赛题名称:用户新增预测挑战赛 赛题类型:数据挖掘 赛题任务:基于提供的样本构建模型,预测用户的新增
比赛地址:https://challenge.xfyun.cn/topic/info?type=subscriber-addition-prediction
视频答辩地址:https://www.bilibili.com/video/BV1nb4y1T7kr?p=47
赛事背景
讯飞开放平台针对不同行业、不同场景提供相应的AI能力和解决方案,赋能开发者的产品和应用,帮助开发者通过AI解决相关实际问题,实现让产品能听会说、能看会认、能理解会思考。
用户新增预测是分析用户使用场景以及预测用户增长情况的关键步骤,有助于进行后续产品和应用的迭代升级。
赛事任务
本次大赛提供了讯飞开放平台海量的应用数据作为训练样本,参赛选手需要基于提供的样本构建模型,预测用户的新增情况。
赛题数据由约62万条训练集、20万条测试集数据组成,共包含13个字段。其中uuid为样本唯一标识,eid为访问行为ID,udmap为行为属性,其中的key1到key9表示不同的行为属性,如项目名、项目id等相关字段,common_ts为应用访问记录发生时间(毫秒时间戳),其余字段x1至x8为用户相关的属性,为匿名处理字段。target字段为预测目标,即是否为新增用户。
评审规则
本次竞赛的评价标准采用f1_score,分数越高,效果越好。
优胜方案
第一名
比赛方案主要采用了决策树和神经网络两种方法。队伍由三名队员组成。赛题要求预测新增用户,是一个二分类问题,使用F1评价指标。
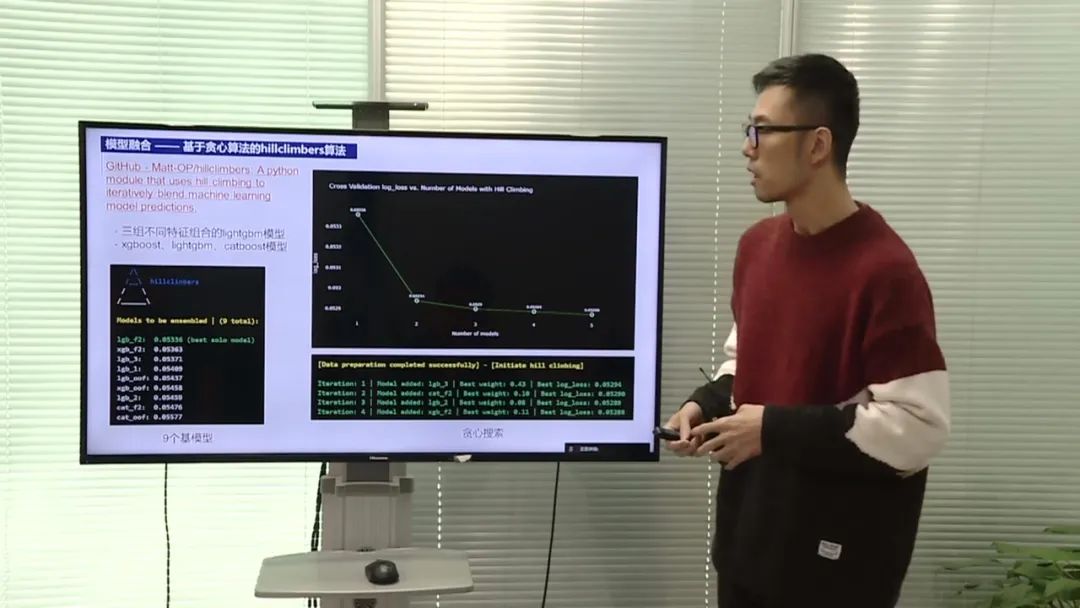
特征工程
在特征工程方面,首先对原始特征进行简单处理,如将行为ID和用户属性进行类目化,将访问时间进行时间特征提取。然后考虑用户特征,将所有用户属性拼接成一个粗用户标志,并对其进行分段处理,得到用户标志。然后提取统计特征,包括用户标志和行为属性等,进行排列组合,得到约1200个特征。

模型选择
对于模型选择,使用了决策树和神经网络两种方法。对于决策树,使用了四个模型,最后进行嫁接得到最终结果。对于神经网络,对ID特征进行嵌入处理,对数值特征进行归一化处理,然后将两组输出进行合并,得到神经网络的输出。最后将T2型人决策术和神经网络的输出进行集成,得到最终预测结果。

实验结果
在实验中,使用了线下测试进行特征和参数的调整,每次在线下测试上有提升后再应用到线上。最终取得了0.9369的成绩,排名第一。

对于进一步的提升,可以考虑简化方案,删除作用不大或有副作用的模型或特征;寻找比赛之外的数据加入特征提取;考虑是否有更合适的评价指标;对模型进行优化,合并同类模型,集中有效特征等。
第二名

图网络思路
比赛方案主要采用了图神经网络(GNN)的思想,通过将样本的用户属性进行组合,构建了一个图结构。 每个样本被视为图中的一个节点,通过连接不同节点构建了边,并根据样本的发生时间计算了边的距离。利用特征传递和标签传递的方式,将邻居节点的特征和标签传递给目标节点进行学习,从而获得了图特征。

其中,标签传递是最重要的部分,通过定义一个标签传播的公式,将样本的标签转换为-1和1,并根据时间差计算时间权重,将转换后的标签乘以时间权重与邻居节点的标签成权重相加,构建出新的特征。通过调整公式中的参数,可以得到不同的特征重要性。
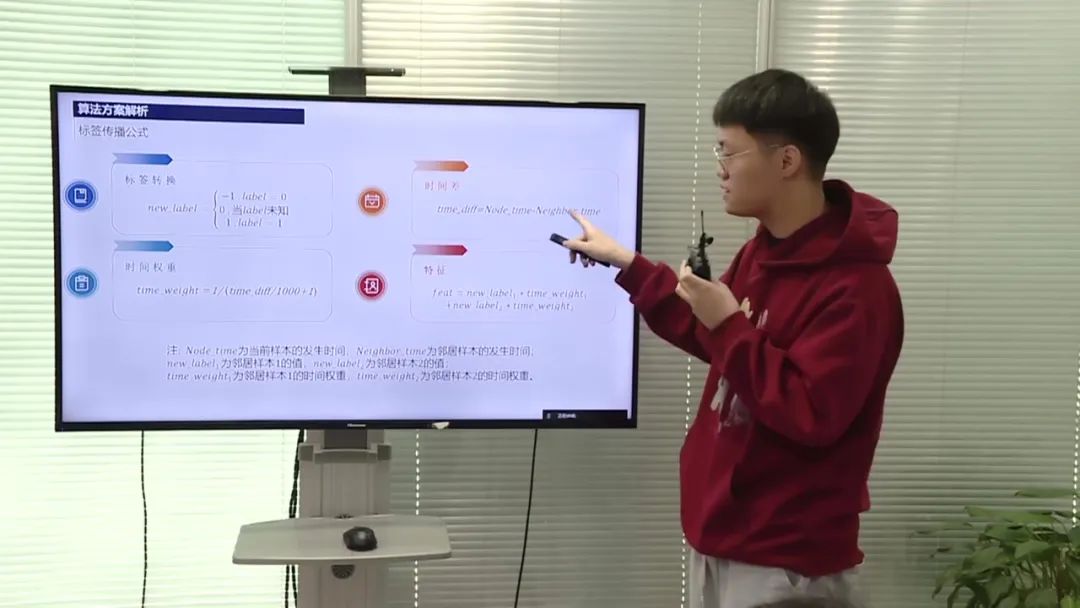
自定义特征
比赛方案还针对行为ID(EID)这个类别特征,使用了Catapult模型进行处理,通过有序标签编码挖掘EID背后的信息,得到与LightGBM模型结果差异较大的结果,以提升模型融合的效果。
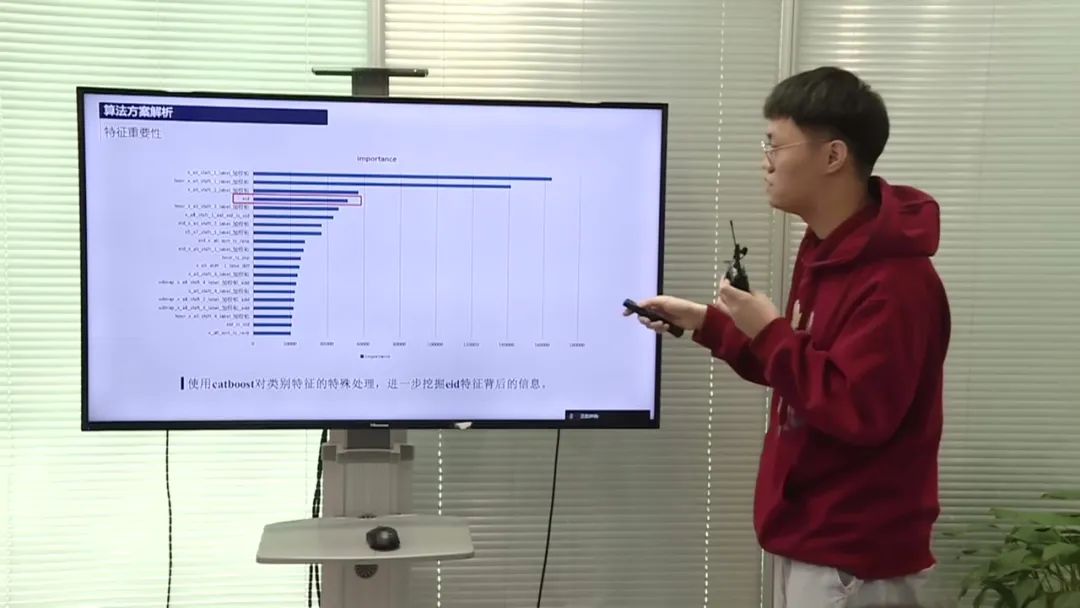
模型融合
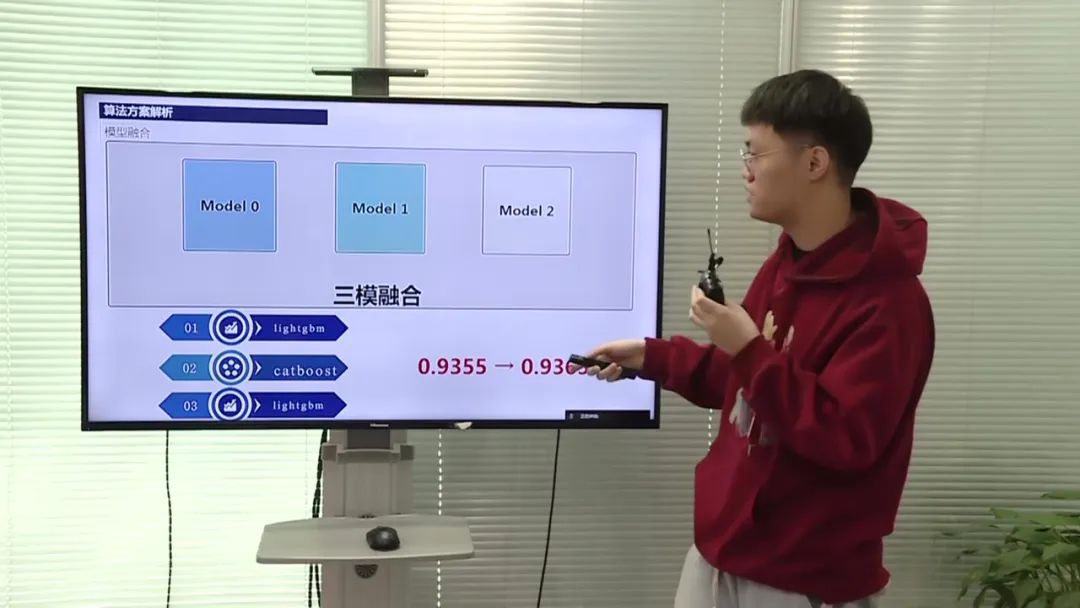
最终方案采用了三个模型的融合,其中第一个模型使用了标签传播公式,得到了最高分的单模结果;第二个模型对标签传递公式进行了改造,但效果不如第一个模型好,但仍存在差异,因此将其纳入模型融合。通过模型融合,将最高分的单模结果提升了一个千分点。
第三名

上分思路
该团队的比赛方案主要分为三个阶段。在第一阶段中,团队成员通过观察数据,使用基本的排序和规则方法,得到了0.82的分数。在第二阶段中,团队成员使用多维度特征衍生的方法,得到了0.89的分数。在第三阶段中,团队成员将规则特征转换为可用的模型特征,并与其他特征进行融合,最终达到了0.93的分数。在最后一个阶段中,团队成员通过探索不同的模型和分数,使用客户端池进行搜索,稍微提高了分数,达到了0.933。
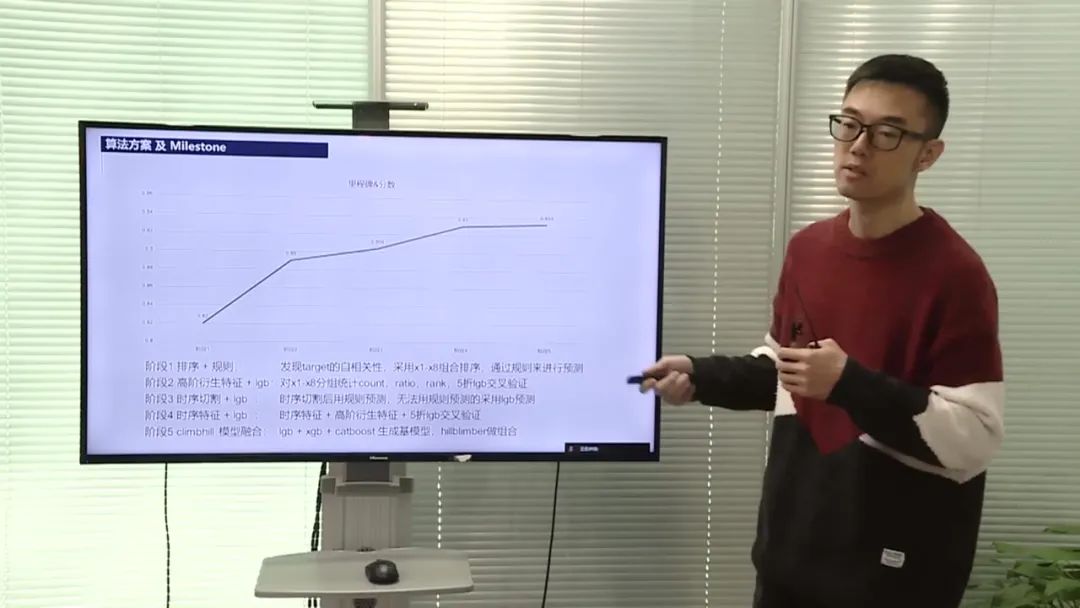

特征工程
团队成员在特征工程方面表现出色,通过对数据的观察和洞察,发现了数据中的关键特征。他们发现训练集和测试集在不同维度和键值上的分布高度一致,推测它们来自同一元数据级别。他们还发现在用户特征X1到X8中,通过组合排序后,相同特征值的目标值具有高度的自相关性。团队成员利用这些洞察,设计了一些规则和特征,从而提高了模型的预测能力。