赛题名称:移动广告营销场景下的人群召回算法挑战赛 赛题类型:数据挖掘 赛题任务:预测广告未来一段时间内可能会产生点击行为的用户集合。
比赛地址:https://challenge.xfyun.cn/topic/info?type=crowd-recall
视频答辩地址:https://www.bilibili.com/video/BV1nb4y1T7kr?p=48
赛题背景
移动互联网中的移动广告营销已经成为了企业推广产品和服务的重要手段之一。然而,在移动广告投放过程中,如何准确地找到目标人群并进行精准投放成为了一大难题,开发一种高效、准确的人群召回算法对于提高移动广告营销的效果具有重要意义。
为了解决这个问题,我们发起了“移动广告营销场景下的人群召回算法挑战赛”。通过本次比赛,我们希望能够促进移动广告营销领域的技术创新和发展,为企业提供更加精准、高效的广告营销服务。
赛事任务
本次大赛提供了移动广告端的一段时间的投放历史数据,参赛选手需要基于这些数据,预测广告未来一段时间内可能会产生点击行为的用户集合。
赛题数据
本次比赛为参赛选手提供了2类数据:广告历史投放数据和投放广告相关的图片数据。出于数据安全的考虑,有些数据做了脱敏处理,广告历史投放数据如下:
| 数据类别 | 变量 | 数据格式 | 解释 |
|---|---|---|---|
| 标签 | click | bigint | 点击标签 |
| 标签 | click_time | bigint | 点击时间 |
| 标签 | tracker | bigint | 是否唤起app |
| 广告 | creative_image_md5 | string | 创意携带图片md5 |
| 广告 | creative_texts | string | 创意携带文本title+desc |
| 广告 | master_id | string | 广告主id |
| 广告 | plan_id | string | 广告投放计划id |
| 广告 | campaign_id | string | 广告投放camaignid |
| 基础 | bid | bigint | 是否竞价 |
| 基础 | bid_floor | bigint | 竞价底价 |
| 基础 | bid_id | string | 竞价id |
| 基础 | bid_time | bigint | 竞价时间 |
| 基础 | imp_id | string | 曝光id |
| 基础 | is_session_uniq | bigint | 是否session唯一 |
| 基础 | view | bigint | 是否曝光 |
| 基础 | view_time | bigint | 曝光时间 |
| 基础 | win | bigint | 是否竞得 |
| 基础 | win_time | bigint | 竞得时间 |
| 流量 | media_id | string | 媒体id |
| 流量 | adx_app_id | string | 流量来源app_id |
| 流量 | adx_app_name | string | 流量来源app_name |
| 流量 | adx_app_pkg | string | 流量来源app_pkg包名 |
| 流量 | adx_slot_id | string | 外部广告位id |
| 流量 | agent_id | string | 代理商id |
| 流量 | carrier | string | 运营商 |
| 流量 | ip | string | ip地址 |
| 流量 | net_type | string | 网络类型 |
| 流量 | region_id | string | 区域id |
| 用户 | make | string | 手机 |
| 用户 | model | string | 机型 |
| 用户 | os | string | 操作系统 |
| 用户 | osv | string | 操作系统版本 |
| 用户 | uid | string | uid |
广告图片二进制文件集合image_set,image_md5.txt表示一个bytes二进制的图片。
评估指标
本模型依据提交的结果文件,采用recall@K指标进行评价。具体指标公式如下,对某一个图片
该指标具体解释为,给定一个query(本赛题为一个image_md5)和该query相关的真实目标集合T(本窓题是image_md5相关的点击用户uid集合),提交的结果集里的top 的集合为 。计算所有图片的平均的 recall@K:
为被点击过的图片数, 为 10 。
优胜方案
第一名



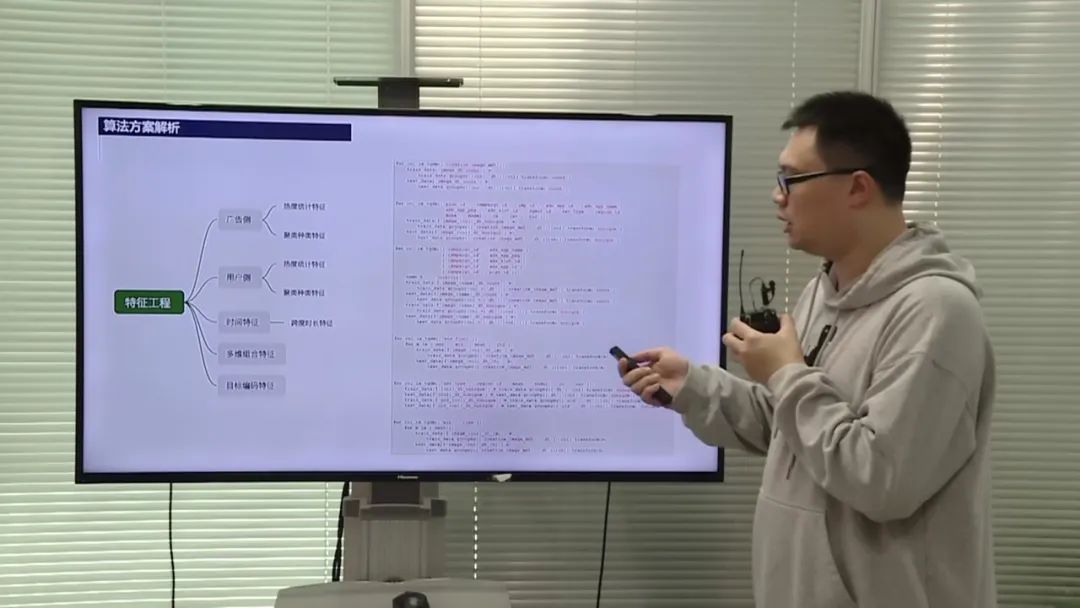
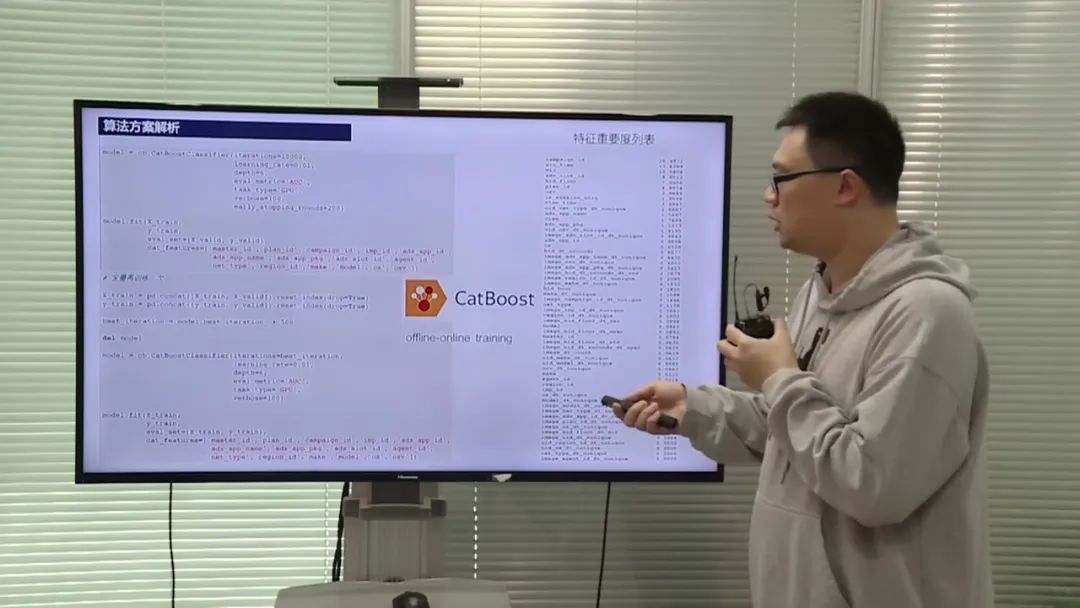
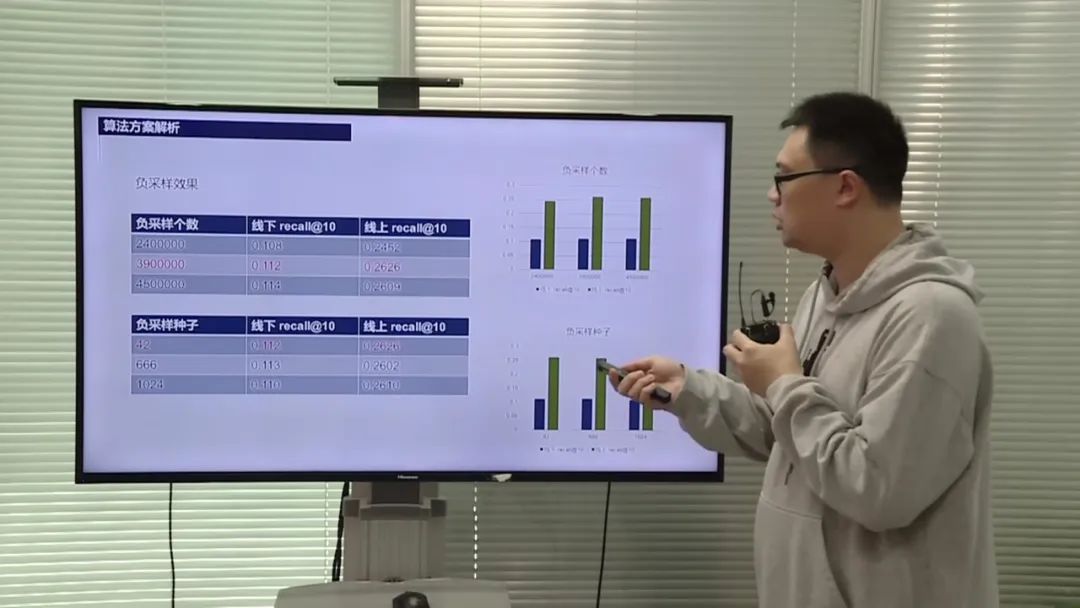
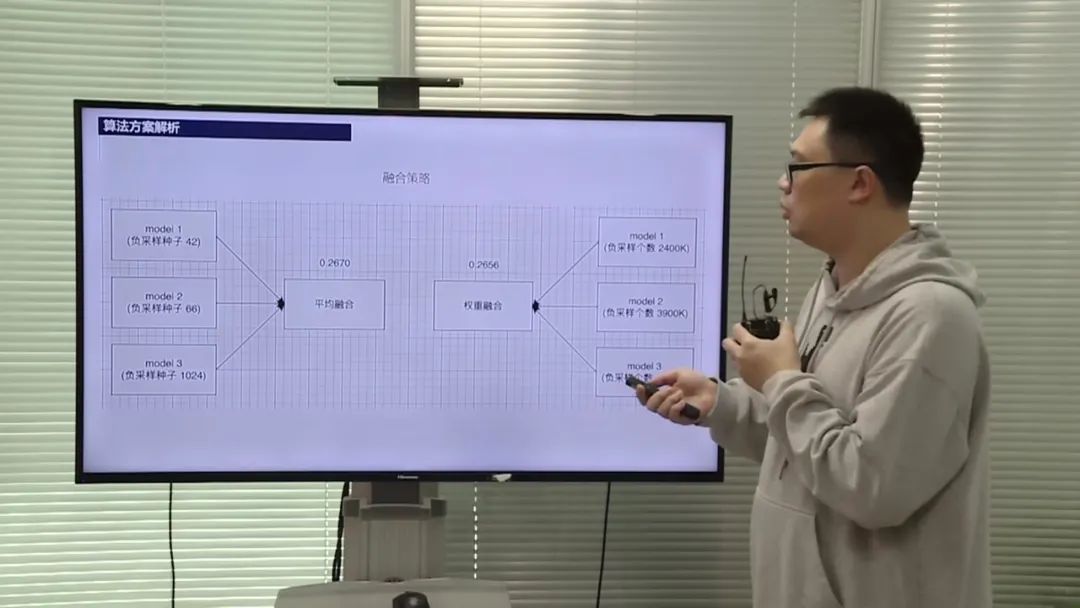
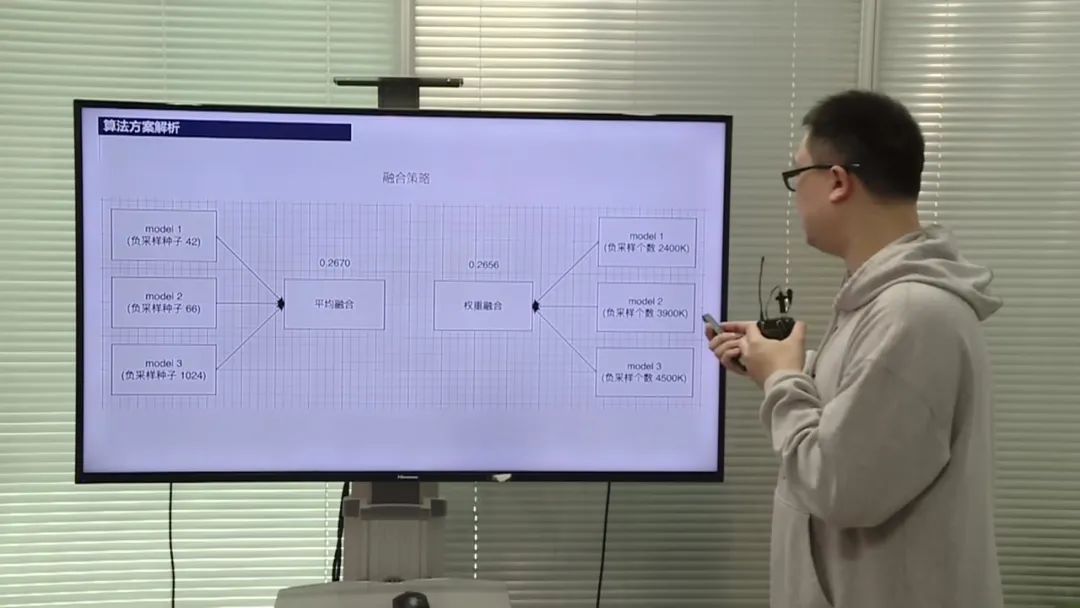

数据处理和特征工程
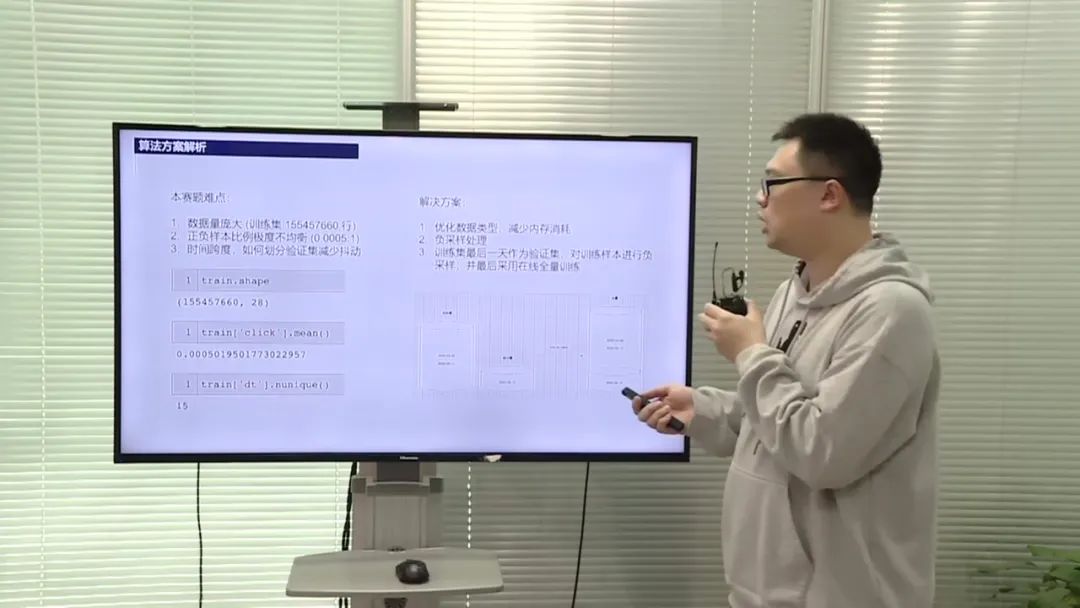
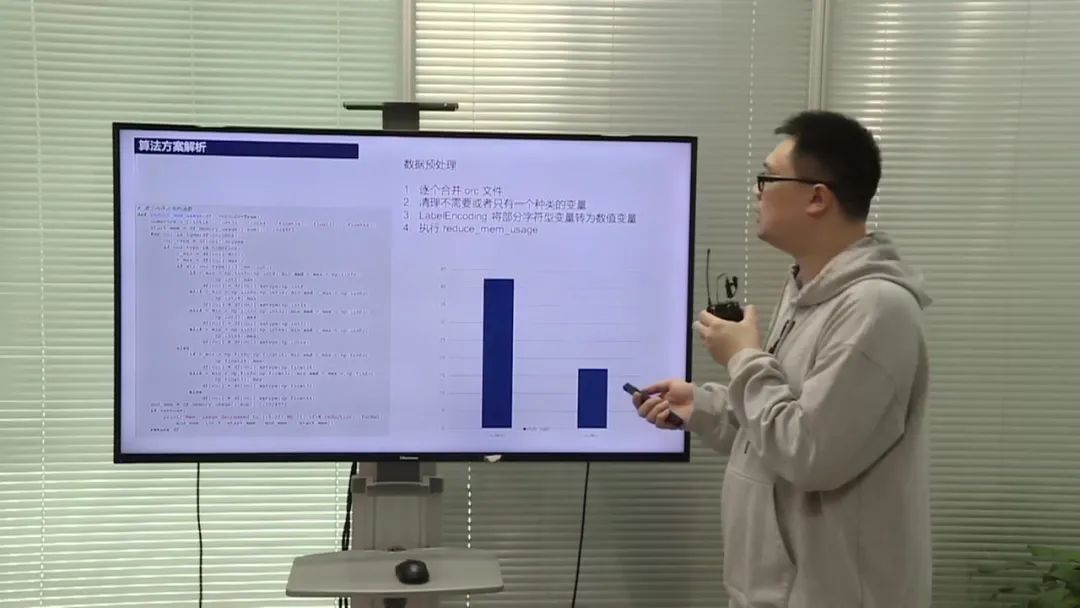
选手提到了数据量庞大、正负样本比例不均衡和时间跨度的问题。为了解决这些问题,他们采取了一系列的数据处理和特征工程方法。首先,他们使用了一些优化数据类型和减少内存损耗的方法,如逐个合并OCR文件、清理不需要的变量和将字符型变量转化为数值变量。其次,他们提取了用户、广告和流量等方面的特征,包括热度统计特征、聚类特征和实验特征等。最后,他们采用了特征重要度分析和特征选择方法,优化了特征的组合和选择。
模型训练和评估
选手使用了逻辑回归模型进行训练,并采用了offline-online的训练方式。他们将除了验证集之外的所有数据进行训练,得到最佳轮次后再将所有数据进行训练,并加上一定的轮次进行推断。选手还使用了交叉验证和特征重要度分析等方法对模型进行评估和优化。
模型融合
选手采用了多种模型融合的方法,包括副样本的融合和种子的融合。他们尝试了多组种子和副样本的组合,并选择效果最好的组合进行模型融合。
第二名









数据处理和特征工程
选手提到了数据量庞大、正负样本比例不均衡和时间跨度的问题。为了解决这些问题,他们采取了一系列的数据处理和特征工程方法。首先,他们提取了用户、广告和流量等方面的特征,包括统计特征、序列特征和实时特征等。其次,他们结合了用户和广告的信息,计算了用户对广告的点击次数、转化率等统计特征。最后,他们使用了一些常见的特征,如历史贡献次数、点击率和兴趣占比等。
模型训练和评估
选手使用了LightGBM、XGBoost和CatBoost等模型进行训练,并进行了模型融合。他们通过调整模型参数和特征选择,优化了模型的预测性能。选手还使用了交叉验证和特征重要度分析等方法对模型进行评估和优化。
特征工程的亮点
选手提到了实时特征的重要性,通过统计用户点击行为和广告曝光行为的时间差,捕捉用户的兴趣和行为变化。他们还尝试了用户序列特征的构建,但效果不明显。选手还提到了图片特征的重要性,但由于数据量和内存限制,没有深入挖掘。
第三名











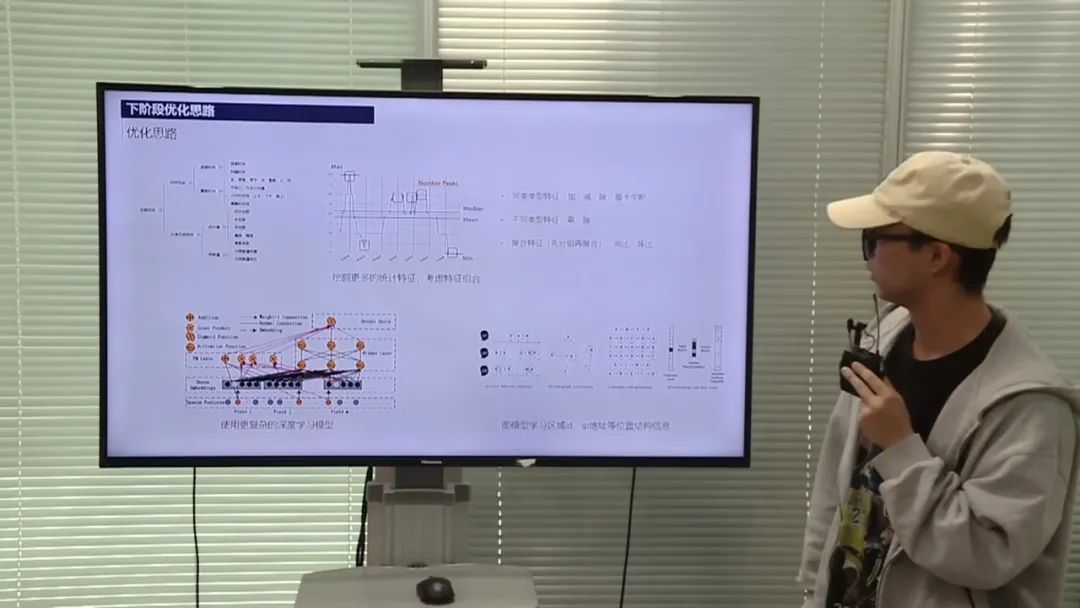
数据分析
对提供的广告历史投放数据进行分析,了解数据的特点和分布情况。发现除了广告标识字段以外,其他字段都没有缺失值,但有一些特征是错误的,有些被填充为零,广告数量本身很少。
特征工程
根据数据分析的结果,进行特征工程。将Creative Text作为ID类特征处理,不做Word特征。增加一些时间特征,如用户多少天之前点击的总量,反映用户的活跃度和广告的活跃度。以时间为单位,如周几、多少天等,构建一些特征。
数据划分
将数据划分为训练集和测试集,将标签设为0和1。使用XGBoost模型进行训练,并计算AUC指标来评估训练集和测试集的同分布性。
特征工程
异常数据处理:发现存在曝光时间为空但点击时间不为空的异常数据,将其剔除。 特征筛选:根据特征的重要性进行筛选,去除一些不重要的特征,以提高模型训练的效果。 特征工程进一步优化:增加一些时间特征,如用户多少天之前点击的总量,反映用户的活跃度和广告的活跃度。
模型优化
模型选择:尝试了XGBoost和DeepFM模型,发现DeepFM模型效果不好,可能是因为正负样本的差距较大,采样后效果仍不理想,最终选择了XGBoost模型。 参数调优:使用贝叶斯优化方法对模型的参数进行调优,以提高模型的性能。 采样处理:最开始没有进行采样,直接使用全量数据进行训练,后来发现正样本和复样本的比例太大,进行了采样处理。