每个月一次——是,“什么是大分区?嗯,这要看情况。需要考虑的一些事项:
- 延迟预期: 分区越大,检索所需的时间就越长。考虑页面大小和完全扫描分区所需的客户端-服务器往返次数。
- 平均有效载荷大小:负载越大,通常会导致延迟越高。它们需要更多的服务器端处理时间进行序列化和反序列化,并且还会产生更高的网络数据传输开销。
- 工作负载需求:某些工作负载有机地需要比其他工作负载更大的有效负载。例如,我曾与一家 Web3 区块链公司合作,该公司将多个交易存储为单个密钥下的 BLOB,每个密钥的大小都可以轻松超过 1 兆字节。
- 如何从这些分区中读取: 例如,时间序列用例通常具有时间戳聚类组件。在这种情况下,从特定时间窗口读取将比扫描整个分区检索的数据少得多。
下表说明了不同有效负载大小(如 1、2 和 4 KB)下大型分区的影响。
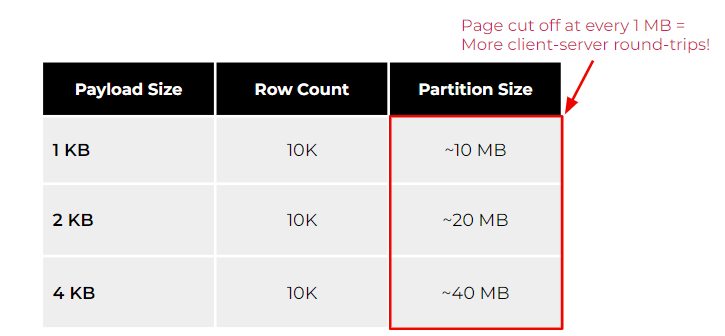
正如你所看到的,在相同的行数下,你的有效负载越高,你的分区就越大。但是,如果您的用例经常需要将分区作为一个整体进行扫描,请注意,数据库具有防止无限内存消耗的限制。例如,ScyllaDB 每隔 1MB 就会切断页面,以防止系统可能耗尽内存。其他数据库(甚至是关系数据库)具有类似的保护机制,以防止无限的错误查询使数据库资源匮乏。要使用 ScyllaDB 检索 4KB 和 10K 行的有效负载大小,您需要检索至少 40 个页面才能使用单个查询扫描分区。乍一看,这似乎没什么大不了的。但是,随着时间推移而扩展,它可能会影响整体客户端尾部延迟。
另一个考虑因素:对于像 ScyllaDB 和 Cassandra 这样的数据库,写入数据库的数据存储在提交日志中,并存储在称为“memtable”的内存中数据结构下。
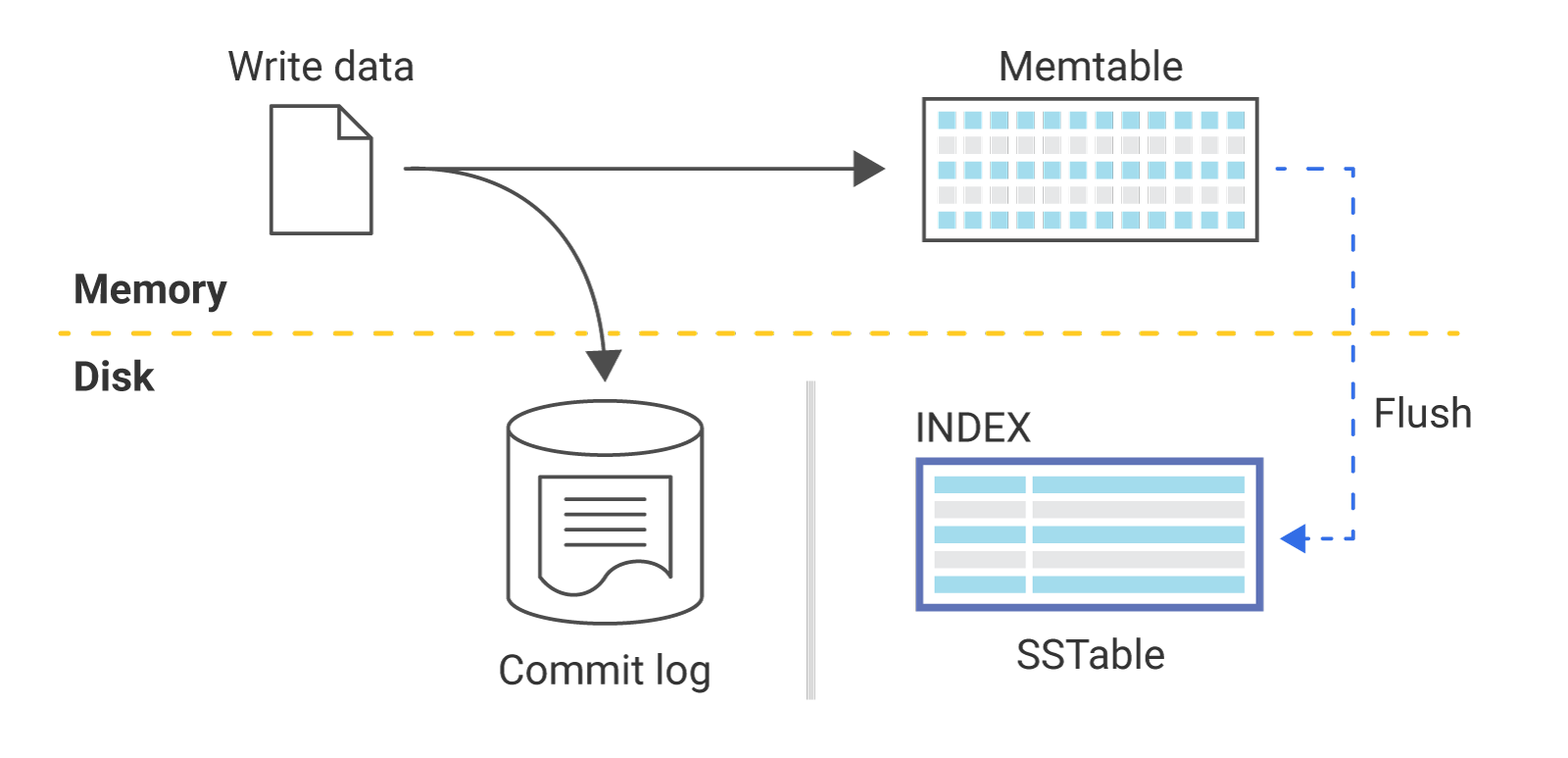
提交日志是预写日志,除非服务器崩溃或服务中断,否则永远不会真正读取。由于记忆存在于记忆中,因此它最终会变得满满的。为了释放内存空间,数据库会将 memtables 刷新到磁盘。该过程会产生 SSTables(排序字符串表),这是数据持久化的方式。
这一切与大分区有什么关系?好吧,SSTables 具有特定的组件,当数据库启动时,这些组件需要保存在内存中。这可确保读取始终有效,并在查找数据时最大限度地减少存储磁盘 I/O 的浪费。当您的分区非常大时(例如,我们最近有一个用户在 ScyllaDB 中使用了 2.5 TB 的分区),这些 SSTable 组件会带来沉重的内存压力,从而缩小数据库的缓存空间并进一步限制延迟。
如何通过数据建模解决大型分区问题?基本上,是时候重新考虑你的主键了。主键决定了数据在集群中的分布方式,从而提高了性能和资源利用率。一个好的分区键应该具有较高的基数和大致均匀的分布。例如,用户名、用户 ID 或传感器 ID 等高基数属性可能是一个很好的分区键。像州这样的东西将是一个糟糕的选择,因为像加利福尼亚州和德克萨斯州这样的州可能比怀俄明州和佛蒙特州等人口较少的州拥有更多的数据。
或者考虑这个例子。下表可用于具有多个传感器的分布式空气质量监测系统:
CQL系列
1
CREATE TABLE air_quality_data (
2
3
sensor_id text,
4
5
time timestamp,
6
7
co_ppm int,
8
9
PRIMARY KEY (sensor_id, time)
10
11
);
由于时间是我们表的聚类键,因此很容易想象每个传感器的分区可能会变得非常大,尤其是在每隔几毫秒收集一次数据的情况下。这张看起来无辜的桌子最终可能会变得无法使用。在此示例中,只需 ~50 天。
标准解决方案是修改数据模型,以减少每个分区键的聚类分析键数。在本例中,让我们看一下更新后的 ' 表:air_quality_data`
CQL系列
1
CREATE TABLE air_quality_data (
2
3
sensor_id text,
4
5
date text,
6
7
time timestamp,
8
9
co_ppm int,
10
11
PRIMARY KEY ((sensor_id, date), time)
12
13
);
更改后,一个分区保存一天内收集的值,这使得溢出的可能性较小。这种技术称为分桶,因为它允许我们控制分区中存储的数据量。
奖励:了解 Discord 如何应用相同的分桶技术来避免大分区。
热点介绍
热点可能是大分区的副作用。如果您有一个大型分区(存储数据集的很大一部分),则应用程序访问模式很可能会比其他分区更频繁地访问该分区。在这种情况下,它也成为一个热点。
每当有问题的数据访问模式导致集群中数据访问方式不平衡时,就会出现热点。一个罪魁祸首是应用程序未能对客户端施加任何限制,并允许租户潜在地向给定密钥发送垃圾邮件。例如,考虑消息传递应用程序中的机器人经常在频道中发送垃圾邮件。热点也可能由不稳定的客户端配置以重试风暴的形式引入。也就是说,客户端尝试查询特定数据,在数据库超时之前超时,并在数据库仍在处理前一个查询时重试查询。
监控仪表板应使你能够轻松查找集群中的热点。例如,此仪表板显示分片 20 因读取而不堪重负。

对于另一个示例,下图显示了三个利用率较高的分片,这与为相关密钥空间配置的 3 个复制因子相关。

在这里,由于垃圾邮件,分片 7 引入了更高的负载。
如何解决热点问题?首先,在其中一个受影响的节点上使用供应商实用程序,对采样期间最常点击的键进行采样。您还可以使用跟踪(如概率跟踪)来分析哪些查询命中了哪些分片,然后从那里采取行动。
如果发现热点,请考虑:
- 查看应用程序访问模式。您可能会发现需要更改数据建模,例如前面提到的分桶技术。如果需要排序,可以使用单调递增的组件,例如 Snowflake。或者,最好应用并发限制器并限制潜在的不良行为者。
- 指定每个分区的速率限制,超过此限制后,数据库将拒绝任何命中同一分区的查询。
- 确保客户端超时高于服务器端超时,以防止客户端在服务器有机会处理查询之前重试查询(“重试风暴”)。
滥用集合
团队并不总是使用集合,但当他们使用集合时,他们经常错误地使用它们。集合用于存储/非规范化相对较少量的数据。它们基本上存储在单个单元中,这使得序列化/反序列化成本极高。
使用集合时,可以定义相关字段是冻结的还是非冻结的。冻结的集合只能作为一个整体来编写;您无法从中追加或删除元素。可以附加一个非冻结的集合,而这正是人们最容易误用的集合类型。更糟糕的是,您甚至可以拥有嵌套集合,例如包含另一个地图的地图,其中包含列表等。
例如,误用的集合会比大型分区更早地引入性能问题。如果您关心性能,则集合根本不可能非常大。例如,如果我们创建一个简单的键值表,其中我们的键是“”,而我们的值是随时间推移记录的样本集合,那么一旦我们开始摄取数据,我们的性能就会不理想。sensor_id
CQL系列
1
CREATE TABLE IF NOT EXISTS {table} (2
3
sensor_id uuid PRIMARY KEY,
4
5
events map<timestamp, FROZEN<map<text, int>>>,
6
7
)
以下监视快照显示了当您尝试一次将多个项目追加到集合时会发生什么情况。


您可以看到,当吞吐量降低时,p99 延迟会增加。为什么会这样?
- 收集单元格作为排序的向量存储在内存中。
- 添加元素需要合并两个集合(旧集合和新集合)。
- 添加元素的成本与整个集合的大小成正比。
- 树(而不是向量)会提高性能,但是......
- 树木会降低小型收藏的效率!
返回相同的示例,解决方案是将时间戳移动到聚类键,并将映射转换为 FROZEN 集合(因为您不再需要向其追加数据)。这些非常简单的更改将大大提高用例的性能。
CQL系列
1
CREATE TABLE IF NOT EXISTS {table} (2
3
sensor_id uuid,
4
record_time timestamp,
5
6
events FROZEN<map<text, int>>,
7
8
PRIMARY KEY(sensor_id, record_time)
9
10
)
11
