什么是目标检测?
在计算机视觉领域,目标检测是指识别和定位图像中各个个体对象的任务。 与图像分类不同:
图像分类的任务是确定图像中占主导地位的对象或场景 目标检测不仅对图像中存在的对象类别进行分类,还提供空间信息,绘制每个检测到的对象周围的边界框。
目标检测器还可以为每个检测输出一个“分数”(或“置信度”)。它表示根据模型的说法,检测到的对象属于每个边界框预测类别的概率。
例如,以下图像显示了五个检测结果:一个“球”置信度为98%,四个“人”置信度分别为98%、95%、97%和97%。

目标检测模型具有多种用途,可在各个领域广泛应用。一些用例包括自动驾驶中的视觉、人脸检测、监控和安全、医学影像、增强现实、体育分析、智能城市、手势识别等。
Hugging Face Hub有数百个在不同数据集上预训练的目标检测模型,能够识别和定位各种对象类别。
一种特定类型的目标检测模型称为零样本模型,可以接收额外的文本查询以搜索文本中描述的目标对象。与在训练期间使用的类别集合相比,这些模型可以检测到在训练期间未见过的对象。
检测器的多样性不仅限于它们能够识别的输出类别范围。它们在底层架构、模型大小、处理速度和预测准确性方面都有所不同。用于评估目标检测模型预测准确性的一种流行度量标准是平均精度(AP)及其变体。
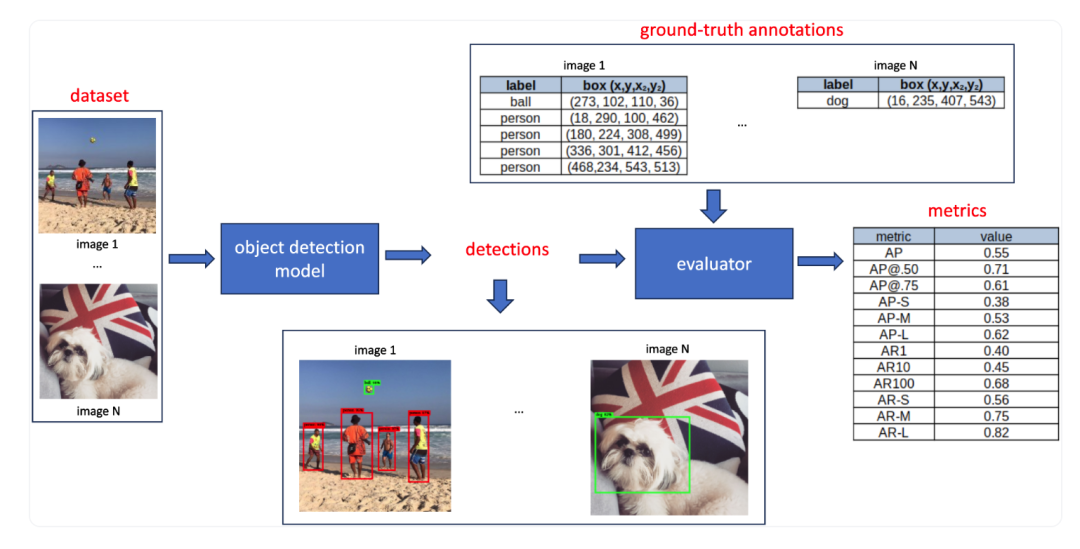
评估目标检测模型包括几个组件,如带有地面实况注释的数据集、检测结果(输出预测)和度量标准。这一过程在图2中提供的示意图中有所体现:
首先,选择一个包含带有地面实况边界框注释的基准数据集,并将其输入目标检测模型。模型为每个图像预测边界框,为每个框分配关联的类别标签和置信度分数。在评估阶段,将这些预测的边界框与数据集中的地面实况框进行比较。评估得出一组度量标准,每个度量标准的范围在[0, 1]之间,反映了特定的评估标准。在下一节,我们将详细介绍度量标准的计算过程。
评价指标
平均精度(Average Precision)
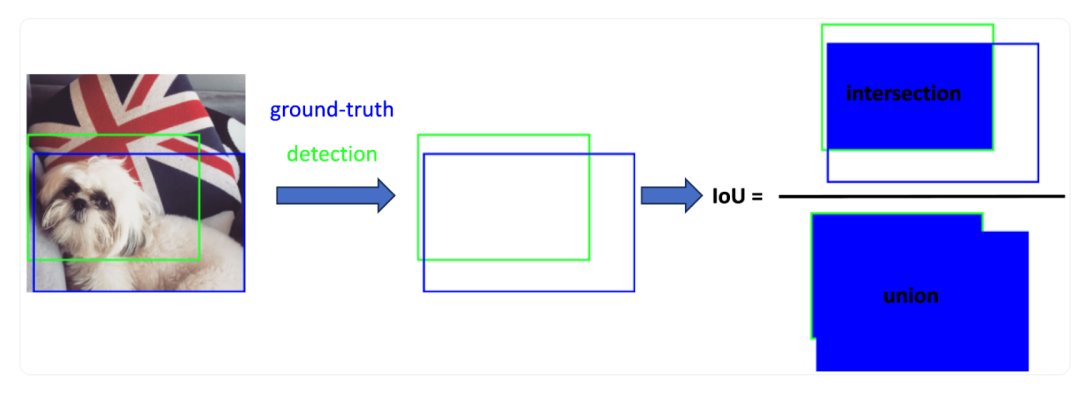
交并比是一个介于0和1之间的度量标准,用于衡量预测边界框与实际(地面实况)边界框之间的重叠程度。它通过将两个框重叠的区域除以两个框组合的总区域来计算。图3通过一个预测框及其相应的地面实况框的示例直观展示了IoU。
计算重叠区域: 计算预测框和地面实况框的重叠区域的面积。
计算总区域: 计算预测框和地面实况框组合的总区域的面积。
计算交并比: 将重叠区域的面积除以总区域的面积。
通过了解IoU的概念,我们可以将检测结果分类为以下两种情况:
True Positive(真正例): 如果检测的边界框与地面实况框的IoU大于等于预定阈值(通常为0.5),则将其视为真正例。
False Positive(假正例): 如果检测的边界框与所有地面实况框的IoU都低于预定阈值,则将其视为假正例。
平均精度(AP)计算示例
现在我们能够识别真正例(TP)、假正例(FP)和假负例(FN),我们可以定义精度(Precision)和召回率(Recall):
精度(Precision) 衡量模型只能识别相关对象的能力。它是正确正例预测的百分比,计算公式为:
其中,TP是真正例的数量,FP是所有检测的数量。
召回率(Recall) 表示模型找到所有相关实例(所有地面实况边界框)的能力。它表示在所有地面实况中检测到的TP的比例,计算公式为:
注意,TP、FP和FN取决于预定义的IoU阈值,精度和召回率也是如此。
平均精度(AP) 捕捉了模型在考虑不同精度和召回率值时正确分类和定位对象的能力。为了说明这一点,我们将通过绘制目标类别(例如“狗”)的精度-召回率曲线来阐述它们之间的关系。我们将采用适度的IoU阈值,例如75%,来确定我们的TP、FP和FN。随后,我们可以计算精度和召回率的值。为此,我们需要改变我们检测的置信度分数。
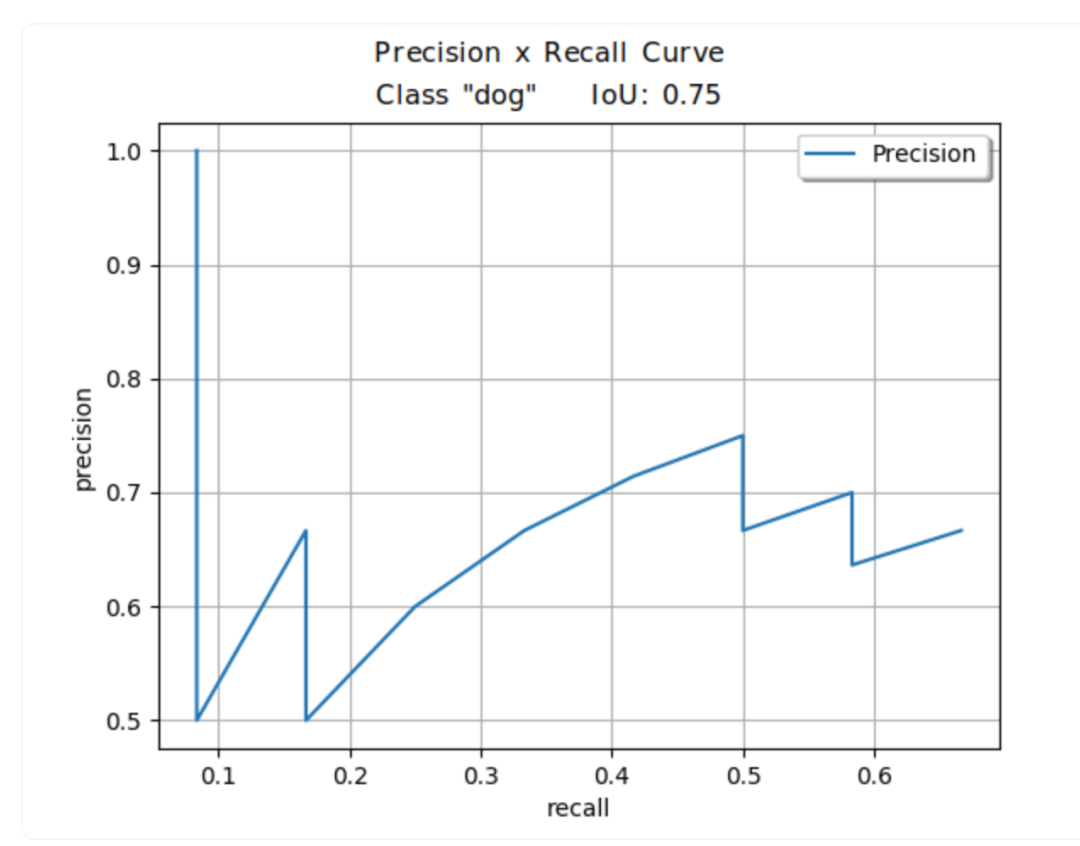
图4: 考虑IoU_thresh = 0.75,目标对象为“狗”时的精度-召回率曲线。精度-召回率曲线说明了基于检测器的边界框不同置信度水平的精度和召回率之间的平衡。绘图的每个点使用不同的置信度值计算。
为了演示如何计算平均精度图,我们将使用前面提到的论文中的一个实际例子。考虑一个包含15个相同类别的地面实况对象的7张图像的数据集,如图5 所示。为简化起见,我们假设所有框属于同一个类别,即“狗”。
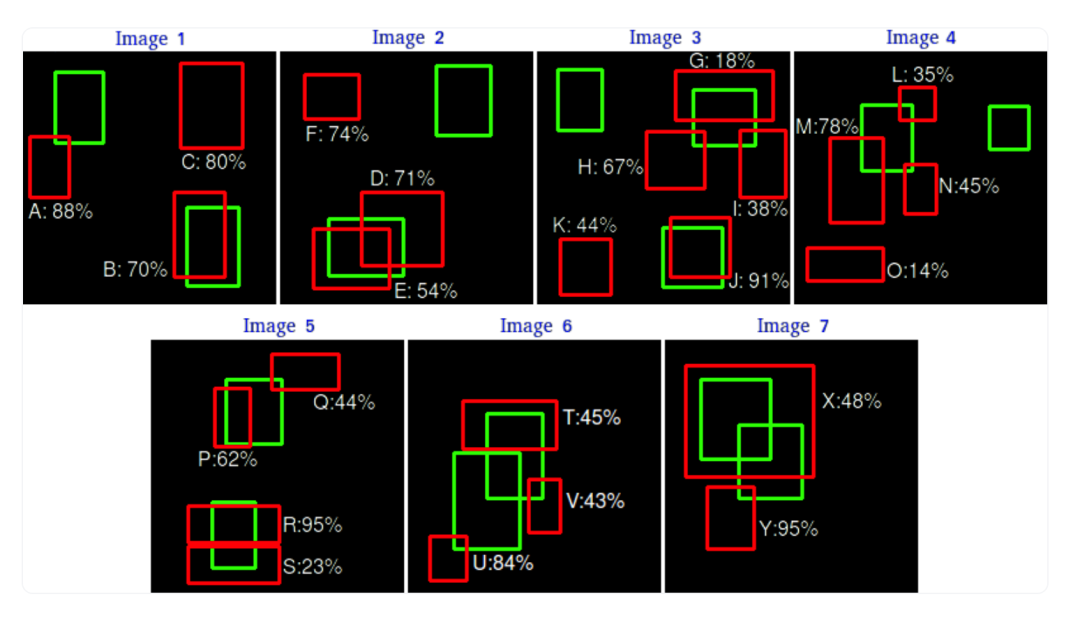
图5: 由一个目标检测器执行的24个检测(红色框),用于检测属于同一类别的15个地面实况对象(绿色框)的示例。
我们的假设目标检测器在数据集中检测到了24个对象,用红色框表示。为了计算精度和召回率,我们使用所有置信度水平上的精度和召回率方程,评估检测器在我们基准数据集上针对这一特定类别的性能。为此,我们需要建立一些规则:
规则1: 为简单起见,如果IoU ≥ 30%,我们将考虑我们的检测为真正例(TP),否则为假正例(FP)。
规则2: 对于检测与多个地面实况重叠的情况(如图2至图7所示),具有最高IoU的预测框被视为TP,另一个被视为FP。
计算精度和召回率
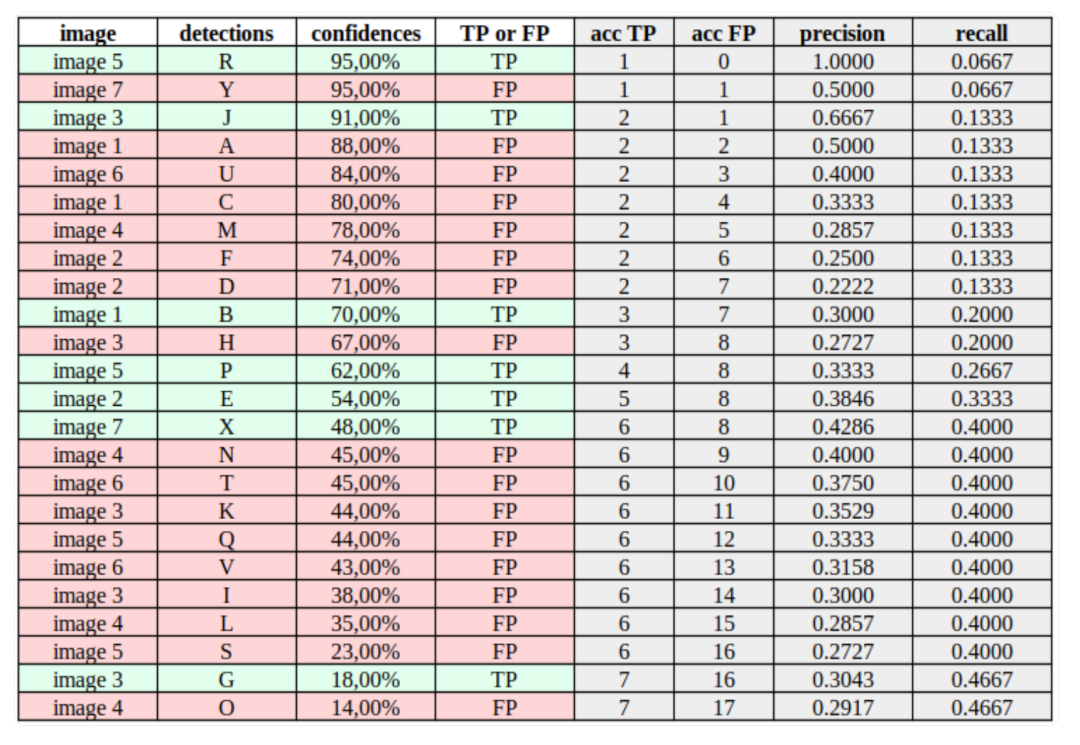
现在我们可以考虑每个检测的置信度值,计算表2中的精度和召回率。一种好的方法是按照置信度值对检测进行排序,如表2所示。然后,对于每一行中的每个置信度值,我们根据累积TP(累积真正例)和累积FP(累积假正例)计算精度和召回率。每行中的“acc TP”在记下一个TP时增加1,“acc FP”在记下一个FP时增加1。列“acc TP”和“acc FP”基本上告诉我们在特定置信水平下的TP和FP值。表2的每个值的计算可以在这个电子表格中查看。
以表2中的第12行(检测“P”)为例。值“acc TP = 4”表示如果我们在这个特定的数据集上以0.62的置信度进行基准测试,我们将正确检测到四个目标对象并错误检测到八个目标对象。这将导致:
和
表2: 表1中检测的精度和召回率值的计算。
现在,我们可以使用这些值绘制精度-召回率曲线,如图6 所示:
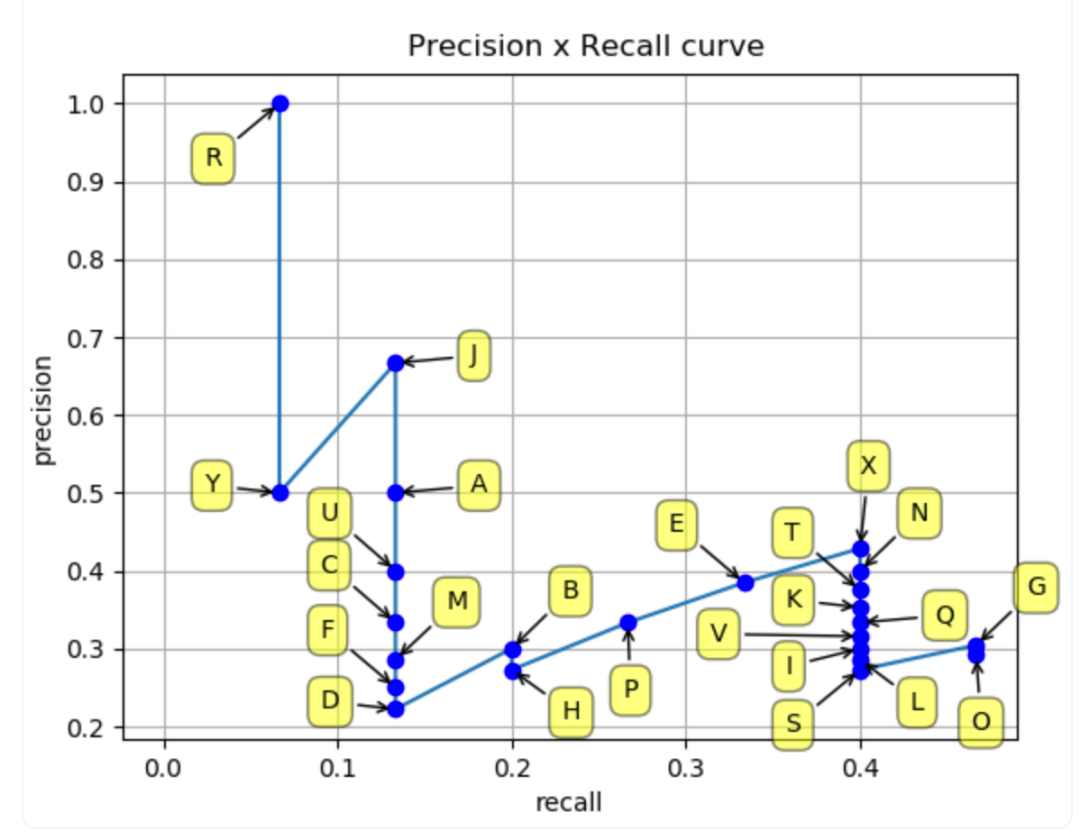
图6: 使用表2中计算的检测值的精度-召回率曲线。通过检查曲线,可以推断精度和召回率之间的潜在权衡,并在选择的置信度阈值基础上找到模型的最佳工作点,即使该阈值没有明确显示在曲线上。
如果检测器的置信度导致很少的假正例(FP),它可能具有较高的精度。然而,这可能会导致漏掉许多真正例(TP),从而导致较高的假负例(FN)率,随之而来的是较低的召回率。另一方面,接受更多的正例检测可能会提高召回率,但也可能会提高FP计数,从而降低精度。
精度-召回率曲线下的面积(AUC)计算为特定类别的平均精度值。COCO评估方法将“AP”称为图像数据集中所有目标类别的平均AUC值,其他方法称之为平均平均精度(mAP)。
对于大型数据集,检测器可能会输出具有广泛置信度水平的框,导致锯齿状的精度-召回率线,使得精确计算其AUC(平均精度)变得具有挑战性。不同的方法用不同的方式估算曲线的面积。一种常用的方法称为N插值,其中N表示从精度-召回率蓝线中采样了多少个点。
例如,COCO方法使用101插值,它计算了等间距召回值(0.,0.01,0.02,… 1.00)的101个点,而其他方法使用11个点(11插值)。图7 说明了使用11插值方法的精度-召回率曲线。
图7: 使用11插值方法的精度-召回率曲线的示例。11个红点是使用精度和召回率方程计算的。红点根据以下公式放置:
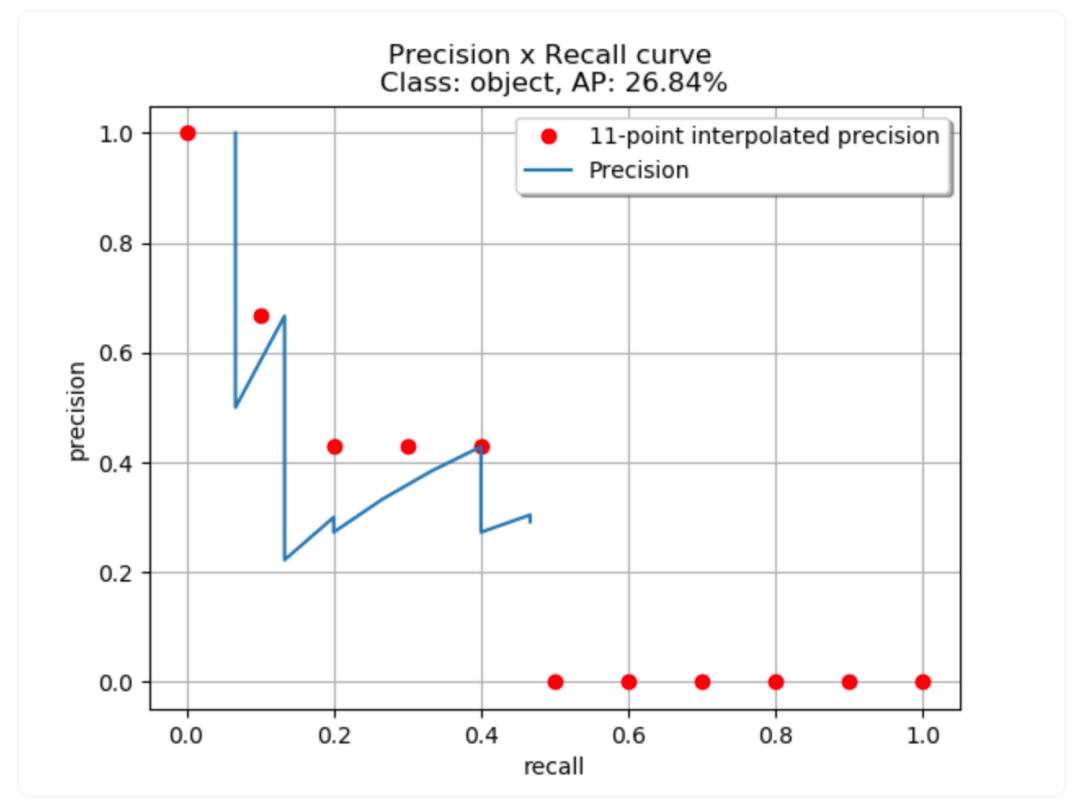
其中 是在每个召回水平 观察到的精度。
平均召回(Average Recall)
平均召回(AR)是经常与平均精度(AP)一起使用的指标,用于评估目标检测模型。虽然AP通过评估不同置信度阈值下的精度和召回率,提供了模型性能的单一数字摘要,但AR专注于召回率方面,不考虑置信度,并将所有检测视为正例。
COCO的方法计算AR作为在IOU > 0.5和类别上获得的召回率的平均值。
通过在范围[0.5, 1]的IOU上计算并平均召回率值,AR评估了模型对其目标定位的预测。因此,如果您的目标是评估模型在高召回率和精确目标定位方面的性能,AR可能是一个有价值的评估指标。
计算方法:
设定IOU阈值范围: 通常,在[0.5, 1]范围内设定IOU阈值。
对于每个IOU阈值,计算召回率: 使用给定的IOU阈值,在所有类别和所有图像上计算召回率。
取平均: 对所有IOU阈值下的召回率值取平均,得到平均召回率(AR)。
公式表示为:
其中, 是使用的IOU阈值的数量, 是在第 个IOU阈值下的召回率。
平均召回率(AR)提供了一个综合考虑模型在不同IOU阈值下的召回表现的指标,而不考虑置信度。
平均精度和平均召回的变体
根据预定义的IoU阈值和与地面实况对象相关的区域,可以得到不同版本的平均精度(AP)和平均召回(AR):
平均精度的变体:
AP@0.5: 将IoU阈值设置为0.5,计算图像数据集中每个目标类别的精度-召回率AUC。然后,将每个类别的计算结果相加并除以类别的数量。 AP@0.75: 使用与AP@0.5相同的方法,IoU阈值为0.75。由于这个更高的IoU要求,AP@0.75被认为比AP@0.5更严格,应用于需要在检测中实现高水平定位准确性的模型的评估。 AP@[0.5:0.05:0.95]: 也称为cocoeval工具中的AP。这是AP@0.5和AP@0.75的扩展版本,因为它使用不同的IoU阈值(0.5、0.55、0.6、...、0.95)计算AP@,并将计算结果平均,如下方程所示。与AP@0.5和AP@0.75相比,这个指标提供了全面的评估,捕捉模型在更广泛的定位准确性范围内的性能。
AP-S: 应用于小(small)地面实况对象,其面积小于322个像素。 AP-M: 应用于中等大小(medium-sized)的地面实况对象,其面积在322到962个像素之间。 AP-L: 应用于大(large)地面实况对象,其面积在962个像素以上。
对于平均召回(AR),使用10个IoU阈值(0.5、0.55、0.6、...、0.95)计算召回率值。AR可以通过限制每个图像的检测数量或基于对象的区域来计算。
AR-1: 每张图像考虑最多1个检测。 AR-10: 每张图像考虑最多10个检测。 AR-100: 每张图像考虑最多100个检测。 AR-S: 考虑小(small)对象,其面积小于322个像素。 AR-M: 考虑中等大小(medium-sized)的对象,其面积在322到962个像素之间。 AR-L: 考虑大(large)对象,其面积大于962个像素。
目标检测排行榜
Hugging Face最近发布了目标检测排行榜,用于比较来自我们 Hub 的开源模型的准确性和效率。
https://huggingface.co/spaces/hf-vision/object_detection_leaderboard
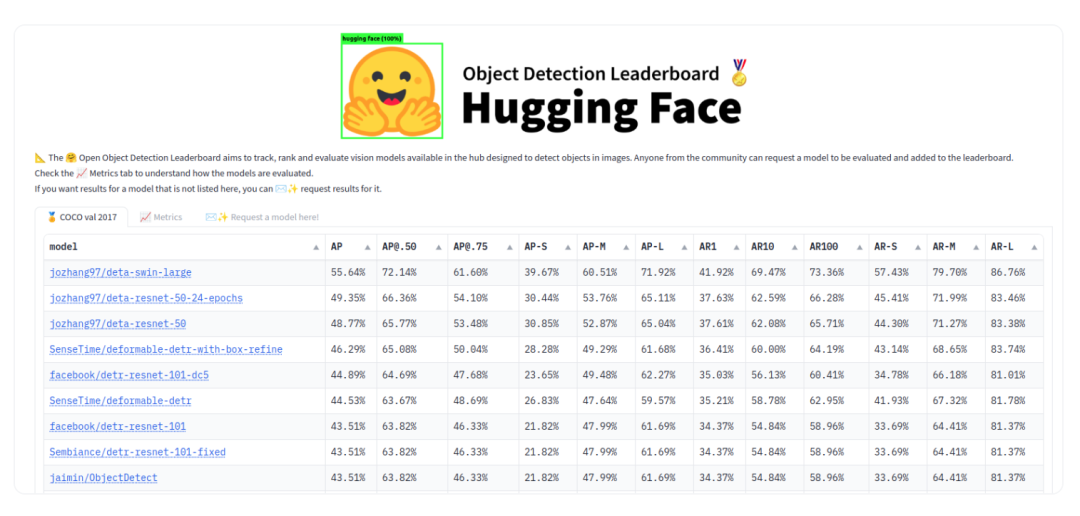
为了衡量准确性,我们使用了12个涉及COCO风格的平均精度和平均召回的度量标准,对COCO val 2017数据集进行基准测试。
正如之前讨论的,不同的工具在评估过程中可能采用不同的细节。为了防止结果不匹配,我们选择不实现我们版本的度量标准。相反,我们选择使用COCO的官方评估代码,也称为PyCOCOtools。
在效率方面,我们计算了每个模型的每秒帧数(FPS),使用整个数据集的平均评估时间,考虑到前后处理步骤。鉴于每个模型对GPU内存的要求存在变异性,我们选择以批量大小为1进行评估(这个选择也受我们的预处理步骤的影响,稍后我们将深入讨论)。然而,值得注意的是,这种方法可能无法完全符合实际性能,因为通常使用较大的批量大小(通常包含多个图像)以提高效率。
如何选择最佳模型?
选择适当的度量标准来评估和比较目标检测器考虑了多个因素。主要考虑因素包括应用程序的目的以及用于训练和评估模型的数据集特征。
对于一般性能,AP(AP@[.5:.05:.95])是一个不错的选择,如果您希望在不同IoU阈值下全面评估模型性能,而不对检测到的对象的定位有硬性要求。
如果您希望模型具有良好的对象识别能力,并且对象通常位于正确的位置,可以查看AP@0.5。 如果您更喜欢对边界框进行更准确的定位,AP@0.75更为合适。
如果您对对象大小有限制,那么AP-S、AP-M和AP-L就变得重要。例如,如果您的数据集或应用程序主要包含小对象,AP-S可以提供有关检测器在识别这些小目标方面的效果的见解。在诸如检测远处的车辆或医学成像中的小物件等场景中,这变得至关重要。