




有关注公众号朋友私信我,问我能不能写一写关于数据库对存储的一些要求。我想这个也是一个比较有意思的话题,毕竟我们以前也经常帮助用户做一些硬件规划和咨询。这个话题比较大,首先数据库种类太多了,不同数据库对硬件的要求有所差异,这里我还是以主流的几种关系型数据库来展开这篇小作文吧!
数据库对于硬件资源的需求,实际上无非就几大类,CPU、内存、IO、网络 4个大的方面。随着这些年硬件技术的快速发展,实际上很少有客户面临一些硬件资源瓶颈了;其次对于硬件的需求,我认为应该从业务角度进行评估,这样才能相对准确的知道,大概什么的资源是可以满足我们业务系统稳定运行的。
这里我熟悉以自己最为熟悉的Oracle为例,假定某省级系统数数据量10T左右,连接数预计5000,每年业务增长(数据量20%增幅),那么我们来简单计算一下。如如果是Oracle RAC,我们在估算CPU、内存资源的时候,需要考虑到单点故障,当单节点存活的情况之下,同时为了确保性能,其CPU资源消耗不要超过90%,如果有可能更一点最好。如果从这样角度来看,正常运行的情况之下,两节点集群,每个节点cpu使用量不超过40%是相对合理的,注意要去看评估资源的消耗峰值。
对于内存来讲,从Oracle 11g开始,但进程的内存消耗超过10M,如果你连接达到5000,那么就需要至少50GB的pga参数设置;同时根据业务模型,假定是OLTP系统,5000连接,并发500的话,QPS 假定5000,平均每个SQL都非常高效,平均访问10个block(比较理想的情况是一个sql控制在5个block的访问甚至更低),默认8k的block size;那么每秒就读取大概400MB左右,如果我们为了避免物理读,我们应该设置多大的Buffer cache算合适呢?我们来看一下某大型客户核心系统的实际数据:
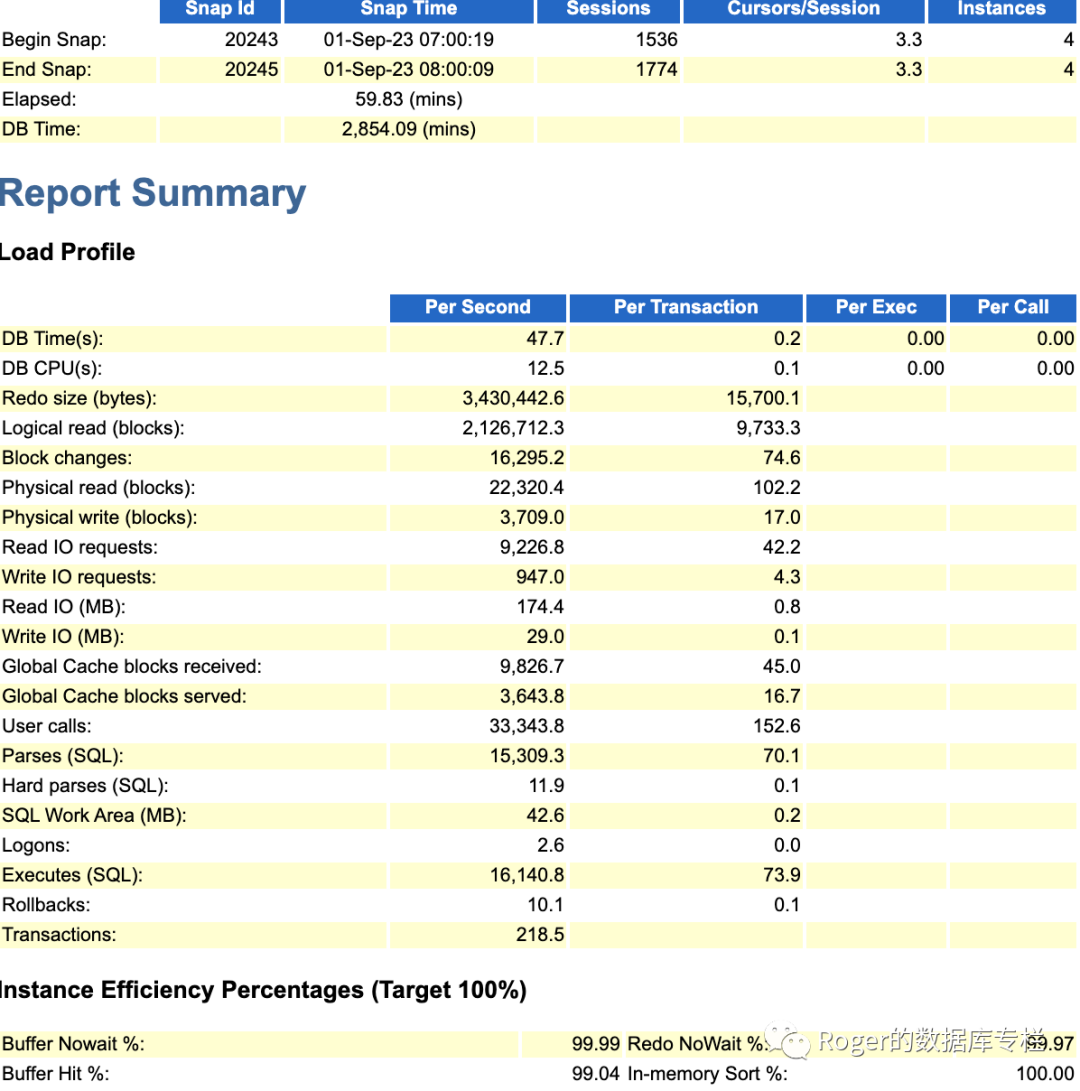
我们可以看到这个客户的核心Oracle RAC是4节点集群,单节点高峰SQL每秒执行量是16000左右,每秒逻辑读诗16G左右,此时buffer cache命中率在99%,算是一个比较不错的数据。同时物理读每秒大概是174MB.而该实例的buffer cache实际大小设置是200GB,也就是说每秒的逻辑读大小小于Buffer cache size的1/10;每秒物理读IO 大约是Buffer cache大小0.01%左右。当然这里客户的机器配置相对较高,所以配置相对略大一些,其次是考拉到了4节点集群,如果某些节点出现故障,那么压力会转移到存活节点,此时对硬件资源要求就高一些。
所以就拿上面的case来讲,虽然目前单节点cpu使用率15%不到,然而如果4个节点的集群宕掉3个,那么一个节点可能就需要扛住接近8000个数据库连接,每秒SQL执行量在7万左右,这就是一个相对比较大的数据了。因此配置数百core cpu也就能理解了。
同时做资源规划的时候,我们通常还要预留30%的资源富余,以定对突发情况吧,因为没有人能真正准确的评估出具体的资源需求,业务毕竟是动态变化的。
说完内存,我们再来讲解存储IO和存储空间需求。对于存储IO的需求,我们通常是根据业务的查询量来判断,不过这个也非常笼统,差异太大;实际上之前我也讲过,这主要还要看应用,如果应用代码质量较差,那么可能对存储IO要求就要高很多。其次是存储空间,如果是Oracle ASM,那么首先在划分逻辑卷的时候,我们要考虑损耗。以我们前段时间实施的一套zData分布式集群为例;客户使用的是单块7.68T的NVME SSD,每个节点插了16块盘。我们在划分存储池的时候,最好发现单块盘实际上可用容量大概在6.99T,损耗在8%左右,然后再进行一次逻辑卷划分(还需要考虑到ASM 冗余方式,Failgroup等等),因此最好单个LUN大概计算下来是在1.7T左右是相对合理的。最终存储池划分完毕之后,整个磁盘使用量在95%左右。
当然除了分布式存储,现在市面上大量的集中式存储性能也不错了,也有很多全闪阵列,性能也都很高,足以满足大部分业务系统。毕竟并非所有客户的系统对IO要求都很高(吞吐、延迟、IOPS等)。
讲完Oracle数据库,我们再来说说其他的国产数据库,比如目前最火的分布式数据库OceanBase,先来看看OceanBase官方文档对于资源的需求说明:
以下数据来自OB官方文档:
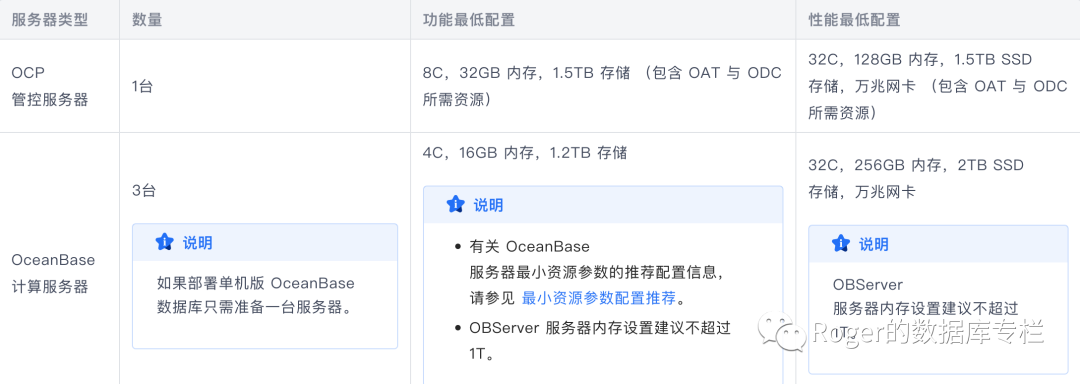
因为OB是分布式数据库,因此完全不需要存储阵列了,也不需要分布式存储了,只需要一堆X86服务器即可。那么对于x86服务要求来讲,如果要跑企业级业务,那么性能最低配置要求是32c/256G + 2TB SSD+万兆网卡。实际上之前看到某些客户的OBServer配置还是蛮高的,都是96core/512G内存,本地磁盘3T SSD+。
我们再来看看TiDB的生产部署要求:
-以下数据来源于TiDB官方文档
| 组件 | CPU | 内存 | 硬盘类型 | 网络 | 实例数量(最低要求) |
|---|---|---|---|---|---|
| TiDB | 16 核+ | 48 GB+ | SSD | 万兆网卡(2 块最佳) | 2 |
| PD | 8 核+ | 16 GB+ | SSD | 万兆网卡(2 块最佳) | 3 |
| TiKV | 16 核+ | 64 GB+ | SSD | 万兆网卡(2 块最佳) | 3 |
| TiFlash | 48 核+ | 128 GB+ | 1 or more SSDs | 万兆网卡(2 块最佳) | 2 |
| TiCDC | 16 核+ | 64 GB+ | SSD | 万兆网卡(2 块最佳) | 2 |
| 监控 | 8 核+ | 16 GB+ | SAS | 千兆网卡 | 1 |
注意
生产环境中的 TiDB 和 PD 可以部署和运行在同一台服务器上,如对性能和可靠性有更高的要求,应尽可能分开部署。
强烈建议分别为生产环境中的 TiDB、TiKV 和 TiFlash 配置至少 8 核的 CPU。强烈推荐使用更高的配置,以获得更好的性能。
TiKV 硬盘大小配置建议 PCIe SSD 不超过 4 TB,普通 SSD 不超过 1.5 TB。
TiFlash 支持多盘部署。
TiFlash 数据目录的第一块磁盘推荐用高性能 SSD 来缓冲 TiKV 同步数据的实时写入,该盘性能应不低于 TiKV 所使用的磁盘,比如 PCIe SSD。并且该磁盘容量建议不小于总容量的 10%,否则它可能成为这个节点的能承载的数据量的瓶颈。而其他磁盘可以根据需求部署多块普通 SSD,当然更好的 PCIe SSD 硬盘会带来更好的性能。
TiFlash 推荐与 TiKV 部署在不同节点,如果条件所限必须将 TiFlash 与 TiKV 部署在相同节点,则需要适当增加 CPU 核数和内存,且尽量将 TiFlash 与 TiKV 部署在不同的磁盘,以免互相干扰。
TiFlash 硬盘总容量大致为:
整个 TiKV 集群的需同步数据容量 TiKV 副本数 * TiFlash 副本数
。例如整体 TiKV 的规划容量为 1 TB、TiKV 副本数为 3、TiFlash 副本数为 2,则 TiFlash 的推荐总容量为1024 GB 3 * 2
。用户可以选择同步部分表数据而非全部,具体容量可以根据需要同步的表的数据量具体分析。TiCDC 硬盘配置建议 500 GB+ PCIe SSD。
| 组件 | 磁盘空间要求 | 健康水位使用率 |
|---|---|---|
| TiDB |
| 低于 90% |
| PD | 数据盘和日志盘建议最少各预留 20 GB | 低于 90% |
| TiKV | 数据盘和日志盘建议最少各预留 100 GB | 低于 80% |
| TiFlash | 数据盘建议最少预留 100 GB,日志盘建议最少预留 30 GB | 低于 80% |
| TiUP |
| 不涉及 |
| Ngmonitoring |
| 不涉及 |
其他的我们先不管,单就看存储层面,会有这样一句话:
TiKV 硬盘大小配置建议 PCIe SSD 不超过 4 TB,普通 SSD 不超过 1.5 TB。
由此可见,tidb对存储性能也是有要求的,比如你使用大容量的SATA SSD,那性能估计也上不去;建议是使用PCIe或者 SAS ssd会好一点。
总之,对于share-nothing架构的分布式数据库来讲,我认为对于硬件尤其是存储磁层的要求差不了太多。
最后我们再来看看集中式国产数据库,比如达梦、金仓、MogDB等等对于硬件的要求。
如下是达梦的官方安装文档对于硬件的要求:
| 关注点 | 结果 | 查询方式 |
|---|---|---|
| 明确部署架构 | 单机/集群。 | 正式版参照软件授权许可证。 |
| 是否安装操作系统 | 是/否。 | 建议不要最小化安装。 |
| tar 命令 | 需要安装。 | tar -help注意:缺失 tar命令会导致数据库无法安装。 |
| CPU 信息 | CPU 架构、颗数、核心数。 | lscpu |
| 存储划分及挂载 | 原则建议分 3 块盘符,分别是 dmdata 实例盘、dmbak 备份盘和 dmarch 归档盘。 原则盘符分配建议: 例如数据总量约为 50G 情况下 dmdata=100G(涉及 temp 和 ROLL 的扩展),dmbak=200G(涉及两次全量 + 多次增量),dmarch=50G 数据库软件安装可以默认到系统盘符,建议空间不要低于200G,应考虑 core 文件、日志文件的使用情况。 若不具备条件,可以使用一块盘符。 | 1、fdisk -l查看所有盘符信息,明确盘符使用是否正确; 2、 blkid dev/sda查看盘符 uuid; 3、 cat etc/fstab查看盘符故障点,应通过盘符 uuid 进行挂载。 |
| UPS 和 raid 卡电池情况 | 衡量标准:机房有没有 UPS、存储 raid 卡是否有电池,是否可以保障服务器持续工作、关闭服务器前是否能正常关闭数据库服务。如果满足的话,建议磁盘缓存开启,因为开启可以提高硬盘的读写速度;如果不满足要求,为保障数据的完整性和安全性,建议关闭。建议尽量能够满足服务器持续服务的要求。 | 1、Windows 环境:打开“设备管理器”窗口,然后双击“磁盘驱动器”设备,展开驱动程序,在展开的设备中,单击右键。选择“属性”命令。在弹出的硬盘属性对话框中,切换到“策略”选项卡,然后选中“启用设备上的写入缓存”复选框,然后单击“确定”按钮。 2、Linux 环境: hdparm -W 1 dev/sda,参数 1:开启,参数 0:关闭。 |
| 端口确定 | 确定是否可用。 | Telnet 用法:telnet ip port。 |
| 网络环境是否具备 | 网卡个数及带宽集群环境原则要求提供不低于 1000M 的心跳网络。 | ifconfig网卡设备。 |
对于需要什么型号或者什么性能的存储或者是磁盘,我们看到没有任何建议。这可能是因为达梦的文档相对较老的原因。根据个人的实际经验;我认为如果是一个系统从Oracle平移到达梦数据库,那么你的硬件配置最起码不能比之前低,实际上存储层还要更高才行(之前我讲过达梦不支持多块写,因此对IOPS要求会更高);不过就现在市面上的SSD来讲,无论是SAS还是PCIe ,我想足以支持99%的业务系统了。当然容量大小又是另外一个话题。
同样金仓数据库对于硬件的要求也类似:

我们可以看到其实也不高,而且描述非常之简单。
最后我们来看看MogDB的安装要求:
| 项目 | 配置描述 |
|---|---|
| 内存 | 功能调试32GB以上。 性能测试和商业部署时,单实例部署建议128GB以上。 复杂的查询对内存的需求量比较高,在高并发场景下,可能出现内存不足。此时建议使用大内存的机器,或使用负载管理限制系统的并发。 |
| CPU | 功能调试最小1×8 核,2.0GHz。 性能测试和商业部署时,单实例部署建议1×16核,2.0GHz。 CPU超线程和非超线程两种模式都支持。但是,MogDB各节点的设置需保持一致。 |
| 硬盘 | 用于安装MogDB的硬盘需最少满足如下要求: - 至少1GB用于安装MogDB的应用程序。 - 每个主机需大约300MB用于元数据存储。 - 预留70%以上的磁盘剩余空间用于数据存储。 建议系统盘配置为RAID1,数据盘配置为RAID5,且规划4组RAID5数据盘用于安装MogDB。有关RAID的配置方法在本手册中不做介绍。请参考硬件厂家的手册或互联网上的方法进行配置,其中Disk Cache Policy一项需要设置为Disabled,否则机器异常掉电后有数据丢失的风险。 MogDB支持使用SSD盘作为数据库的主存储设备,支持SAS接口和NVME协议的SSD盘,以RAID的方式部署使用。 |
| 网络要求 | 300兆以上以太网。 建议网卡设置为双网卡冗余bond。有关网卡冗余bond的配置方法在本手册中不做介绍。请参考硬件厂商的手册或互联网上的方法进行配置。 MogDB网络如果配置bond,请保证bond模式一致,不一致的bond配置可能导致MogDB工作异常。 |
上述文档很大一部分是从openGauss转移而来,实际上根据我们的各行各大客户的实际部署生产的经验来看,存储层我们建议都是SSD,最起码要配置SATA SSD,机械盘通常是不建议使用的,除非你是测试环境或者非常小型的业务系统。
最后我们来简单总结一下:
1、 分布式数据库对于硬件环境的要求,尤其是存储层,可参考厂商的建议配置;其次各家分布式数据库的要求差不多并不大,毕竟都是share-nothing架构;无非就是一堆x86服务器+磁盘而言。
2、对于集中式数据库来讲,如果要进行评估,那么计算能力方面,我认为最起码不能比之前Oracle/MySQL环境低,其次对于存储层,都建议使用SSD。毕竟大部分数据库的写能力是比Oracle之类的要差很多的。
3、就现在SSD的价格来说,其实我认为都不是什么大问题了,至于说数据库使用存储阵列,那么同样的道理,根据IO能力去测算就知道了。
4、无论是分布式数据库还是集中式数据库,我们在进行硬件规划时,都需要考虑一定的冗余能力,扩展能力。
