





关于Redis(4.0+)里面的持久化方案有三种:
RDB(Redis DataBase)
AOF(Append Only File)
混合型方案
RDB相关配置
这是redis里面默认提供的一套持久化技术方案,专门用于保证内存中的数据被写入到磁盘里面去。主要配置是修改相应的redis.conf来实现
redis里面的这一行主要是用于将数据持久化在redis的dump.rdb文件里面,然后每一次开启redis的时候都会将里面的数据重新加载,进行数据恢复。(dump.rdb的存放位置由下边的dir来标识)
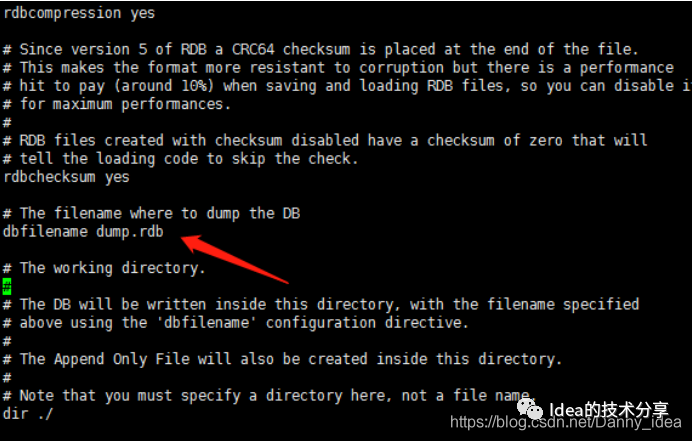
这一段配置主要是rdb的核心规则配置内容:
save <指定时间间隔> <执行指定次数更新操作> (默认是save 900 1)
举个例子来说:
save m n
也就是说m秒类如果进行了n次操作,就会将数据存储到dump.rdb文件中去。
rdb里面并不是单纯将数据直接存储起来,而是通过一种特定的lzf压缩方式来实现的:
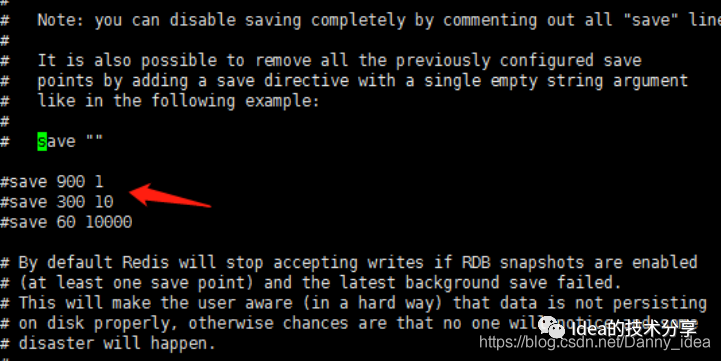
这个配置开关最好打开(默认开启),否则会导致rdb文件过大,占用磁盘空间。
触发rdb存储机制的条件:
1.显示执行save指令(但是这是一种阻塞式指令)
2.执行flushall指令的时候,清空所有数据
3.执行shutdown指令
4.在指定时间间隔,操作次数达到save配置的数目
RDB的优缺点
缺点
RDB 在服务器故障时容易造成数据的丢失。RDB 允许我们通过修改 save point 配置来控制持久化的频率。但是,因为 RDB 文件需要保存整个数据集的状态, 所以它是一个比较重的操作,如果频率太频繁,可能会对 Redis 性能产生影响。所以通常可能设置至少5分钟才保存一次快照,这时如果 Redis 出现宕机等情况,则意味着最多可能丢失5分钟数据。
RDB 保存时使用 fork 子进程进行数据的持久化,如果数据比较大的话,fork 可能会非常耗时,造成 Redis 停止处理服务N毫秒。如果数据集很大且 CPU 比较繁忙的时候,停止服务的时间甚至会到一秒。
Linux fork 子进程采用的是 copy-on-write 的方式。在 Redis 执行 RDB 持久化期间,如果 client 写入数据很频繁,那么将增加 Redis 占用的内存,最坏情况下,内存的占用将达到原先的2倍。刚 fork 时,主进程和子进程共享内存,但是随着主进程需要处理写操作,主进程需要将修改的页面拷贝一份出来,然后进行修改。极端情况下,如果所有的页面都被修改,则此时的内存占用是原先的2倍。
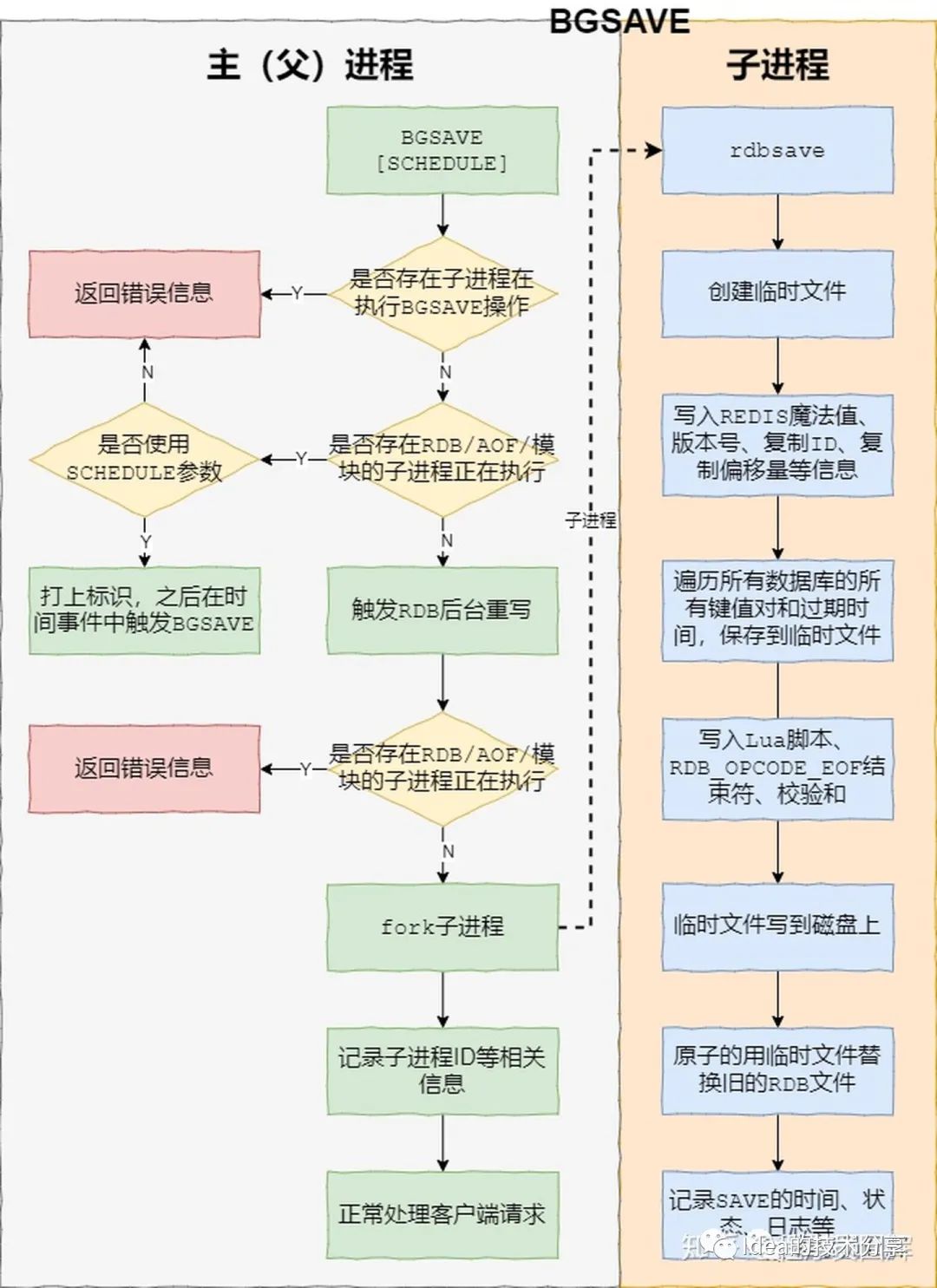
关于Redis在使用RDB方案解决数据持久化的时候实际上底层的主进程是fork了一个子进程用于处理RDB文件,我在网上找到了一份比较清晰的流程图用于展示这个环节中的细节点:
优点
RDB 文件是是经过压缩的二进制文件,占用空间很小,它保存了 Redis 某个时间点的数据集,很适合用于做备份。比如说,你可以在最近的 24 小时内,每小时备份一次 RDB 文件,并且在每个月的每一天,也备份一个 RDB 文件。这样的话,即使遇上问题,也可以随时将数据集还原到不同的版本。
RDB 非常适用于灾难恢复(disaster recovery):它只有一个文件,并且内容都非常紧凑,可以(在加密后)将它传送到别的数据中心。
RDB 可以最大化 redis 的性能。父进程在保存 RDB 文件时唯一要做的就是 fork 出一个子进程,然后这个子进程就会处理接下来的所有保存工作,父进程无须执行任何磁盘 I/O 操作。
RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
实战--RDB的数据恢复过程
接下来我们来演示一段redis里面进行rdb数据恢复的过程
首先我们需要修改rdb的配置信息
[root@idea-centos bin]# vim redis.conf1
修改内容
save 900 1save 120 5save 60 10000
修改了对应的配置属性之后,我们可以先模拟制造一些数据信息,如下所示:
[root@idea-centos bin]# ./redis-server redis.conf[root@idea-centos bin]# ./redis-cli -h 127.0.0.1 -p 6379127.0.0.1:6379> keys *(empty list or set)127.0.0.1:6379> set key1 value1OK127.0.0.1:6379> set key2 value2OK127.0.0.1:6379> set key3 value3OK127.0.0.1:6379> set key4 value4OK127.0.0.1:6379> set key5 value5OK127.0.0.1:6379> set key6 value6OK127.0.0.1:6379> SHUTDOWNnot connected> QUIT
由于已经制造了部分数据信息,所以此时的dump.rdb文件内就已经存在一些数据内容了。为了后期的演示,我这里做个数据备份:
[root@idea-centos bin]# cp dump.rdb dump_bk.rdb[root@idea-centos bin]# ./redis-server redis.conf[root@idea-centos bin]# ./redis-cli -h 127.0.0.1 -p 6379127.0.0.1:6379> FLUSHALLOK127.0.0.1:6379> keys *(empty list or set)127.0.0.1:6379> SHUTDOWNnot connected> QUIT
接下来我们对已经清空的数据库进行rdb文件的恢复操作:
[root@idea-centos bin]# cp dump_bk.rdb dump.rdbcp: overwrite `dump.rdb'? y[root@idea-centos bin]# ./redis-server redis.conf[root@idea-centos bin]# ./redis-cli -h 127.0.0.1 -p 6379127.0.0.1:6379> keys *1) "key5"2) "key1"3) "key3"4) "key4"5) "key6"6) "key2"......
恢复之后会发现先前清理掉的部分数据又再次恢复正常了。
ps:一般情况下我们会禁止flushall指令和shutdown指令,这里只是为了模拟测试才使用的。
问题:假设我们给redis配置的保存机制是10秒内10次操作才做保存,倘若某一天redis在10秒内只执行了9次修改操作,当满了10秒的时候机器宕机了,那么这些对应的10次操作的key就会发生丢失。这也是rbd作为数据备份时候对一个缺陷,为了优化这种问题,redis后边又提出了aof的持久化解决手段。
AOF方式持久化
为了弥补rdb的不足之处,aof出现了。它是采用日志的形式来将每一次写操作都进行记录,追加到相应的文件中去。Redis重启的时候会根据日志文件的内容从前到后执行一次。
关于aof内部对一些配置我们可以关注以下几个内容点:
appendonly:默认值为no,也就是说redis 默认使用的是rdb方式持久化,如果想要开启 AOF 持久化方式,需要将 appendonly 修改为 yes。
appendfilename :aof文件名,默认是"appendonly.aof"
appendfsync:aof持久化策略的配置
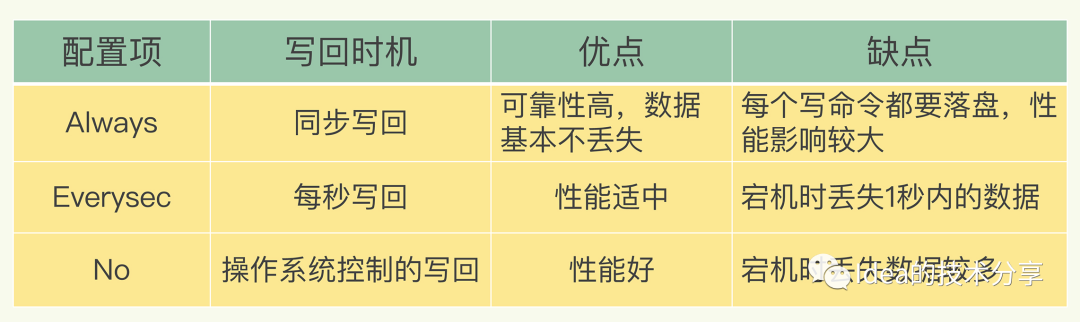
AOF的持久化策略有哪些
always策略
这类策略是每次处理redis指令的时候都会将数据立马写入磁盘进行持久化,虽然性能差,但是安全性是最高的。
everysec策略(推荐)
会有一个异步子线程,每一秒将新写入到内存的数据持久化到磁盘中。
no策略
直接写入aof的内存缓冲区,剩下部分由操作系统自身来控制
AOF文件过大如何优化
上边在写rdb重写机制的时候有讲到过rdb文件压缩的原理是使用算法将二进制文件进行压缩,而对于AOF来说,它自身是采用去除无效命令的方式来进行空间压缩的。
例如说同一个key进行了重复的插入,那么就只保留最后一次插入的数据。如下图所示:
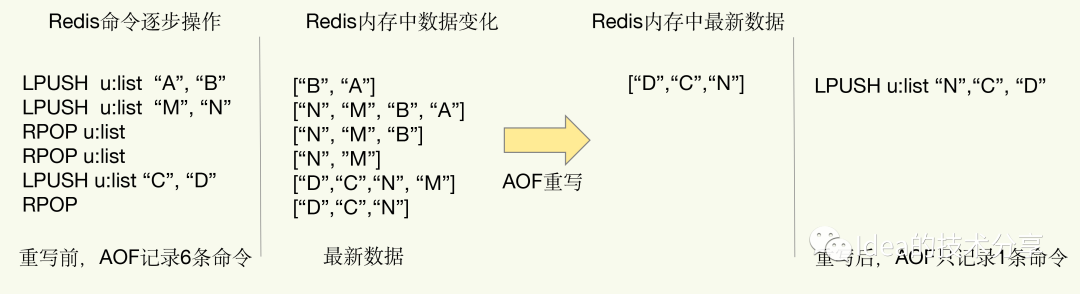
AOF里触发该机制的条件可以在conf文件里面进行配置:
当AOF文件的大小超过所设定的阈值时,Redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集。
配置参数:
auto-aof-rewrite-min-size 64mb #aof文件要达到一定体积才会进行重写
auto-aof-rewrite-percentage 100 #当aof文件大小增长了100%才会触发重写
重写的原理
aof在进行重写处理的时候,会额外开辟一个bgrewriteaof线程,将原先的aof文件数据拷贝到一个临时文件进行处理,最后再覆盖原先文件。
相比于rdb而言,aof的数据备份效率更高,但是在数据恢复的时候其性能却远远不如rdb高效。
混合型存储
redis4.0相对与3.X版本其中一个比较大的变化是4.0添加了新的混合持久化方式。前面已经详细介绍了AOF持久化以及RDB持久化,这里介绍的混合持久化就是同时结合RDB持久化以及AOF持久化混合写入AOF文件。这样做的好处是可以结合 rdb 和 aof 的优点, 快速加载同时避免丢失过多的数据,缺点是 aof 里面的 rdb 部分就是压缩格式不再是 aof 格式,可读性差。
开启混合持久化
4.0版本的混合持久化默认关闭的,通过aof-use-rdb-preamble配置参数控制,yes则表示开启,no表示禁用,默认是禁用的,可通过config set修改。
混合持久化过程
了解了AOF持久化过程和RDB持久化过程以后,混合持久化过程就相对简单了。
混合持久化同样也是通过bgrewriteaof完成的,不同的是当开启混合持久化时,fork出的子进程先将共享的内存副本全量的以RDB方式写入aof文件,然后在将重写缓冲区的增量命令以AOF方式写入到文件,写入完成后通知主进程更新统计信息,并将新的含有RDB格式和AOF格式的AOF文件替换旧的的AOF文件。简单的说:新的AOF文件前半段是RDB格式的全量数据后半段是AOF格式的增量数据,如下图:
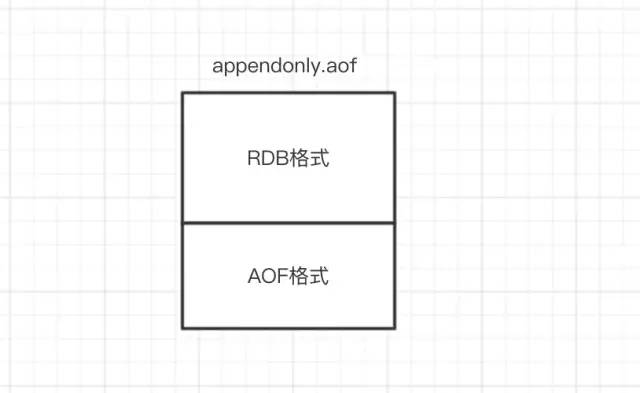
数据恢复
当我们开启了混合持久化时,启动redis依然优先加载aof文件,aof文件加载可能有两种情况如下:
aof文件开头是rdb的格式, 先加载 rdb内容再加载剩余的 aof。
aof文件开头不是rdb的格式,直接以aof格式加载整个文件。
混合持久化优缺点
优点:
混合持久化结合了RDB持久化 和 AOF 持久化的优点, 由于绝大部分都是RDB格式,加载速度快,同时结合AOF,增量的数据以AOF方式保存了,数据更少的丢失。
缺点:
兼容性差,一旦开启了混合持久化,在4.0之前版本都不识别该aof文件,同时由于前部分是RDB格式,阅读性较差

长按二维码
就可以关注我们啦~
往期技术文章整理:
大话Redis系列(后边依旧会继续更新)
大话Redis系列--实战案例总结(下)
大话Redis系列--实战案例总结(上)
大话Redis系列--哪些场景下redis会“快”不起来
深入挖掘Spring专题 (内部有配套的源代码仓库,实操理论合二为一)
深入挖掘Spring系列(一)依赖查找背后的细节
深入挖掘Spring系列(二)依赖注入专题
深入挖掘Spring系列 (三)依赖的来源
深入挖掘Spring系列 (四)手写一个mini版本AOP
深入挖掘Spring系列 (五)从设计模式的角度看Spring
深入挖掘Spring系列(六)Spring内部的事件机制
深入挖掘Spring系列(七)阶段性总结
计算机底层原理专题 (程序的原理和本质都离不开OS)
计算机原理探险系列(一)CPU
计算机原理探险系列(二)网络传输
计算机原理探险系列(三)TCP数据传输
计算机原理探险系列(四)磁盘存储探秘
计算机原理探险系列(五)OS中的进程
计算机原理探险系列 (六) 看图认识内存分配
计算机原理探险系列 (七) 阶段性复习
计算机原理探险系列(八)继续探索,进程和线程
JVM系列专题 (没有JVM,Java程序跑着跑着说不定就崩了)
JVM系列 (一) Java发展的历史背景故事
JVM系列 (二) Hotspot虚拟机的内存管理
JVM系列 (三) 对象内存分配技术分析
JVM系列 (四) Hotspot中内存的回收策略
JVM系列 (五) 垃圾回收器
JVM系列 (六) G1与低延迟垃圾收集器Shenandoah,ZGC
