





/王相/

为什么需要混沌工程?
YMatrix 作为分布式数据库,其架构复杂度与单机数据库相比不可同日而语。而在实际生产环境中,这种架构复杂度与种种我们在开发过程中难以预料的负载相混合,会导致最终产品在生产使用过程中的稳定性,变成一个不可知的问题。
💡 例如,考虑网络延迟的情况:在一个分布式系统中,即使是轻微的网络延迟也可能导致数据同步问题、性能瓶颈,甚至服务中断;由于系统组件之间高度依赖,这样的延迟可能引发一系列连锁反应,从而影响整个数据库的稳定性和响应速度。
面对前所未有的复杂性和它带来的挑战,我们又该如何确保 YMatrix 在任何情况下都能够提供稳定服务呢?“混沌工程”正是解决方案之一:通过模拟各种真实世界的故障情景,我们不仅能够提前发现并解决潜在的问题,而且能够确保 YMatrix 在最具挑战性的环境中也能表现出色,从而保证 YMatrix 能够在物联网和金融场景中提供稳定的服务。

什么是混沌工程?
传统的软件测试方法通常是基于严格定义的输入和预期输出。在这种测试中,如果最终的结果与预先定义的输出不一致,那么测试就会被视为失败。这种方法侧重于验证软件是否按照其设计正确执行其功能。
而混沌工程旨在通过有意识地在系统中引入混乱(例如网络延迟、服务器故障等),来提高系统的稳定性和可靠性。这种方法源于一个核心观点:在真实的生产环境中,不可预测的事件是不可避免的。因此,混沌工程的目标不是防止失败,而是通过理解和应对这些失败来增强系统的弹性。
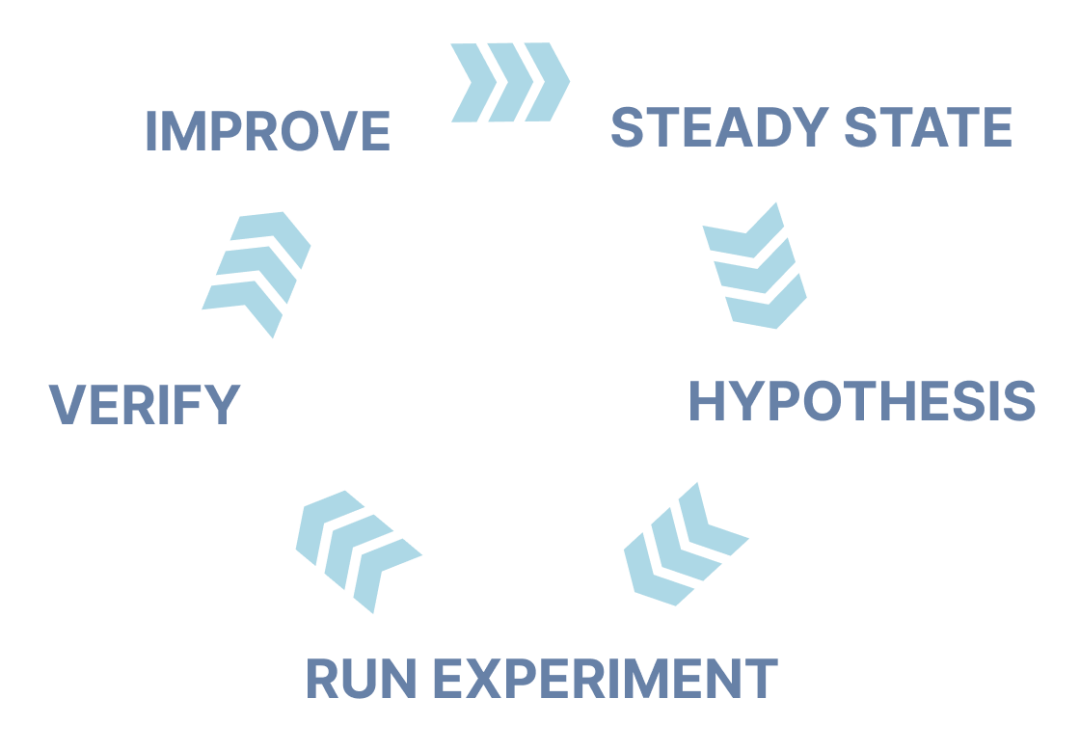
基线状态定义(Steady State):确定系统在正常运行时的性能和行为基线。
假设验证(Hypothesis):建立关于系统在面临特定挑战时如何响应的假设。
实验设计和执行(Run Experiment):设计并执行实验来模拟各种故障场景,观察系统是否按照预期的方式响应。
结果分析和学习 (Verify):分析实验结果,理解系统的实际行为与预期的偏差,从而进行必要的改进。
改进和迭代(Improve):根据所学到的内容对系统进行改进,并重复测试循环,以不断提升系统的稳定性和可靠性。
以 YMatrix 稳定性测试中典型的 Failover 测试为例:
定义系统稳定状态:所有 Primary 和 Mirror 都是正常状态,YMatrix 是健康的;
提出假设:对某几个 Primary 进行节点故障的模拟,相对应 Mirror 是否会被提升为 Primary 并能够正常提供服务;
进行实验:注入故障,使选中的 Primary 无法正常运行;
系统验证:YMatrix 可正常加载数据,可正常执行查询,Mirror 被提升为 Primary;
分析并改进实验:分析注入故障后系统行为是否符合预期,并根据情况进一步提升产品表现。
💡YMatrix 的数据节点(Segment)有两个角色:Primary 和 Mirror,正常情况下 Primary 提供服务,Mirror 节点作为 Primary 的镜像。
Failover 即故障自动转移,当 Primary 节点出现故障时,自动提升 Mirror 为 Primary,保证 YMatrix 的高可用。
💡对于像 YMatrix 这样的数据库系统而言,混沌工程不仅是一种测试手段,更是一种持续改进和自我完善的文化和实践。

YMatrix 如何进行测试
YMatrix 作为一款适用于物联网、金融场景的超融合数据库,不仅需要在复杂负载下充分保障数据一致性以及卓越性能,保证系统在复杂场景下的稳定性更为重要。为此,在项目建立之初,chaos 就已经被引入,作为整个测试框架的重要组成单元,旨保障 YMatrix 在复杂、极端的场景中的稳定性、正确性与性能。
我们研发了完善的测试框架以及其配套的测试工具,包括 mxbench、mxchoas、mxlancer、SSB 等,并设计了超百种场景的测试用例,已覆盖了数据库稳定性、功能、性能各个维度,最终通过高频的每天运行,力求在开发过程中的每一天保障系统稳定向前迭代,不出现回归问题。
整体上,我们主要从四个角度对 YMatrix 进行测试:
查询正确性测试:确保测试查询结果的正确性;
性能测试:针对业界 Benchmark 的性能评估,包括 TPC-H、TSBS 以及 SSB 等;
压力测试:针对客户真实场景的压力负载测试,包括读负载、写负载以及混合负载;
稳定性测试:针对 YMatrix 专门设计的混沌测试用例,接下来我们会进行详细的介绍。
1. 不同的 Workload 维度
为了将 YMatrix 的问题提前暴露在开发和测试阶段,我们需要设计足够多的测试用例,以覆盖绝大多数的用户真实使用场景。我们将这些测试用例称为 Workload,它由三个维度组成:
模拟场景及负载类型,模拟用户的真实业务场景;
Chaos 类型,详见下文;
数据库核心引擎,比如存储引擎或者执行引擎。
模拟场景和负载类型
我们对用户案例进行了分析和整理,总结出多种典型场景和负载类型。比如针对时序场景的数据建模、负载及业务查询,模拟某城市的出租车的行程信息,包括上下车时间、上下车地点、乘车人数、费用和付费方式等。对于负载类型,我们总结出加载数据、查询、读写混合负载等几种大类。
Chaos 类型
对于稳定性测试,YMatrix 针对其特性,结合混沌工程的思想设计了大量的混沌测试用例,如下图所示:
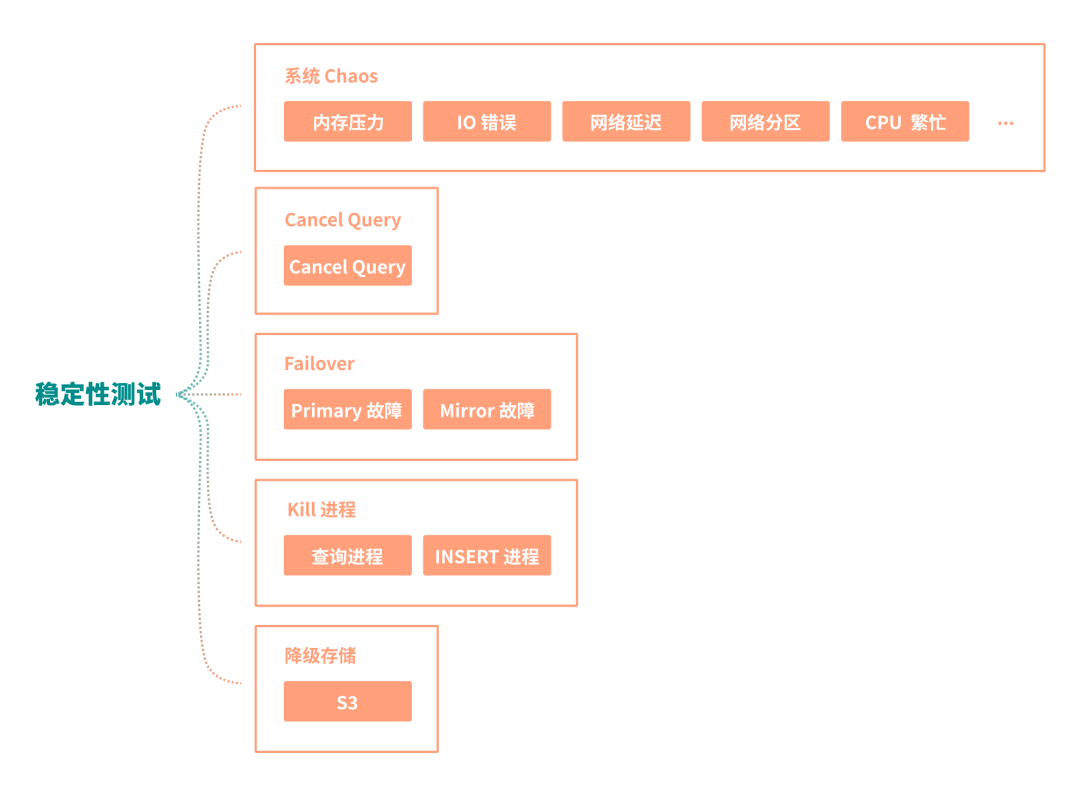
Cancel Query:撤销正在运行的 Query。
Failover:对 Primary 或者 Mirror 进行故障注入,验证系统的 Failover 机制,以及数据库能否正常恢复并提供服务。
Kill 关键进程:Kill 掉关键进程,例如查询执行器的进程。
降级存储:能否将数据降级到其他存储中,例如 S3。
系统 Chaos:网络、内存、CPU、IO 等系统相关的故障注入。
数据库核心引擎
主要针对存储引擎、执行引擎等其他核心引擎进行测试。
A. 存储引擎
存储引擎是数据库系统的存储基座,数据库基于存储引擎进行数据的创建、查询、更新和删除等操作。根据不同场景的需求特点,YMatrix 提供了多种不同的存储机制的存储引擎,包括 Heap、AOCO、 MARS2、 MARS3等。
B. 执行引擎
除了传统的火山引擎,YMatrix 还专门为面向列的存储引擎(如 MARS3,MARS2,AOCO)打造了高性能向量化执行引擎,其特点是一次 CPU 计算能处理一批数据,相比传统的火山引擎能够提高分析型查询执行速度 1 - 2 个数量级。
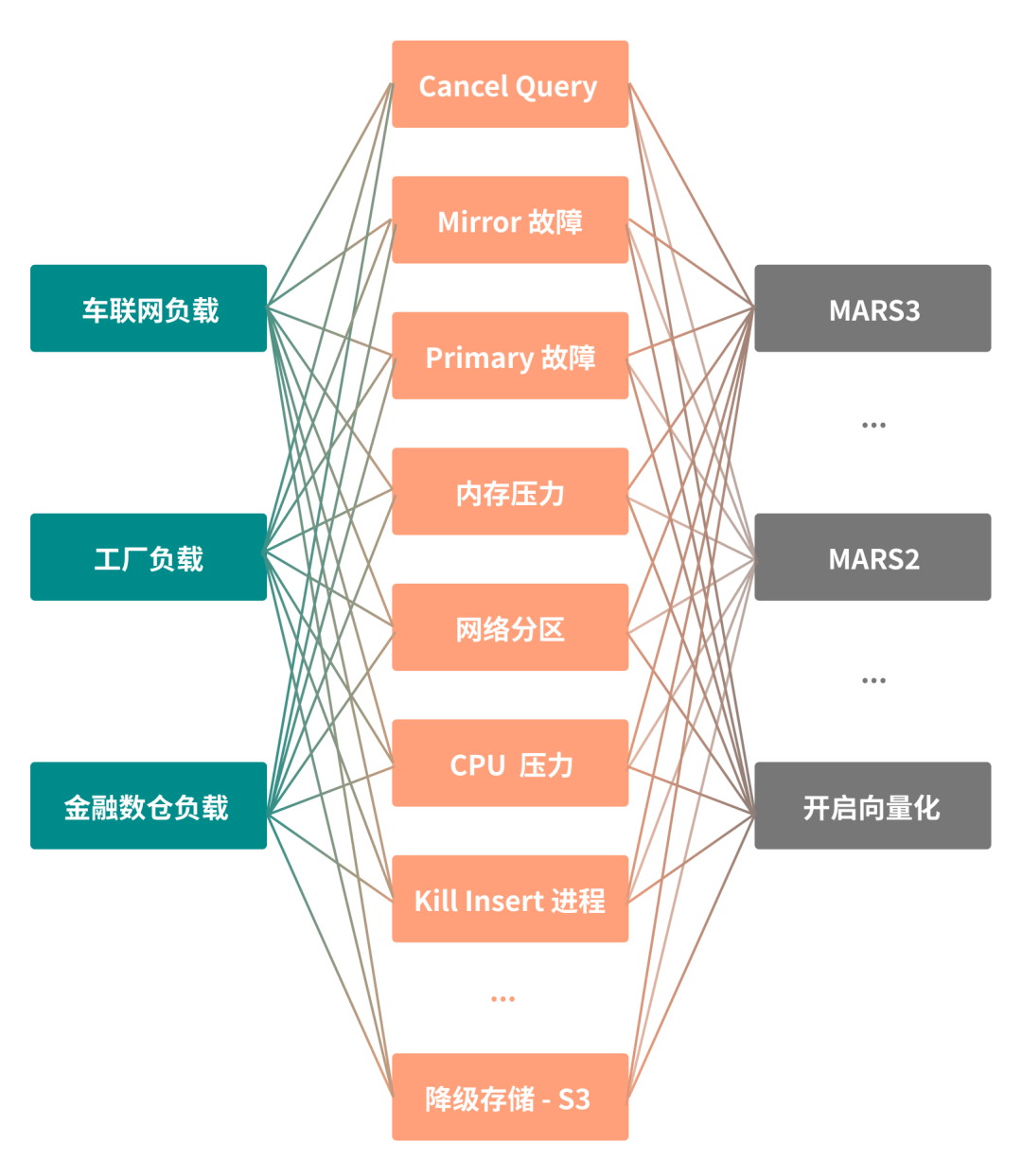
2. 用排列组合覆盖全场景
我们对模拟场景和负载类型、Chaos 类型以及数据库核心引擎三个维度进行交叉组合,就可以组合出数十种 Workload,覆盖了绝大多数的测试场景:
3. 测试流程与框架
有了充足的 Workload,那么如何将它们运行起来呢?而除了运行 Workload,我们也需要一些配套设施来帮助我们了解测试的情况,以及分析问题。
为此,我们不仅设计了完整的测试流程框架,也建设了配套的日志和监控系统,从而覆盖从测试运行到问题分析排查全流程:
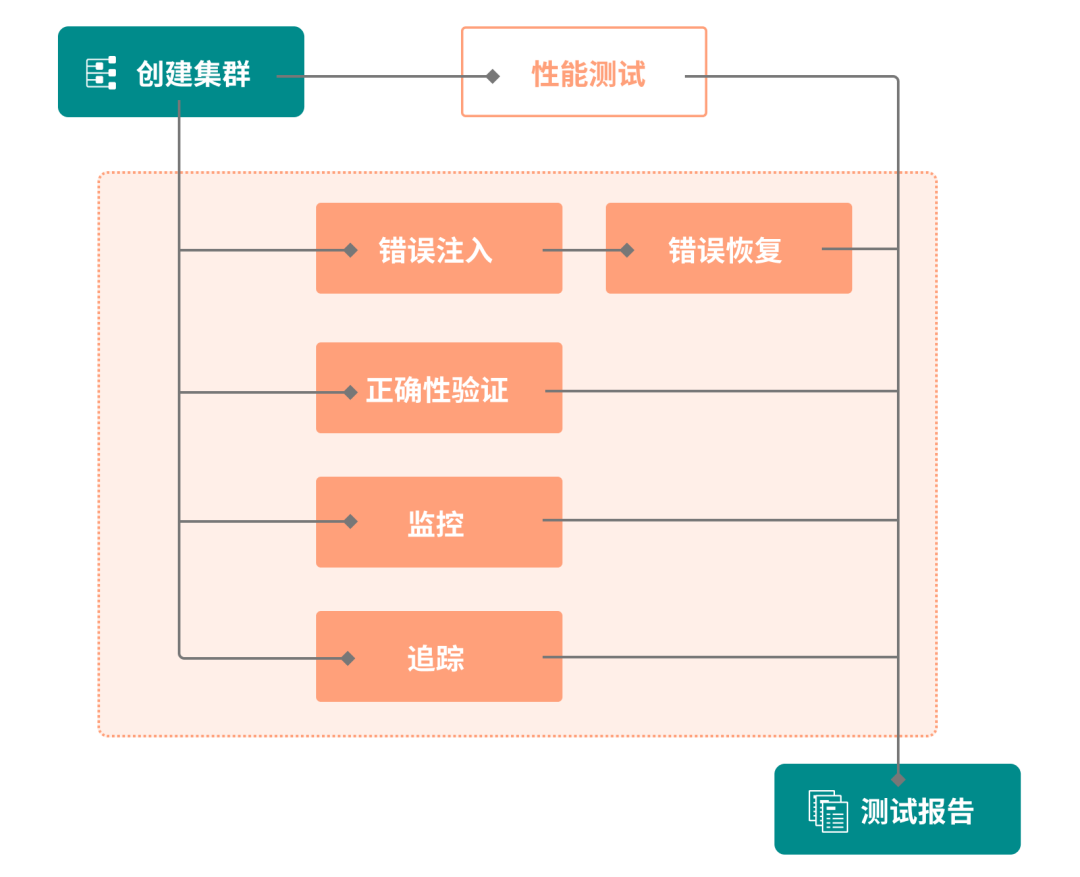
有了充足的测试 Workload,也定义清楚了整个测试流程,那么下面就需要将测试自动化运行起来。我们设计的自动化测试框架如下所示:
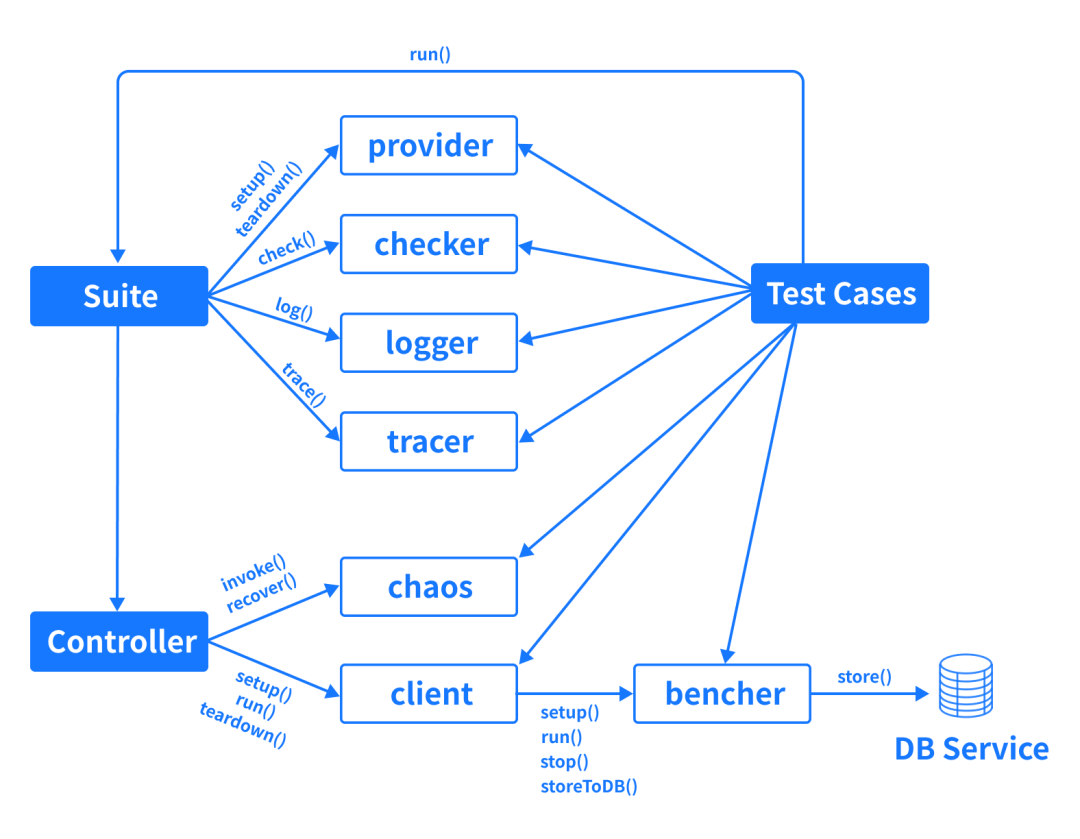
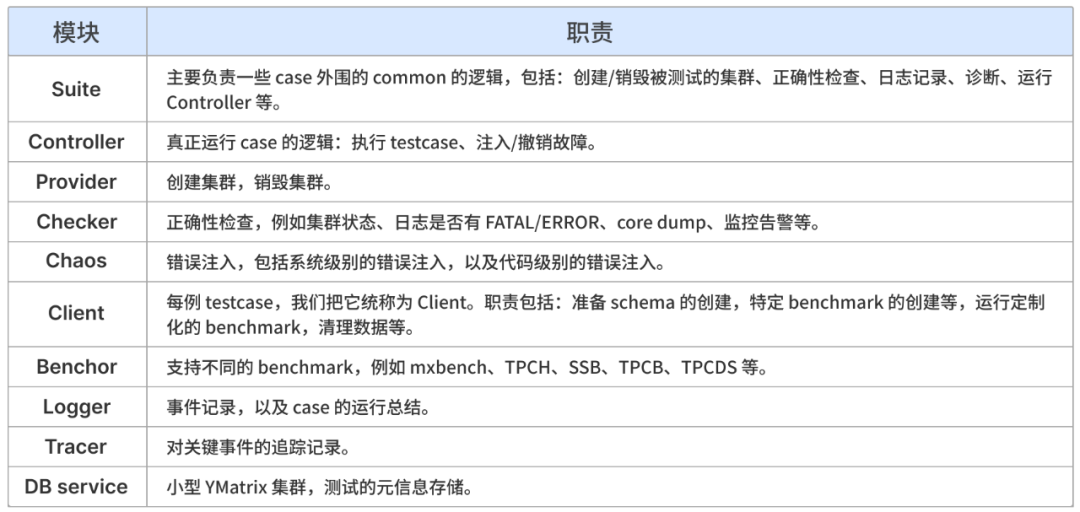
其中主要模块的职责如下:
运行平台
测试系统运行在 Kubernetes 集群上,这是因为 Kubernetes 具有良好的可扩展性和调度能力。我们为 YMatrix 实现了 operator,这样就可以方便地在 Kubernetes 上创建测试用的 YMatrix 集群。
故障注入
对于故障注入,我们选择了 PingCAP 的 开源项目 Chaos Mesh。Chaos Mesh 是云原生的混沌工程平台,提供了丰富的故障模拟类型,包括网络、磁盘、Pod 故障等,可以充分满足我们的需求。此外,Chaos Mesh 使用 CRD 的形式定义故障,我们可以方便地在代码中通过创建 CR 的方式注入故障。
运行结果展示
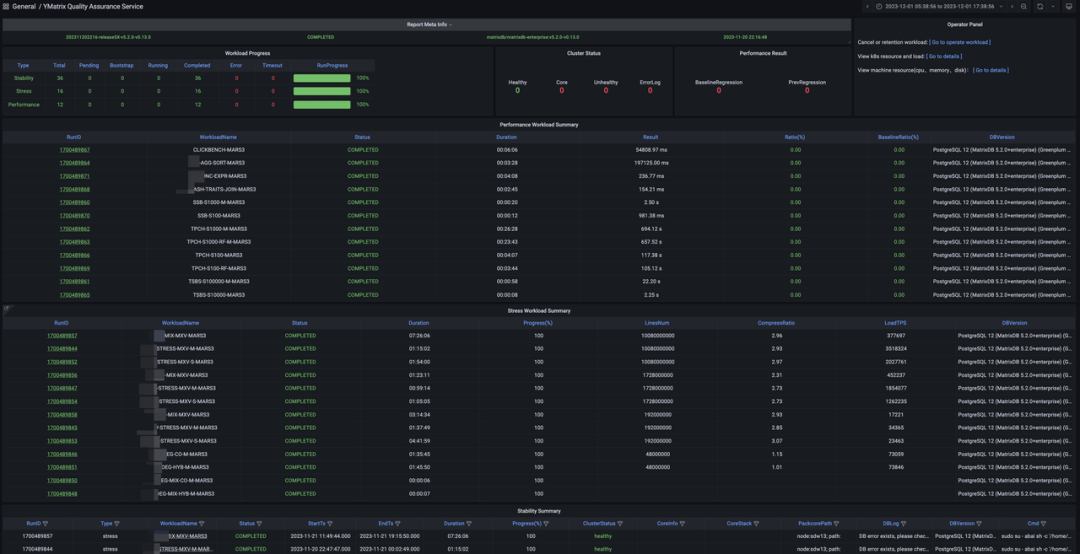
可以看到,Grafana 中提供了 Workload 的运行状态、运行时间、数据库的版本、以及其他一些有用的信息。当运行出现故障,或者结果没有符合预期,也会在 Grafana 中展示出来,方便我们去排查和定位问题。

下期预告
感谢你的阅读,YMatrix 期待与志同道合的你一起同行。





