




图数据库计算和查询结果正确性的重要性不言而喻。本文旨在向读者介绍图数据库查询中的基础知识以及如何进行正确性验证。
1. 面向元数据的操作,即面向顶点、边或它们之上的属性字段的操作;操作可以具体分为增、删、改、查四类。
2. 面向高维数据的操作,这也是本文关注的重点,例如面向全图或子图数据的查询结果返回多个顶点、边组合而成的高维数据结构,可能是多顶点的集合、点边构成的路径、子图(子网)甚至是全图遍历结果。
面向高维数据的查询有三大类:
1. K邻查询:即返回某顶点的全部K度(跳)邻居顶点集合。K邻查询可以有很多变种,包括按照某个特定方向、点边属性字段等进行过滤。还有全图K邻查询,也被视作一种高计算复杂度的图算法。
2. 路径查询:常见的有最短路径、模板路径、环路路径、组网查询、自动展开查询等。
3. 图算法:图算法在本质上是面向元数据、K邻、路径等查询方式的组合。
无论以何种方式进行高维查询,图数据库中的操作无外乎遵循如下3种遍历模式:
1. 广度优先:例如K邻查询、最短路径就是典型的广度优先遍历模式。
2. 深度优先:例如环路查询、组网查询、模板路径查询、图嵌入随机游走等。
3. 以上两者兼而有之:以最短路径方式遍历的模板路径或组网查询、带方向或条件过滤的模板K邻查询、定制化的图算法等。
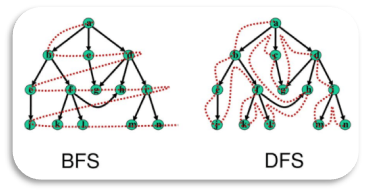
图:广度优先遍历 vs. 深度优先遍历
我们以各图数据库厂商的基准性能评测中常用的Twitter-2010数据集为例来说明如何进行图上查询的正确性验证。Twitter数据集(其中顶点数量4200万,边数量14.7亿,原始数据24.6GB)的下载链接为: http://an.kaist.ac.kr/traces/WWW2010.html。
· 有向图:由顶点(人)和边(关注关系)组成,其中关注关系为有向边。Twitter源数据中有两列,对应在每一行是由TAB键分割的两个数字,例如,12与13,代表两个用户的ID,表示两者间的有向的关注关系:12关注13。在图数据建模中就应该构建为两条边,一条表示从12到13的正向边,另一条则是从13到12的反向边,缺一不可。后面的验证细节中很多正确性的问题都与此相关——没有构建反向边,查询结果就会不可避免的错误。
· 简单图vs.多边图:如果一对顶点间存在超过(含)2条边,则其为多边图,否则即为简单图。在简单图中任意顶点间最多只有1条边,因此简单图也称作“单边图”。Twitter数据实际上是一种特殊的多边图,当两个用户互相关注对方时,他们之间可以形成两条边。在金融场景中,如果用户账户为顶点,转账交易为边,两个账户之间可以存在多笔转账关系,即多条边。很多系统只能支持简单的单边图,就会带来很多图上查询与计算的结果错误的问题。
· 点、边属性:Twitter数据本身除了隐含的边的方向可以作为一种特殊的边属性外,并不存在其他点边属性。这个特征区别于金融行业中的交易流水图——无论是顶点还是边都可能存在多个属性,可以被用来对实体或关系进行精准的查询过滤、筛选、排序、聚合运算、下钻、归因分析等。不支持点边属性过滤的图数据库可以认为功能没有实现闭环,也不具备商业化价值
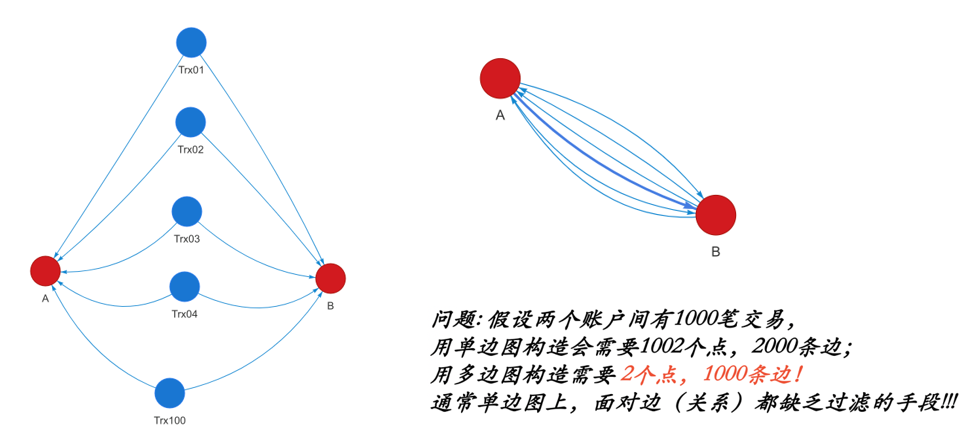
图:单边图 vs. 多边图
1. 第K度(跳)邻居
2. 从第1跳到第K条的全部邻居
其中第K跳邻居指的是全部距离原点最短路径距离为K的邻居数量。以上两种涵义的区别仅仅在于到底K-Hop的邻居是只包含当前步幅(跳、层)的邻居,还是要包含前面所有层的邻居。
无论是哪种定义,有两个要点直接影响“正确性”:
A. K邻查询的正确实现方式默认应基于广度优先搜索!
B. 结果集去重:即第K层的邻居集合中不会有重复的顶点,也不会有在其它层出现的邻居!(已知的多个图数据库系统都存在数据结果没有去重的错误。)
有的厂家会用深度优先搜索(DFS)的方式,通过穷举全部可能的深度为K跳的路径来试图找到全部途径和最终能抵达的终点。但是,DFS方式实现K邻查询有2个致命的缺点:
A.效率低下:在体量稍大的图中,不可能遍历完毕,例如Twitter数据集中常见的有超过百万邻居的顶点,如果以深度遍历的复杂度是天文数字级的(百万的11次方以上);
B.结果大概率错误:即便是可以通过DFS完成遍历,也没有对结果进行分层,即无法判断某个邻居到底是位于第1跳还是第N跳。
我们先从验证1度(1跳)邻居开始,以Twitter数据集的顶点“27960125”为例,在源数据集中,如下图所示,返回了8行(对应图数据库中的8条边!),但是它的1度邻居到底是几个呢?
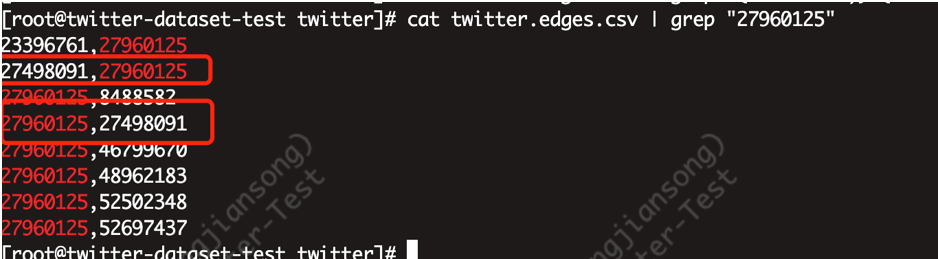
图:Twitter源数据中顶点关联的边
为了更精准地验证结果正确性,对K邻查询还可以按照边的方向来进行过滤,例如只查询顶点“2796015”的出边、入边或者双向边(注:默认是查询双向边关联的全部邻居)。下图展示了如何通过图查询语言来完成相应的工作。注意,该顶点有6条出边对应的1跳邻居、2条入边对应的1跳邻居,其中有1个邻居“27498091”是重叠的。
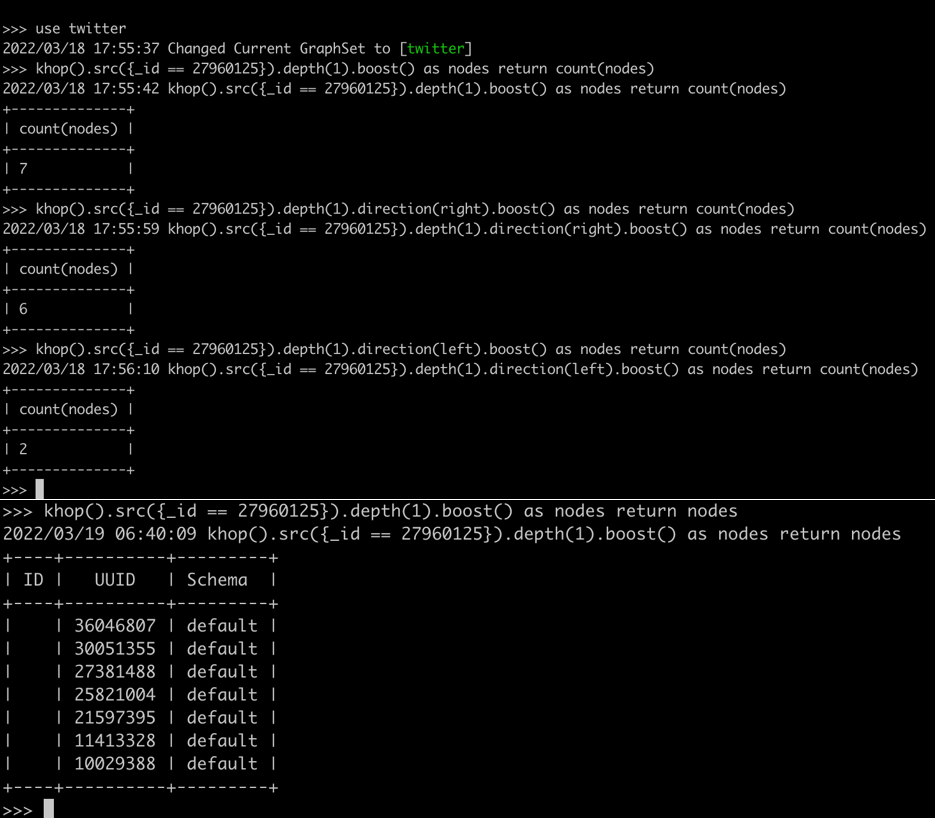
图:从嬴图CLI命令行工具操作K邻
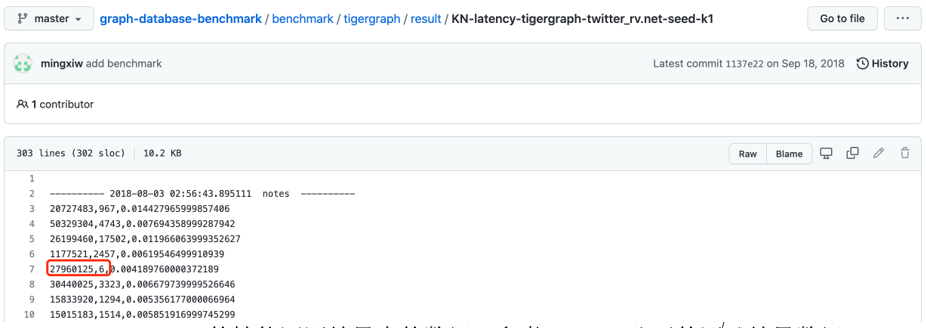
图:Tigergraph的性能评测结果中的数据(参考Github公开的测试结果数据)
Tigergraph的查询结果错误有3个可能,都具有典型性:
· 构图错误:只存储了单向边,没有存储反向边,无法进行反向边遍历;
· 查询方式错误:只进行了单向查询,没有进行双向边遍历查询;
· 图查询代码实现错误:即没有对结果进行有效的去重——这个我们在多跳K-hop查询中再继续分析。
其中,构图错误代表着数据建模错误,这意味着业务逻辑不能在数据建模层面被准确反应。例如在反欺诈、反洗钱场景中,账户A收到了一笔来自账户B的转账,但是却因为没有存储一条从A至B的反向边而无法追踪该笔交易,这显然是不能容忍的。查询方式和查询代码逻辑错误同样也会对结果造成严重影响——每一跳查询双向边,在多跳情况下查询复杂度指数级高于单向边查询,这也意味着Tigergraph如果正确地实现图数据建模、存储与查询,其性能会指数级降低,并且存储空间的占用也会成倍增加(存储正向+反向边的数据结构要比仅存储单向边复杂2x以上),数据加载时间也会成倍增长。
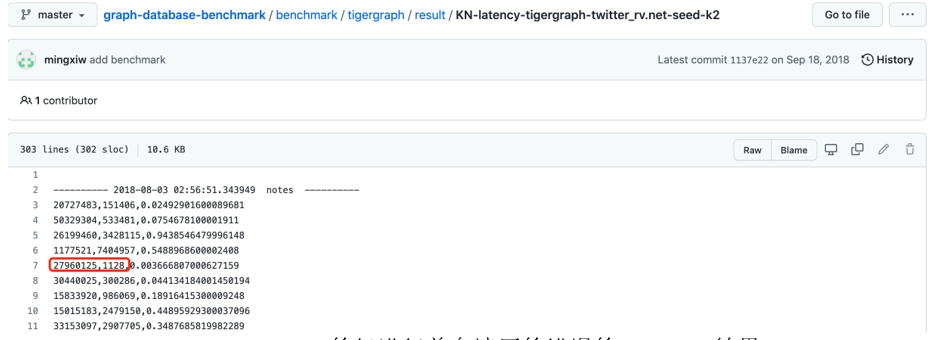
图:Tigergraph的仅进行单向遍历的错误的2nd-Hop结果
遗憾的是Tigergraph的查询结果错误问题在今天的图数据库市场并不是个例,我们在Neo4j、ArangoDB等系统中也发现因底层实现或接口调用等问题而出现的错误——更为遗憾的是,有多个厂家的“自研图数据库”实际上是对Neo4j社区版或ArangoDB的封装,姑且不论这么操作是否涉嫌违规商用,暴力封装几乎注定了它们的查询结果也是错误的。例如Neo4j默认并不对K邻查询结果进行去重,而一旦开启去重,它的运行效率会指数级下降,因此为了保证效率,K邻结果默认都是不去重的;而ArangoDB有一种最短路径查询模式,只返回一条路径,这种模式本身就是对最短路径的错误理解与实现。
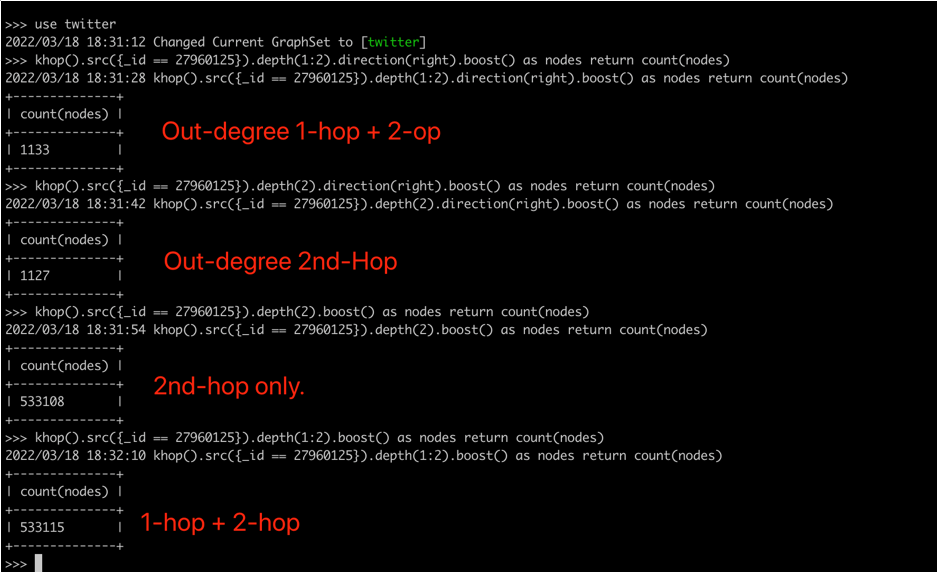
图:嬴图的正确的K-Hop查询结果(4种查询方式)
例如,某数据集中ID为“12242”的顶点的1度邻居查询,有12个邻居,在嬴图高可视化平台中操作结果如下:
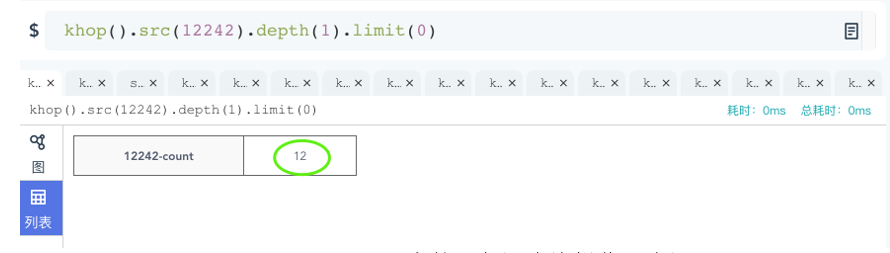
图:嬴图高可视化平台中的K邻图查询操作示意图
如何可视化的验证结果正确性呢?可以通过对该顶点进行广度优先的展开操作,即展开其全部的边所关联的第一层(跳)的邻居。如下图所示,可以看到尽管12242有18条边,但是关联的具有唯一ID的、去重后的邻居只有12个。
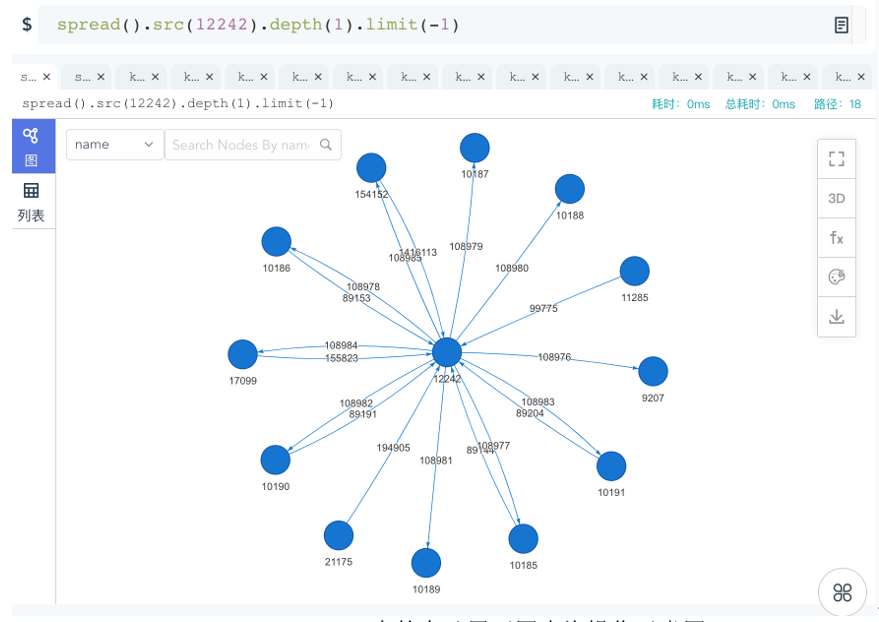
图:嬴图高可视化平台中的自动展开图查询操作示意图
· 最短路径
· 图算法
最短路径可以看做是K邻查询的一个自然的延展,区别在于它需要返回的结果有两个特征:
·高维结果:最短路径需要返回的多条由顶点、边按遍历顺序组合而成的路径;
·全部路径:任意两个顶点间可能存在多条最短路径,如果是转账网络、反洗钱网络、归因分析等查询,只计算一条路径显然是无法反应全貌的!
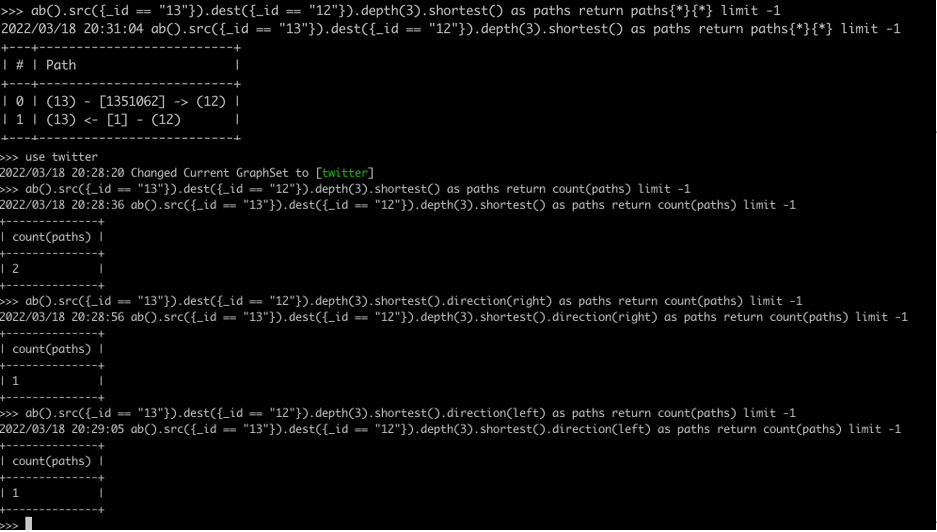
图:嬴图CLI中的最短路径查询操作结果验证
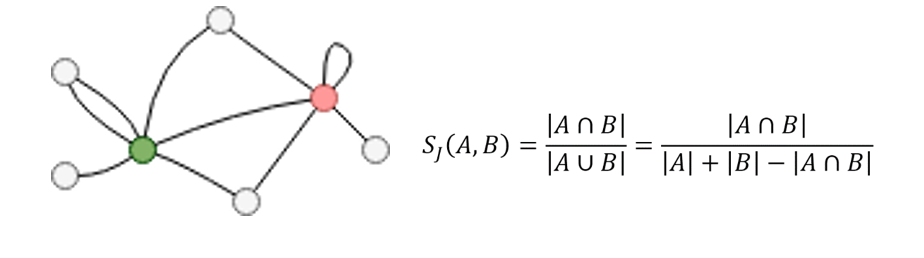


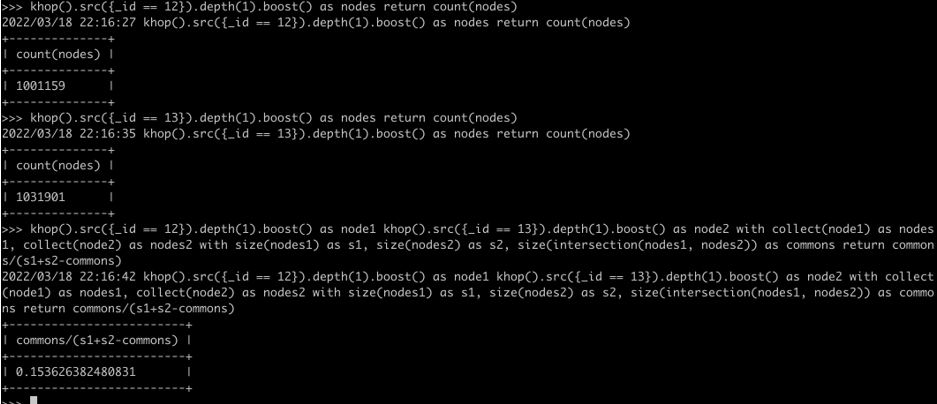
3. 验证方法二:查询顶点12的1跳邻居个数(下图):
4. 验证方法二:查询顶点13的1跳邻居个数(下图):
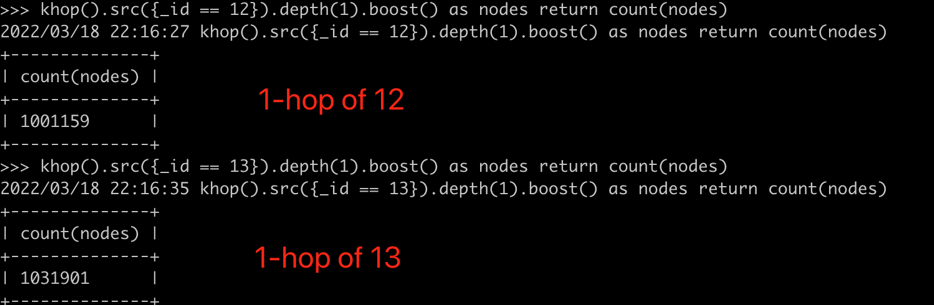

6. 验证方法二:用以上第5步的结果,除以(第3步结果 + 第4步结果 – 第5步结果)= 0.15362638;
7. 如果以上算法和两种验证方法结果均一致,则图算法计算结果正确。
作者:嬴图团队 【特别声明】原创文章,转载、引用或内容合作请联系13810538013,违规必究。
