




背景
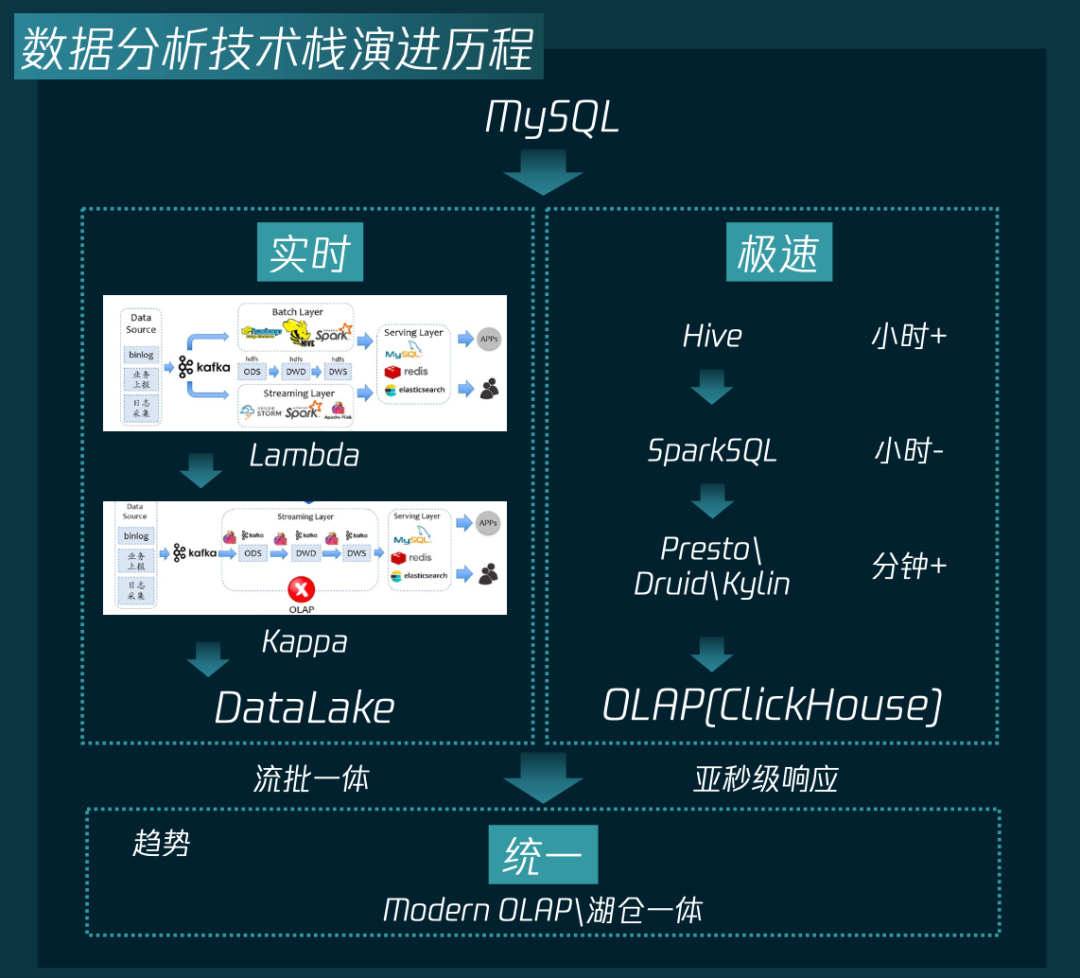
海量数据:在我们的业务场景下,数据规模很大,单表日增万亿,单次查询扫描数据量在10亿以上,同时需要计算的指标和维度可能会非常多(50+维度,100+指标);
极速:微信业务场景对查询耗时要求极高,查询耗时 TP 90 需要在5秒以内,同时要求数据低时效(秒/分钟);
统一:我们希望能够实现计算侧和存储侧的统一。
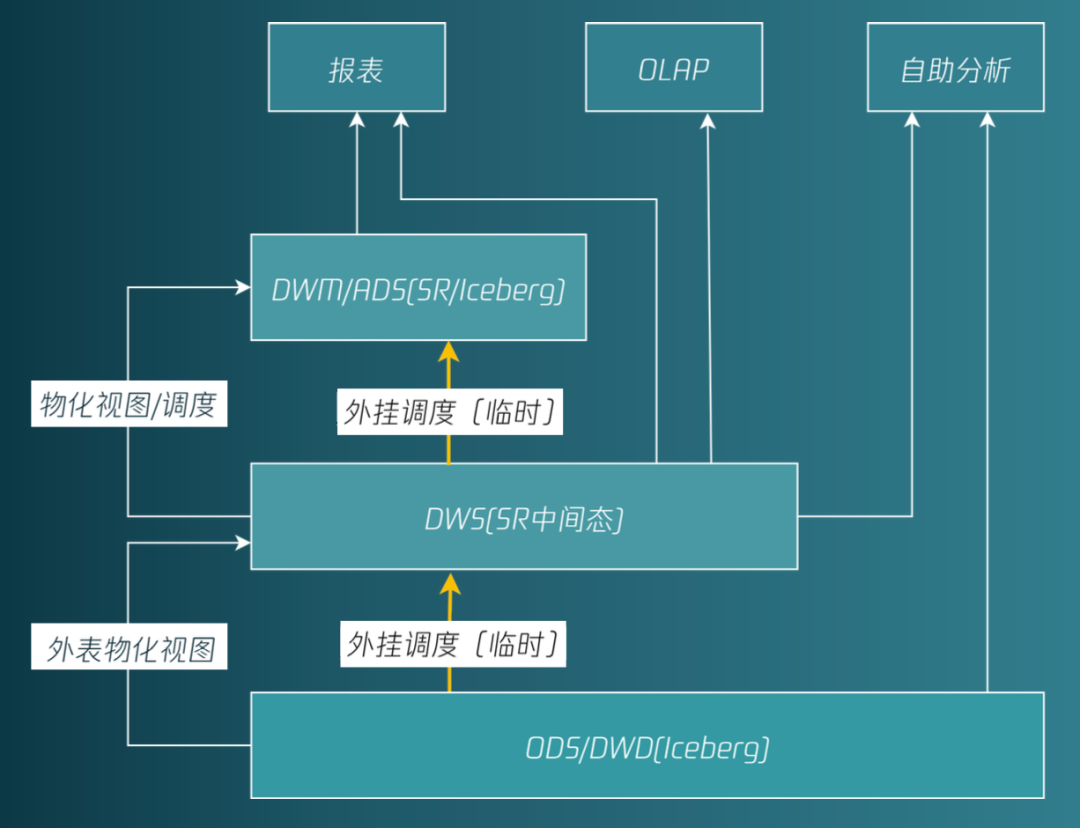
湖仓一体
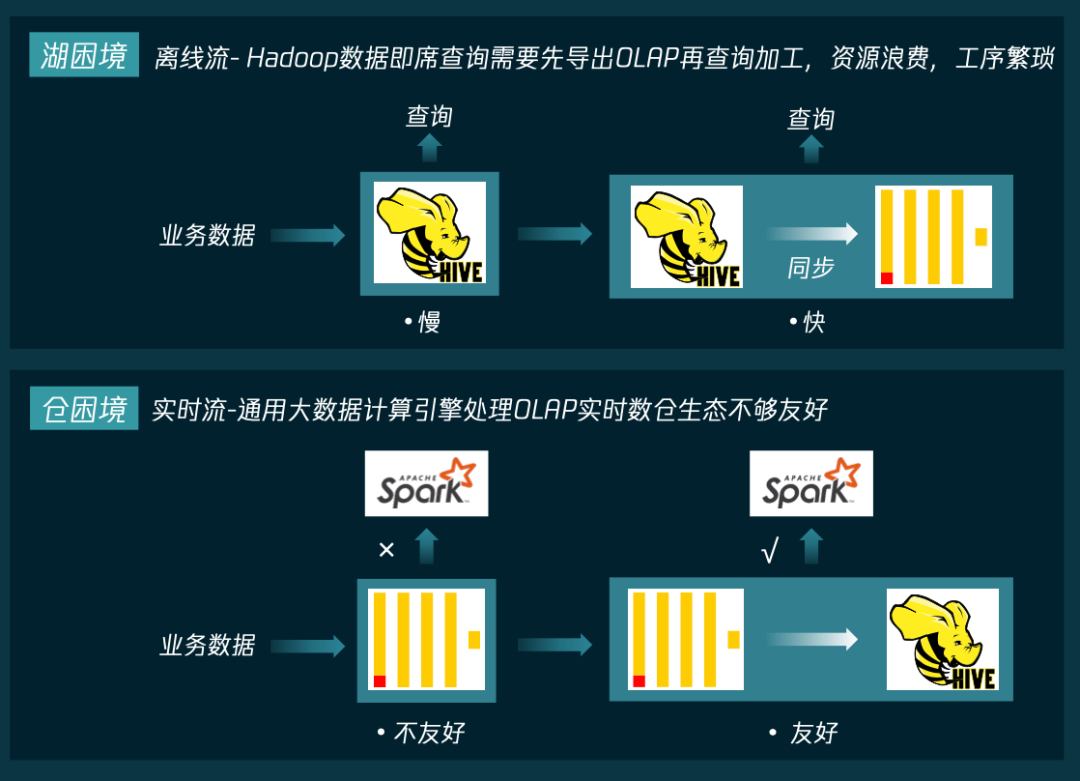
两份存储
口径不一致
额外的数据导入导出步骤
数据分析流程难以标准化
01
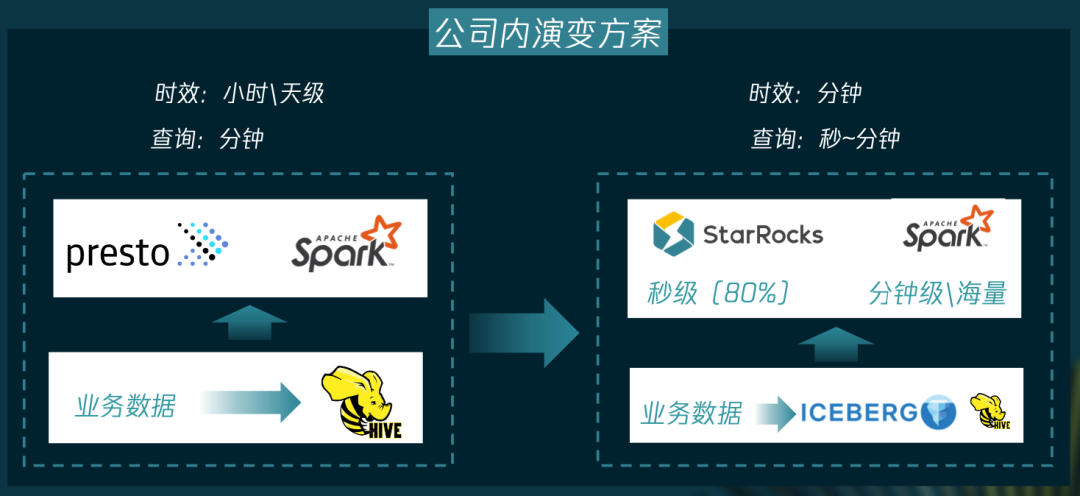
01
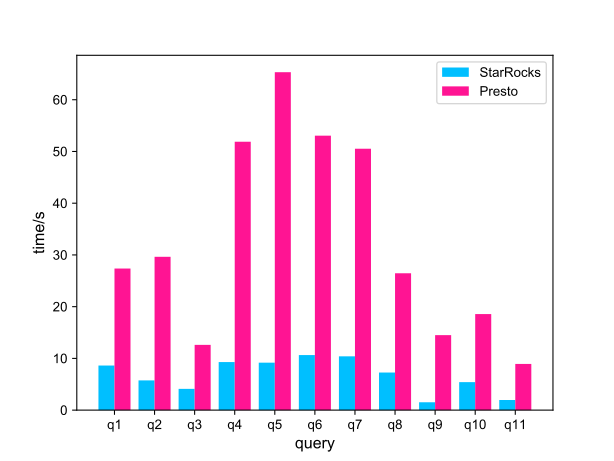
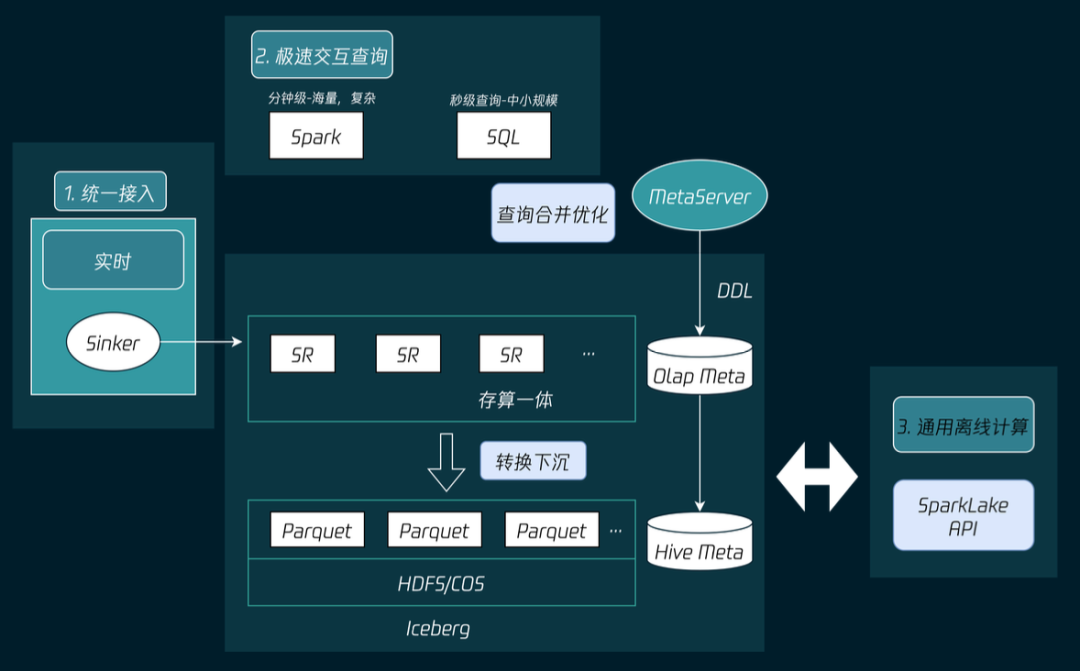
秒级:中大表,秒级返回,StarRocks
分钟级:大表查询,分钟级,Spark
02
02
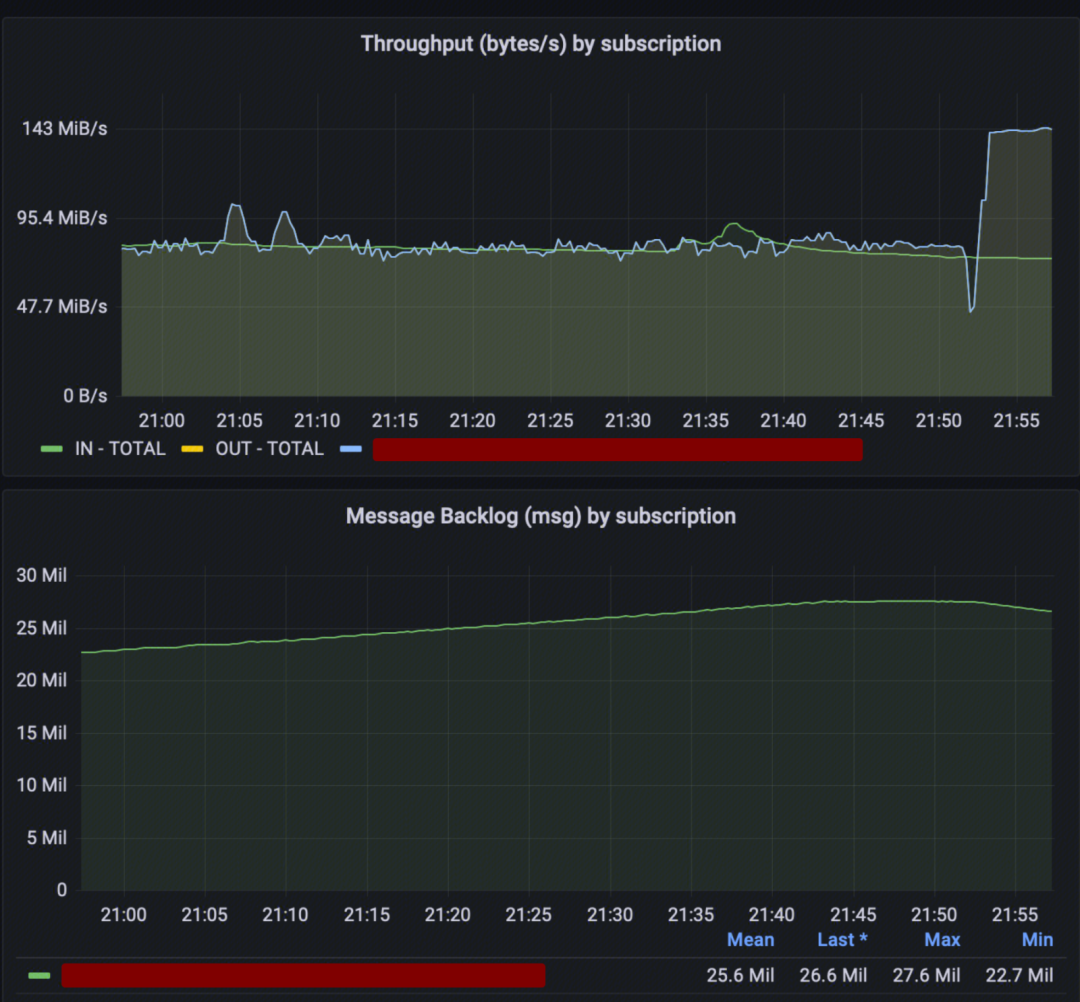 上线前
上线前
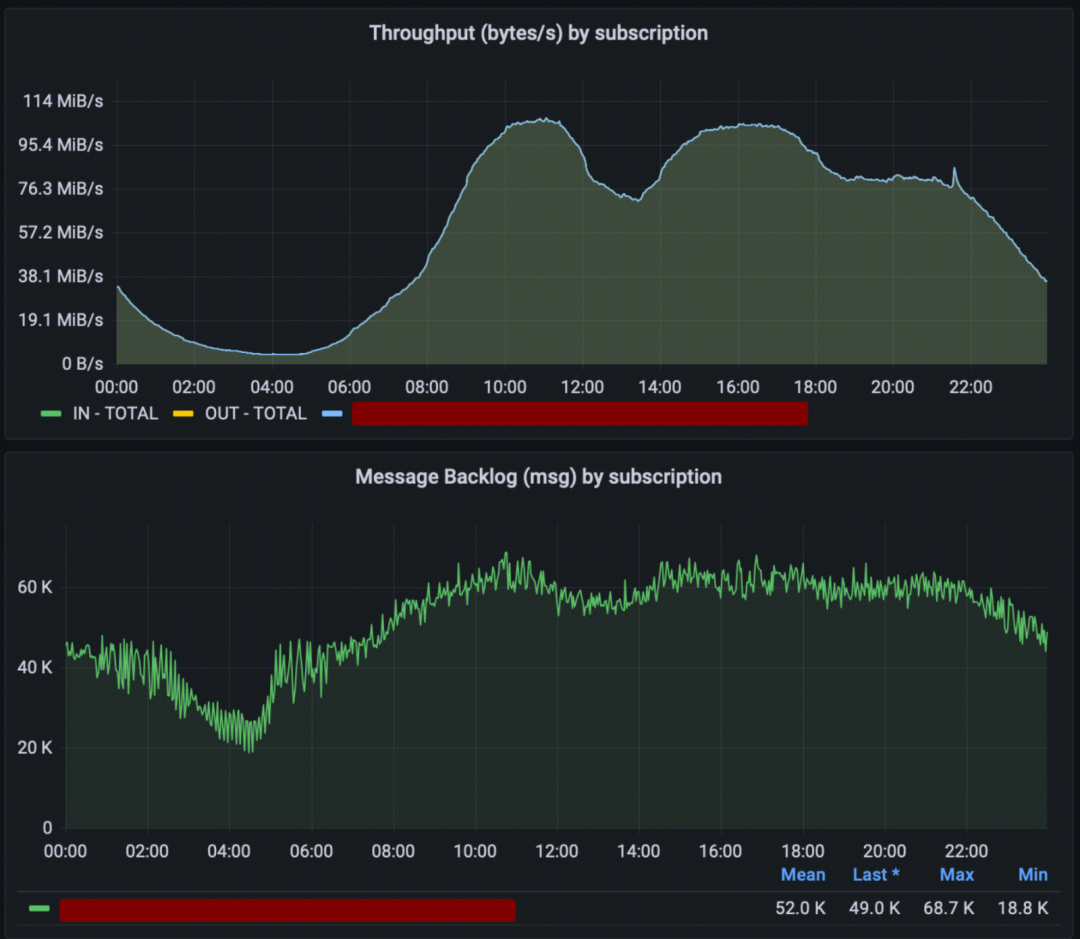 上线后
上线后03
03

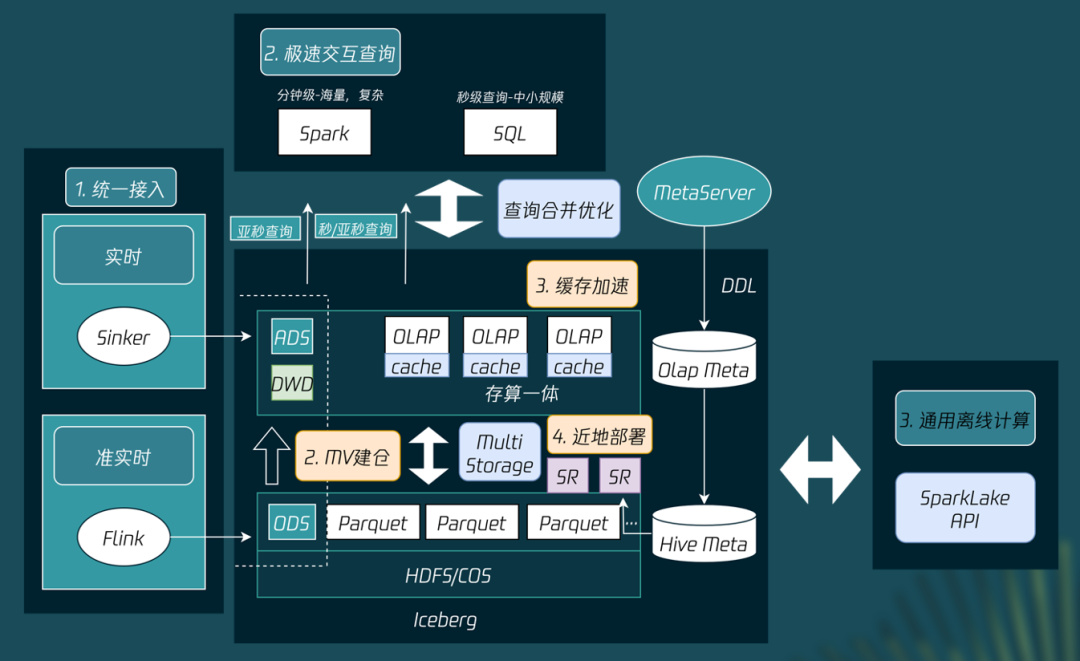
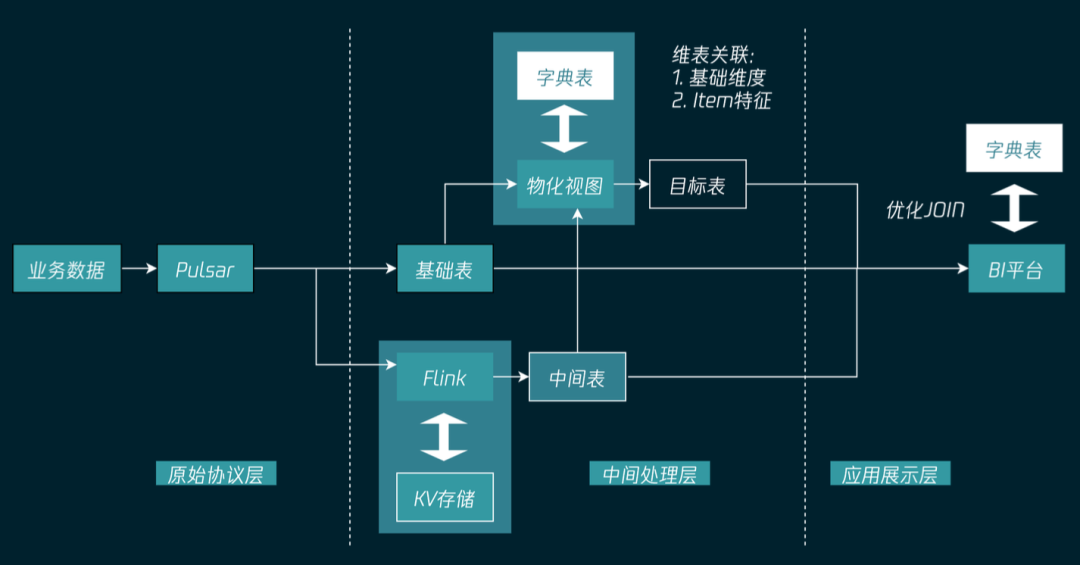
实时增量物化视图
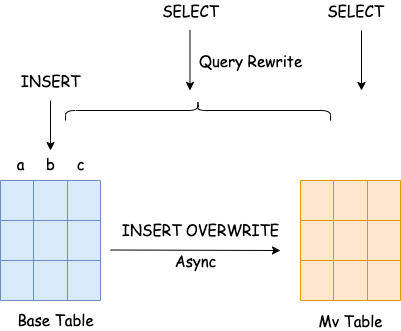
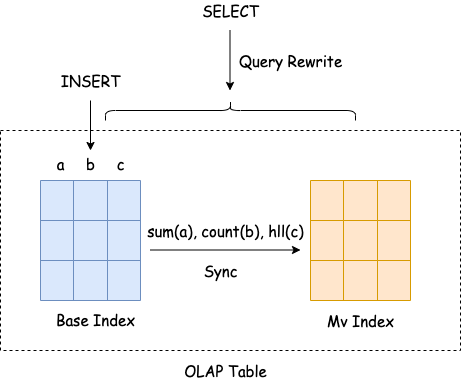
不支持复杂表达式,仅能够对基础表中的列进行简单的聚合操作,无论是维度列还是指标列中,都不能包含复杂表达式;
不支持输出列别名;
基础表中的列不能在物化视图中被多次引用;
仅支持少量聚合函数,不支持通用聚合函数;
物化视图数据与基础表强绑定,无法直接查询物化视图数据。
大规模,单表数据量大,因此物化视图只能增量更新,不能全量刷新
实时性要求高:需要同步刷新,不能异步刷新
多表指标拼接:多个基础表的物化视图计算指标拼接到同一个物化视图目标表中
在物化视图写入时进行高性能维表关联
...
01
01
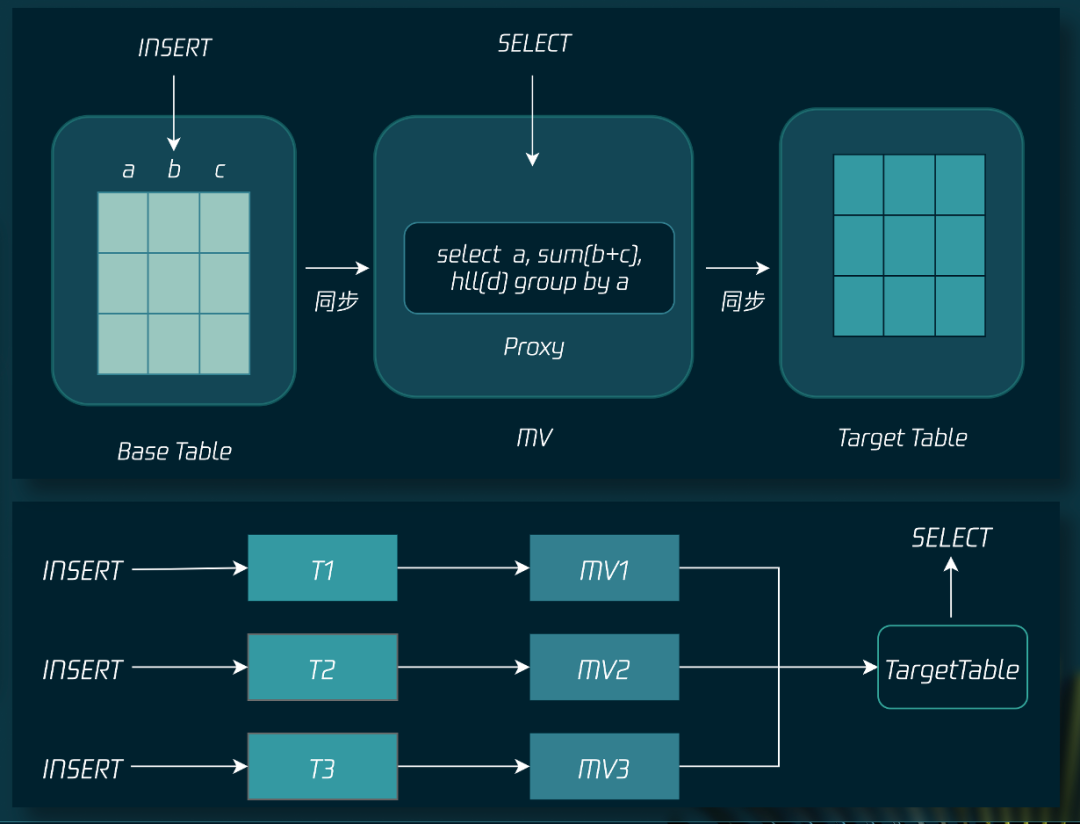
在数仓体系中,基础表通常属于 ODS 层,需要保留3~7天,而存储物化视图结果的目标表属于 DWS 层,通常需要保留半年到一年,将这两者解耦之后,我们才能够分别为其定义不同的存储周期。
将物化视图的计算逻辑和计算结果完全解耦,业务不需要关心具体的计算逻辑,直接查询物化视图目标表中存储的指标结果即可,能够极大提高易用性,同时能够将上下游业务逻辑解耦,上游计算逻辑发生变化不会影响下游使用。
最后,只有将两者解耦,我们才能够实现多个基础表的协议关联,通过让多个基础表的物化视图计算结果写同一个目标表,从而完成指标拼接。
02
02
03
03
总结与展望
面向 SQL,用户不再感知底层架构;
接入/查询体验统一,存储统一;
秒级/分钟级延迟架构体验统一,亚秒/分钟级分析统一;
SQL 交互标准统一。
致谢
感谢" StarRocks 社区"在功能开发,问题定位解决上的诸多帮忙,祝愿社区发展的越来越好!
关于 StarRocks


文章转载自StarRocks,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
