




点击上方“IT那活儿”公众号--专注于企业全栈运维技术分享,不管IT什么活儿,干就完了!!!
某天某业务系统,偶尔出现业务访问失败的情况。
经分析,临时对该业务所属K8S主机XXX.XXX.1.2停止调度,并迁移至其它主机,业务恢复正常,但在业务迁移后,业务主机还存在一直告警,报有时无法连接的信息。
2.1 主机核心参数检查
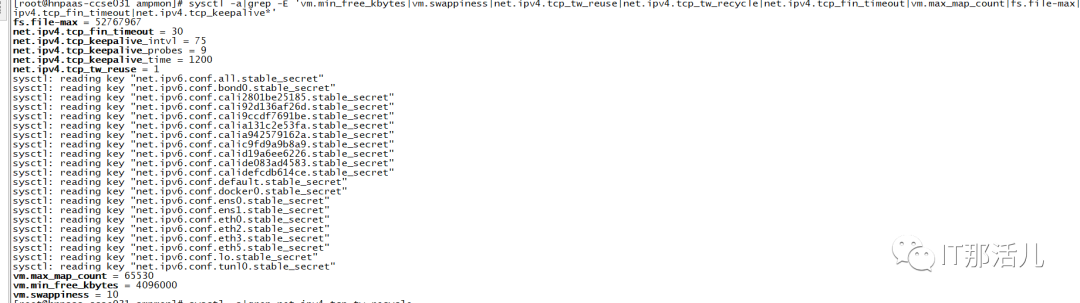
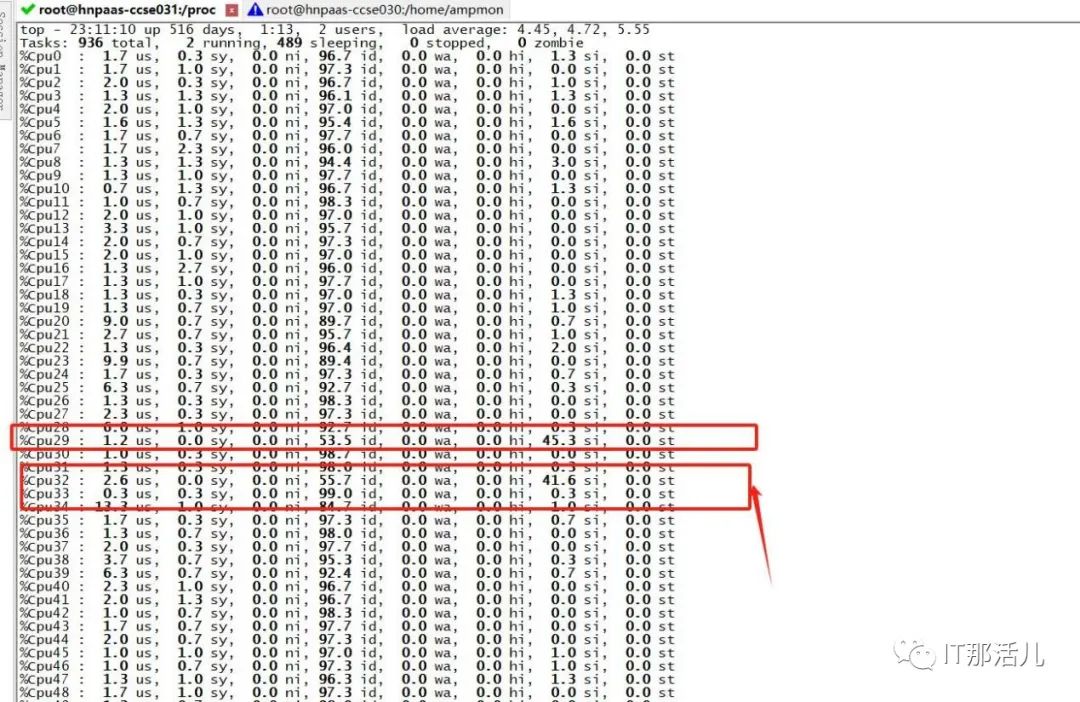
2.2 CPU资源负载低,但存在CPU软中断
1)Cpu 29,cpu 32 core 存在cpu软中断
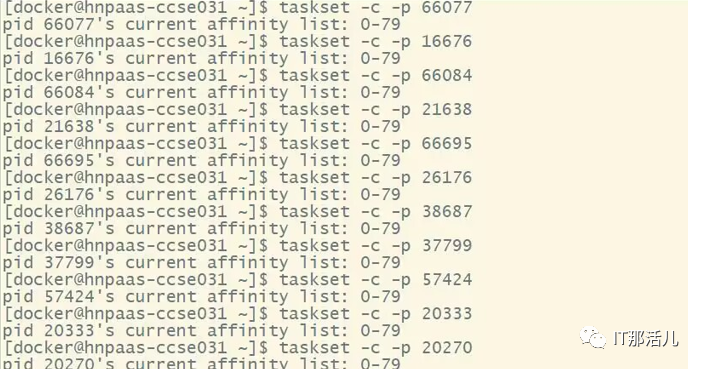
2)检查CPU亲和性
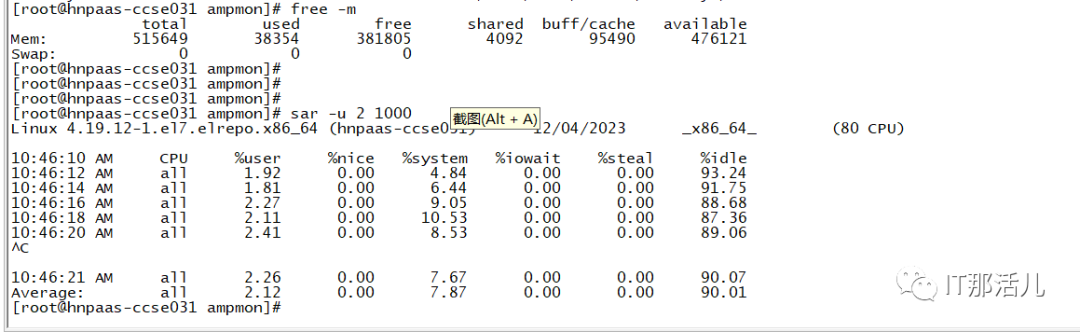
2.3 内存使用分析
内存及swap属正常范围。
2.4 TCP网络连接分析
1)当前存在1000多个close_wait连接
netstat -atunp | grep CLOSE_WAIT | awk '{print $4}' | cut -d '/' -f 1 | sort | uniq -c | sort -n -r
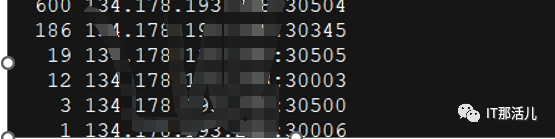
2)客户端在主机累积的未关闭socket存在4万多个
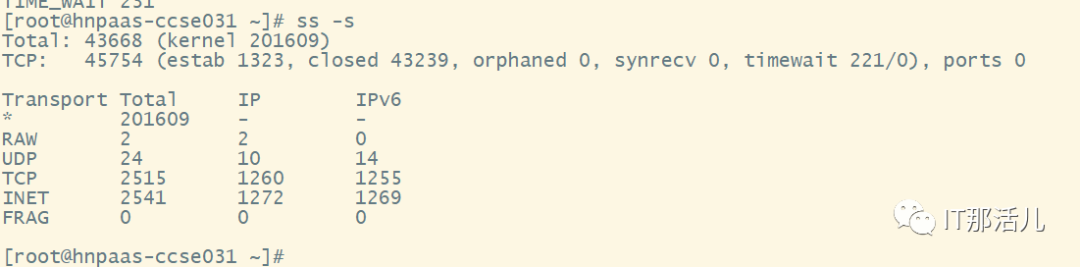
2.5 进程所属TCP连接及socket文件数分析
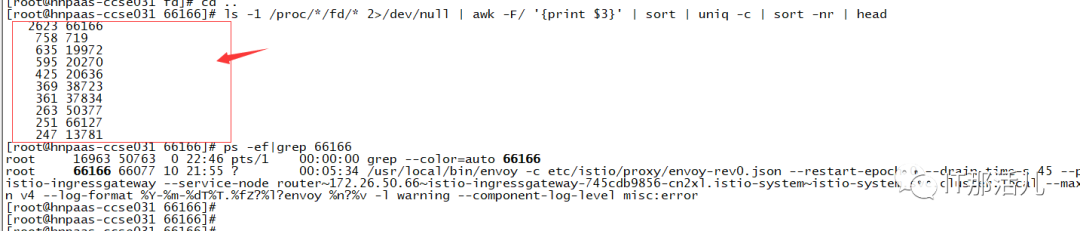
3.1 根据来源进行处理
对promethus重建pod后, 连接从4万5千多到3万6; 对hnvc所属nacos重建后,连接从3万6到2000多。
3.2 原因总结
3.3 后续优化
完善监控指标,对close_wait以及close_wait累积量的监控; 业务侧分析业务代码是否有未关闭的代码逻辑。
本文作者:唐田寿(上海新炬中北团队)
本文来源:“IT那活儿”公众号

文章转载自IT那活儿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
