




obca 认证题库 https://www.modb.pro/doc/129748
obca 认证题库 https://www.modb.pro/doc/129748
hadoop
存:HDFS namenodes,datanode
库:HBASE
算:mapreduce
oracle量达到P结构时需要用hadoop(或可以一体机,可以达到几十P)
HDFS:
namenode HDFS最重要的
维护目录 维护文件系统的目录树机构
接收请求,接受用户请求
管理关系,管理文件、块和datanode之间的关系
datanode 存数据,存副本
mapreduce
map分而治之,分别运算
reduce 将结果合并
hive →sql
原理:
jobtracker 分任务 mapreduce最重要的
tasktrackers 做任务
或者shutdown -h now

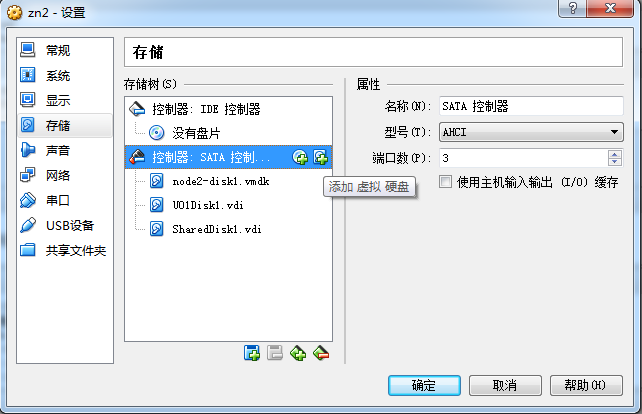
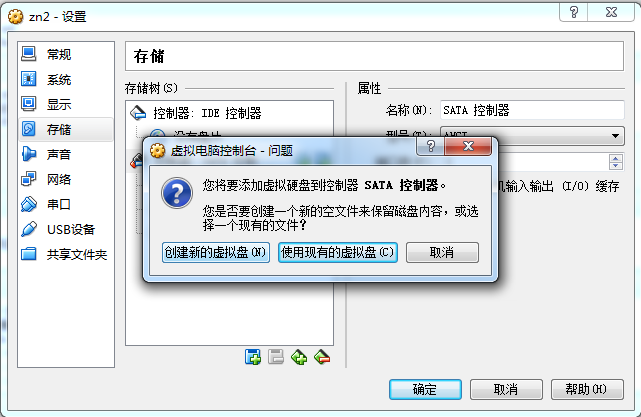
点击创建新的虚拟盘
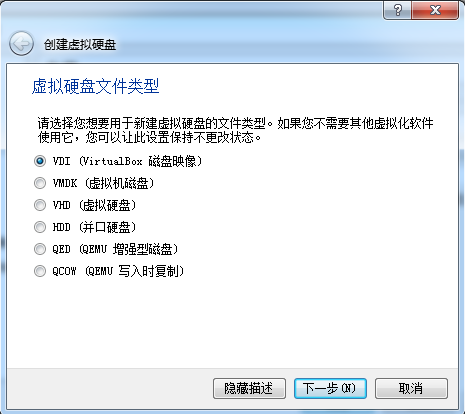
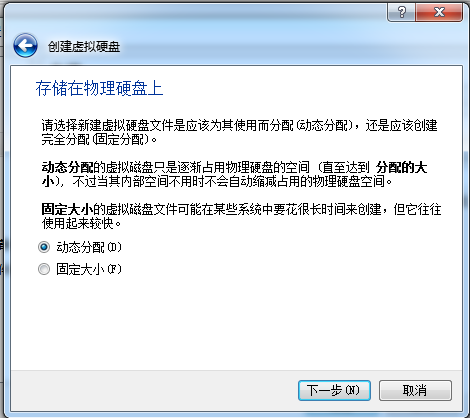
名称改成U02Disk1.vdi,大小设20G(一定要改大,8G太小了)。路径是
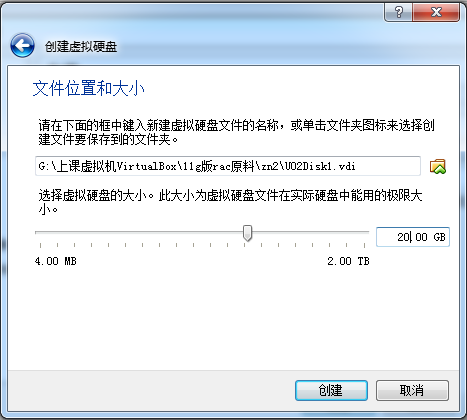
如果名字重就改名,比如叫U03
点击确定。
过程和上面的添加磁盘相同,使用动态的,然后上限设为20G。
启动gc2,然后进行如下操作:
fdisk -l
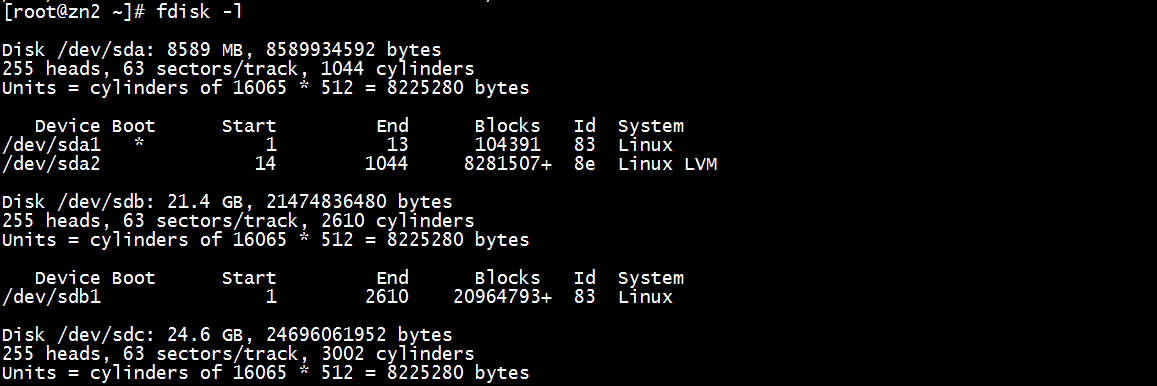
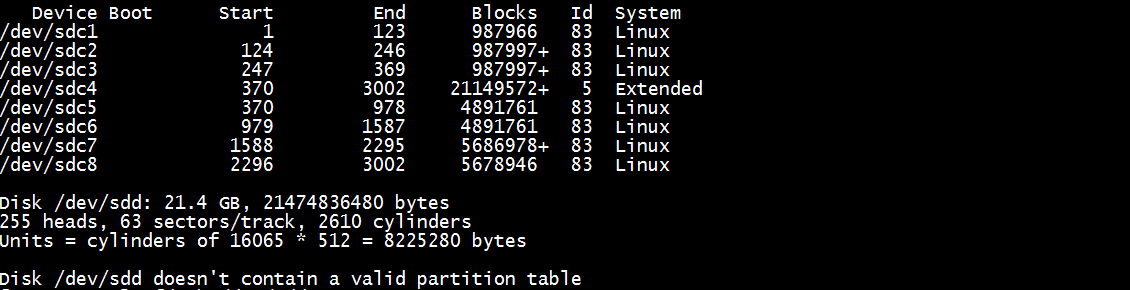
注意/dev/sdd没分过区:
fdisk /dev/sdd
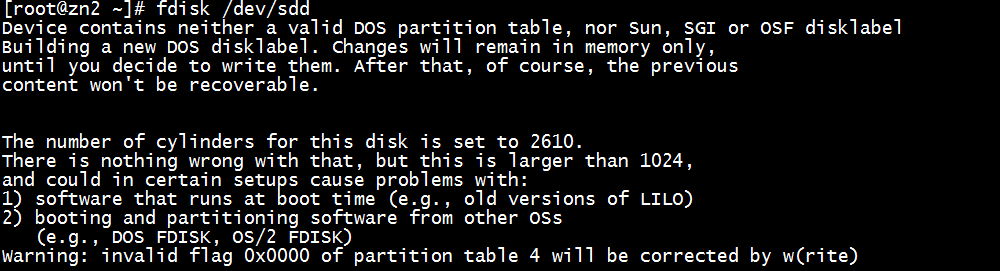
输入m
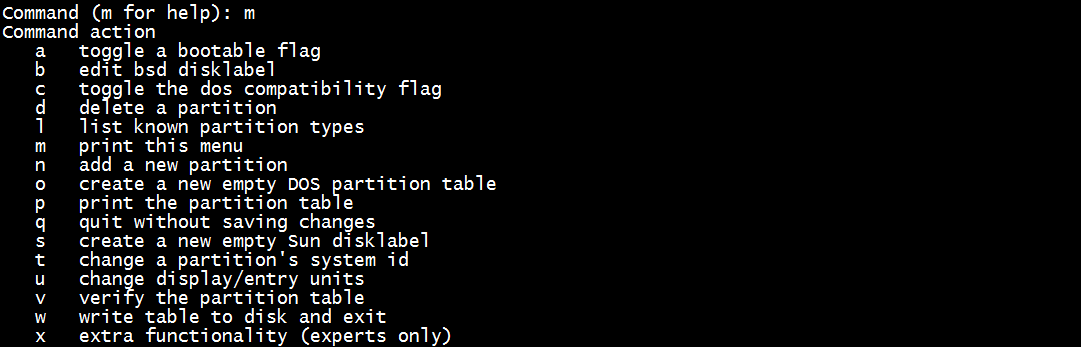
输入n
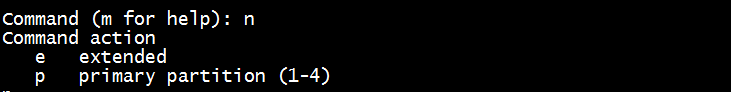
输入p,1,回车,回车

输入w保存

fdisk -l
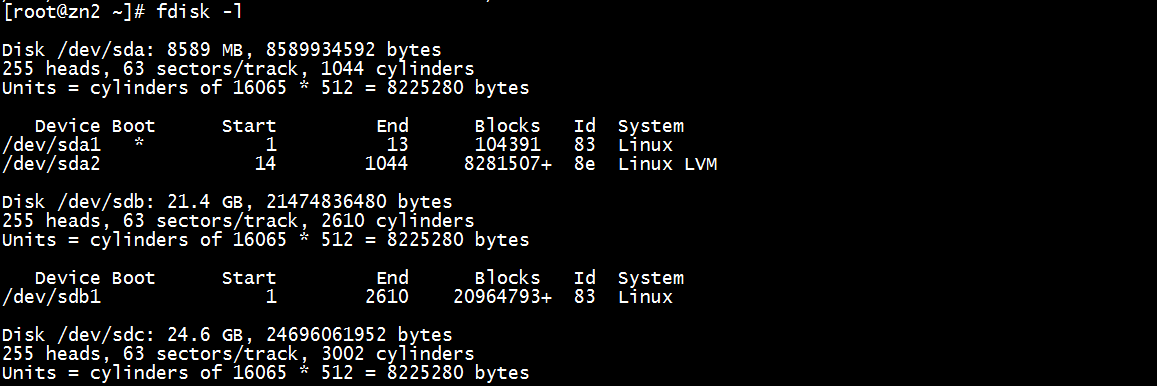
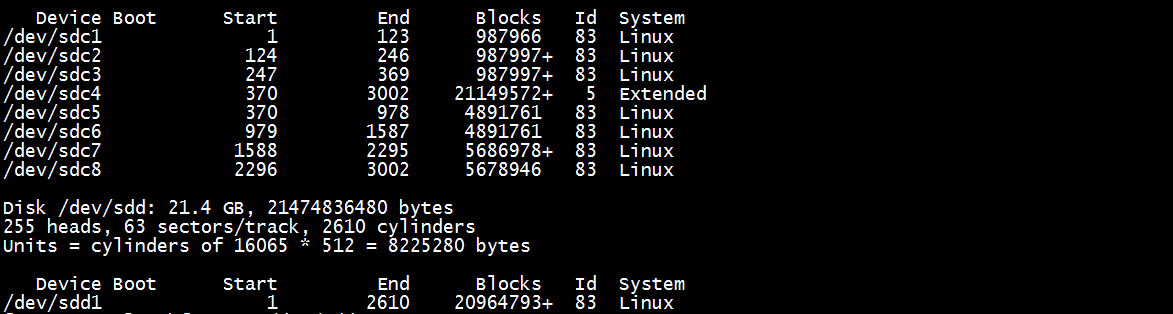
已经产生了/dev/sdd1
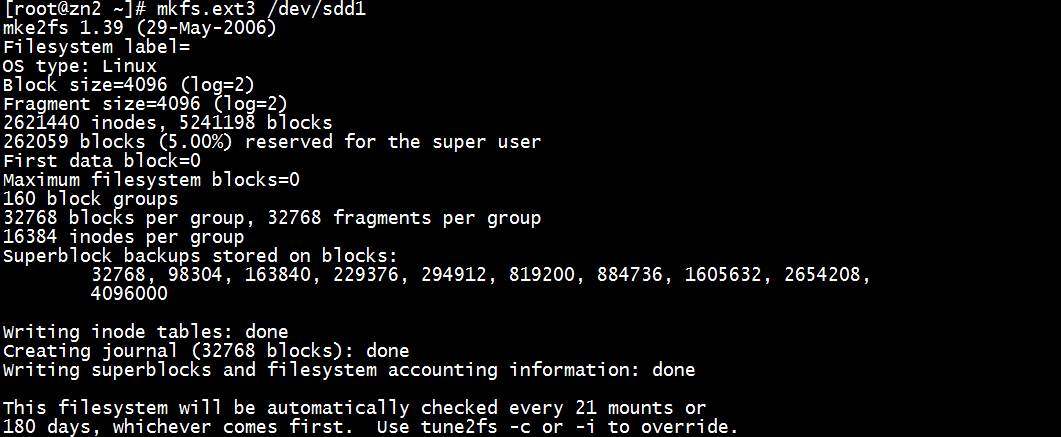
下面格式化
mkfs.ext4 /dev/sdd1
df -h

pvcreate /dev/sdd1

pvscan

扩容
vgextend /dev/mapper/VolGroup00 /dev/sdd1

lvextend -L +18G /dev/mapper/VolGroup00-LogVol00
我扩18个G

df -h

没变化:
resize2fs /dev/VolGroup00/LogVol00

df -h

扩容成功。
