





沃尔玛是全球最大的零售商之一,也是人们进行家庭购物的首选零售商之一。以其在各种产品类别中的最低价格和成本节省而闻名,到其实体店购物本身就是一种体验。作为一家零售业务,沃尔玛产生了价值 5670 亿美元的销售额。沃尔玛设有一个专门致力于通过销售预测、根据客户购买趋势推荐产品、产品/客户细分以及数据科学的其他用例来改善客户-客户-员工关系的数据科学和分析部门。
问题陈述
在 2014 年,沃尔玛在 Kaggle 上举办了一场招聘竞赛。求职者被提供了包含不同地区的 45 家沃尔玛商店的历史销售数据。每家商店包含多个部门,我们的任务是预测每家商店的整个部门销售额。此外,沃尔玛每年都会举办几次促销性的降价活动。这些降价活动在突显的假期之前进行,其中最大的四个假期分别是超级碗、劳动节、感恩节和圣诞节。包括这些假期的周次在评估中的权重是非假期周次的五倍。这个竞赛所提出的挑战之一是在没有完整/理想的历史数据的情况下,对这些假期周次的降价效应进行建模。
理解业务需求和数据性质
我尝试解决的业务问题是通过在历史数据上训练机器学习模型来预测未来的销售数据。销售预测有助于每个企业做出更好的业务决策。它有助于整体业务规划、预算编制和风险管理。它允许公司有效地为未来的增长分配资源并管理其现金流。销售预测还帮助企业根据其能够预测其短期和长期绩效的准确成本和收入估算。
下载并使用pandas读取
import warnings
warnings.filterwarnings('ignore')
导入模块
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
# import jovian
import plotly.express as px
import os
import zipfile
import glob
%matplotlib inline
sns.set_style('darkgrid')
matplotlib.rcParams['font.size']=14
matplotlib.rcParams['figure.figsize'] = (10,8)
从Kaggle下载数据
手动下载
解压缩
import os
os.makedirs('walmart',exist_ok=True)
for file in glob.glob("walmart-recruiting-store-sales-forecasting.zip"):
with zipfile.ZipFile(file, 'r') as zip_ref:
zip_ref.extractall("walmart/")
使用 Pandas 读取输入文件
def return_df(file):
return pd.read_csv(os.path.join("walmart",file), header = 0)
stores = return_df("stores.csv")
features = return_df("features.csv.zip")
train = return_df("train.csv.zip")
test = return_df("test.csv.zip")
数据文件说明
stores - 45 家店铺的类型和大小 features - 与店铺、部门和区域活动相关的数据,如燃油价格、顾客价格指数、失业率等,涵盖了指定日期范围内的信息 train - 历史训练数据,包括 2010 年 2 月 5 日到 2012 年 11 月 1 日的日期范围 test - 用于测试已训练模型的数据,与训练数据相同,但不包含周销售列
display(stores.sample(5).sort_values(by='Store').reset_index(drop=True))
| Store | Type | Size | |
|---|---|---|---|
| 0 | 11 | A | 207499 |
| 1 | 24 | A | 203819 |
| 2 | 31 | A | 203750 |
| 3 | 39 | A | 184109 |
| 4 | 42 | C | 39690 |
display(features.sample(5).sort_values(by='Store').reset_index(drop=True))
| Store | Date | Temperature | Fuel_Price | MarkDown1 | MarkDown2 | MarkDown3 | MarkDown4 | MarkDown5 | CPI | Unemployment | IsHoliday | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 2011-07-08 | 87.70 | 3.480 | NaN | NaN | NaN | NaN | NaN | 214.929625 | 7.852 | False |
| 1 | 2 | 2010-04-02 | 63.27 | 2.719 | NaN | NaN | NaN | NaN | NaN | 210.479887 | 8.200 | False |
| 2 | 22 | 2012-06-01 | 70.01 | 3.798 | 16432.28 | 7.60 | 73.36 | 3723.80 | 3331.57 | 142.109544 | 7.671 | False |
| 3 | 22 | 2012-03-02 | 37.47 | 3.827 | 28298.18 | 3333.76 | 89.58 | 25615.48 | 3141.76 | 141.387536 | 7.503 | False |
| 4 | 37 | 2012-09-28 | 79.49 | 3.666 | 59.61 | NaN | NaN | NaN | 722.92 | 221.655600 | 6.623 | False |
display(train.sample(5).sort_values(by='Store').reset_index(drop=True))
| Store | Dept | Date | Weekly_Sales | IsHoliday | |
|---|---|---|---|---|---|
| 0 | 1 | 42 | 2011-03-11 | 8293.47 | False |
| 1 | 22 | 93 | 2010-08-20 | 2335.70 | False |
| 2 | 24 | 44 | 2011-04-08 | 4203.04 | False |
| 3 | 31 | 24 | 2012-05-25 | 4151.44 | False |
| 4 | 39 | 24 | 2012-04-27 | 5425.93 | False |
display(test.sample(5).sort_values(by='Store').reset_index(drop=True))
| Store | Dept | Date | IsHoliday | |
|---|---|---|---|---|
| 0 | 3 | 31 | 2013-04-26 | False |
| 1 | 11 | 13 | 2013-02-15 | False |
| 2 | 12 | 54 | 2013-07-12 | False |
| 3 | 34 | 40 | 2013-06-21 | False |
| 4 | 44 | 60 | 2013-05-10 | False |
问题识别
Weekly_Sales 是一个标记的连续数值特征。因此,这是监督学习的一个应用,具体来说,是一个回归问题。
项目大纲
数据预处理 探索性数据分析 模型训练准备 实施和训练模型 模型评估 超参数调整 模型选择 预测和分析
1. 数据预处理
通过清理、转换和编码必要的分类变量,准备历史商店销售数据。执行特征工程和特征选择。已执行以下预处理任务:
使用 Pandas 的合并操作将商店和特征数据框与训练和测试数据框合并。 将布尔特征转换为 0 和 1。 检查缺失/NaN 值。
将特征和商店的数据框与训练和测试数据合并
features = features.merge(stores, how = 'left', on = 'Store')
def return_merged_data(data):
df = data.merge(features, how = 'left', on = ['Store','Date','IsHoliday']).sort_values(by=['Store','Dept','Date']).reset_index(drop=True)
return df
train_data, test_data = return_merged_data(train), return_merged_data(test)
display(train_data.sample(5).sort_values(by = 'Store').reset_index(drop = True))
| Store | Dept | Date | Weekly_Sales | IsHoliday | Temperature | Fuel_Price | MarkDown1 | MarkDown2 | MarkDown3 | MarkDown4 | MarkDown5 | CPI | Unemployment | Type | Size | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | 44 | 2011-06-17 | 2580.86 | False | 86.96 | 3.637 | NaN | NaN | NaN | NaN | NaN | 218.355175 | 7.574 | B | 37392 |
| 1 | 7 | 32 | 2011-10-21 | 3265.18 | False | 37.49 | 3.548 | NaN | NaN | NaN | NaN | NaN | 195.178999 | 8.513 | B | 70713 |
| 2 | 17 | 22 | 2011-02-18 | 6682.91 | False | 26.86 | 3.062 | NaN | NaN | NaN | NaN | NaN | 127.995250 | 6.866 | B | 93188 |
| 3 | 20 | 42 | 2011-06-03 | 10052.31 | False | 73.51 | 3.922 | NaN | NaN | NaN | NaN | NaN | 208.355112 | 7.287 | A | 203742 |
| 4 | 26 | 11 | 2012-08-03 | 14430.99 | False | 65.60 | 3.698 | 28330.0 | 49.21 | 42.09 | 8478.97 | 3544.06 | 138.173581 | 7.405 | A | 152513 |
将 IsHoliday 的布尔数据转换为 0(False)和 1(True)
def convert_boolean(data):
data['IsHoliday'] = data['IsHoliday'].map({False : 0, True : 1}).astype('int')
return data
train_data, test_data = convert_boolean(train_data), convert_boolean(test_data)
检查缺失/NaN 值
train_data.isna().sum()
Store 0
Dept 0
Date 0
Weekly_Sales 0
IsHoliday 0
Temperature 0
Fuel_Price 0
MarkDown1 270889
MarkDown2 310322
MarkDown3 284479
MarkDown4 286603
MarkDown5 270138
CPI 0
Unemployment 0
Type 0
Size 0
dtype: int64
唯一具有缺失值的特征是 MarkDown(1-5),它是与沃尔玛正在运行的促销降价活动相关的匿名数据。MarkDown 数据仅在 2011 年 11 月后可用,并且并非始终对所有商店都可用。任何缺失值都用 NA 标记。我已经用 0 替换了这些列中的 NaN 值。
用 0 替换 NaN 值
def replace_nan(data):
columns_to_fill = ['MarkDown1','MarkDown2','MarkDown3','MarkDown4','MarkDown5']
data[columns_to_fill] = data[columns_to_fill].fillna(0)
return data
train_data, test_data = replace_nan(train_data), replace_nan(test_data)
特征工程
从日期列中提取了 DayOfMonth、Month、Year、DayOfWeek、WeekOfYear 和 Quarter,并删除了日期列 创建了一个名为 MarkDown 的新列,它是所有 MarkDown(1-5) 列的总和,然后删除了这 5 列 在 IsHoliday 列中,我将值更改为 1,表示国家和联邦假期,因为带有假期的周可能比没有假期的周销售额更高。沃尔玛在假期期间可能还提供了促销活动。
从日期列提取日期信息
def extract_date_info(df):
df['Date2'] = pd.to_datetime(df['Date'])
df['Day'] = df['Date2'].dt.day.astype('int')
df['Month'] = df['Date2'].dt.month.astype('int')
df['Year'] = df['Date2'].dt.year.astype('int')
# df['DayOfWeek'] = df['Date2'].dt.weekday
df['WeekOfYear'] = df['Date2'].dt.isocalendar().week.astype('int')
df['Quarter'] = df['Date2'].dt.quarter.astype('int')
df = df.drop(columns = ['Date2'])
return df
train_data, test_data = extract_date_info(train_data), extract_date_info(test_data)
数据摘要统计
train_data.describe()
| Store | Dept | Weekly_Sales | IsHoliday | Temperature | Fuel_Price | MarkDown1 | MarkDown2 | MarkDown3 | MarkDown4 | MarkDown5 | CPI | Unemployment | Size | Day | Month | Year | WeekOfYear | Quarter | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 421570.000000 | 421570.000000 | 421570.000000 | 421570.000000 | 421570.000000 | 421570.000000 | 421570.000000 | 421570.000000 | 421570.000000 | 421570.000000 | 421570.000000 | 421570.000000 | 421570.000000 | 421570.000000 | 421570.000000 | 421570.000000 | 421570.000000 | 421570.000000 | 421570.000000 |
| mean | 22.200546 | 44.260317 | 15981.258123 | 0.070358 | 60.090059 | 3.361027 | 2590.074819 | 879.974298 | 468.087665 | 1083.132268 | 1662.772385 | 171.201947 | 7.960289 | 136727.915739 | 15.673131 | 6.449510 | 2010.968591 | 25.826762 | 2.482767 |
| std | 12.785297 | 30.492054 | 22711.183519 | 0.255750 | 18.447931 | 0.458515 | 6052.385934 | 5084.538801 | 5528.873453 | 3894.529945 | 4207.629321 | 39.159276 | 1.863296 | 60980.583328 | 8.753549 | 3.243217 | 0.796876 | 14.151887 | 1.071341 |
| min | 1.000000 | 1.000000 | -4988.940000 | 0.000000 | -2.060000 | 2.472000 | 0.000000 | -265.760000 | -29.100000 | 0.000000 | 0.000000 | 126.064000 | 3.879000 | 34875.000000 | 1.000000 | 1.000000 | 2010.000000 | 1.000000 | 1.000000 |
| 25% | 11.000000 | 18.000000 | 2079.650000 | 0.000000 | 46.680000 | 2.933000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 132.022667 | 6.891000 | 93638.000000 | 8.000000 | 4.000000 | 2010.000000 | 14.000000 | 2.000000 |
| 50% | 22.000000 | 37.000000 | 7612.030000 | 0.000000 | 62.090000 | 3.452000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 182.318780 | 7.866000 | 140167.000000 | 16.000000 | 6.000000 | 2011.000000 | 26.000000 | 2.000000 |
| 75% | 33.000000 | 74.000000 | 20205.852500 | 0.000000 | 74.280000 | 3.738000 | 2809.050000 | 2.200000 | 4.540000 | 425.290000 | 2168.040000 | 212.416993 | 8.572000 | 202505.000000 | 23.000000 | 9.000000 | 2012.000000 | 38.000000 | 3.000000 |
| max | 45.000000 | 99.000000 | 693099.360000 | 1.000000 | 100.140000 | 4.468000 | 88646.760000 | 104519.540000 | 141630.610000 | 67474.850000 | 108519.280000 | 227.232807 | 14.313000 | 219622.000000 | 31.000000 | 12.000000 | 2012.000000 | 52.000000 | 4.000000 |
将所有 MarkDown(1-5) 值添加到一个新列 MarkDown 中
def markdown_info(df):
# Drop rows with negative values in the specified columns
# negative_mask = (df['MarkDown1'] < 0) | (df['MarkDown2'] < 0) | (df['MarkDown3'] < 0) | (df['MarkDown4'] < 0) | (df['MarkDown5'] < 0)
# df = df[~negative_mask].copy()
# Create a new column 'MarkDown' with the sum of values from the 5 columns
df['MarkDown'] = df['MarkDown1'] + df['MarkDown2'] + df['MarkDown3'] + df['MarkDown4'] + df['MarkDown5']
df.drop(['MarkDown1', 'MarkDown2', 'MarkDown3', 'MarkDown4', 'MarkDown5'], axis=1, inplace=True)
return df
train_data, test_data = markdown_info(train_data), markdown_info(test_data)
添加国家假期信息
所有四年的假期的共同周数:
第 1 周:元旦(2010 年,2011 年,2012 年,2013 年) 第 6 周:超级碗 第 47 周:感恩节(2010 年,2011 年,2012 年) 第 52 周:圣诞节(2010 年,2011 年,2012 年,2013 年)
def isholiday(df):
holiday_weeks = [1, 6, 36, 47, 52]
df.loc[df['WeekOfYear'].isin(holiday_weeks), 'IsHoliday'] = 1
return df
train_data, test_data = isholiday(train_data), isholiday(test_data)
仅考虑那些每周销售额为正的行
train_data = train_data[train_data['Weekly_Sales'] > 0]
按日期对训练数据进行排序
train_data = train_data.sort_values(by=['Date']).reset_index(drop=True)
2. 探索性数据分析
让我们探索几个输入列与目标列 Weeky_Sales 之间的趋势。
可视化相关矩阵的热力图
numeric_cols = ['Store', 'Dept', 'IsHoliday', 'Temperature','Fuel_Price', 'CPI', 'Unemployment', 'Size', 'Day', 'Month','Year', 'WeekOfYear', 'Quarter', 'MarkDown','Weekly_Sales']
sns.heatmap(train_data[numeric_cols].corr().round(decimals=2), annot = True)

洞察 - 大小和部门似乎与每周销售额有最高的相关性。
整年的所有周中销售的趋势是什么?
sns.lineplot(data=train_data, x='WeekOfYear', y='Weekly_Sales')
plt.xlabel('Week')
plt.ylabel('Weekly Sales')
plt.title('Trend of Weekly Sales over Time')
plt.show()

洞察 - 感恩节和圣诞节周似乎有一个明显的销售激增。
不同商店的每周销售额是怎样的?
avg_sales_by_store = train_data.groupby('Store')['Weekly_Sales'].mean().reset_index()
sns.barplot(data=avg_sales_by_store, x='Store', y='Weekly_Sales',
order = avg_sales_by_store.sort_values('Weekly_Sales',ascending = False)['Store'])
plt.xlabel('Store')
plt.ylabel('Average Weekly Sales')
plt.title('Average Weekly Sales by Store')
plt.xticks(rotation=90) # Rotate X-axis labels by 45 degrees
plt.tight_layout() # Adjust layout to prevent label overlapping
plt.show()

洞察 - 平均每周销售额最高的五家商店分别是 20、4、14、13、2。
一天的温度是否影响销售额?
sns.scatterplot(data=train_data, x='Temperature', y='Weekly_Sales')
plt.xlabel('Temperature')
plt.ylabel('Weekly Sales')
plt.title('Relationship between Temperature and Weekly Sales')
plt.show()
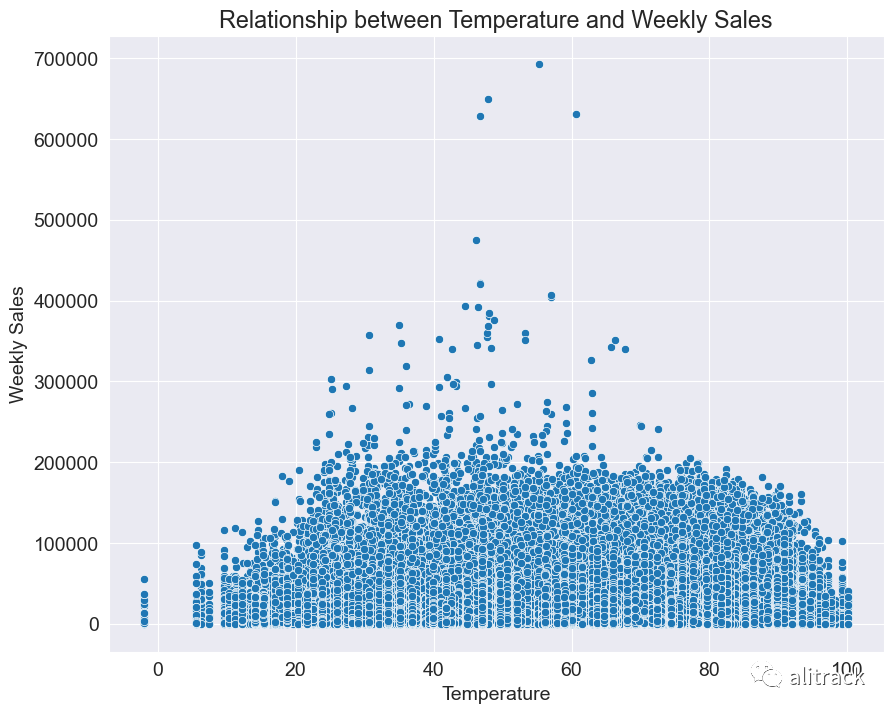
洞察 - 在温度在 30-70 华氏度的范围内时,似乎记录了较高的每周销售额。
商店类型是否与每周销售额有任何趋势?
sns.boxplot(data=train_data, x='Type', y='Weekly_Sales',showfliers = False)
plt.xlabel('Store Type')
plt.ylabel('Weekly Sales')
plt.title('Weekly Sales Distribution by Store Type')
plt.show()

洞察 - A 类商店似乎具有较高的每周销售额,其次是 B 类,然后是 C 类。
每月的平均每周销售额是多少?
avg_sales_by_month = train_data.groupby('Month')['Weekly_Sales'].mean().reset_index()
sns.barplot(data=avg_sales_by_month, x='Month', y='Weekly_Sales')
plt.xlabel('Month')
plt.ylabel('Average Weekly Sales')
plt.title('Average Weekly Sales by Month')
plt.show()
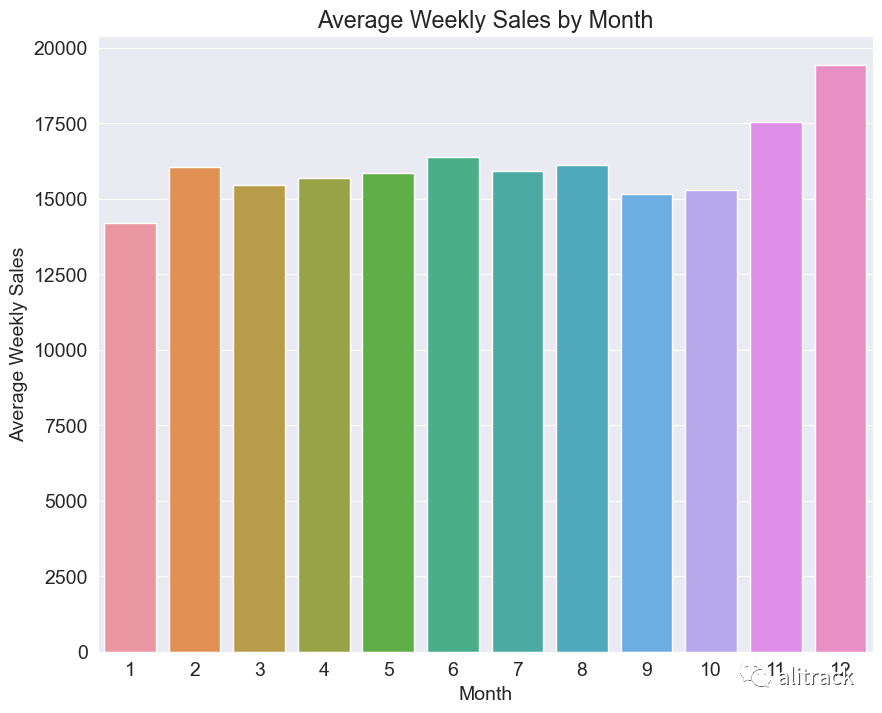
洞察 - 第 11 和 12 月似乎记录了最高的每周销售额。
商店大小与每周销售额之间的关系?
sns.scatterplot(data=train_data, x='Size', y='Weekly_Sales', hue='Type')
plt.xlabel('Store Size')
plt.ylabel('Weekly Sales')
plt.title('Weekly Sales vs. Store Size with Store Type')
plt.show()

洞察 - A 类店铺是更大的沃尔玛,因此记录最高每周销售额是合理的。
假期周与非假期周的每周销售额
sns.boxplot(data=train_data, x='IsHoliday', y='Weekly_Sales')
plt.xlabel('Is Holiday')
plt.ylabel('Weekly Sales')
plt.title('Weekly Sales Distribution for Holidays vs. Non-Holidays')
plt.xticks([0, 1], ['Non-Holiday', 'Holiday'])
plt.show()
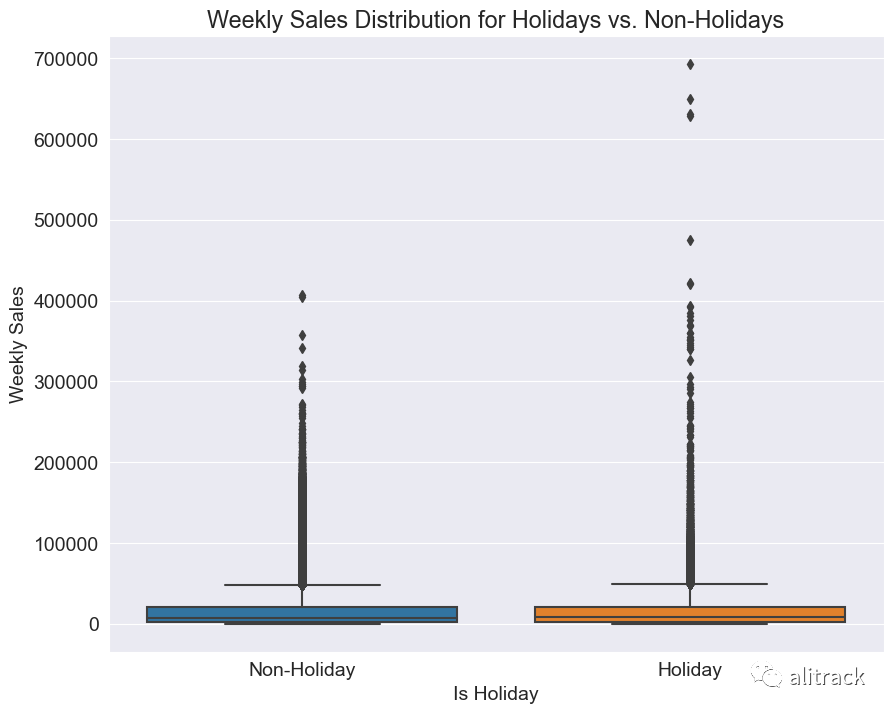
洞察 - 与非假期周相比,假期周具有更多的高周销售额离群值。
average weekly sales for all the years
avg_sales_by_year = train_data.groupby('Year')['Weekly_Sales'].sum().reset_index()
# Plot the average weekly sales by years
sns.barplot(data=avg_sales_by_year, x='Year', y='Weekly_Sales')
plt.xlabel('Year')
plt.ylabel('Average Weekly Sales')
plt.title('Average Weekly Sales by Years')
plt.show()
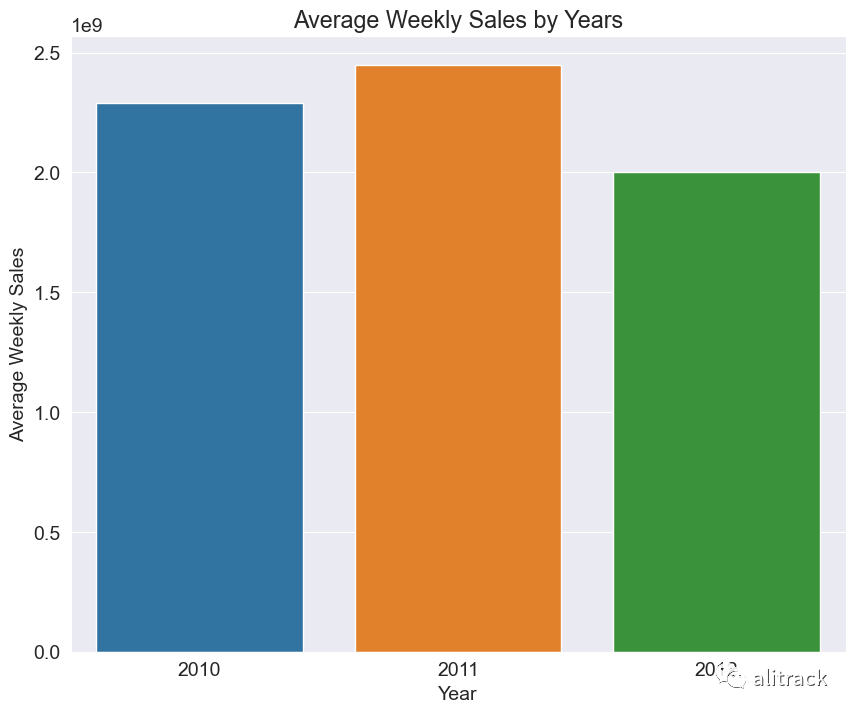
洞察 - 2011 年是记录了最高每周销售额的年份。
sns.lineplot(train_data, x = 'WeekOfYear', y = 'Weekly_Sales', hue = 'Year', palette = ['blue', 'red', 'green'])
plt.xlabel('Week Of Year')
plt.ylabel('Weekly Sales')
plt.title('Weekly Sales vs. Week of Year')
plt.show()
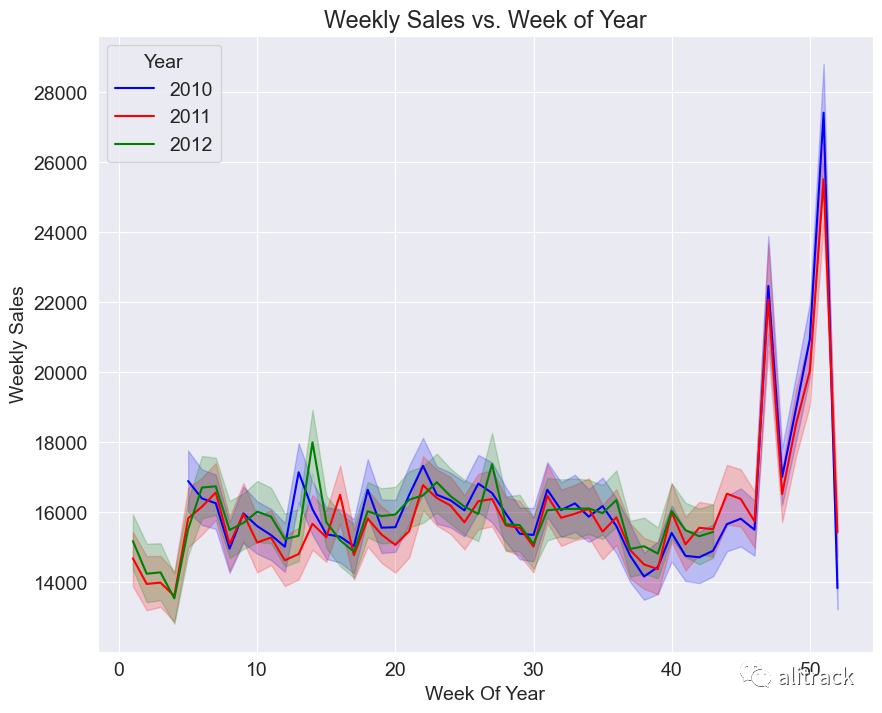
洞察 - 年度趋势似乎遵循相似的销售趋势 - 在假期周围存在销售激增。
avg_sales_by_store = train_data.sample(1000).groupby(['Dept'])['Weekly_Sales'].mean().reset_index()
plt.figure(figsize = (80,30))
sns.barplot(data=avg_sales_by_store, x='Dept', y='Weekly_Sales', order = avg_sales_by_store.sort_values('Weekly_Sales',ascending = False)['Dept'])
plt.xlabel('Department', fontsize = 100)
plt.ylabel('Average Weekly Sales', fontsize = 100)
plt.title('Average Weekly Sales by Department', fontsize = 100)
plt.yticks(fontsize=60)
plt.xticks(fontsize=60)
plt.xticks(rotation=90) # Rotate X-axis labels by 45 degrees
plt.tight_layout() # Adjust layout to prevent label overlapping
plt.show()

洞察 - 表现最好的五个部门是 95、38、40、92、90。
avg_sales_by_month = train_data.groupby('Quarter')['Weekly_Sales'].mean().reset_index()
sns.barplot(data=avg_sales_by_month, x='Quarter', y='Weekly_Sales')
plt.xlabel('Quarter')
plt.ylabel('Average Weekly Sales')
plt.title('Average Weekly Sales by Quarter')
plt.show()
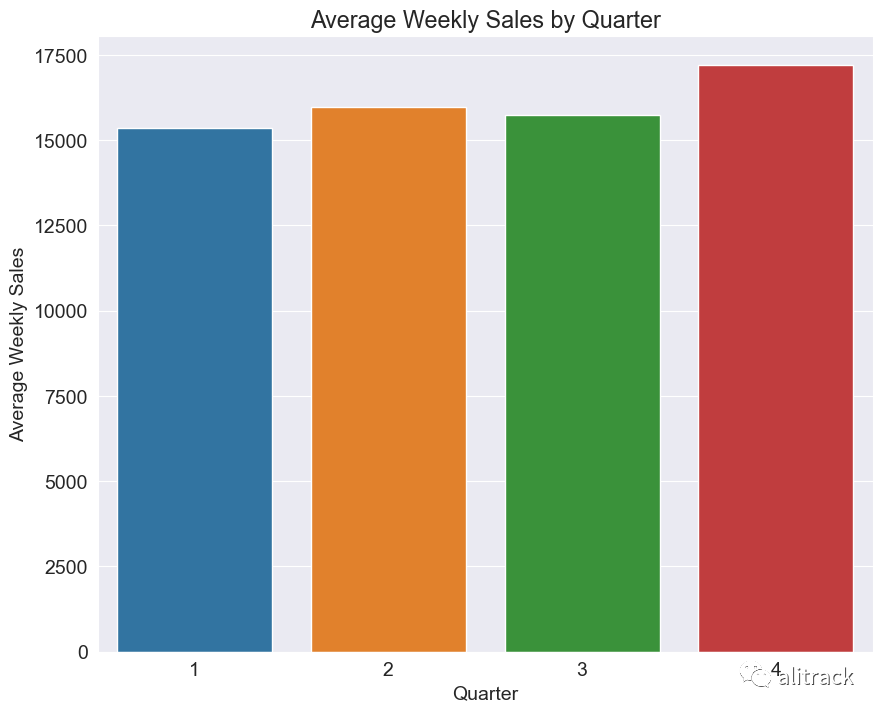
洞察 - 如预期的那样,第四季度的销售额较其他季度更高。
avg_sales_by_month = train_data.groupby(['Day', 'Month'])['Weekly_Sales'].mean().reset_index()
sns.lineplot(data=avg_sales_by_month, x='Day', y='Weekly_Sales', hue = 'Month', palette = sns.color_palette("Paired", 12))
plt.xlabel('Day')
plt.ylabel('Average Weekly Sales')
plt.title('Average Weekly Sales by Day')
plt.show()
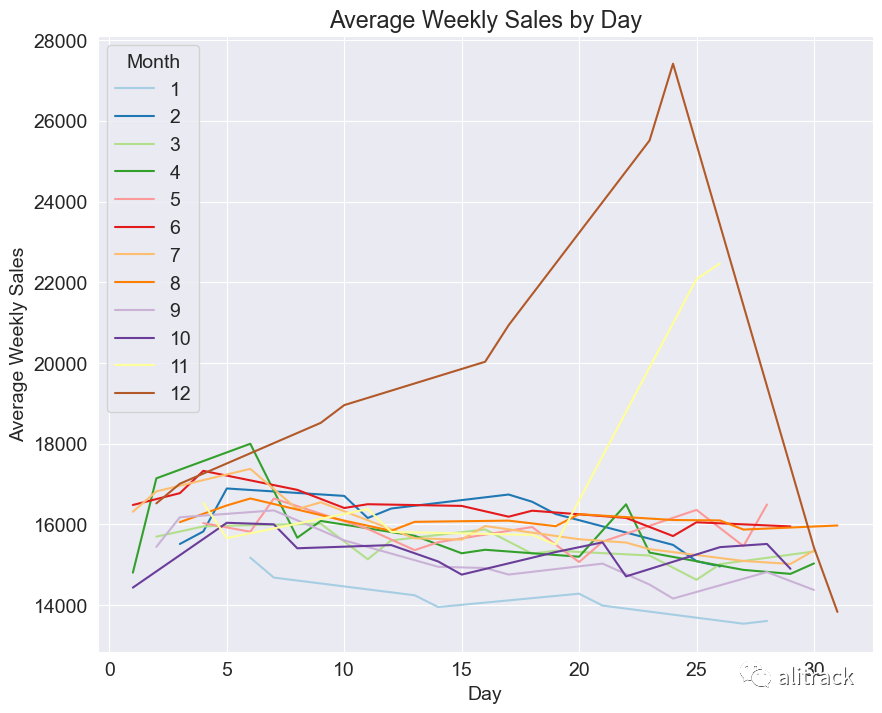
洞察 - 圣诞节周围存在一个巨大的销售额激增。
3. 准备训练机器学习模型
在这一部分,我执行了以下任务:
将数据分割为训练集和验证集(75-25 的划分) 识别输入和目标列 识别数值和分类列 填充、缩放和编码
将给定的训练数据分割为训练和验证数据
我们将对训练数据和验证数据进行一个大致的 75-25 分割。
train_size = int(.75 * len(train_data))
train_df,val_df = train_data[:train_size], train_data[train_size:]
len(train_df), len(val_df)
(315159, 105053)
Identifying input and target columns
input_cols = ['Store', 'Dept', 'IsHoliday', 'Temperature','Fuel_Price', 'CPI', 'Unemployment', 'Type', 'Size', 'Day', 'Month','Year', 'WeekOfYear', 'Quarter', 'MarkDown']
target_col = 'Weekly_Sales'
train_inputs = train_df[input_cols].copy()
train_targets = train_df[target_col].copy()
val_inputs = val_df[input_cols].copy()
val_targets = val_df[target_col].copy()
test_inputs = test_data[input_cols].copy()
识别数值和分类列
def num_cat_cols(data):
numeric_cols = data.select_dtypes(include=['int64', 'float64']).columns.tolist()
categorical_cols = data.select_dtypes('object').columns.tolist()
return numeric_cols, categorical_cols
numeric_cols, categorical_cols = num_cat_cols(train_inputs)
Imputation, Scaling and Encode
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import OneHotEncoder
imputer = SimpleImputer(strategy='mean').fit(train_inputs[numeric_cols])
train_inputs[numeric_cols] = imputer.transform(train_inputs[numeric_cols])
val_inputs[numeric_cols] = imputer.transform(val_inputs[numeric_cols])
test_inputs[numeric_cols] = imputer.transform(test_inputs[numeric_cols])
scaler = MinMaxScaler().fit(train_inputs[numeric_cols])
train_inputs[numeric_cols] = scaler.transform(train_inputs[numeric_cols])
val_inputs[numeric_cols] = scaler.transform(val_inputs[numeric_cols])
test_inputs[numeric_cols] = scaler.transform(test_inputs[numeric_cols])
encoder = OneHotEncoder(sparse_output=False, handle_unknown='ignore').fit(train_inputs[categorical_cols])
encoded_cols = list(encoder.get_feature_names_out(categorical_cols))
train_inputs[encoded_cols] = encoder.transform(train_inputs[categorical_cols])
val_inputs[encoded_cols] = encoder.transform(val_inputs[categorical_cols])
test_inputs[encoded_cols] = encoder.transform(test_inputs[categorical_cols])
X_train = train_inputs[numeric_cols+encoded_cols]
X_val = val_inputs[numeric_cols+encoded_cols]
X_test = test_inputs[numeric_cols+encoded_cols]
4. 实施和训练机器学习模型
基线机器学习模型 - 线性模型
由于这是一个回归问题,我将把 LinearRegression() 模型作为基线机器学习模型。
我还额外训练了 Ridge、Lasso、ElasticNet 和 SGDRegressor,以便全面比较 Sklearn 提供的所有线性模型的性能。
我创建了一个名为 try_linear_models(model)
的函数,该函数以模型作为输入,对训练数据进行训练,并返回训练和验证的均方根误差。
from sklearn.linear_model import LinearRegression, Ridge, Lasso, ElasticNet, SGDRegressor
from sklearn.metrics import mean_absolute_error, mean_squared_error, mean_squared_log_error, r2_score
linear_models_scores = {}
def try_linear_models(model_name, model):
model.fit(X_train, train_targets) # training the model on training data
train_preds = model.predict(X_train)
val_preds = model.predict(X_val) # model predictions on validation data
# Training prediction scores
train_mae = mean_absolute_error(train_targets, train_preds)
train_rmse = mean_squared_error(train_targets, train_preds, squared=False)
train_r2 = r2_score(train_targets, train_preds)
# validation prediction scores
val_mae = mean_absolute_error(val_targets, val_preds)
val_rmse = mean_squared_error(val_targets, val_preds, squared=False)
val_r2 = r2_score(val_targets, val_preds)
linear_models_scores[model_name] = {'mae':[round(train_mae,2), round(val_mae,2)],'rmse':[round(train_rmse,2), round(val_rmse,2)],'r2':[round(train_r2,2), round(val_r2,2)]}
return val_mae, val_rmse, val_r2
model_names = ['linear', 'ridge', 'lasso', 'elasticnet', 'sgd']
models = [LinearRegression(), Ridge(), Lasso(), ElasticNet(), SGDRegressor()]
for i in range(len(models)):
val_mae, val_rmse, val_r2 = try_linear_models(model_names[i], models[i])
pd.DataFrame(linear_models_scores)
| linear | ridge | lasso | elasticnet | sgd | |
|---|---|---|---|---|---|
| mae | [14610.62, 14416.66] | [14610.46, 14410.3] | [14609.78, 14409.66] | [14857.83, 14743.27] | [14842.92, 14716.8] |
| rmse | [21897.48, 20997.08] | [21897.78, 20995.76] | [21898.1, 20995.46] | [22466.83, 21587.16] | [21909.39, 21011.37] |
| r2 | [0.09, 0.1] | [0.09, 0.1] | [0.09, 0.1] | [0.04, 0.04] | [0.09, 0.09] |
我们看到线性模型的平均 RMSE 分数约为 20,000 美元。这是我们基线机器学习模型非常差的性能,因为 20,000 美元大约是每周销售的第 75 百分位数。模型的 r2 分数非常低,因此我认为没有必要进一步调查线性模型。
集成模型
我已经训练了一些集成模型,比如随机森林、梯度提升、AdaBoost、XGBoost 和 LightGBM,使用默认参数进行初步检查,以查看哪些模型具有更好的评估分数。我创建了一个名为 try_ensemble_methods()
的函数,它以模型作为输入并返回评估指标。
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor, AdaBoostRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
rf_scores = {}
gb_scores = {}
ab_scores = {}
xgb_scores = {}
lgbm_scores = {}
trained_models = {}
def try_ensemble_methods(model_name, model, score_dict):
model.fit(X_train, train_targets.values.ravel())
train_preds = model.predict(X_train)
val_preds = model.predict(X_val)
# Training prediction scores
train_mae = mean_absolute_error(train_targets, train_preds)
train_rmse = mean_squared_error(train_targets, train_preds, squared=False)
train_r2 = r2_score(train_targets, train_preds)
# validation prediction scores
val_mae = mean_absolute_error(val_targets, val_preds)
val_rmse = mean_squared_error(val_targets, val_preds, squared=False)
val_r2 = r2_score(val_targets, val_preds)
score_dict['mae'] = {'training':round(train_mae,2), 'validation': round(val_mae,2)}
score_dict['rmse'] = {'training':round(train_rmse,2), 'validation': round(val_rmse,2)}
score_dict['r2'] = {'training':round(train_r2,2), 'validation': round(val_r2,2)}
trained_models[model_name] = model
return val_mae, val_rmse, val_r2
ensemble_models = [RandomForestRegressor(random_state=42, n_jobs=-1),
GradientBoostingRegressor(random_state=42),
AdaBoostRegressor(random_state=42),
XGBRegressor(random_state=42, n_jobs=-1),
LGBMRegressor(random_state=42, n_jobs=-1)]
ensemble_model_names = ['random_forest','gradient_boosting',
'adaboost','xgboost','lightgbm']
score_dicts = [rf_scores,gb_scores, ab_scores, xgb_scores, lgbm_scores]
for i in range(5):
val_mae, val_rmse, val_r2 = try_ensemble_methods(ensemble_model_names[i], ensemble_models[i], score_dicts[i])
print("*********")
print(ensemble_model_names[i])
print("Val MAE: ", val_mae)
print("Val RMSE: ", val_rmse)
print("Val R2: ", val_r2)
*********
random_forest
Val MAE: 1972.73927486126
Val RMSE: 4293.76945097734
Val R2: 0.9621713170910176
*********
gradient_boosting
Val MAE: 6599.888238020384
Val RMSE: 10390.931194099461
Val R2: 0.778459712408722
*********
adaboost
Val MAE: 18335.0794120106
Val RMSE: 22224.678093018403
Val R2: -0.013478956504596962
*********
xgboost
Val MAE: 3326.0800714051434
Val RMSE: 5480.708662594418
Val R2: 0.9383664460585117
*********
lightgbm
Val MAE: 4175.374835228325
Val RMSE: 6710.251528702608
Val R2: 0.9076107638701445
5. Model Evaluation
print("Random Forest scores")
display(pd.DataFrame(rf_scores))
print("XGBoost Scores")
display(pd.DataFrame(xgb_scores))
print("LightGBM Scores")
display(pd.DataFrame(lgbm_scores))
print("Gradient Boosting Scores")
display(pd.DataFrame(gb_scores))
print("AdaBoost Scores")
display(pd.DataFrame(ab_scores))
Random Forest scores
| mae | rmse | r2 | |
|---|---|---|---|
| training | 493.43 | 1285.99 | 1.00 |
| validation | 1972.74 | 4293.77 | 0.96 |
XGBoost Scores
| mae | rmse | r2 | |
|---|---|---|---|
| training | 2962.67 | 5084.61 | 0.95 |
| validation | 3326.08 | 5480.71 | 0.94 |
LightGBM Scores
| mae | rmse | r2 | |
|---|---|---|---|
| training | 4095.20 | 6717.26 | 0.91 |
| validation | 4175.37 | 6710.25 | 0.91 |
Gradient Boosting Scores
| mae | rmse | r2 | |
|---|---|---|---|
| training | 6881.98 | 11743.40 | 0.74 |
| validation | 6599.89 | 10390.93 | 0.78 |
AdaBoost Scores
| mae | rmse | r2 | |
|---|---|---|---|
| training | 19386.34 | 23509.50 | -0.05 |
| validation | 18335.08 | 22224.68 | -0.01 |
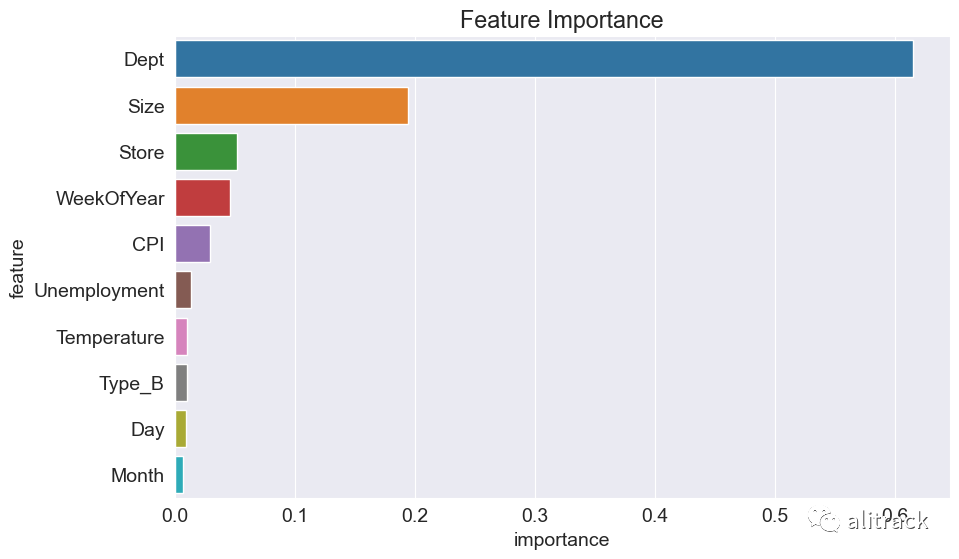
Feature importance
rf = trained_models['random_forest']
xgb = trained_models['xgboost']
lgbm = trained_models['lightgbm']
rf_imp_df = pd.DataFrame({
'feature': X_train.columns,
'importance': rf.feature_importances_
}).sort_values('importance', ascending=False)
plt.figure(figsize=(10,6))
plt.title('Feature Importance')
sns.barplot(data=rf_imp_df.head(10), x='importance', y='feature');
xgb_imp_df = pd.DataFrame({
'feature': X_train.columns,
'importance': xgb.feature_importances_
}).sort_values('importance', ascending=False)
plt.figure(figsize=(10,6))
plt.title('Feature Importance')
sns.barplot(data=xgb_imp_df.head(10), x='importance', y='feature');
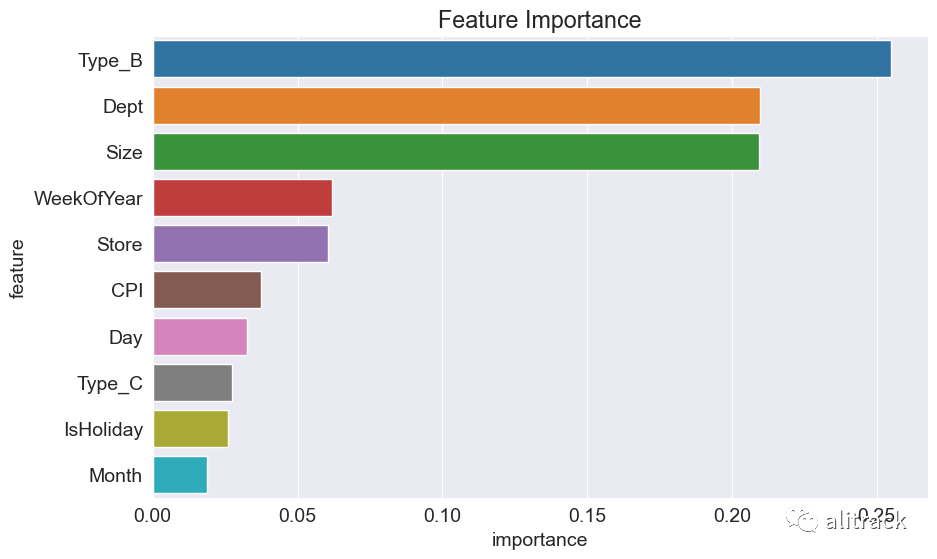
lgbm_imp_df = pd.DataFrame({
'feature': X_train.columns,
'importance': lgbm.feature_importances_
}).sort_values('importance', ascending=False)
plt.figure(figsize=(10,6))
plt.title('Feature Importance')
sns.barplot(data=lgbm_imp_df.head(10), x='importance', y='feature');
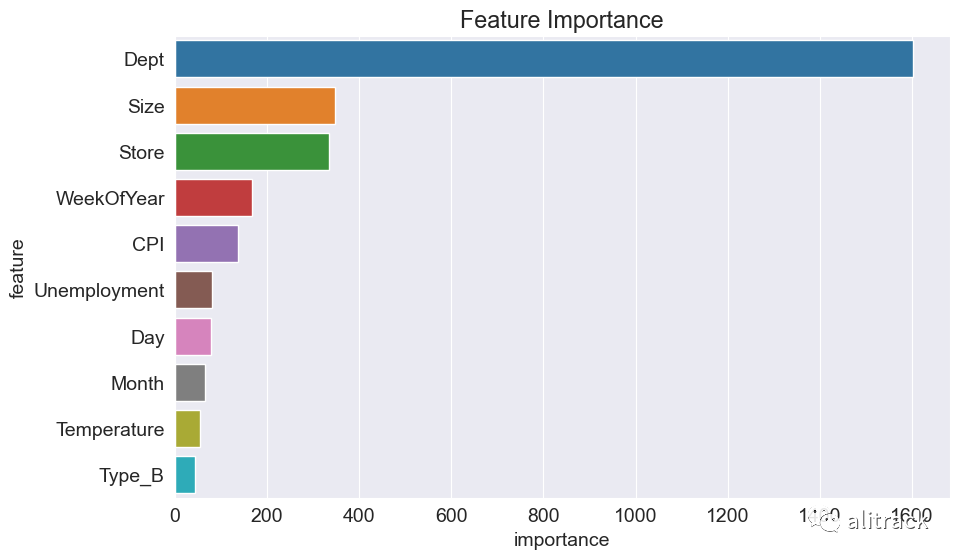
部门(Dept)和大小(Size)是决定每周销售的两个最重要的特征。
表现最好的三个模型是随机森林、XGBoost 和 LightGBM。我将对这些模型进行超参数调整。
6. 超参数调整
超参数调整是基于加权平均绝对误差(WMAE)进行评估的。
$ WMAE = \frac1}{\sum w_i} \sum_{i=1}^{n} w_i_i| $
其中,
n:行数 :预测销售额 :实际销售额 :权重。如果这周是假期周,w = 5,否则为 1。
def weighted_mean_absolute_error(y_true, y_pred, weights):
return np.sum(weights * np.abs(y_true - y_pred)) / np.sum(weights)
# Creating the weights
train_weights = np.where(X_train['IsHoliday'] == 1, 5, 1)
val_weights = np.where(X_val['IsHoliday'] == 1, 5, 1)
models = {
'randomforest': {
'model': RandomForestRegressor,
'params': {
'max_depth': [5, 10, 15, 20, 25, 30, None],
'n_estimators': [20, 50, 100, 150, 200, 250, 300,500],
'min_samples_split': [2, 3, 4, 5, 10]
}
},
'xgboost': {
'model': XGBRegressor,
'params': {
'max_depth': [3, 4, 5, 6, 7, 8, 9, 10],
'n_estimators': [30, 50, 100, 150, 200, 250, 300, 500],
'learning_rate': [0.3, 0.2, 0.1, 0.01, 0.001]
}
},
'lightgbm': {
'model': LGBMRegressor,
'params': {
'max_depth': [3, 4, 5, 6, 7, 8, 9, 10],
'n_estimators': [30, 50, 100, 150, 200, 250, 300, 500],
'learning_rate': [0.3, 0.2, 0.1, 0.01, 0.001]
}
}
}
results = {}
def test_params(model_type, model, **params):
model_instance = model(**params)
model_instance.fit(X_train, train_targets)
train_wmae = weighted_mean_absolute_error(model_instance.predict(X_train), train_targets, train_weights)
val_wmae = weighted_mean_absolute_error(model_instance.predict(X_val), val_targets, val_weights)
return train_wmae, val_wmae
def test_param_and_plot(model_type, model, param_name, param_values):
train_errors, val_errors = [], []
wmae_results = {}
for value in param_values:
params = {param_name: value}
train_wmae, val_wmae = test_params(model_type, model, **params)
train_errors.append(train_wmae)
val_errors.append(val_wmae)
plt.figure(figsize=(10, 6))
plt.title(model_type + ' Overfitting curve: ' + param_name)
plt.plot(param_values, train_errors, 'b-o')
plt.plot(param_values, val_errors, 'r-o')
plt.xlabel(param_name)
plt.ylabel('WMAE')
plt.legend(['Training', 'Validation'])
wmae_results[param_name] = {
'train_wmae': train_errors,
'val_wmae': val_errors
}
return wmae_results
# Iterate over each model type
for model_type, config in models.items():
model = config['model']
params = config['params']
# Iterate over each parameter and its values
for param_name, param_values in params.items():
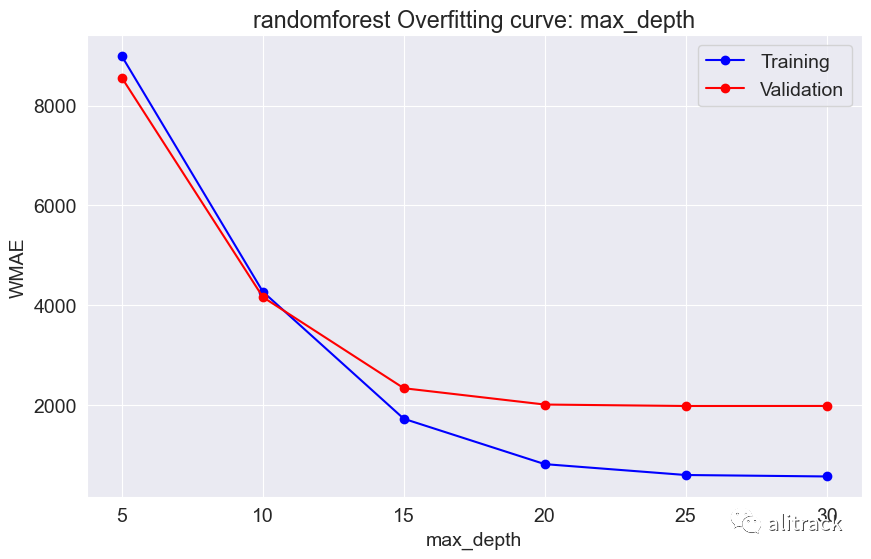
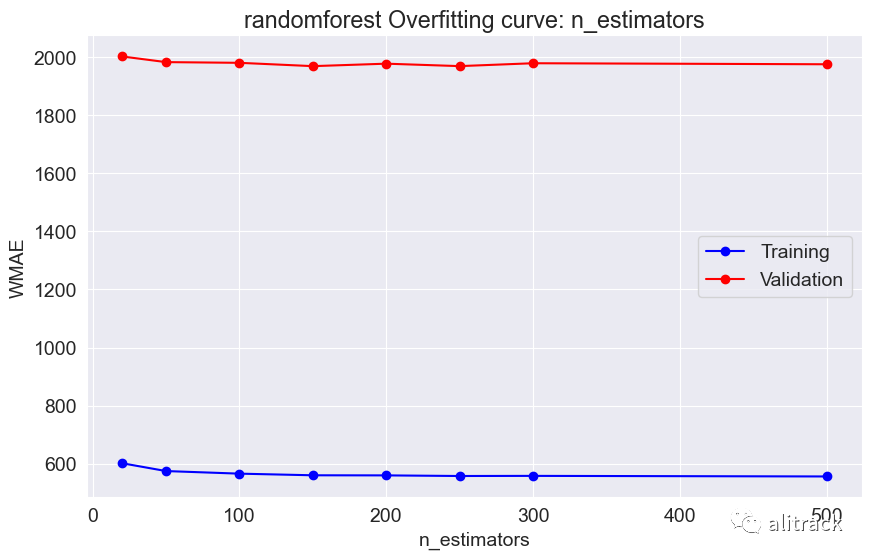
wmae_results = test_param_and_plot(model_type, model, param_name, param_values)
results[model_type] = wmae_results
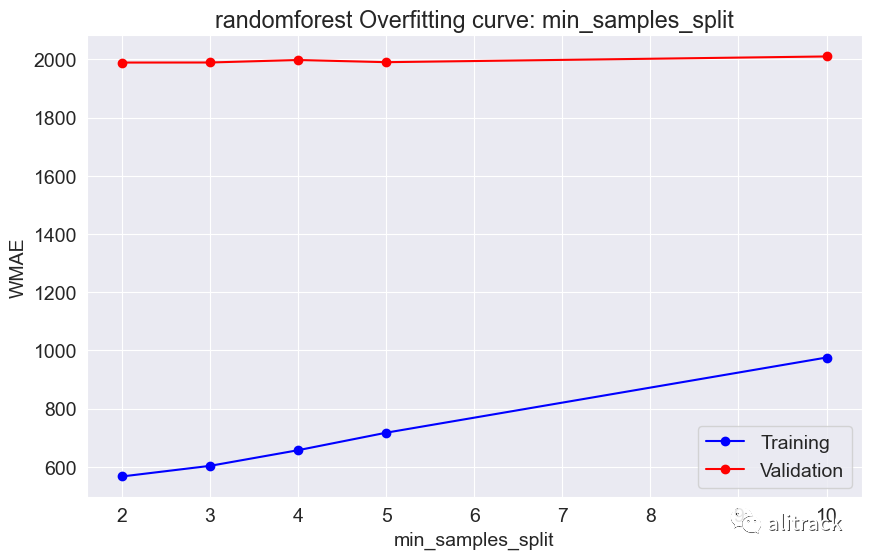
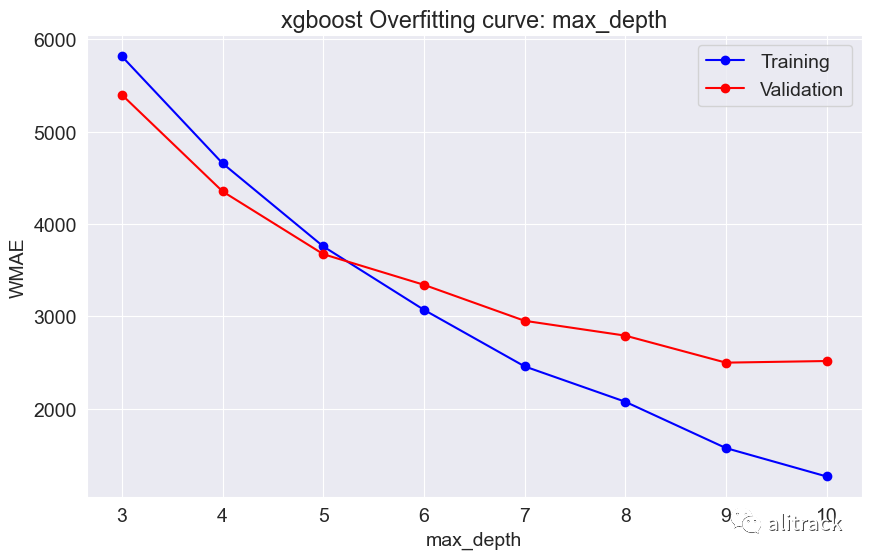
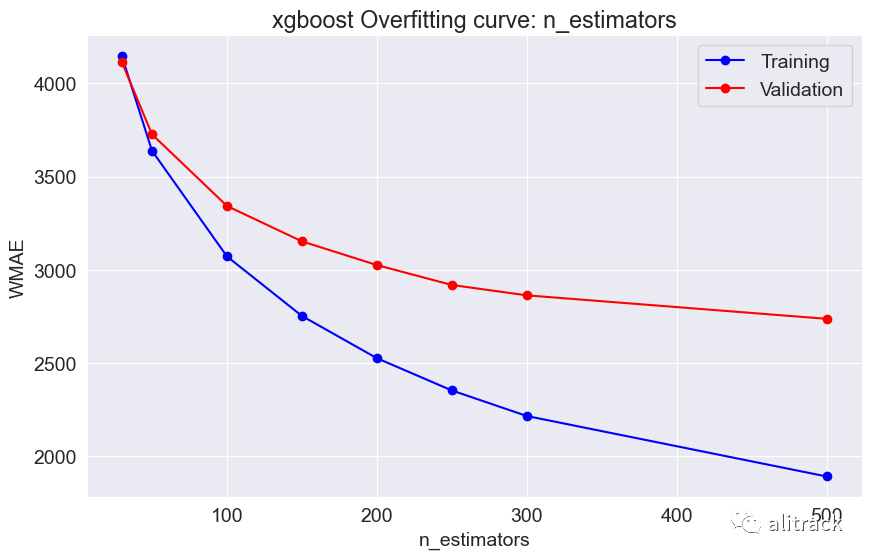
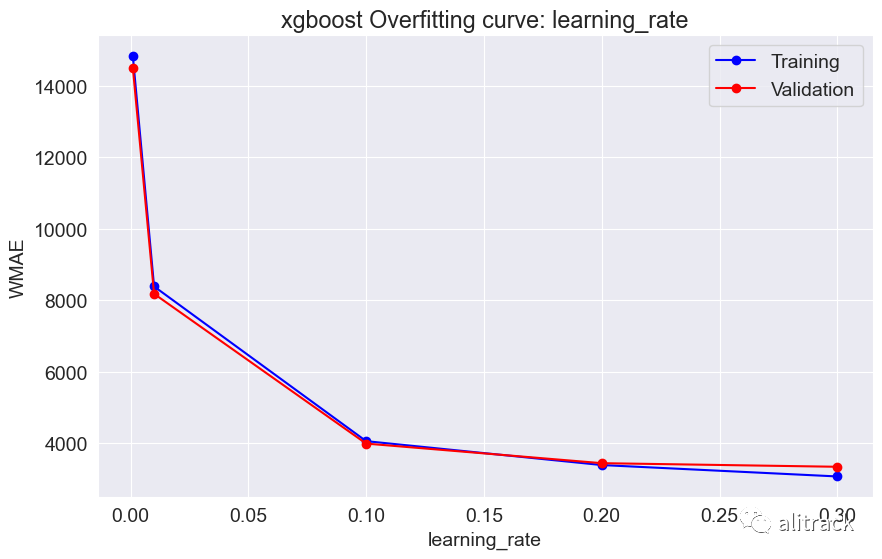

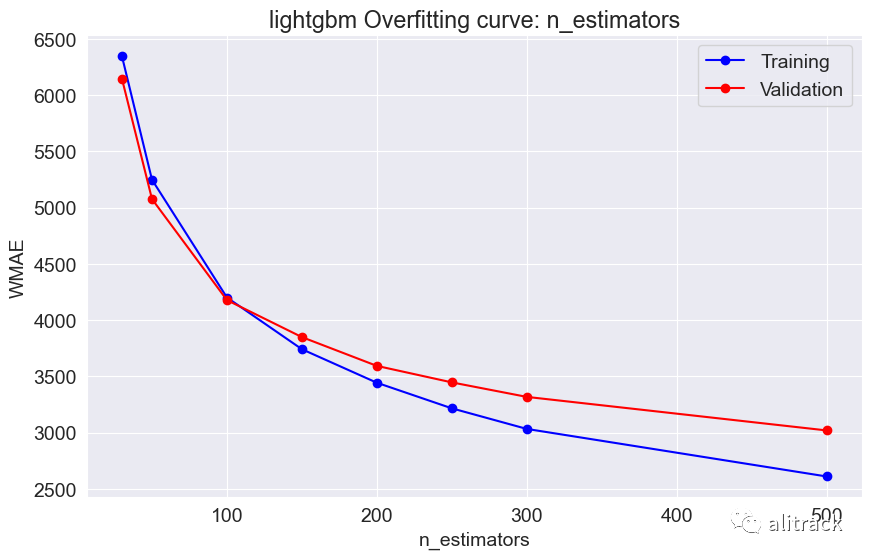
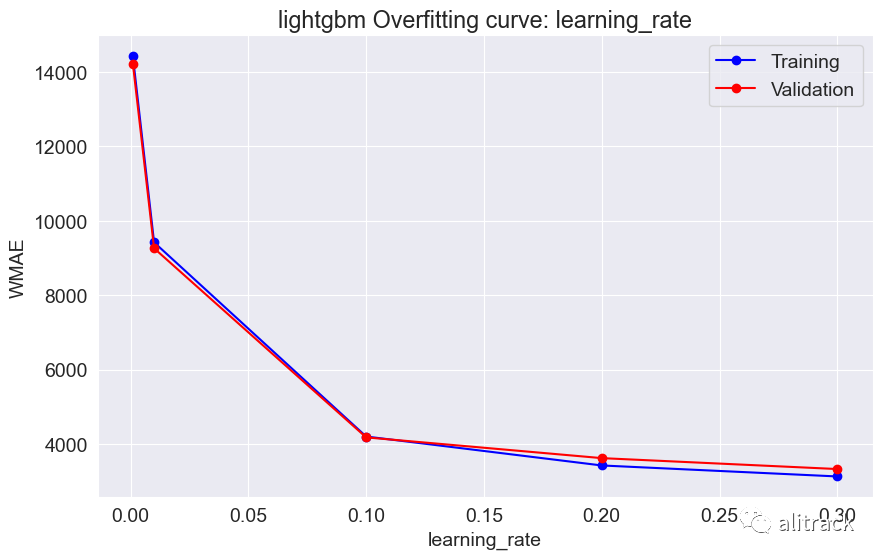
7. 模型选择
通过超参数调整,随机森林似乎效果最好 - 它提供了最佳的验证分数约为 2000。此外,我使用了 GridSearchCV 来获取最适合的随机森林和 XGBoost 模型。
from sklearn.model_selection import GridSearchCV,cross_val_score
model = RandomForestRegressor(random_state=42, n_jobs=-1)
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [10, 15, 20, 25, 30],
'min_samples_split': [2, 5, 10]
}
grid_search = GridSearchCV(model, param_grid, cv=5, scoring='neg_mean_absolute_error')
grid_search.fit(X_train, train_targets)
best_model = grid_search.best_estimator_
scores = cross_val_score(best_model, X_train, train_targets, cv=5, scoring='neg_mean_absolute_error')
wmae_scores = -scores
print("Cross-validation WMAE scores: ", wmae_scores)
print("Mean WMAE: ", np.mean(wmae_scores))
best_model.fit(X_train, train_targets)
print("Validation WMAE")
rf_val_wmae = weighted_mean_absolute_error(val_targets, best_model.predict(X_val), val_weights)
Cross-validation WMAE scores: [2084.20588859 1801.3954088 2289.6250968 1807.34656699 2494.84223194]
Mean WMAE: 2095.483038623421
Validation WMAE
rf_val_wmae
1984.7730360508367
xgb_model = XGBRegressor(random_state=42, n_jobs=-1)
xgb_param_grid = {
'learning_rate': [0.1, 0.01, 0.001],
'max_depth': [3, 5, 7],
'n_estimators': [100, 200, 300],
'reg_alpha': [0, 0.1, 0.5],
'reg_lambda': [0, 0.1, 0.5]
}
grid_search = GridSearchCV(xgb_model, xgb_param_grid, cv=5, scoring='neg_mean_absolute_error')
grid_search.fit(X_train, train_targets)
xgb_best_model = grid_search.best_estimator_
scores = cross_val_score(xgb_best_model, X_train, train_targets, cv=5, scoring='neg_mean_absolute_error')
xgb_mae_scores = -scores
print("Cross-validation MAE scores:", xgb_mae_scores)
print("Mean MAE:", np.mean(xgb_mae_scores))
xgb_best_model.fit(X_train, train_targets)
print("Validation WMAE")
xgb_val_wmae = weighted_mean_absolute_error(val_targets, xgb_best_model.predict(X_val), val_weights)
Cross-validation MAE scores: [2935.79216268 2625.76383495 3001.69304197 2738.494869 3179.13154636]
Mean MAE: 2896.175090991595
Validation WMAE
2820.2727876636172
xgb_val_wmae
2820.2727876636172
保存训练好的模型
我们可以将训练好的模型的参数(权重和偏差)保存到磁盘上,这样我们就无需每次使用模型时都从头开始重新训练。除了模型本身,保存填充器、缩放器、编码器甚至列名也很重要。任何在使用模型生成预测时需要的内容都应该被保存。
我们可以使用 joblib 模块来在磁盘上保存和加载 Python 对象。
import joblib
walmart_sales = {
'rf_model':best_model,
'xgb_model':xgb_best_model,
'imputer':imputer,
'scaler':scaler,
'encoder':encoder,
'input_cols':input_cols,
'target_cols':target_col,
'numeric_cols':numeric_cols,
'categorical_cols':categorical_cols,
'encoded_cols':encoded_cols
}
joblib.dump(walmart_sales, 'walmart/walmart_sales.joblib')
['walmart_sales.joblib']
8. Test Predictions and Submission
test_preds1 = best_model.predict(X_test)
test_preds2 = xgb_best_model.predict(X_test)
submission = pd.read_csv("walmart/sampleSubmission.csv.zip", header = 0)
submission['Weekly_Sales'] = test_preds2
submission.fillna(0, inplace=True)
submission.to_csv("walmart/submission.csv", index=None)
从不同的提交中,随机森林是表现最好的模型,参数设置为 n_estimators = 200 和 max_depth = 25。公共得分约为 4000,使我进入了比赛提交的前 50%。
总结与结论
在这个机器学习项目中,我利用了沃尔玛商店的历史销售数据,基于为期 3 年的数据预测了每周的销售情况。由于我们想要预测一个连续变量,这是一个回归问题的例子。以下是执行的步骤:
从 Kaggle 下载了数据集 进行数据清理和预处理(合并、检查空值) 进行特征工程 - 在数据集上应用新的日期时间、降价和假期特征 执行探索性数据分析 - 检查与每周销售相关的趋势 为模型训练准备数据 - 划分训练和验证集,识别数值和分类列,进行缩放、填充和编码 训练了几个线性模型,但不幸的是它们效果不佳 随后训练了集成模型,其中表现最好的三个模型是随机森林、XGBoost 和 LightGBM 进行超参数调整以获得最佳拟合值 在执行网格搜索后选择了模型 表现最佳的模型是随机森林
这个项目使我跻身 Kaggle 提交的前 50%。排名靠前的提交采用了 ARIMA 和时间序列技术来训练模型。通过采用时间序列分析技术,这个项目可以得到改进。
References & Inspiration
https://jovian.com/learn/zero-to-data-analyst-bootcamp/lesson/decision-trees-and-random-forests https://jovian.com/learn/zero-to-data-analyst-bootcamp/lesson/how-to-approach-machine-learning-problems https://jovian.com/learn/zero-to-data-analyst-bootcamp/lesson/gradient-boosting-machines-with-xgboost ChatGPT
参考资料
这里: https://www.kaggle.com/competitions/walmart-recruiting-store-sales-forecasting
