




为什么要升级
版本特性:一年一个大版本,三个月一个小版本
9.4支持 jsonb
9.6 支持并行
10 支持逻辑复制和声明分区
11 支持jit 、存储过程
14 引入 idle_session_timeout
15 逻辑复制有大幅度提升
16 支持standby logical replication ,并行回放, 以及 libpq的负载均衡
查软件生命周期的网址
https://endoflife.date/
比如 各版本数据库

各版本对比网址
https://why-upgrade.depesz.com/metainfo
比如16版本升级到16.1 有哪些不一样的地方
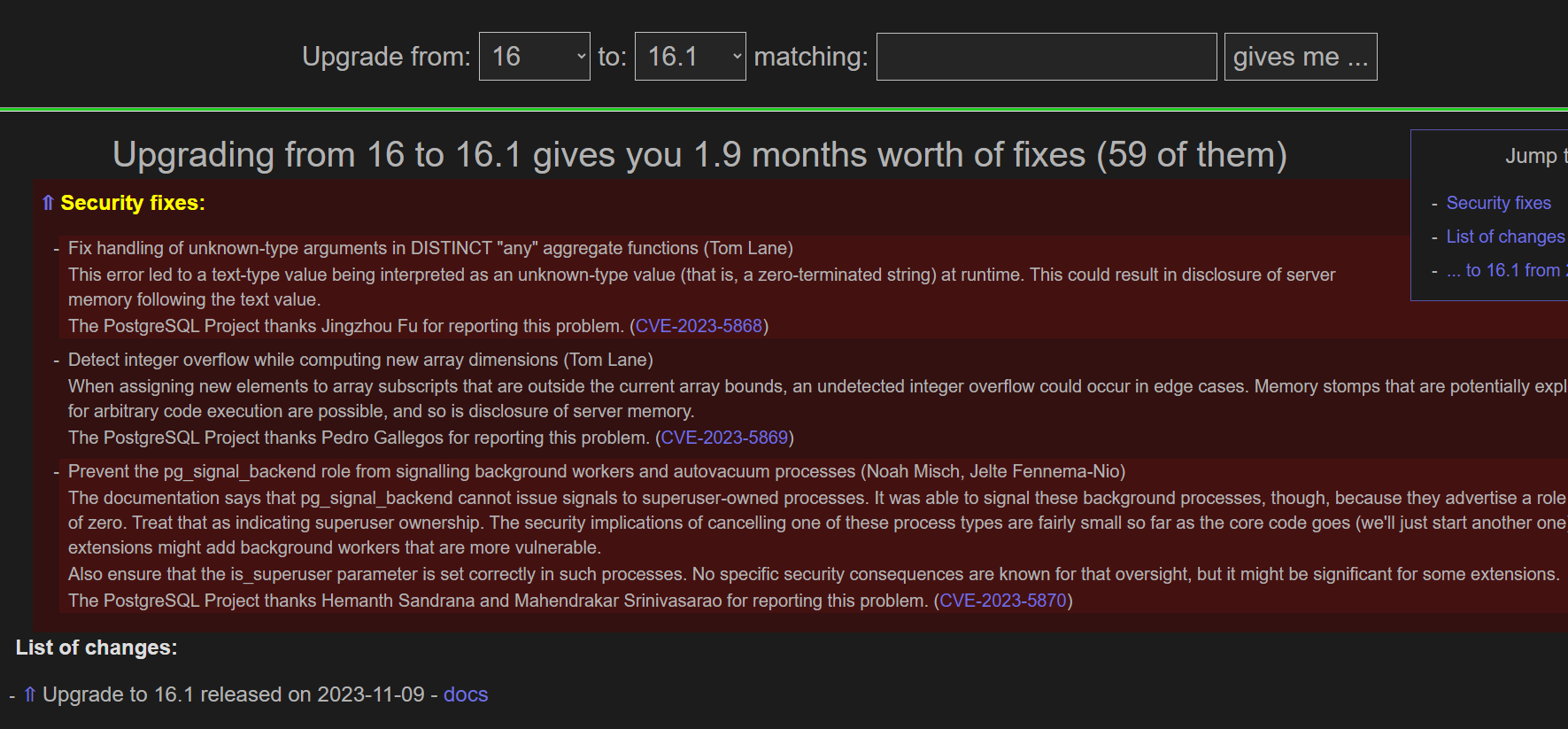
小版本升级
小版本升级不改变存储结构,可以直接替换二进制文件进行升级
数据库升级分为两种,一种是小版本迭代升级,另一种是主版本升级。PostgreSQL 版本号由主要版本和次要版本组成。例如,PostgreSQL 12.4 中的 12 是主要版本,4 是次要版本;PostgreSQL
10.0 之前的版本由 3 个数字组成,例如 9.6.19,其中 9.6 是主要版本,19 是次要版本。
Starting with PostgreSQL 10, a major version is indicated by increasing the first part of the version, e.g. 10 to 11. Before PostgreSQL 10, a major version was indicated by increasing
either the first or second part of the version number, e.g. 9.5 to 9.6.Minor releases are numbered by increasing the last part of the version number. Beginning with PostgreSQL 10, this
is the second part of the version number, e.g. 10.0 to 10.1; for older versions this is the third part of the version number, e.g. 9.5.3 to 9.5.4.
小版本升级不会改变内部的存储格式,因此总是和大版本兼容。例如,PostgreSQL 12.4 和 PostgreSQL 12.0 以及后续的 PostgreSQL 12.x 兼容。对于这些兼容版本的升级非常简单,只需要关闭数据库服务,安装替换二进制的可执行文件,重新启动服务即可。小版本一般主要为了修复BUG。比如14.0~14.3的一个索引大BUG
大版本升级
官方提供三种大版本升级方案
\1. Upgrading Data via pg_dumpall,使用 pg_dumpall / pg_restore 进行升级
\2. Upgrading Data via pg_upgrade,使用 pg_upgrade 进行升级
\3. Upgrading Data via Replication,使用逻辑复制进行升级
当然,还可以进行一下引申:
\1. pg_dump
\2. pg_dumpall
\3. pg_dumpall + pg_dump组合拳
\4. pg_upgrade
\5. 大于PostgreSQL 10: Logical replication
\6. 小于PostgreSQL 10: pglogical, Slony, Londiste, and Bucardo.
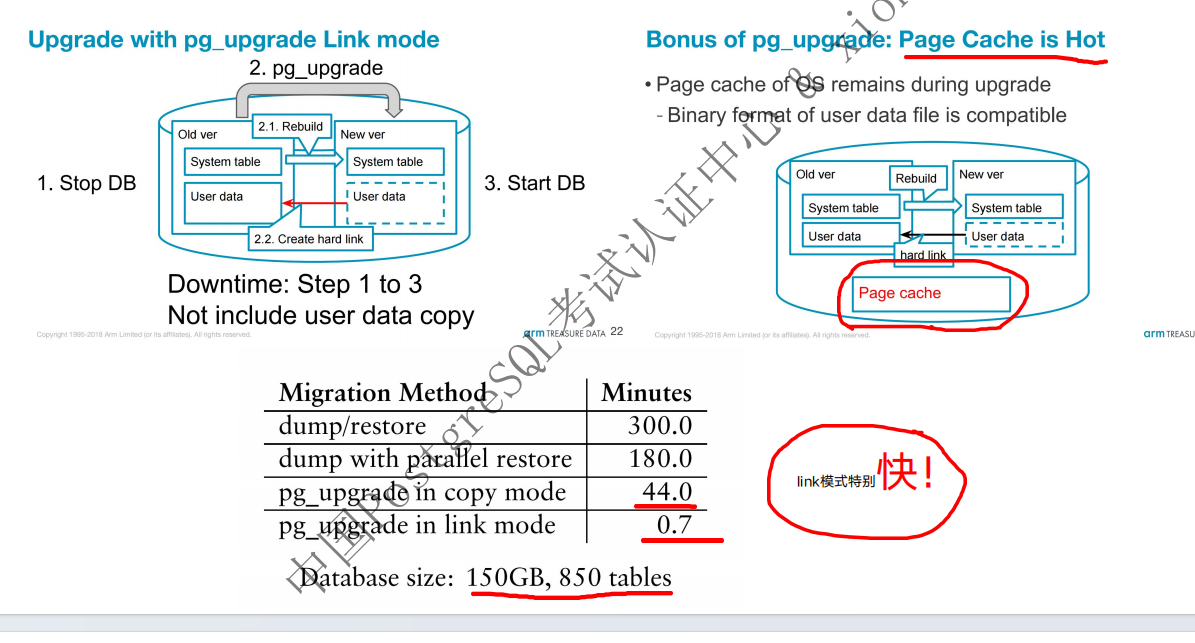
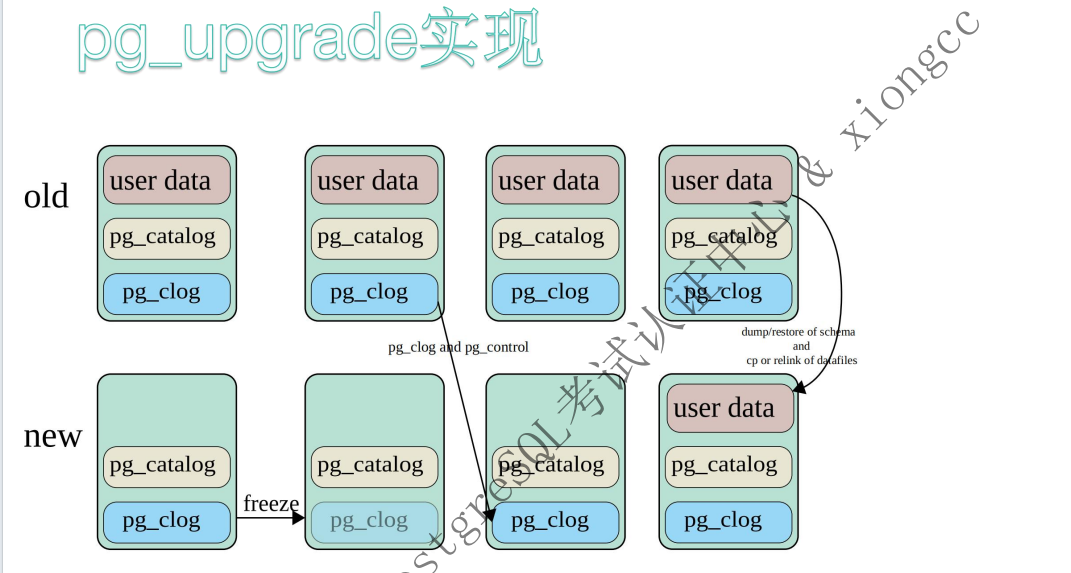
pg_upgrade升级原理
大概架构
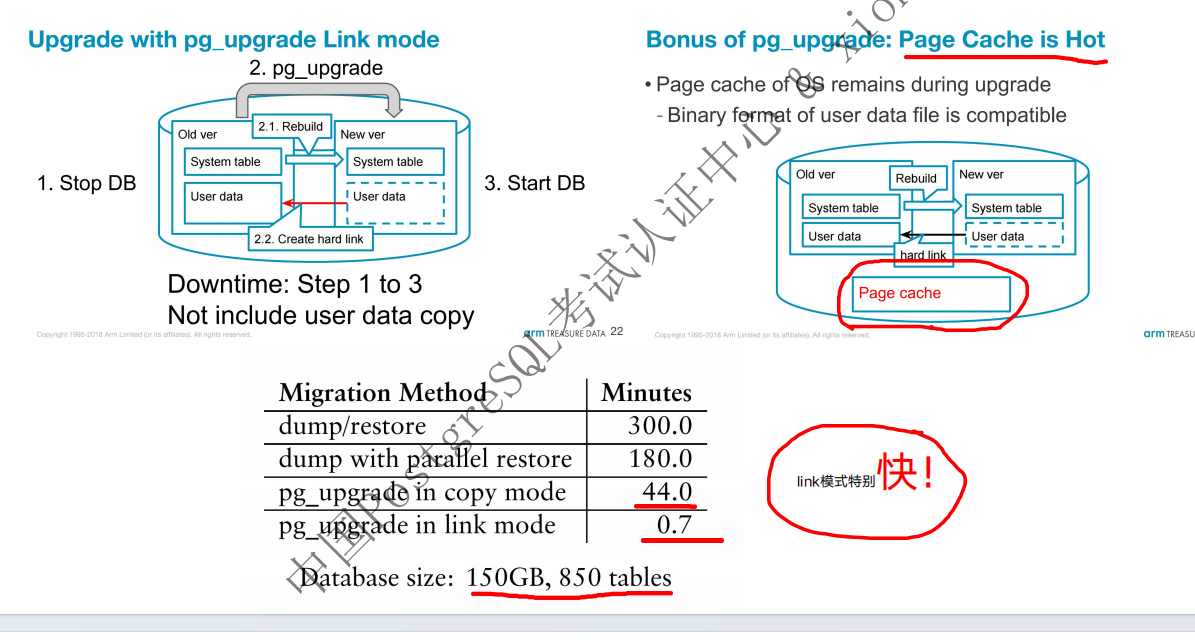
详细解释

细节图
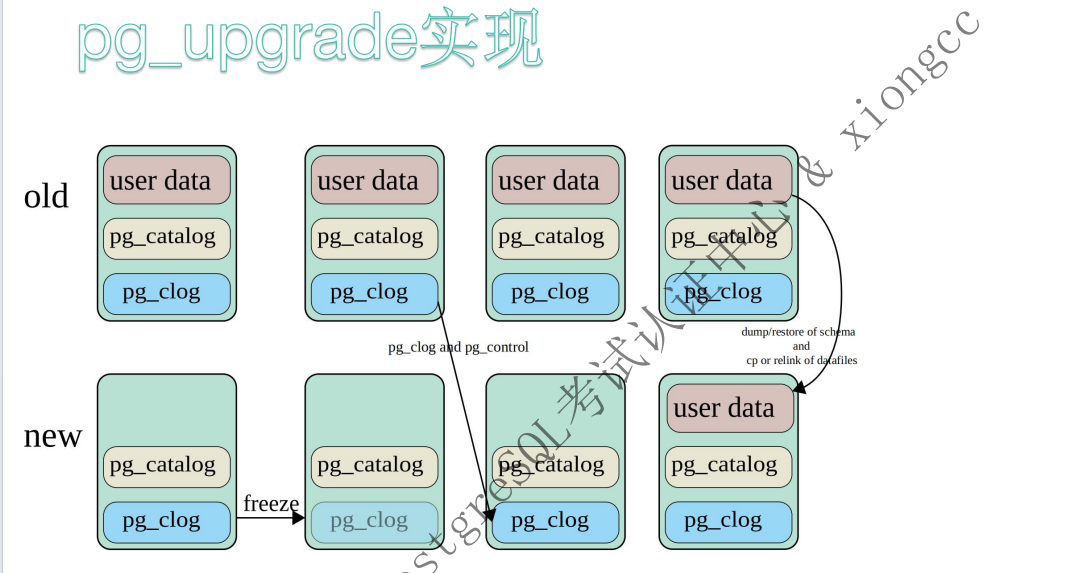
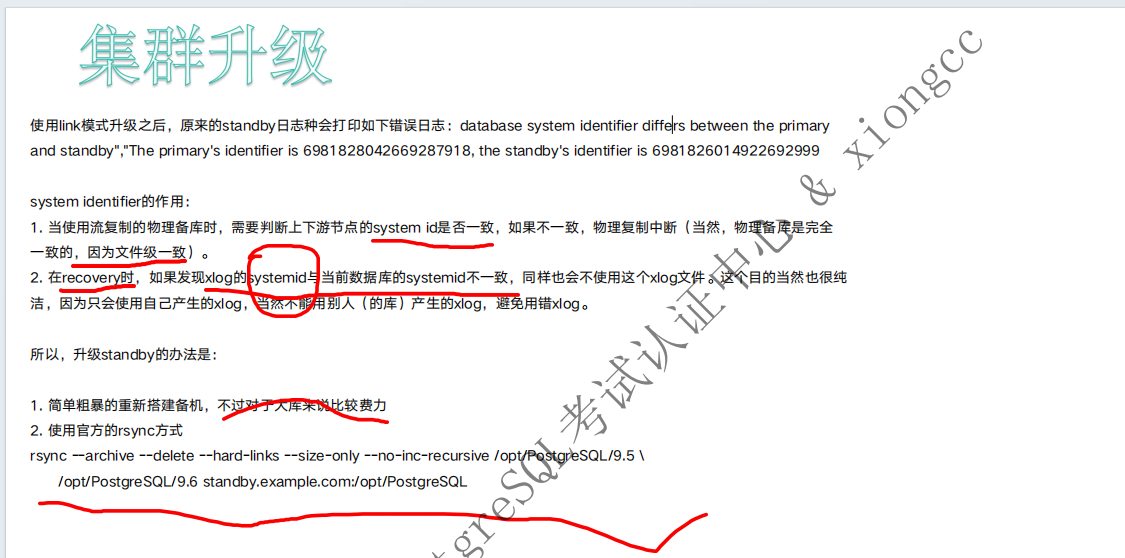
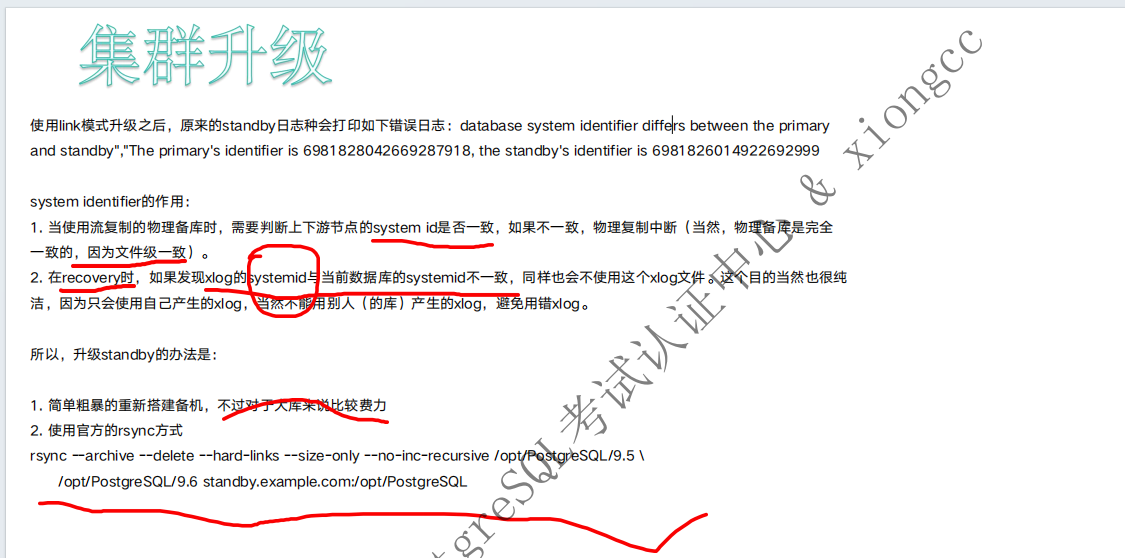
集群升级需要注意事项
1.升级后从库需要重新搭建
升级方式对比
1. dump/dumpall + restore/psql:由于dump+restore总体相对耗时较长,因此不适用于大数据量的数据库,或是写入比较频繁的场景使用。尤其是对于核心的业务程序(特别是有99.999
保证的程序)来说是不可接受的,好处就是十分安全,当然也可以不停机,使用逻辑复制搭配decoder_raw等Plugins解析出备份之后的操作SQL,不过不能保证一致性。
2. pg_upgrade:此方案优势是速度非常快,搭配并行和link模式,pg_upgrade –link –jobs xxx,但是必须停机升级,并且link模式,会无法使用以前的版本,因此不适用于7x24的场景,
若使用默认模式,就地升级会导致磁盘使用率增倍,好处就是源端还可以用,同时假如还有standby或者流复制的场景下,可能还会丢失备库,可以使用官方推荐的rsync模式。同时值得注意
的是,升级过程目前不会复制数据分布的任何统计数据,比如像直方图、最常见的值及其频率之类的东西,所以这也是“vacuumdb –analyze-only –analyze-in-stage”的重要性,不然复
杂查询的性能会受到相当大的影响,还有就是make 、configure编译的参数得保持一致
3. 逻辑复制:此方案是最平滑的方案,比较适用于7x24小时以及大数据量场景,停机时间非常短,只有几秒钟,同时源端和目标端升级之后假如有需求,还是可以使用的。但是配置繁琐,尤
其是v10以前的版本,还没有原生逻辑复制,需要第三方扩展,第三方扩展除了问题还是黑盒,增加了运维成本,同时还要有集群环境,但是原生逻辑复制又不支持序列、DDL(搭配插件
pg_ddl_deploy,不过又回到了黑盒来了)、视图等等

练习题
1、
PG11引入的include index和multi column index的区别
可参考墨天轮文章,写的是真好,可以单独研究下
https://www.modb.pro/db/576632
2、
log_statement、log_min_duration_statements,记录日志的时机,即是SQL执行前记录日志,还是SQL执行完记录日志
log_statement
① 作用
控制记录SQL的类型,可选值为:
none:关闭(默认) ddl:DDL语句 mod:DDL和所有涉及数据修改的语句(DML、COPY FROM、PREPARE、EXECUTE等)。对于explain和explain analyze,如果后面的语句类型符合,也会被记录 all:所有语句 ② 记录时机
SQL语句解析成功后,执行前。因此即使设置为all,也不会记录有语法错误的语句(如果想记录,应该使用log_min_error_statement参数)。
③ 记录内容
记录SQL语句,包含参数,但不包含执行用户、主机名等信息,这些需要审计插件才有。
log_min_duration_statement
① 作用
记录超过指定执行时间阈值的SQL,可选值为:
-1:关闭(默认) 0:所有语句 正数:慢SQL阈值 ② 记录时机
SQL语句执行完成后,因此能记录到执行时间。
③ 记录内容
记录SQL语句、执行时间,但不包含参数。 对于使用扩展查询协议的客户端,对语法分析、绑定、执行每一步所花时间会独立记录。
同时符合两者的SQL会如何?
语句在解析完成后、执行开始前,即被记入日志(log_statement生效) 语句执行完成后,单独将duration记入日志(log_min_duration_statement生效),但不再重复记录语句 因此建议使用log_line_prefix记录PID或会话ID,避免duration和语句关联不上
https://blog.csdn.net/Hehuyi_In/article/details/89882474
3、
⑥ pg_timeout 插件,控制连接会话超过多少被cancel ?
pg_timeout has 2 specific GUC:
- pg_timeout.naptime: number of seconds for the dedicated backgroud worker to sleep between idle session checks (default value is 10 seconds)
- pg_timeout.idle_session_timeout: database session idle timeout in seconds (default value is 60 seconds)
Note that pg_timeout only takes care of database session with idle status (idle in transaction is not taken into account).
为什么要升级
版本特性:一年一个大版本,三个月一个小版本
9.4支持 jsonb
9.6 支持并行
10 支持逻辑复制和声明分区
11 支持jit 、存储过程
14 引入 idle_session_timeout
15 逻辑复制有大幅度提升
16 支持standby logical replication ,并行回放, 以及 libpq的负载均衡
查软件生命周期的网址
https://endoflife.date/
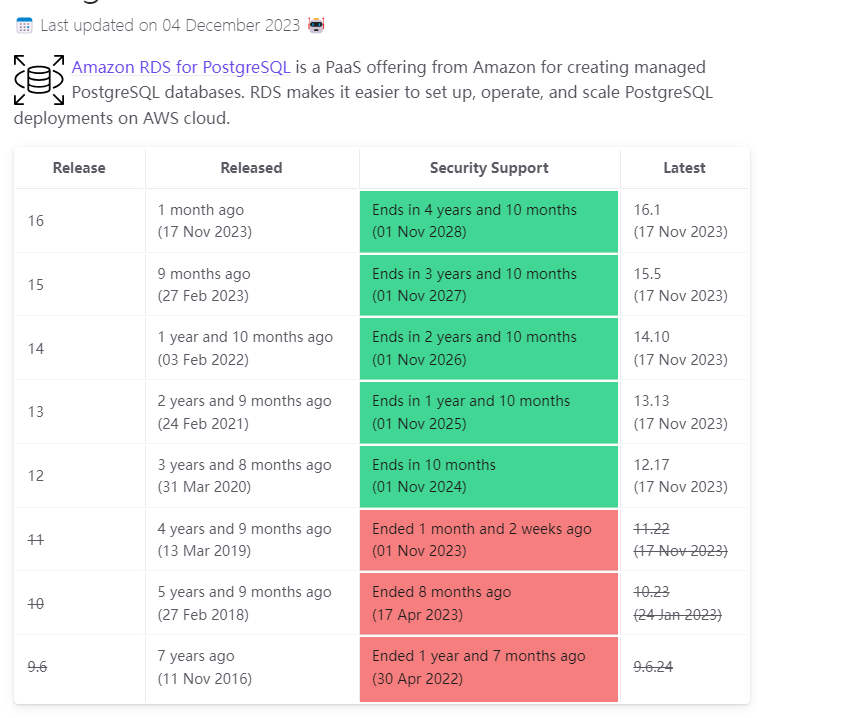
比如 各版本数据库
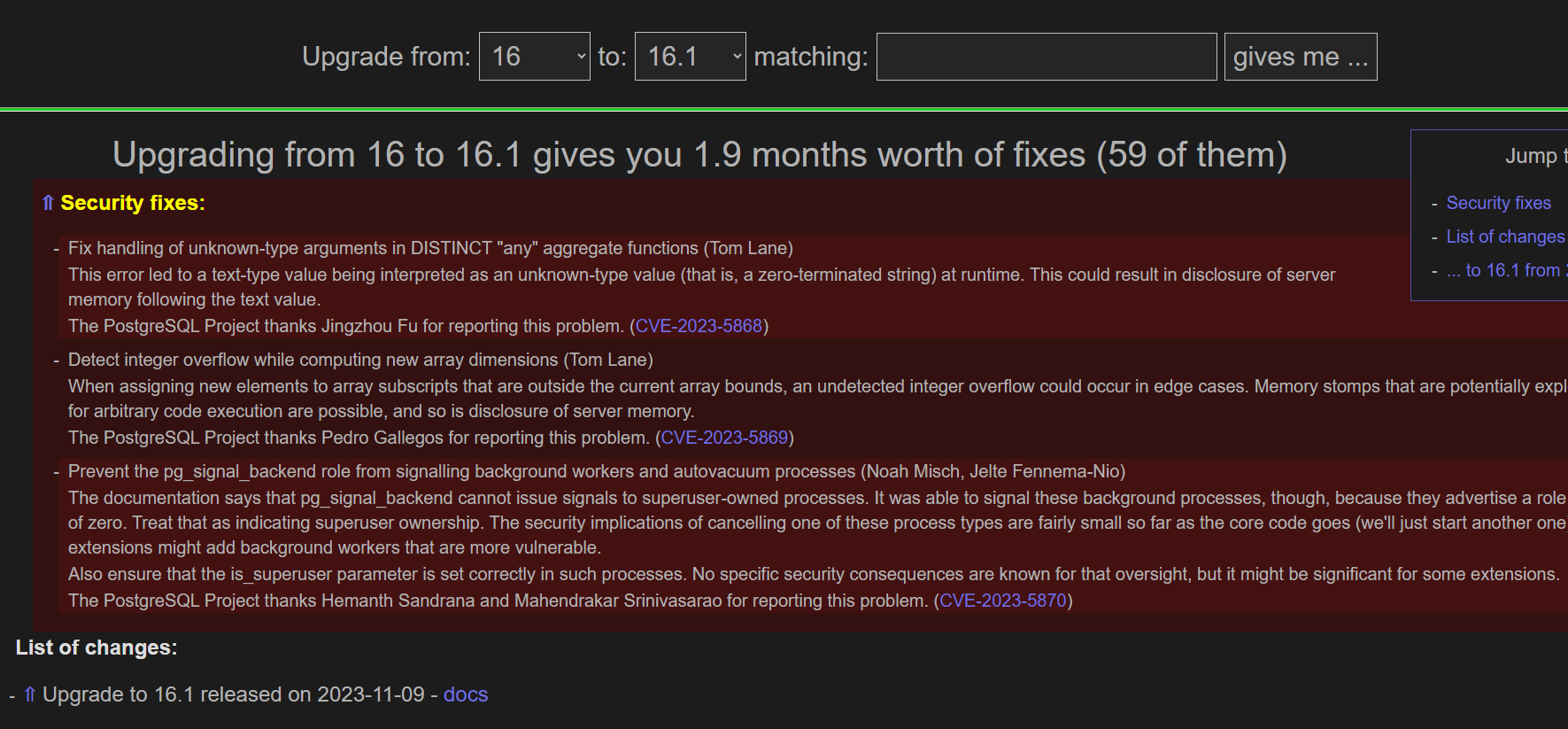
各版本对比网址
https://why-upgrade.depesz.com/metainfo
比如16版本升级到16.1 有哪些不一样的地方
小版本升级
小版本升级不改变存储结构,可以直接替换二进制文件进行升级
数据库升级分为两种,一种是小版本迭代升级,另一种是主版本升级。PostgreSQL 版本号由主要版本和次要版本组成。例如,PostgreSQL 12.4 中的 12 是主要版本,4 是次要版本;PostgreSQL
10.0 之前的版本由 3 个数字组成,例如 9.6.19,其中 9.6 是主要版本,19 是次要版本。
Starting with PostgreSQL 10, a major version is indicated by increasing the first part of the version, e.g. 10 to 11. Before PostgreSQL 10, a major version was indicated by increasing
either the first or second part of the version number, e.g. 9.5 to 9.6.Minor releases are numbered by increasing the last part of the version number. Beginning with PostgreSQL 10, this
is the second part of the version number, e.g. 10.0 to 10.1; for older versions this is the third part of the version number, e.g. 9.5.3 to 9.5.4.
小版本升级不会改变内部的存储格式,因此总是和大版本兼容。例如,PostgreSQL 12.4 和 PostgreSQL 12.0 以及后续的 PostgreSQL 12.x 兼容。对于这些兼容版本的升级非常简单,只需要关闭数据库服务,安装替换二进制的可执行文件,重新启动服务即可。小版本一般主要为了修复BUG。比如14.0~14.3的一个索引大BUG
大版本升级
官方提供三种大版本升级方案
\1. Upgrading Data via pg_dumpall,使用 pg_dumpall / pg_restore 进行升级
\2. Upgrading Data via pg_upgrade,使用 pg_upgrade 进行升级
\3. Upgrading Data via Replication,使用逻辑复制进行升级
当然,还可以进行一下引申:
\1. pg_dump
\2. pg_dumpall
\3. pg_dumpall + pg_dump组合拳
\4. pg_upgrade
\5. 大于PostgreSQL 10: Logical replication
\6. 小于PostgreSQL 10: pglogical, Slony, Londiste, and Bucardo.
pg_upgrade升级原理
大概架构
详细解释

细节图
集群升级需要注意事项
1.升级后从库需要重新搭建
升级方式对比
1. dump/dumpall + restore/psql:由于dump+restore总体相对耗时较长,因此不适用于大数据量的数据库,或是写入比较频繁的场景使用。尤其是对于核心的业务程序(特别是有99.999
保证的程序)来说是不可接受的,好处就是十分安全,当然也可以不停机,使用逻辑复制搭配decoder_raw等Plugins解析出备份之后的操作SQL,不过不能保证一致性。
2. pg_upgrade:此方案优势是速度非常快,搭配并行和link模式,pg_upgrade –link –jobs xxx,但是必须停机升级,并且link模式,会无法使用以前的版本,因此不适用于7x24的场景,
若使用默认模式,就地升级会导致磁盘使用率增倍,好处就是源端还可以用,同时假如还有standby或者流复制的场景下,可能还会丢失备库,可以使用官方推荐的rsync模式。同时值得注意
的是,升级过程目前不会复制数据分布的任何统计数据,比如像直方图、最常见的值及其频率之类的东西,所以这也是“vacuumdb –analyze-only –analyze-in-stage”的重要性,不然复
杂查询的性能会受到相当大的影响,还有就是make 、configure编译的参数得保持一致
3. 逻辑复制:此方案是最平滑的方案,比较适用于7x24小时以及大数据量场景,停机时间非常短,只有几秒钟,同时源端和目标端升级之后假如有需求,还是可以使用的。但是配置繁琐,尤
其是v10以前的版本,还没有原生逻辑复制,需要第三方扩展,第三方扩展除了问题还是黑盒,增加了运维成本,同时还要有集群环境,但是原生逻辑复制又不支持序列、DDL(搭配插件
pg_ddl_deploy,不过又回到了黑盒来了)、视图等等

练习题
1、
PG11引入的include index和multi column index的区别
可参考墨天轮文章,写的是真好,可以单独研究下
https://www.modb.pro/db/576632
2、
log_statement、log_min_duration_statements,记录日志的时机,即是SQL执行前记录日志,还是SQL执行完记录日志
log_statement
① 作用
控制记录SQL的类型,可选值为:
none:关闭(默认) ddl:DDL语句 mod:DDL和所有涉及数据修改的语句(DML、COPY FROM、PREPARE、EXECUTE等)。对于explain和explain analyze,如果后面的语句类型符合,也会被记录 all:所有语句 ② 记录时机
SQL语句解析成功后,执行前。因此即使设置为all,也不会记录有语法错误的语句(如果想记录,应该使用log_min_error_statement参数)。
③ 记录内容
记录SQL语句,包含参数,但不包含执行用户、主机名等信息,这些需要审计插件才有。
log_min_duration_statement
① 作用
记录超过指定执行时间阈值的SQL,可选值为:
-1:关闭(默认) 0:所有语句 正数:慢SQL阈值 ② 记录时机
SQL语句执行完成后,因此能记录到执行时间。
③ 记录内容
记录SQL语句、执行时间,但不包含参数。 对于使用扩展查询协议的客户端,对语法分析、绑定、执行每一步所花时间会独立记录。
同时符合两者的SQL会如何?
语句在解析完成后、执行开始前,即被记入日志(log_statement生效) 语句执行完成后,单独将duration记入日志(log_min_duration_statement生效),但不再重复记录语句 因此建议使用log_line_prefix记录PID或会话ID,避免duration和语句关联不上
https://blog.csdn.net/Hehuyi_In/article/details/89882474
3、
⑥ pg_timeout 插件,控制连接会话超过多少被cancel ?
pg_timeout has 2 specific GUC:
- pg_timeout.naptime: number of seconds for the dedicated backgroud worker to sleep between idle session checks (default value is 10 seconds)
- pg_timeout.idle_session_timeout: database session idle timeout in seconds (default value is 60 seconds)
Note that pg_timeout only takes care of database session with idle status (idle in transaction is not taken into account).
作者公众号:

