




点击上方“IT那活儿”公众号--专注于企业全栈运维技术分享,不管IT什么活儿,干就完了!!!
checkpoint总体时间变长,最终超时失败,然后不断重试,最后job作业挂掉; state状态变大; kafka数据积压; OOM。
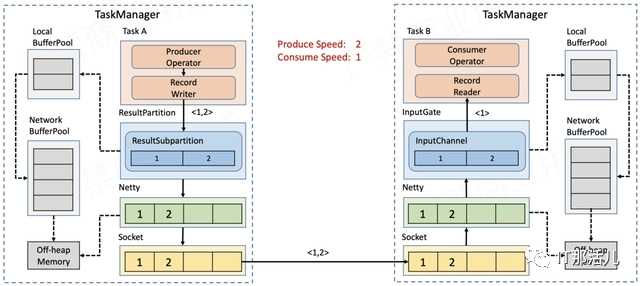
输出缓冲区 resultPartition -> local bufferpool -> network bufferpool 输入缓冲区 inputGate -> local bufferpool -> network bufferpool
1.4 反压的原因
资源不合理(cpu少了,内存小了,并行度小了); 数据倾斜; 代码性能低; 与外部系统交互。
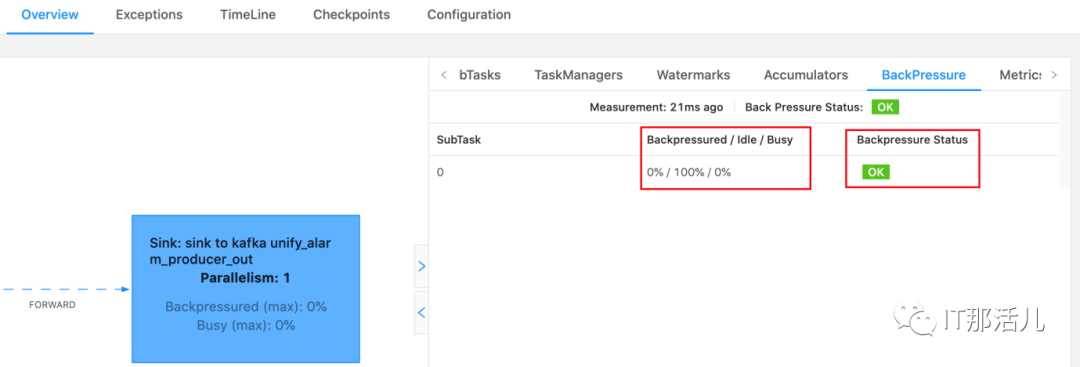
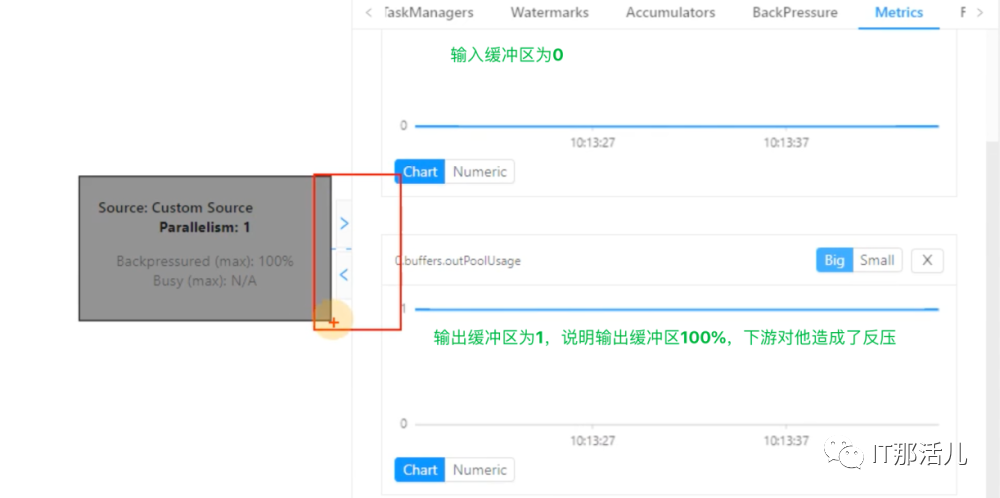
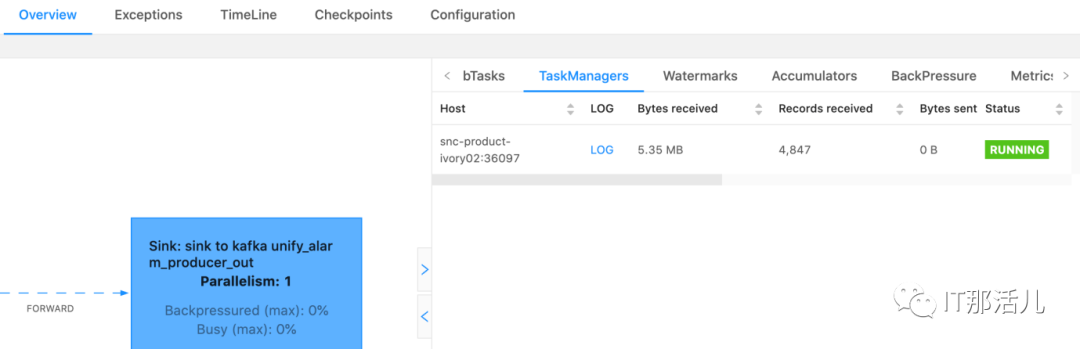
纵向:调用链,最上面的是执行中的; 横向:可以理解为执行时长。
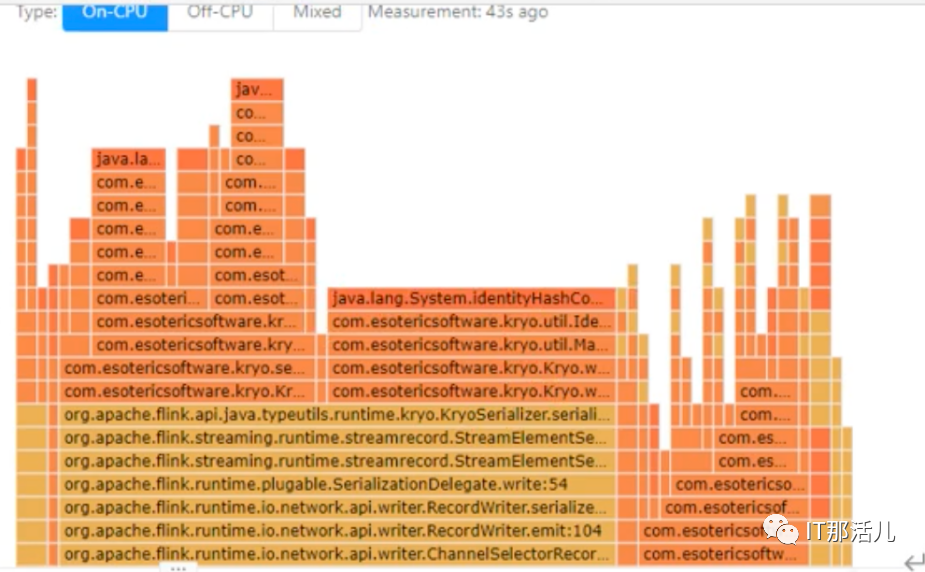
通过参数指定,打印GC日志; 通过web ui下载; 通过gc工具打开gc日志,查看是不是出现了fullgc情况,分析是不是出现了内存泄露。
总 结:
本文作者:田兆壮(上海新炬中北团队)
本文来源:“IT那活儿”公众号

文章转载自IT那活儿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
