赛题名称: 谷歌AI模型运行时间预测 赛题类型:深度学习、TPU 赛题链接👇:
https://www.kaggle.com/competitions/predict-ai-model-runtime/overview
比赛介绍
Alice是一个人工智能模型开发者,但她的团队开发的一些模型运行速度非常慢。最近,她发现编译器的配置可以改变编译器编译和优化模型的方式,从而使模型运行速度更快(或更慢)!你的任务是帮助Alice找到每个模型的最佳配置。
比赛目标:根据训练数据集中提供的运行时数据,训练一个机器学习模型,并进一步预测测试数据集中图形和配置的运行时。
关于AI编译器的一些技术背景将有助于你入门!一个AI模型可以表示为一个图,其中一个节点是张量操作(例如矩阵乘法、卷积等),一条边表示一个张量。编译配置控制编译器如何为特定的优化传递来变换图。具体来说,Alice可以控制两种类型的配置/优化:
布局配置 控制图中张量在物理内存中的布局,通过指定每个操作节点的输入和输出的维度顺序。 块配置 控制融合子图的块大小。
能够预测给定图形的最佳配置不仅有助于Alice的团队,还可以改进编译器选择最佳配置的启发式算法,无需人工干预。这将使AI模型更有效地运行,总体上消耗更少的时间和资源!
在这个竞赛中,你的目标是根据训练数据集中提供的运行时数据训练一个机器学习模型,并进一步预测测试数据集中图形和配置的运行时。
比赛数据集
我们的数据集名为TpuGraphs,是关于在张量处理单元(TPUs)v3上运行的XLA HLO图的性能预测数据集。总共有5个数据集合:layout:xla:random
、layout:xla:default
、layout:nlp:random
、layout:nlp:default
和 tile:xla
。最终得分将是所有集合的平均值。要下载整个数据集并查看更多信息,你可以转到数据选项卡。
基线模型
我们提供了基线模型以及一个已准备好的训练设置,供你开始使用,网址是:https://github.com/google-research-datasets/tpu_graphs。请参考我们的数据集论文以获取有关基线模型的详细信息。
评估指标
根据实际需求,我们使用两个评估指标,并对它们求平均。具体来说,对于集合 tile:xla
,我们使用 (1-slowdown)
指标来反映模型预测的前K个配置相对于实际最快配置的速度减慢程度,计算方法如下:
其中,K 是前K个预测,A 是来自数据集集合的给定图形的所有配置,y 是测量的执行时间。
对于集合 layout:*
,我们使用 Kendall Tau 相关性作为评估指标(一种排名度量:您的模型预测的排名与实际运行时间排名的匹配程度)。
选择这些指标的原因如下。对于 tile 大小的搜索空间,由于可能性相对较小,可以列举所有可能性,并在每个可能性上调用模型,然后选择模型建议的最佳几个(这里是5个)配置,针对每个配置编译,然后测量每个配置的运行时间并提交最佳结果。另一方面,对于 layout:*
集合,搜索空间相当大。因此,常见的搜索策略,如遗传算法、模拟退火和朗格温动力学,需要访问一个适应度/效用函数(可以是您的模型)。因此,模型能够很好地保持配置的顺序(从最快到最慢)非常重要。
提交文件
您的提交必须是一个带有标题 ID,TopConfigs
的 csv
文件。每个 npz/**/test/*.npz
文件(参见数据)必须在 csv
文件中有一行。
ID 是 {collection}:{test_filename_without_extension}
,其中 collection 是以下之一:tile:xla
、layout:xla:random
、layout:xla:default
、layout:nlp:random
和layout:nlp:default
。TopConfigs 应列出根据您的模型预测,从最快(运行时间最短)到最慢(运行时间最长)的配置的索引,用分号分隔。 对于 tile:xla
集合,只有前5个条目将被考虑,其余将被忽略。对于 layout:*
集合,将考虑所有条目(您应该输出配置数量的排列)。有关示例提交文件,请从数据选项卡下载 sample_submission.csv
。
数据集描述
(推荐)从此页面下载。请下载 npz_all
zip文件(在此页面底部滚动,右侧找到"Data Explorer",点击npz_all
目录,然后点击"Data Explorer"面板左侧的下载图标。然后将此文件解压缩到路径~/data/tpugraphs
。您可以从tensorflow.org下载数据集。您可以按照我们的GitHub存储库上的说明进行下载,或者运行 curl https://raw.githubusercontent.com/google-research-datasets/tpu_graphs/main/echo_download_commands.py | python | bash
命令,该命令会自动下载到~/data/tpugraphs
目录。
在上述任何选项之后,您的最终数据路径应该包含~/data/tpugraphs/npz/layout
和~/data/tpugraphs/npz/tile
。默认情况下,训练脚本(请参阅GitHub存储库)从~/data/tpugraphs
读取数据,但您可以在train_lib.py或layout集合的训练器中覆盖标志--data_root
。
数据集描述
一旦您已经下载了数据集(例如,到~/data/tpugraphs
,这是训练代码的默认路径),并解压缩它,您将获得以下目录结构。
npz/tile/xla/{train, valid, test}/*.npz
:包含瓦片集合的.npz
文件。npz/layout/{nlp, xla}/{random, default}/{train, valid, test}/*.npz
:包含布局集合的.npz
文件。
优胜方案
第一名
https://www.kaggle.com/competitions/predict-ai-model-runtime/discussion/456343
对于布局,只有 Convolution
、Dot
和 Reshape
是可配置的节点。同时,在大多数情况下,配置集中的大多数节点在整个配置集中是相同的。因此,采用了一个简单的修剪策略,即对于每个图,只保留那些是可配置模型本身或与可配置节点连接的节点,即与可配置节点相连的输入或输出节点。通过这种方式,他们将一个大图转换为多个(可能是不连通的)子图,这对于网络有一个在最后进行全局图池化的层,从而将子图的信息融合在一起。这个简单的技巧将 vRAM 的使用减少了 4 倍,并在某些情况下提高了 5 倍的训练速度。
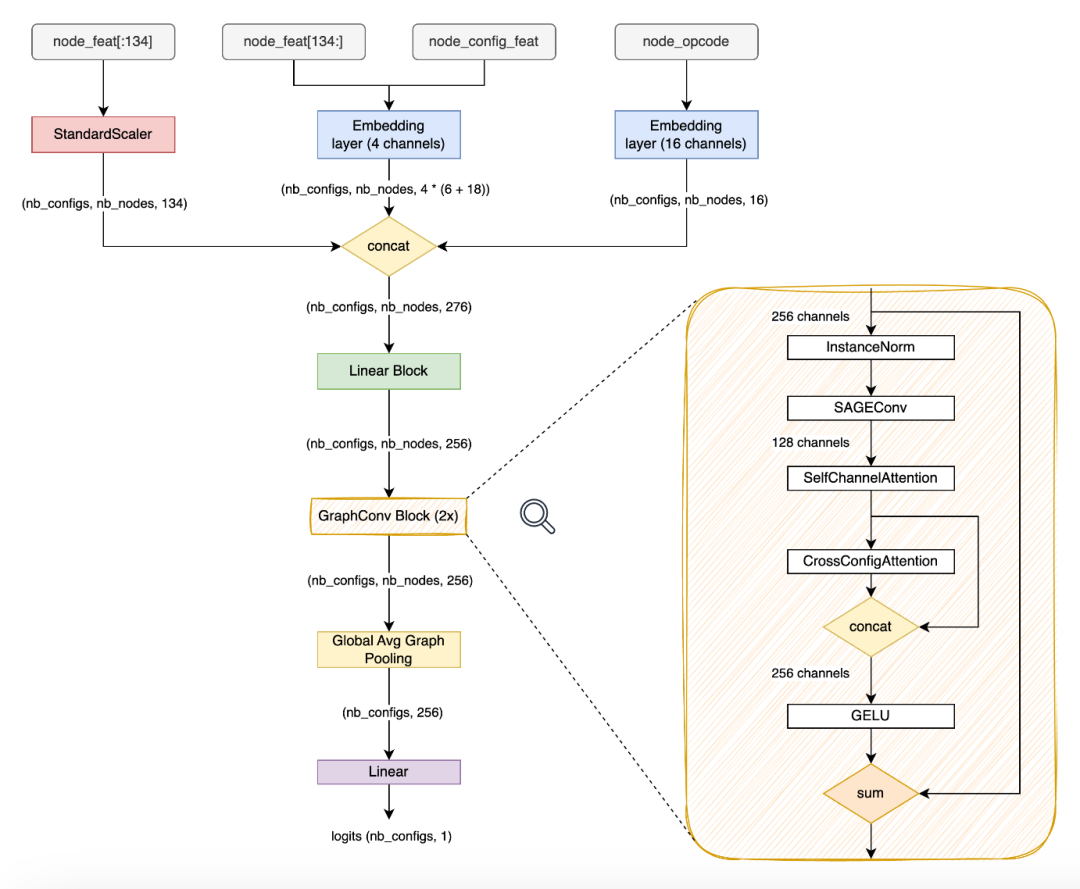
对于布局,将 node_feat
划分为 node_feat[:134]
和 node_feat[134:]
(layout_minor_to_major_*
)。前者仅使用 StandardScaler
进行标准化,而后者以及 node_config_feat
则输入到一个学习的嵌入矩阵(4 通道)中。他们发现这里的标准化是必不可少的,因为 node_feat
具有像 *_sum
和 *_product
这样的特征,这些特征可能非常高,从而干扰优化。
对于 node_opcode
,他们还使用了一个具有 16 个通道的单独嵌入层。网络的输入是前述所有特征的串联,对于每个图,他们在训练时动态抽样了 64(默认)或 128(随机)个配置来形成输入批次。对于 tile,他们选择使用后期融合来将 config_feat
集成到网络中。
网络架构
网络架构相对简单。首先,将输入特征传递给线性块,将其映射到 256 维嵌入向量,然后是 2x Conv 块、全局图均值池化和最终的线性层。
至于图卷积层本身,他们尝试了许多类型,但没有一种比 SAGEConv
更好。特别是,他们过去在 GAT 变体中有很好的经验,但在这个竞赛中没有一种效果比较好。如果要猜测原因,可能是因为在其他应用中,图本身非常嘈杂,因此注意力有助于“忽略”那些不重要的连接。然而,对于 TPU 图来说,所有的连接都是“真实”且重要的,所以图注意力并不那么有用。尽管如此,他们发现另外两种类型的注意力非常有用:自通道注意力和跨配置注意力。
自通道注意力
借鉴了 Squeeze-and-Excitation 的思想,创建了一个通道注意力层。首先,应用线性层来瓶颈通道维度(8 倍减少),然后应用 ReLU
。然后,应用第二个线性层,将通道再次增加到原始值,然后应用 sigmoid。最后,通过元素乘法将获得的特征映射与原始输入相乘。
其背后的思想是捕捉通道之间的相关性,并使用它来抑制不太有用的通道,同时增强其他通道。
跨配置注意力
可以利用注意力的另一个维度是批处理平面(跨配置)。他们设计了一个非常简单的块,允许模型在整个网络中显式地“比较”每个配置与其他配置。他们发现,与让模型单独为每个配置进行推断并仅通过损失函数(PairwiseHingeLoss
)隐含地进行比较相比,这种方式要好得多。注意力代码如下:
class CrossConfigAttention(nn.Module):
def __init__(self):
super().__init__()
self.temperature = nn.Parameter(torch.tensor(0.5))
def forward(self, x):
# x of shape (nb_configs, nb_nodes, nb_features)
scores = (x / self.temperature).softmax(dim=0)
x = x * scores
return x
通过在网络的每个块之后应用这个简单的层,对默认集合来说,这给了他们巨大的提升。对于推断,他们简单地使用了一个相当大的批次大小为 128。然而,由于预测取决于批次,他们可以进一步利用 TTA(测试时间增强)来生成 N
(10)个配置的排列,并在排序回原始顺序后取平均结果。
线性/卷积块设计
为了创建线性/卷积块,他们遵循计算机视觉中的良好实践。首先使用 InstanceNorm
对输入特征图进行归一化,然后是 Linear
/SAGEConv
层,SelfChannelAttetion
和 CrossConfigAttetion
(将输出与输入连接以保持每个样本的个性)。接下来,对残差连接进行求和,并以 GELU
和 dropout 结束。
集成
他们最好的单一模型预测在私有(public)LB 上得分为 0.714(0.748)。然而,由于某些集合的测试样本数量相对较低,他们选择使用集成来提高结果并防止波动。通过对每个集合使用 5-10 个模型的简单平均,他们获得的最佳结果是 0.736(0.757)LB,但遗憾的是他们没有选择这个提交。
未成功尝试的方法
在随机和默认数据上一起训练 在模型的嵌入/预测之上进行第二级堆叠 对测试集进行伪标记 针对测试集中的特定图进行微调模型 不同的配置采样方式,例如,在配置之间的运行时间距中使用退火 其他损失函数 梯度累积和同时训练多个图
第二名
https://www.kaggle.com/competitions/predict-ai-model-runtime/discussion/456365
https://github.com/Obs01ete/kaggle_latenciaga/tree/master
模型架构
训练5个模型,每个子集一个,使用不同的超参数。 所有GNN层都是SageConv层,当输入和输出通道数相同时使用残差连接。 节点类型嵌入为12维度。 对节点特征进行压缩,配置在Tile中广播到所有节点。 使用早期融合将节点类型嵌入、节点特征和配置组合成单个特征向量,然后传递给GNN层。 GNN层堆栈生成的特征转换为每个节点一个值,然后通过求和约简为单个图预测。
数据过滤
一些图的数据受到了破坏,例如, magenta_dynamic
的运行时与配置ID的演变表明这些不可能是同一图的测量。对于其他图,他们不能确定这些测量是在什么条件下进行的。
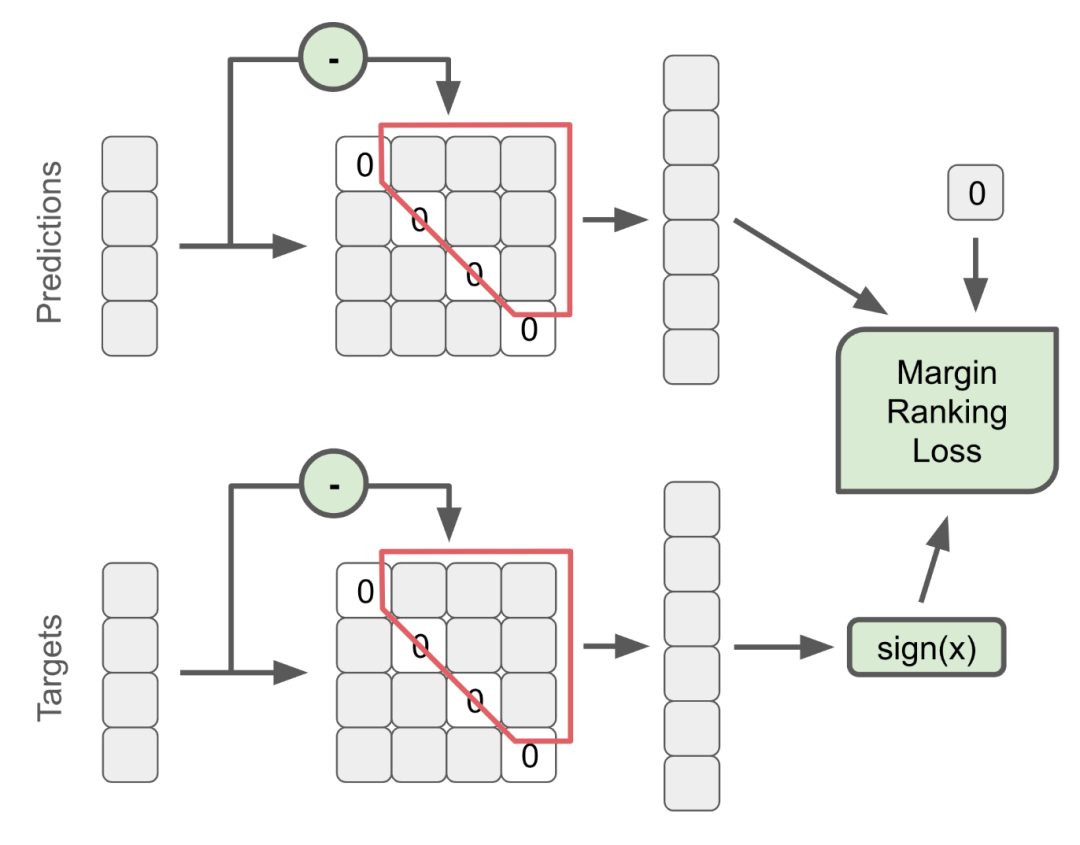
损失函数
使用ListMLE进行Layout-NLP的损失。 对于Tile,使用一种新颖的DiffMat损失。 对于Layout-XLA,使用DiffMat损失和MAPE损失的组合。
第三名
https://www.kaggle.com/competitions/predict-ai-model-runtime/discussion/456377
这是第三名在Google主办的"Fast or Slow? Predict AI Model Runtime"比赛中的解决方案。以下是解决方案的详细介绍:
该解决方案主要分为三个部分:次要特征提取和工程、对图进行调整(如剪枝),以及训练图神经网络(GNN)。GNN层基于GPS层,使用SAGE卷积,Linformers和可学习的位置编码。需要注意的是,此讨论主要涉及布局数据集。
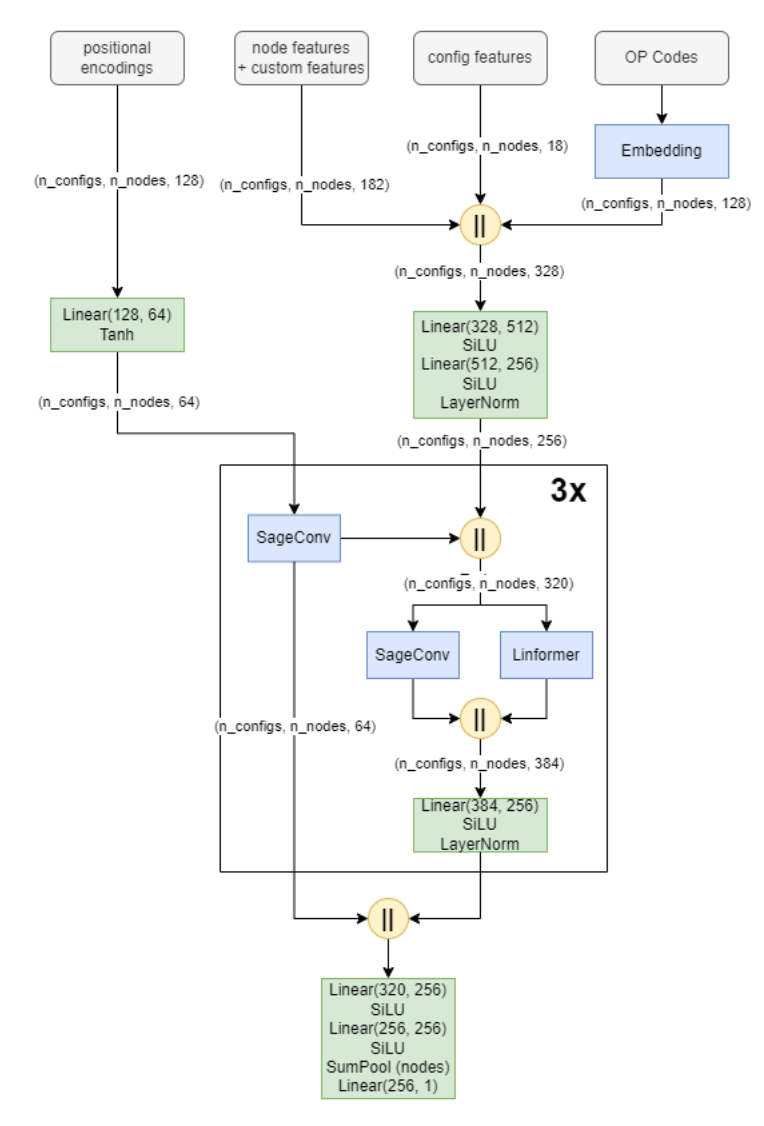
输入特征
使用了所有提供的140个输入特征,并对它们进行了简单的对数变换,使每个特征至少为1。此外,通过协议缓冲区,提取了以下特征:
has_dynamic_com
:指示图是否具有动态计算的标志。is_root_of_com
:指示节点是否为计算的输出节点的标志。indices_are_sorted
:我不确定为什么添加了这个标志。对于 dot
操作,提取了lhs_contracting_dimensions
,rhs_contracting_dimensions
,lhs_batch_dimensions
和rhs_batch_dimensions
,这些都是整数序列,我将它们填充到长度为3,因此总共有12个特征。对于 gather
操作,添加了整数序列offset_dims
,collapsed_slice_dims
和start_index_map
,填充到长度为3,单个整数index_vector_dim
和填充到长度为5的序列gather_slice_sizes
。
OP代码嵌入和位置编码
我使用128维度的嵌入来表示OP代码。对于位置编码使用了RWPE。我使用有向邻接矩阵创建了16维PE,使用无向矩阵创建了112维PE,总共128个特征。编码始终是使用完整图计算的,独立于网络训练期间使用的剪枝。
GNN
GNN包含SAGE卷积和Linfomer。架构如下图所示。SAGE卷积使用不同的权重和消息维度为输入维度的一半,同时使用输入和输出节点。Linfomer的维度设置为128(或某些实验中的256)。使用Sigmoid Linear Units(SiLU)激活函数和大量的层归一化。
第四名
https://www.kaggle.com/competitions/predict-ai-model-runtime/discussion/456462
class SimpleMLP(torch.nn.Module):
def __init__(self):
super().__init__()
self.embedding = torch.nn.Embedding(120,10)
self.config_dense = torch.nn.Sequential(nn.Linear(128+8, 1024),
nn.ReLU(),
nn.Linear(1024, 128),
nn.ReLU(),
)
self.node_dense = torch.nn.Sequential(nn.Linear(12*2+20, 1024),
nn.ReLU(),
nn.Linear(1024, 128),
nn.ReLU(),
)
self.output=torch.nn.Sequential(nn.Linear(128*128+128, 1024),
nn.ReLU(),
nn.Linear(1024, 1),
)
def forward(self,x_cfg,x_feat,x_op):
x_feat=x_feat.squeeze()
x_op=x_op.squeeze()
x_op = self.embedding(x_op).reshape(-1,20)
x_feat = torch.concat([x_feat,x_op],dim =1)
x_feat = self.node_dense(x_feat)
x_graph = x_feat.unsqueeze(0)
x_graph = x_graph.repeat_interleave(len(x_cfg),dim=0)
x_cfg = torch.concat([x_cfg,x_graph],axis=2)
x_cfg = self.config_dense(x_cfg)
x=(x_feat.T@x_cfg).reshape(len(x_cfg),-1)
x_cfg_mean=x_cfg.mean(dim=1)
x = torch.concat([x,x_cfg_mean],axis=1)
x=self.output(x)
x=torch.flatten(x)
return x
第五名
https://www.kaggle.com/competitions/predict-ai-model-runtime/discussion/456093
https://github.com/knshnb/kaggle-tpu-graph-5th-place
解决方案基于端到端的图神经网络(GNN)。作者实现了一个基于PyG的3层GraphSage。在每一层,作者通过不同的权重在边的两个方向上进行图卷积,并将输出连接在一起。作者训练了这个模型以最小化使用AdamW优化器和余弦退火调度器的成对hinge损失。
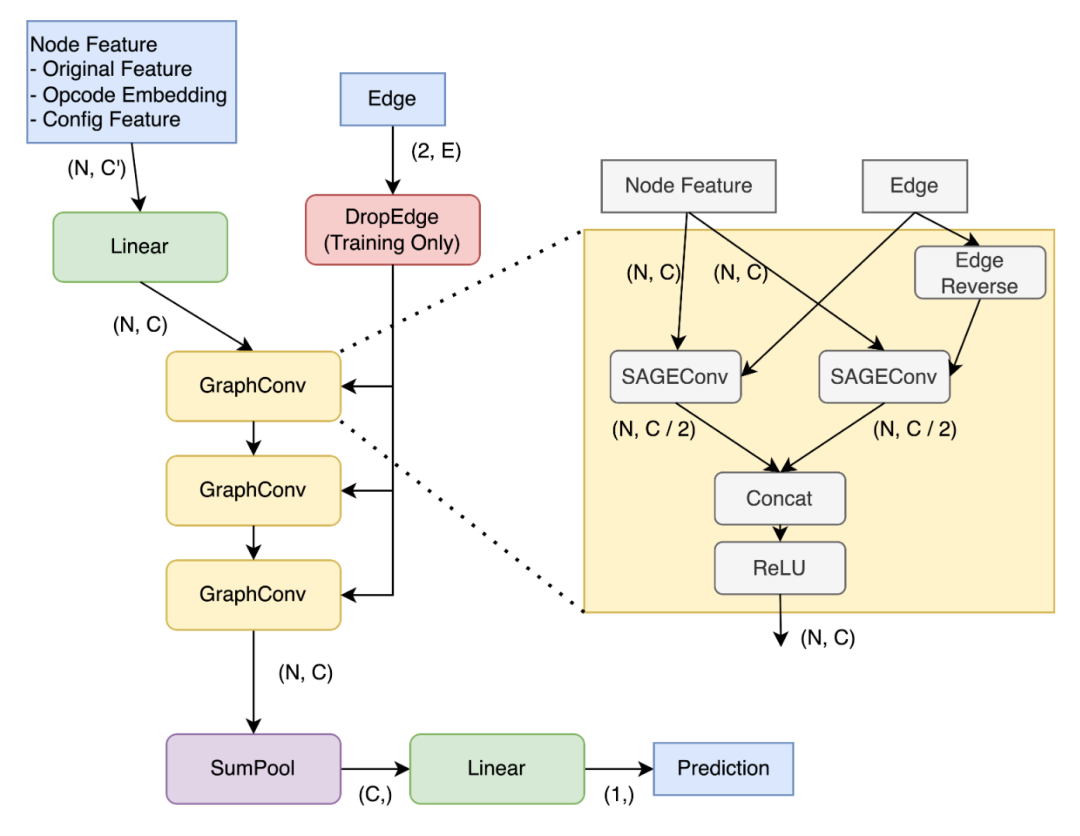
对于损失,作者使用同一图的不同配置之间的成对hinge损失的平均值,以及一个批次中所有样本(包括不同的图)之间的成对hinge损失的平均值。因此,作者没有使用子图,而是将整个图作为GNN的输入。
节点特征包括每个维度的30个特征(包括tile和layout配置)。一种简单的方法是将它们简单地展平(作者称之为naive模型),但作者考虑到以下两个缺点:
它丢失了关于维度之间特征对应关系的先验信息。 输出应该对维度的索引顺序无关(我不确定这是否完全正确)。
第六名
https://www.kaggle.com/competitions/predict-ai-model-untime/discussion/456084
图的缩减: 对于Tile运行时预测,由于Kaggle的训练数据中的图要小得多,不存在内存问题。这些实际上是更大原始计算图的子图。
归一化: 仍然使用"graph instance norm"(节点级别的图归一化)和相同的梯度积累方法,批大小为64。
尝试的GNN模型: 尝试了SAGE卷积[2]和GAT卷积[4]。实验证明,GAT卷积的效果更好。
损失函数: 由于对前5名的排名感兴趣,作者发现ListMLE是一个更好的损失函数。
第七名
https://www.kaggle.com/competitions/predict-ai-model-runtime/discussion/456673
Tile部分与官方代码非常相似。作者发现公共Tile代码的验证得分已经相当高,而集成它们并没有导致显著的改进,因此在这一部分没有投入太多时间。
对于Layout部分,作者主要参考了gst代码 https://github.com/kaidic/GST。然而,由于GPU内存限制,作者在使其高效运行方面遇到了一些挑战。最终,作者使用了一种采样方法来减少GPU的使用。
训练策略:
根据边缘和节点形状分别训练。虽然测试数据没有明确指定模型类型,但可以根据边缘和节点形状进行推断。 使用不同的参数,如图卷积类型、学习率、批大小、层数和隐藏大小。
第十名
https://www.kaggle.com/competitions/predict-ai-model-runtime/discussion/456129
关键思路是使用中间融合方法,以在计算效率和图表示的表达能力之间取得良好的平衡。中间融合允许在配置输入与图表示融合时使用,从而能够同时处理数千个配置和包含数万个节点的图,而没有显著的开销。这对于像listMLE这样的序列排名损失非常重要,因为每个批次中包含大量的配置。
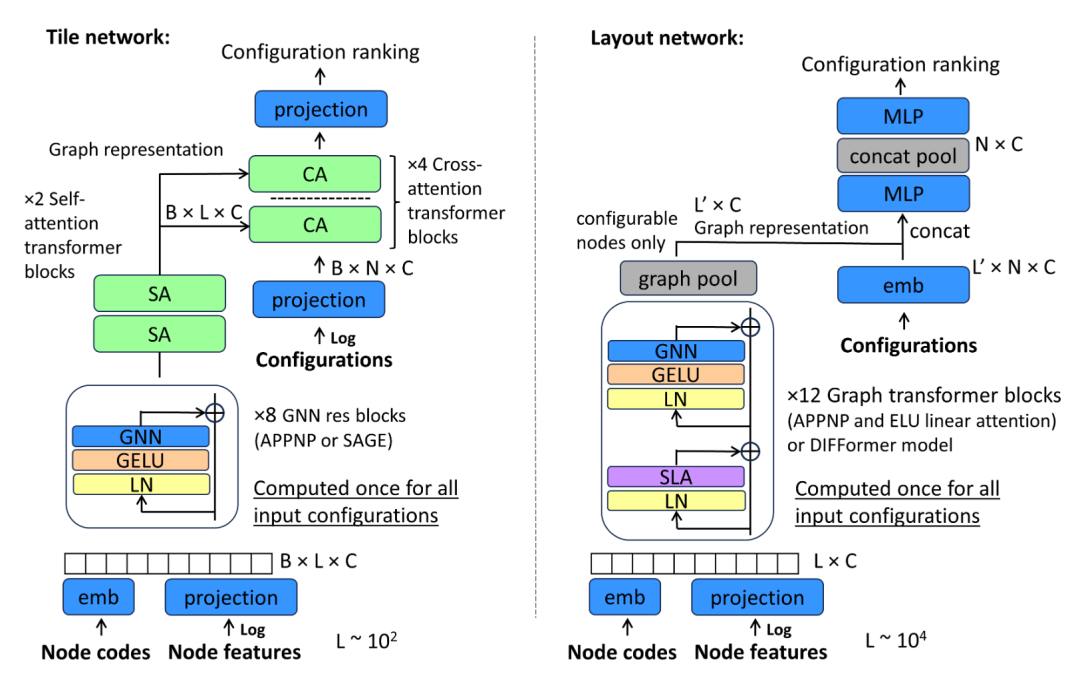
Tile部分
使用了一系列残差图块,能够在全局混合之前创建本地邻域表示。 使用自注意块进行全局混合,然后使用跨注意力Transformer块进行特定配置的节点信息检索。 在这种设置下,模型在Tile上的训练速度非常快,达到0.97以上的减速度指标只需不到1分钟。
Layout部分
使用了多头线性注意力代替标准点积注意力,具有线性复杂度,能够在整个10^4节点图上实现全局感受野。 使用图网络替换了Transformer块的MLP部分,从而实现了节点之间的局部特征混合。 考虑了多种图模块,包括APPNP、SAGE、GAT和GPRGNN,其中APPNP的效果稍好。
训练和评估:
使用标准的AdamW优化器、余弦退火和listMLE作为损失函数。 在XLA和NLP图之间进行了独立训练,因为它们在图大小和配置数量上有很大的差异。 采用了11折交叉验证,但由于时间有限,只运行了几个fold,以保持实验的多样性。
最终模型:
主要采用了运行尽可能多的配置并将它们混合在一起的策略,以减轻可能发生的波动效应。 使用了10-20个不同配置的XLA和NLP模型的组合,取得了0.712和0.696的公共和私有LB。 选取了他们最佳的公共LB提交,包括2个APPNP XLA模型和2个DIFFormer NLP模型,达到了0.721的公共LB和0.703的私有LB。 最佳的私有LB提交在APPNP模型中使用了门单元而不是残差和求和,达到了0.706的公共LB和0.715的私有LB。