使用工具是大型语言模型(LLMs)建立与物理世界联系,解决社会需求的有效途径。为了评测现有LLMs在工具学习上的各种能力表现,复旦大学自然语言处理实验室建模七个真实场景,收集568个真实工具,从五个维度开展细粒度分析,揭示了目前LLMs对场景的偏好和思维的局限,表明工具学习任务并非可以通过简单的增加模型参数量解决。
访问 https://arxiv.org/abs/2401.00741
或点击 阅读原文 获取原文链接

论 文 内 容
Abstract
现有的工具学习评估主要侧重于验证大型语言模型(LLMs)所选工具与预期结果的一致性。然而,这些方法依赖于答案是可以预先确定的有限场景,无法充分反映真实需求。此外,只强调结果的评测忽视了 LLMs 有效利用工具所必需的复杂能力。
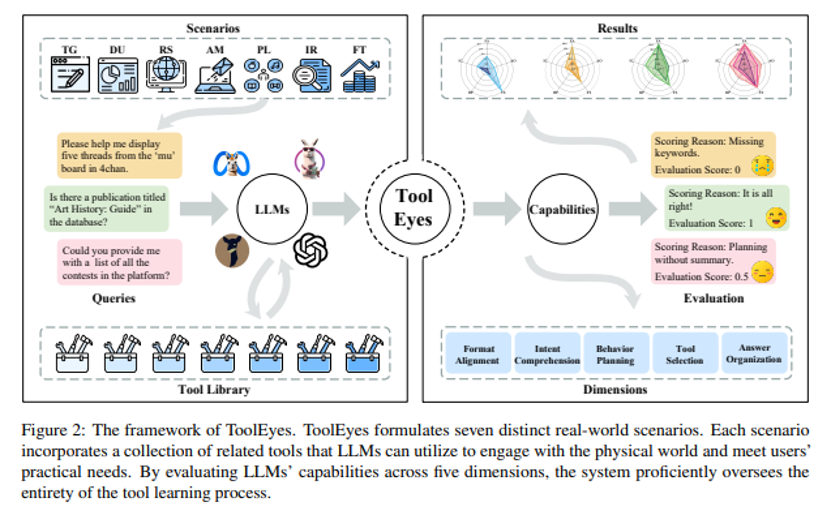
为了解决这个问题,我们提出了ToolEyes,专门用于细粒度评估LLMs在真实场景中工具学习能力。该系统建模了七个真实场景,分析了LLMs在工具学习中至关重要的五个能力维度:格式对齐、意图理解、行为规划、工具选择和答案组织。
此外,ToolEyes 还集成了一个拥有约 600 种工具的工具库,作为 LLMs 与物理世界之间的接口。对三种来源的十个 LLMs 进行的评估显示,在工具学习中,LLMs 具备场景偏好性,且其思维能力有限。更有意思的是,扩大模型规模甚至会加剧工具学习的障碍。这些发现为推动工具学习领域的发展提供了具有启发性的见解。
具体工具集和评测数据已开源:
https://github.com/Junjie-Ye/ToolEyes.git
场景构建
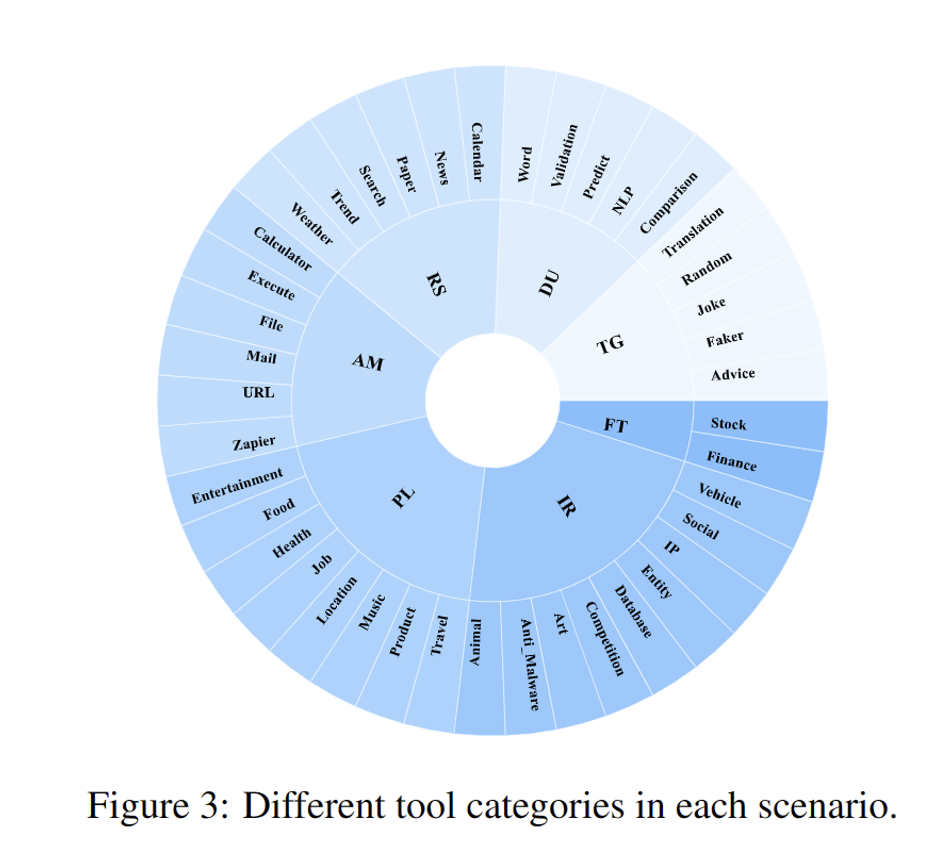
为了扩大工具学习的应用范围,捕捉错综复杂的物理世界,我们构建了七个真实世界场景:
文本生成 (TG) 是一种极具代表性的通用场景,它要求 LLMs 生成符合用户需求的文本,同时遵守查询的体裁、格式、字数和其他规范。典型的用户文本生成请求包括建议、笑话、翻译等。
数据理解 (DU) 囊括了一种专门的需求场景,在这种场景中,LLMs 的任务是理解用户输入的数据,并根据用户需求从特定维度对其进行分析,包括情感分析、关系预测、有效性验证等。
实时搜索 (RS) 在物理世界中应用广泛,要求LLMs使用各种搜索工具收集与用户需求相关的信息。 随后,LLMs 负责将收集到的数据进行分析,并以自然语言文本的形式呈现给用户。
应用操作(AM)是一种特殊场景,要求 LLMs 根据用户请求选择相关工具,通过执行代码、操作文件和管理通信来直接影响外部环境的状态,可以超越了语言模型能力的典型限制。
个人生活 (PL) 包括与个人生活需求相关的场景,促使 LLMs 利用给定的工具收集娱乐、饮食、工作和其他相关主题的信息。随后,LLMs 将获取的信息进行综合,为用户提供有效的建议。
信息检索 (IR) 是检索任务的一个子集,要求 LLMs 从大量现有数据库中检索相关信息。这区别于优先考虑即时信息的实时搜索。由于每个数据库支持的检索方法各不相同,LLMs需要根据具体要求访问不同的数据库。
金融交易(FT)包括需要专业金融和经济知识的场景,需要LLMs使用工具获取相关金融信息并进行分析,以解决用户的问题或提供相关建议,其中可能涉及对股票走势或汇率波动的讨论。 基于这些场景,我们收集了将近600个工具,作为LLMs与物理世界的交互接口。
不同场景表现速览
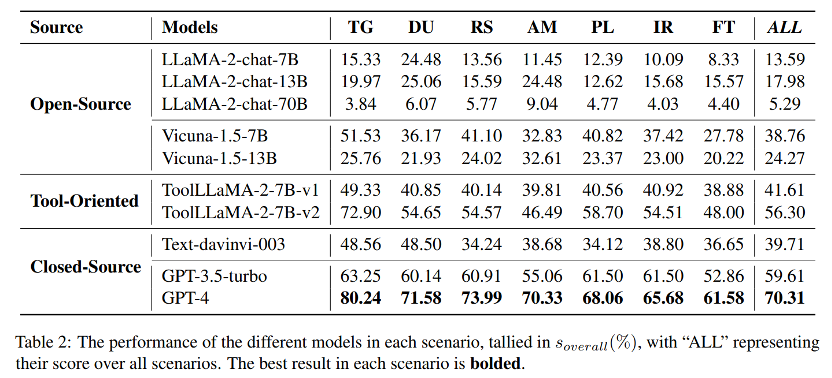
1. LLMs在工具学习中具备场景偏好。
许多 LLMs 在文本生成和数据理解等场景中表现出了非凡的能力,而在信息检索或金融交易等场景中则表现出了局限性。造成这种差异的原因是,在前一种情况下,工具的返回值可以直接用作最终输出。
相反,在后一种情况下,工具的返回值包含了更多的无关信息,这就要求提高有效归纳相关信息的能力。
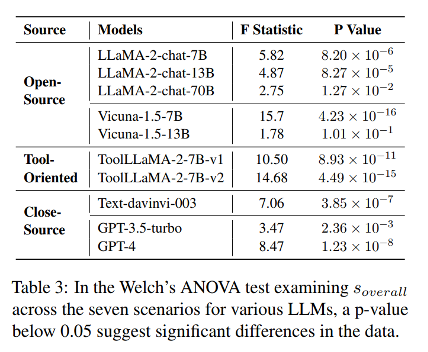
2. 其他LLMs与GPT-4在工具学习性能上的差距非常明显。
在对各种源 LLM 的工具学习能力进行评估后,GPT-4在所有场景下都具有优势。值得注意的是,现有的开源 LLMs 在工具学习方面表现不佳。
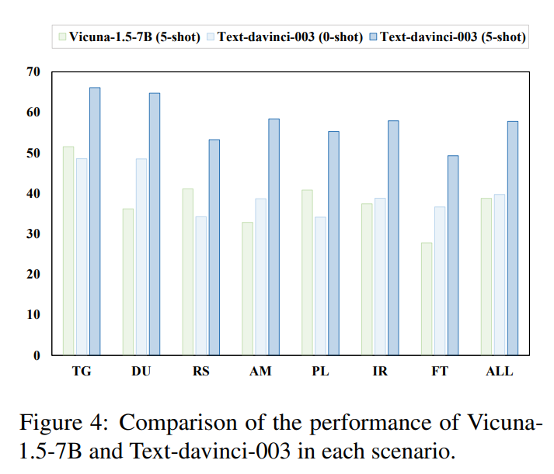
3.表现优异的LLMs具备更有效的问题解决能力。
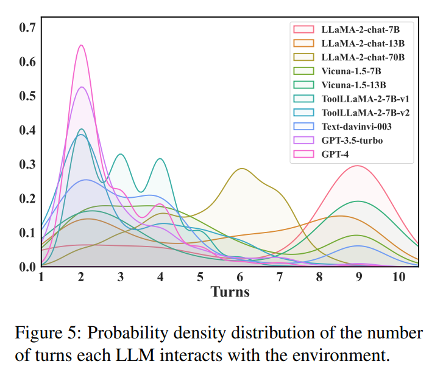
我们分析了各种场景下的数据,研究了不同 LLMs 与环境交互次数的分布情况。与通常需要多次交互才能完成任务的开源 LLMs相比,擅长工具学习任务的工具导向型和闭源 LLMs 可以在有限的交互次数内高效解决问题并满足用户需求。LLaMA-2-chat-7B 平均需要 7.0 个交互回合,大大高于 ToolLLaMA-2-7b-v2 的 3.1 个回合和 GPT-4 的 2.8 个回合。
不同维度表现速览
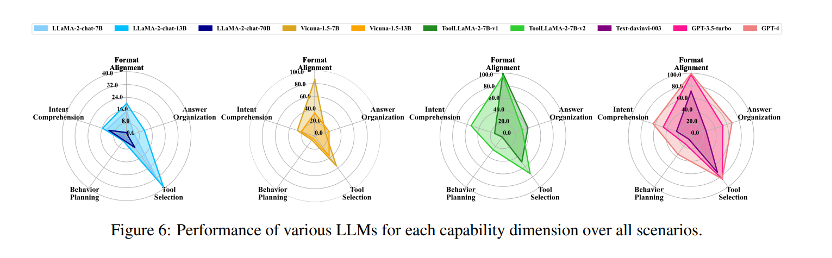
1. LLMs 目前在思维能力方面的局限对工具学习构成了巨大障碍。
无论其来源如何,LLMs行为规划能力的缺陷在有效工具学习所必需的各种能力中都是显而易见的。即使是最熟练的 GPT-4 模型,其行为规划能力也仅为 35.70%。
2. LLMs的工具学习能力受其优化目标和训练数据的影响。
与 LLaMA-2-chat-7B 相比,Vicuna-1.5-7B 的格式对齐能力提高了 73.1%,但其整体性能仍比 ToolLLaMA-2-7B-v2 差 17.5%。同时,与 ToolLLaMA-2-7B-v1 相比,ToolLLaMA-2-7B-v2 的训练集针对 LLMs 的认知过程进行了优化。这种优化大大提高了工具学习性能,尤其是在意图理解和行为规划方面。
3. 工具学习需要各种LLMs能力的相互作用过程。
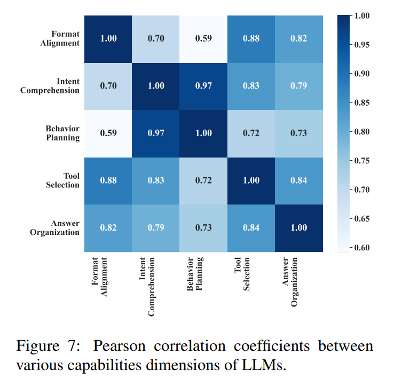
我们仔细研究了五个能力维度的表现,并计算了皮尔逊相关系数,分析发现,大多数LLMs能力之间存在正相关。这说明工具学习是一个多方面的过程,需要多种能力的协同作用。因此,对工具学习的评估不应局限于对工具选择结果的评估。
为何模型能力不随参数规模上升而提高?
随着模型规模的扩大,LLaMA-2-chat 和 Vicuna-1.5 系列模型的工具学习能力似乎有可能减弱。为了阐明这一现象,我们对模型的性能进行了深入分析。我们的研究发现,这些局限性源于 LLMs 固有的行为特征。
1. 与对话对齐会促使 LLMs 生成冗余句子。
随着参数数量的增加,以冗余句子为特征的回合数量也明显增加。这种现象可以归因于 LLMs 在工具选择的末尾添加了额外的句子,以便与日常对话更加接近。这种行为在根据会话数据训练的模型中尤为明显,参数越大,影响越大。因此,在 91% 的测试数据中,LLaMA-2-chat-70B 与环境的交互完全失败,导致其整体性能明显较差。
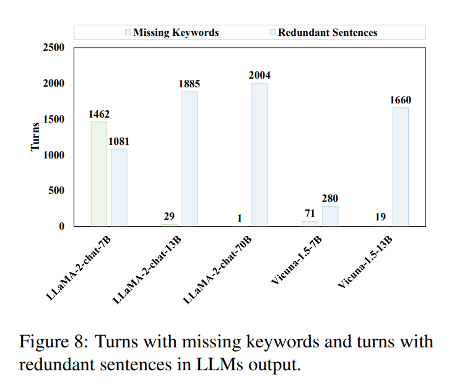
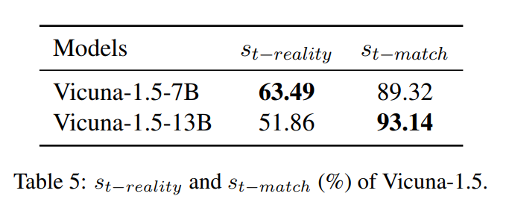
2. Vicuna-1.5 中自动生成的转义字符导致了工具选择幻觉。
导致 Vicuna-1.5-13B 中工具选择能力下降的主要因素是一个更为明显的工具选择幻觉问题。这个问题是由于 Vicuna-1.5 自动加入了多余的转义字符,导致工具和参数名称与工具库中的信息不一致。