论文信息
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
ICLR 2024 论文主页: https://openreview.net/forum?id=XUZ2S0JVJP
论文的主题是关于如何在使用大型语言模型时降低成本并提高性能,作者来自斯坦福大学。论文在2023年上半年公开,并已提交到ICLR 2024 Conference。尽管审稿人对该论文的评价不高,但在实际应用中具有很大的参考价值。
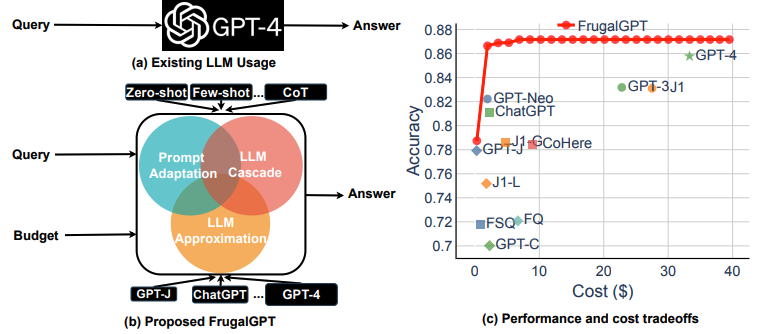
论文对比了大型语言模型(LLMs)的使用成本,如GPT-4、ChatGPT和J1-Jumbo。通过对比发现这些模型的费用相差两个数量级,论文提出了三种策略来降低使用LLMs的推理成本。
论文出发点
据估计ChatGPT每天的运营成本超过70万美元,而使用GPT-4支持客户服务可能会让小型企业每月花费超过2.1万美元。
目前有许多LLMs通过API提供,并且它们的收费价格差异巨大。一般而言,使用LLM API的成本通常包括三个部分:
提示成本(与提示长度成正比) 生成成本(与生成长度成正比) 每个查询的固定成本
鉴于LLMs的成本和质量,如何有效而高效地利用完整的LLM选项是从业者面临的一项关键挑战。对于相对简单的任务,通过组合尺寸更小的大模型可能性价比更高。
策略1:改进提示文本
LLM查询的成本与提示的大小成正比。因此降低使用LLM API成本的一个合理途径是减小提示的大小,这个过程被称为提示适应(Prompt adaptation)。
提示选择
提示选择是提示适应的一个自然示例:与使用包含多个演示如何执行任务的示例的提示不同,可以保留提示中的一小部分示例。这导致了一个更小的提示,随之而来的是更低的成本。提示选择的一个有趣挑战在于确定在不损害任务性能的情况下为各种查询保留哪些示例。

查询串联
单独处理查询需要将相同的提示多次发送到LLM API。查询串联的基本概念是只发送一次提示到LLM API,同时允许其处理多个查询,从而防止冗余的提示处理。为了实现这一点,多个查询必须被串联成一个单一的查询,并且提示必须明确要求LLM API处理多个查询。

策略2:避免使用(大)模型
请求缓存
如果使用LLM API成本过高,可以使用更经济的模型或基础设施来逼近它。一个例子是完成缓存,在向LLM API提交查询时,将响应存储在本地缓存中。为了处理新的查询,我们首先验证是否之前已回答过类似的查询。

模型微调
模型过程包括三个步骤:首先收集一个强大但昂贵的LLM API对少量查询的响应;其次使用这些响应来微调一个更小更经济的AI模型;最后使用微调后的模型处理新的查询。

除了成本节省外,微调后的模型通常不需要冗长的提示文本,此外输出的结果也会更加可控。
策略3:组合多个大模型
不同的LLM API对于不同查询具有各自的优势和劣势。因此适当地选择要使用哪些LLMs既可以降低成本,又可以提高性能。

LLM级联将查询顺序发送到一系列LLM API。如果一个LLM API的响应是可靠的,那么就返回其响应,不需要进一步查询列表中的其他LLMs。仅当前面的API生成被认为不够可靠时,才会查询其余的LLM API。如果前几个API相对便宜且生成可靠,查询成本将大幅降低。基于上述方法,可以对查询寻找到满足性能的最小提示和最经济的LLM。
论文实验
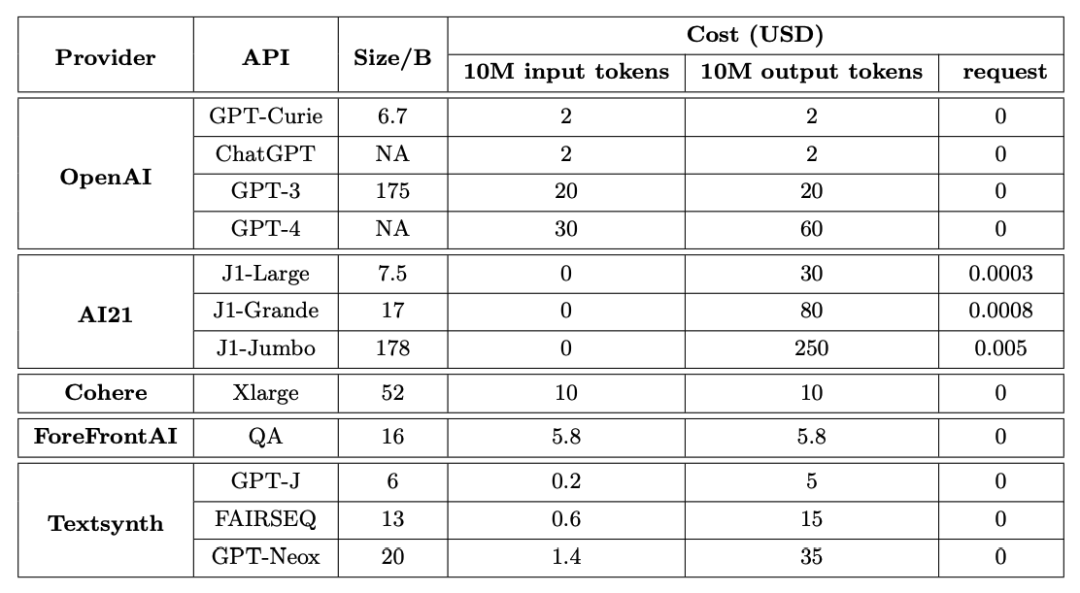
从5个主要提供商中选择了12个LLM APIs,详情总结如下表所示。FrugalGPT是在这些API的基础上开发的,并在属于不同任务的一系列数据集上进行了评估。
HEADLINES是一个金融新闻数据集,其目标是通过阅读金融新闻标题来确定黄金价格趋势(上涨、下跌、中性或无变化)。 OVERRULING是一个法律文件数据集,其目标是确定给定句子是否是推翻前期法律案例的情况。 COQA是一个在对话设置中开发的阅读理解数据集,我们将其调整为一个直接的查询回答任务。
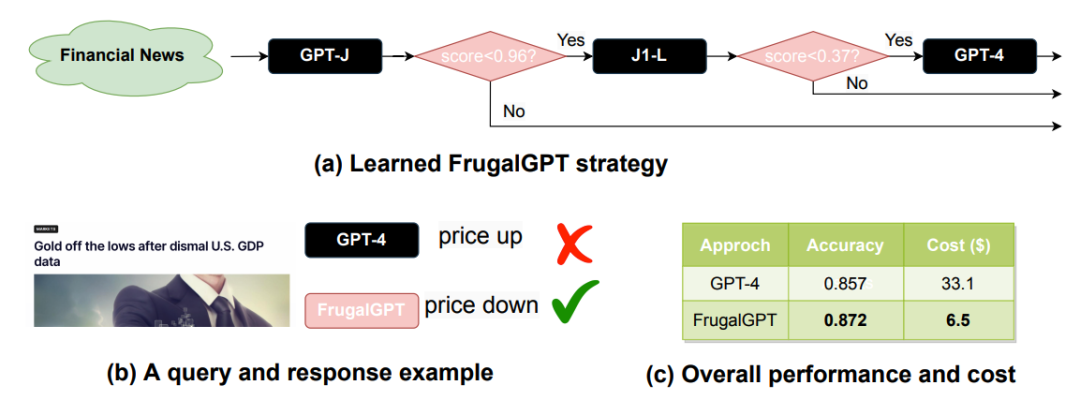

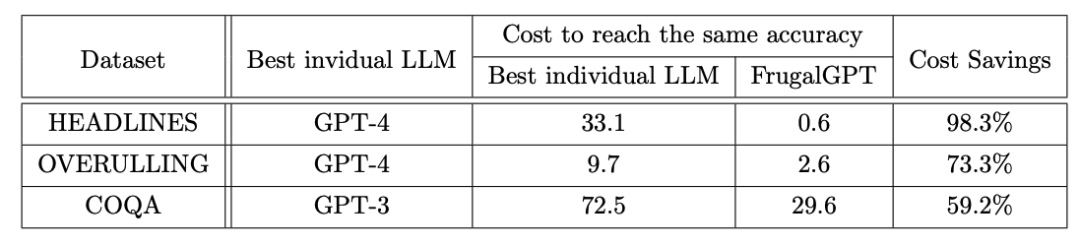
为什么多个LLM API可能比最佳单个LLM产生更好的性能?实质上,这是由于生成多样性:即使是一个廉价的LLM有时也能正确回答昂贵LLM无法回答的查询。
论文结论
在实际应用中,使用大型语言模型(LLMs)的昂贵成本是一个显著的障碍,限制了它们的广泛应用。 现实存在多种如prompt adaptation(提示适应)、LLM approximation(LLM近似)和LLM cascade(LLM级联),可以降低成本的策略。 在使用的过程中,需要考虑到不同的会有不同的输出。因此需要还考虑到不同模型的不平衡和不确定的因素。