




 蚂蚁集团时序数据库 CeresDB 于 2022 年 6 月正式宣布开源,2023年12月11日,将 CeresDB 的核心源代码以 HoraeDB 的品牌捐赠给 Apache Software Foundation (ASF) 。根据 Apache 基金会邮件列表中显示,HoraeDB 以 13 个约束性投票(binding votes)和 1 个无约束性投票(non-binding votes),无弃权和反对票通过投票决议,全票通过,官宣正式加入Apache 孵化器。
蚂蚁集团时序数据库 CeresDB 于 2022 年 6 月正式宣布开源,2023年12月11日,将 CeresDB 的核心源代码以 HoraeDB 的品牌捐赠给 Apache Software Foundation (ASF) 。根据 Apache 基金会邮件列表中显示,HoraeDB 以 13 个约束性投票(binding votes)和 1 个无约束性投票(non-binding votes),无弃权和反对票通过投票决议,全票通过,官宣正式加入Apache 孵化器。
" Welcome HoraeDB to the ASF incubator "
加入 Apache 孵化器后,HoraeDB 将积极践行『开放、协作』 的 Apache 之道(The Apache Way),保持开放治理,持续构建一个公平、多元、包容的社区,遵守 Apache 孵化器的指导方针和流程,积极参与社区活动,努力推动项目的进展,也期待能够与项目导师等社区成员一起合作,分享经验和知识,持续提升项目的可靠性和质量。同时无论您是想为社区做出贡献,还是想提升自己的技术能力,我们都非常欢迎各位加入到 HoraeDB 社区,社区接受任何形式的贡献,让我们一起共同推动开源的发展,创造更美好的未来!
HoraeDB 团队已经在时序数据领域进行了5年的深耕。但是随着在领域内研究的深入以及用户场景的逐渐复杂化,我们发现了若干传统时序数据库尚未很好解决的一些技术问题,比如:
高效处理高基数 Tag 组合(时间线膨胀问题)与分析型工作负载
现代且完备的分布式技术方案
云原生与计算存储分离
因此,HoraeDB 开源项目发起之初,我们就将其定义为下一代的云原生时序数据库。希望它能同时较好支持传统时间序列工作负载(timeseries workload)与分析型工作负载(analytic workload),并且能拥有一个现代的云原生分布式技术架构,支持从简单的单节点到庞大分布式集群等各种部署场景。
接下来简单介绍 HoraeDB 投入的几个重点方向的技术方案。
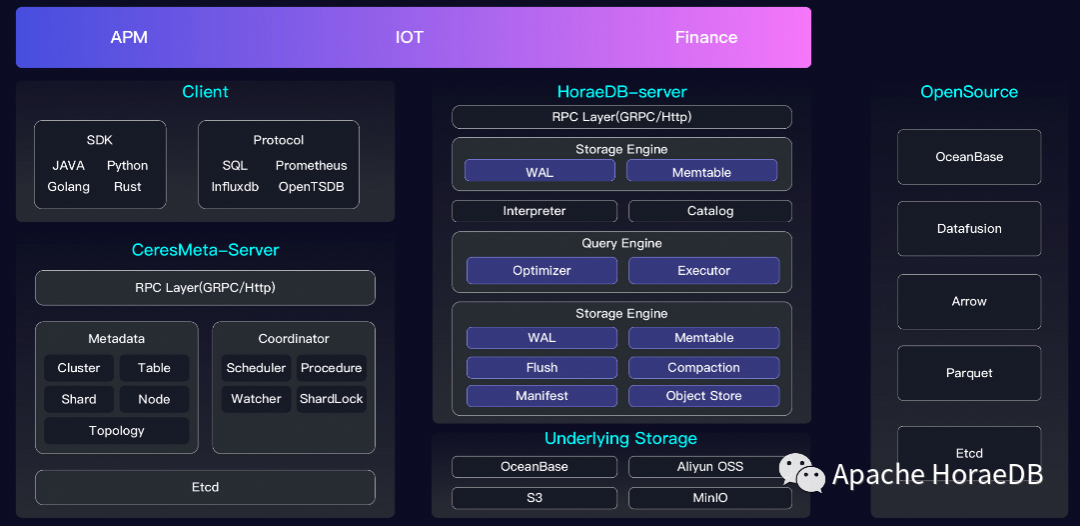 HoraeDB 架构图
HoraeDB 架构图
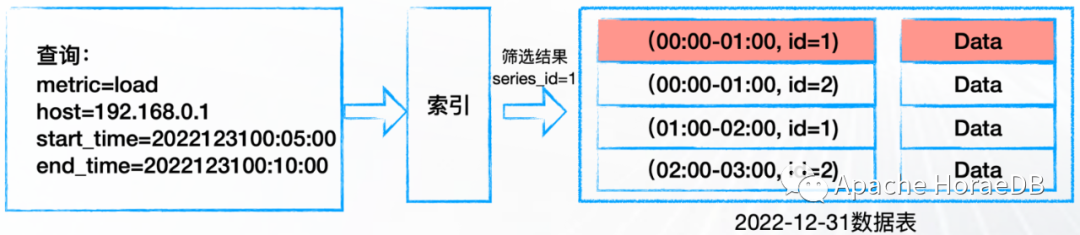
经典时序模型会使用倒排索引的方式对数据进行组织。然而在某些场景如短生命周期 pod 监控、业务数据监控等,会产生高基数时间线,进而导致倒排索引膨胀问题,写入查询性能会急剧变差。
写入时由于索引的复杂性高,写入耗时变高
查询时由于索引的有效性低,查询耗时变高
下图为经典时序模型的示意图:
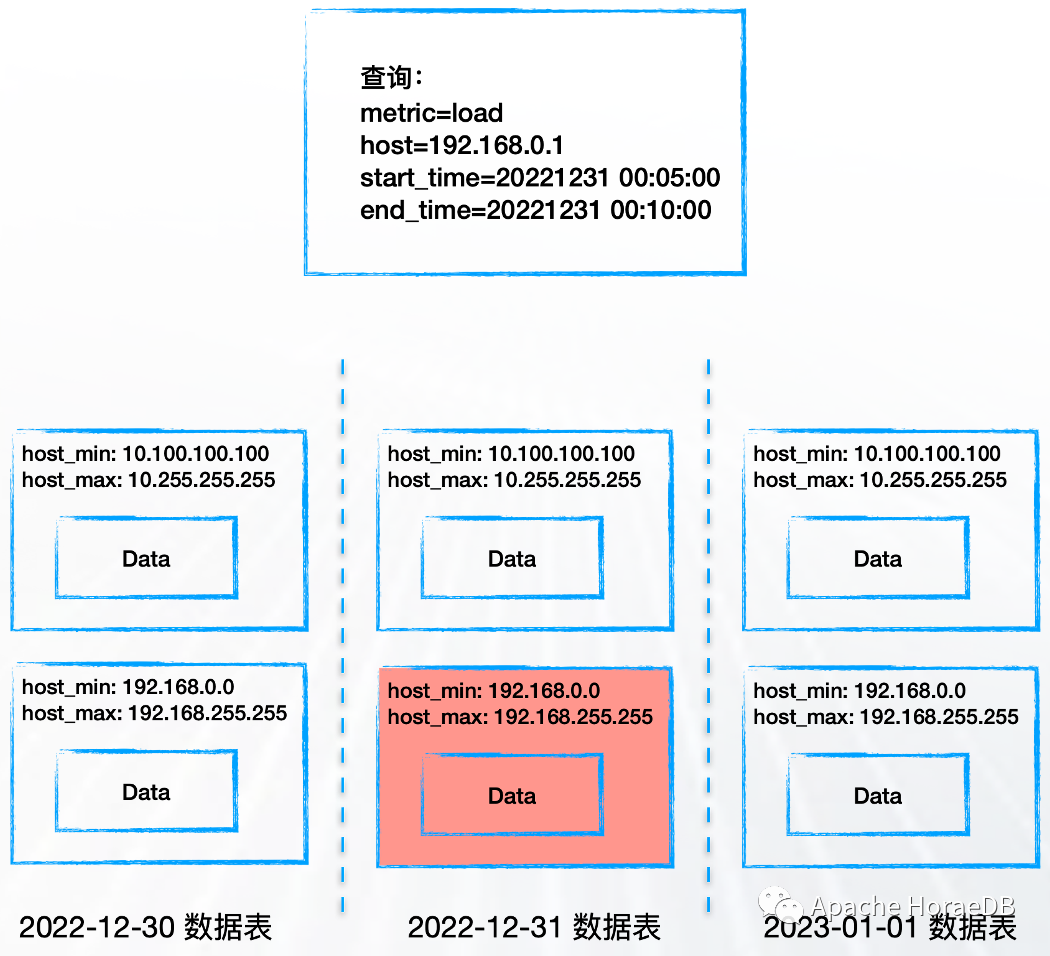
为了解决高基数的问题,HoraeDB 受 InfluxDB IOx 以及各类分析型数据库的启发,采用以下方式对时序数据进行组织来实现存储和查询:
列式存储 + 混合存储
分区扫描 + 剪枝 + 高效 fitler
下图展示了 HoraeDB 内部的数据组织形式:
HoraeDB 采用存储计算分离架构,如下图所示。HoraeDB 实例本身可以不存储任何数据,在此基础上可以较好实现关键的几项分布式特性,比如:计算存储弹性扩缩容、服务高可用和负载均衡等等。
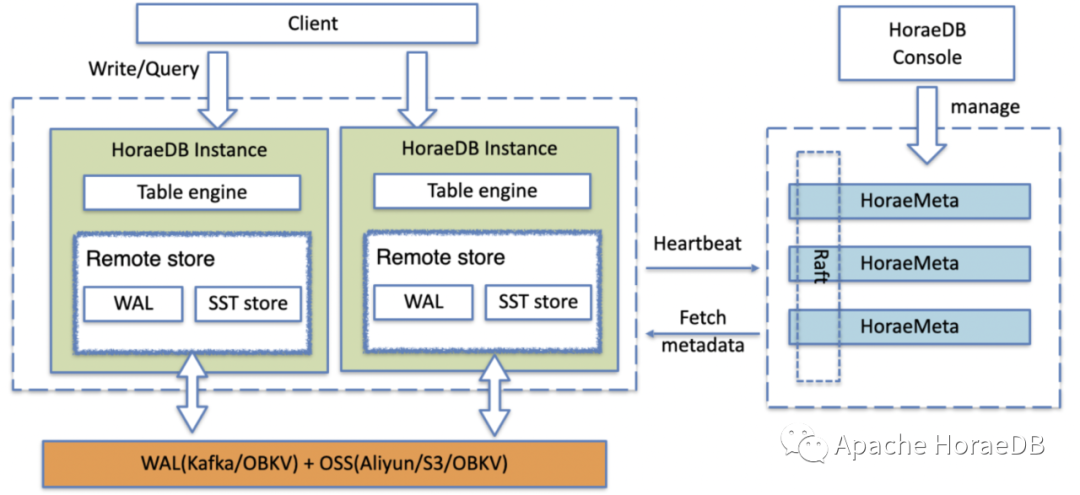
HoraeDB 分布式集群主要由以下部分组成:
HoraeMeta Cluster:集群的元数据中心,负责集群的整体调度;
HoraeDB:一个 HoraeDB 实例, 负责时序数据组织与存储;
WAL Service(外部):WAL 服务,在集群方案中,用于存储实时写入的数据;
Object Storage(外部):对象存储服务,用于存储从 memtable 生成的 SST 文件。
自建引擎,低开销技术栈 (Rust) 高压缩比(10:1)
基于 SQL 的 OLAP 分析能力,支持关联查询、谓词和聚合算子下推
存储计算分离架构,支持多种存储介质 分级存储,数据冷热分离
数据分片、计算和存储均可水平扩展 支持同城异地容灾,金融级容灾标准
多值模型,Metric + Tags + MultiFields RestfulAPI,多语言 SDK
兼容 Prometheus、InfluxDB、OpenTSDB 协议 HoraeDB GitHub 开源
时序数据库 HoraeDB 能顺利加入 Apache 孵化器,离不开社区贡献者多年来的不断努力以及蚂蚁集团数据库团队的支持。
在此特别感谢给 HoraeDB 提供指导的各位 champion 和 mentors。
Champion:
tison(tison@apache.org)
Mentors:
shaofengshi@apache.org
lgcareer@apache.org
vongosling@apache.org
tison@apache.org
在此,向所有帮助和支持 HoraeDB 的个人和团队表达最衷心的感激。每一份努力和贡献都是 HoraeDB 前进的关键,感谢大家携手同行。
诚邀对时序数据库 HoraeDB 感兴趣的各位开发者和用户加入我们的开源社区,共同推动项目更进一步的发展,您可以通过以下方式关注和了解社区的最近动态,期待您的加入~
GitHub 仓库:https://github.com/apache/incubator-horaedb
官方网站:https://horaedb.apache.org(即将揭晓,敬请期待)
订阅邮件组:dev-subscribe@horaedb.apache.org
官方小蜜微信号:ApacheHoraeDB
微信公众号:Apache HoraeDB
