




背景
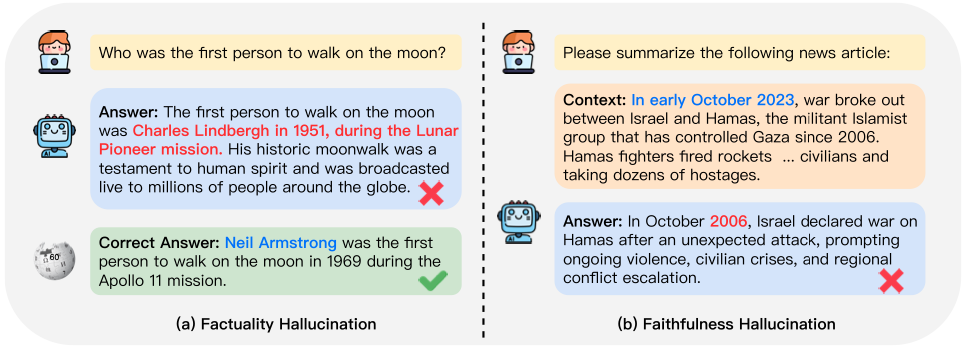
大语言模型(LLM)的出现极大地推动了自然语言处理领域的发展。基于预训练、(指令)微调、对齐等流程的大模型具有较强的文本理解与生成能力,但仍然面临着幻觉(见下图)与过时知识等挑战。基于检索增强的生成(RAG)范式支持知识集成与知识的持续更新,能增强大模型在下游任务中的准确性。
流水线形式的 RAG 包括以下部分:
查询改写(Rewriter) 检索(Retrieve) 重排序(Reranker) 内容压缩(Compress) 阅读器(Reader)
本文将针对以上内容介绍一些新工作
相关工作
Rewriter
论文名:Enhancing Conversational Search: Large Language Model-Aided Informative Query Rewriting (EMNLP'23 Findings)
改写模块通过修改或重写原始查询,可以从准确性与信息量等维度对其进行改善,以避免查询较短、有歧义等问题。该论文利用提示学习方法,使用大模型作为查询重写器。首先,作者定义了良好查询的四个特点,分别为正确、清晰、有信息量、无赘余,并基于这四个特点设计了一段提示指令。
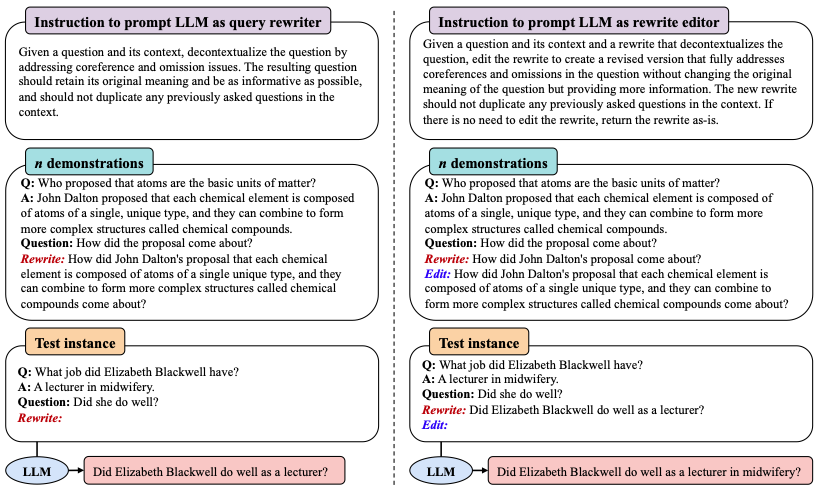
基于这段指令,可以通过大模型对原始查询进行改写。当存在少量的(人工)改写示例时,可将其拼接到当前查询之前,利用大模型的上下文学习能力进一步提升改写质量(下图左)。
特别地,大模型只进行一次改写可能很难生成满足所有特点的查询。因此,作者提出了一种 “改写+编辑” 的替代方法(下图右),可以对提供的初始改写进行再编辑。初始改写可由 T5QR 等小模型提供,也可直接通过大模型生成。
此外,可以利用大模型生成的改写查询作为标签,通过知识蒸馏技术将大模型的改写能力提炼到小模型上以减少开销。
Retriever
论文名:KnowledGPT: Enhancing Large Language Models with Retrieval and Storage Access on Knowledge Bases (2023.8)
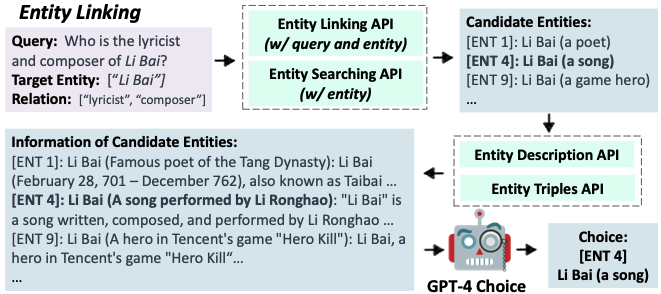
本文作者尝试将大模型与多种类型的知识库进行结合,并将检索过程统一化。对自然语言查询,KnowledGPT 通过 GPT-4 生成 Python 风格的搜索代码(PoT)作为查知识库的逻辑形式(见下图),其中包括内置的 Python 函数和三个自定义的知识库函数,分别为:get_entity_info(根据实体查描述)、find_entity_or_value(根据实体关系对查实体或属性值)、find_relationship(根据两个实体查关系)。搜索代码中的实体与关系均为候选的别名列表,以有效处理同义词。

对每个 KB,则分别实现 _get_entity_info、_entity_linking 、_get_entity_info 三个函数。其中,_entity_linking 利用 KB 提供的 API 获取候选实体,并使用 _get_entity_info 获得相关信息,基于上述信息通过大模型选出最匹配的实体。当大模型生成知识库函数后,将其转化为调用 KB 函数来获取知识。
Reranker
论文名:Improving Passage Retrieval with Zero-Shot Question Generation (EMNLP'22)
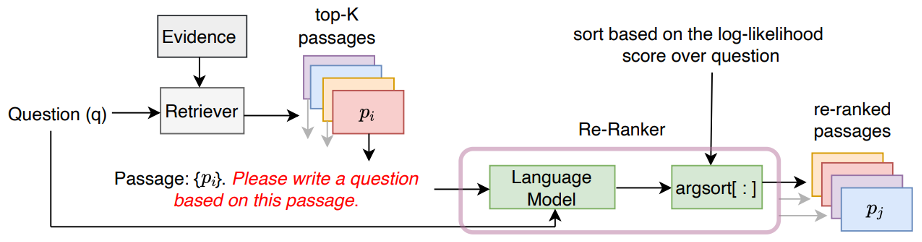
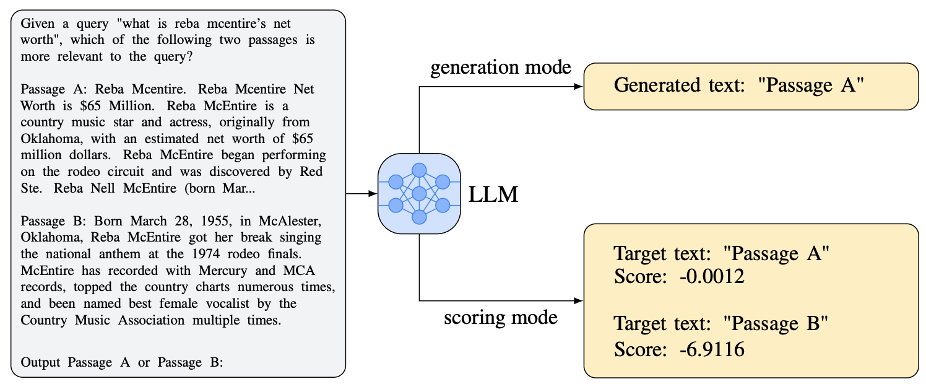
基于提示学习的重排序模块可以根据样本的输入方式分为 Pointwise、Listwise、Pairwise 三类(见下图)。Pointwise 类方法输入查询与单个文档,一种较为直接的思路是让大模型根据输入生成二者是否相关的 token,并将生成的概率作为相关性得分。
该论文采取了不同的思路,作者设计了指令 “根据该文档写一个查询” 用于提示大模型,将生成给定查询的概率作为相关性得分。
论文名:Zero-Shot Listwise Document Reranking with a Large Language Model (2023.5)
Listwise 类方法同时输入多个文档,根据相关性对文档进行排序。该论文将其建模为一个 Seq2Seq 过程,提示大模型基于输入的文档集输出排序后文档 ID 的列表。此类方法可以同时利用来自多个文档或段落的信息,具有更高的效率。
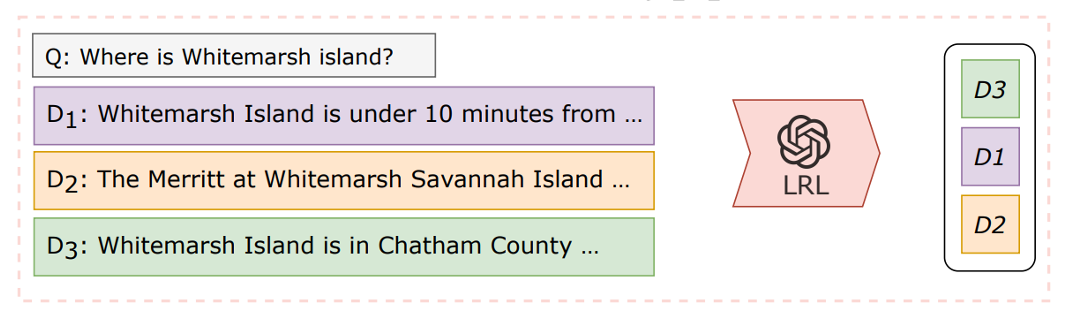
论文名:Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting (2023.6)
相关工作表明,当改变文档的位置时,大语言模型表现不够稳健。并且,利用较小的语言模型时,Listwise 类方法效果可能低于监督学习方法甚至 BM25 等统计模型。为此,该论文采取了 Pairwise 类方法,输入为查询与一个文档对,根据 Pairwise 的提示比较其中一个文档是否比另一个更加相关(见下图)。此外,若对所有的文档对均进行一次比较会带来较大的计算开销。因此可以将 Pairwise 类方法与快速排序、堆排序、滑动窗口等技术结合以减少成本。
Compress
论文名:RECOMP: Improving Retrieval-Augmented LMs with Compression and Selective Augmentation (2023.10)
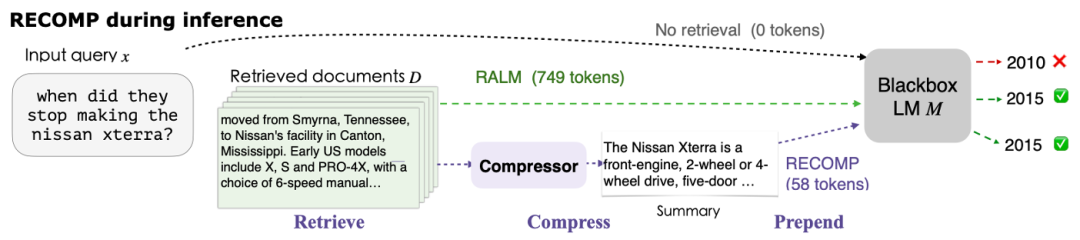
经过了检索与重排序阶段后,可以从知识库中获得与查询相关的若干文档,然而文档级别的知识具有较多的 token 量,增大了推理的开销。因此可以在将相关文档集成到上下文之前进行压缩。
该论文设计了两种压缩模块。第一种为提取式压缩器,基于训练后的 dual encoder 对文档集合中包含的句子与输入序列进行编码,通过向量内积评估句子对后续生成是否具有帮助。
第二种为摘要式压缩器,基于训练后的 encoder-decoder 对多个文档生成输入序列相关的摘要。如果检索到的文档与输入无关,则可以返回一个空字符串。
Reader
论文名:Measuring and Narrowing the Compositionality Gap in Language Models (2022)
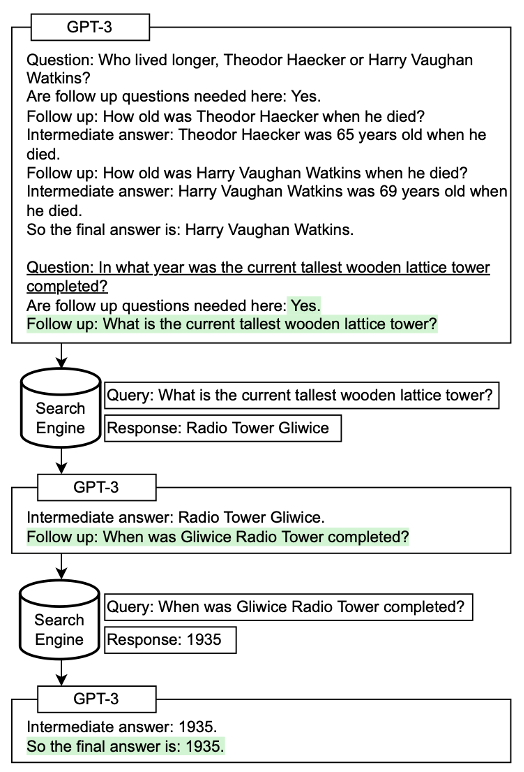
论文中,对于复杂问题,当模型不具备相关知识而无法直接回答时,将生成用于解决初始问题的子问题,并在搜索引擎上进行查询。通过思维链形式的推理以及模型与检索模块的主动交互,可以进一步提升模型在回答复杂问题时的准确性。
总结
本次论文分享围绕检索增强流程中的查询改写、检索、重排序、内容压缩、阅读器共五个方面进行了调研。对于未来的研究方向,笔者认为,可以从个性化查询改写、异质乃至多模态形式知识源检索与整合方面进行入手,提升大模型在复杂任务中的表现。
参考文献
Huang L, Yu W, Ma W, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions[J]. arXiv preprint arXiv:2311.05232, 2023. Gao Y, Xiong Y, Gao X, et al. Retrieval-Augmented Generation for Large Language Models: A Survey[J]. arXiv preprint arXiv:2312.10997, 2023. Zhu Y, Yuan H, Wang S, et al. Large language models for information retrieval: A survey[J]. arXiv preprint arXiv:2308.07107, 2023. Fanghua Ye, Meng Fang, Shenghui Li, and Emine Yilmaz. Enhancing Conversational Search: Large Language Model-Aided Informative Query Rewriting. In Findings of Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023. Wang X, Yang Q, Qiu Y, et al. Knowledgpt: Enhancing large language models with retrieval and storage access on knowledge bases[J]. arXiv preprint arXiv:2308.11761, 2023. Sachan, D.S., Lewis, M., Joshi, M., Aghajanyan, A., Yih, W., Pineau, J., & Zettlemoyer, L. . Improving Passage Retrieval with Zero-Shot Question Generation. In Conference on Empirical Methods in Natural Language Processing (EMNLP), 2022. Ma X, Zhang Y, Pradeep R, et al. Zero-Shot Listwise Document Reranking with a Large Language Model. arXiv preprint arXiv:2305.02156, 2023. Qin Z, Jagerman R, Hui K, et al. Large language models are effective text rankers with pairwise ranking prompting[J]. arXiv preprint arXiv:2306.17563, 2023. Xu F, Shi W, Choi E. Recomp: Improving retrieval-augmented lms with compression and selective augmentation[J]. arXiv preprint arXiv:2310.04408, 2023. Press O, Zhang M, Min S, et al. Measuring and narrowing the compositionality gap in language models[J]. arXiv preprint arXiv:2210.03350, 2022.


欢迎关注北京大学王选计算机研究所数据管理实验室微信公众号“图谱学苑“
实验室官网:https://mod.wict.pku.edu.cn/
微信社区群:请回复“社区”获取
gStore官网:https://www.gstore.cn/
GitHub:https://github.com/pkumod/gStore
Gitee:https://gitee.com/PKUMOD/gStore

