




“ 随着人工智能的发展,检索增强生成(Retrieval-Augmented Generation,RAG)技术在智能应用中展现出了巨大的潜力。尽管RAG在提供精准答案方面取得了显著成效,它在应对幻觉问题、信息损失以及准确性挑战方面仍面临诸多考验。业界正积极探索包括COT提示、向量检索优化以及结构化数据查询等方法来提升RAG系统的效能,并在此基础上营造更加智能化的对话体验。本文将深入探讨RAG技术的挑战、现有解决方案以及结构化数据在提升RAG性能中的重要作用。”
01
—
RAG面临的挑战和问题
在当前人工智能应用的实际部署中,检索增强生成(Retrieval-Augmented Generation,简称RAG)技术受到极大关注,成为当前应用最为广泛的前沿解决方案之一。RAG旨在响应用户问题,通过高效地从庞大的数据库中定位信息相关性高的文献资料,并从这些文档中提炼出最精准的答案。该技术的应用涉及多个领域,包括但不限于智能客户服务支持系统、知识图谱的自动化构建,以及交互式对话系统的开发,均展现出RAG的潜能与应用价值。
尽管RAG在多个领域表现出色,但幻觉问题仍然是其难以忽视的挑战,RAG的应用流程通常包括以下几个关键步骤:
2、通过语义搜索对数据进行召回,这一阶段主要是从大规模数据集中检索出与用户问题语义上相关的文档。
3、融合这些信息输入大语言模型,并生成输出结果。
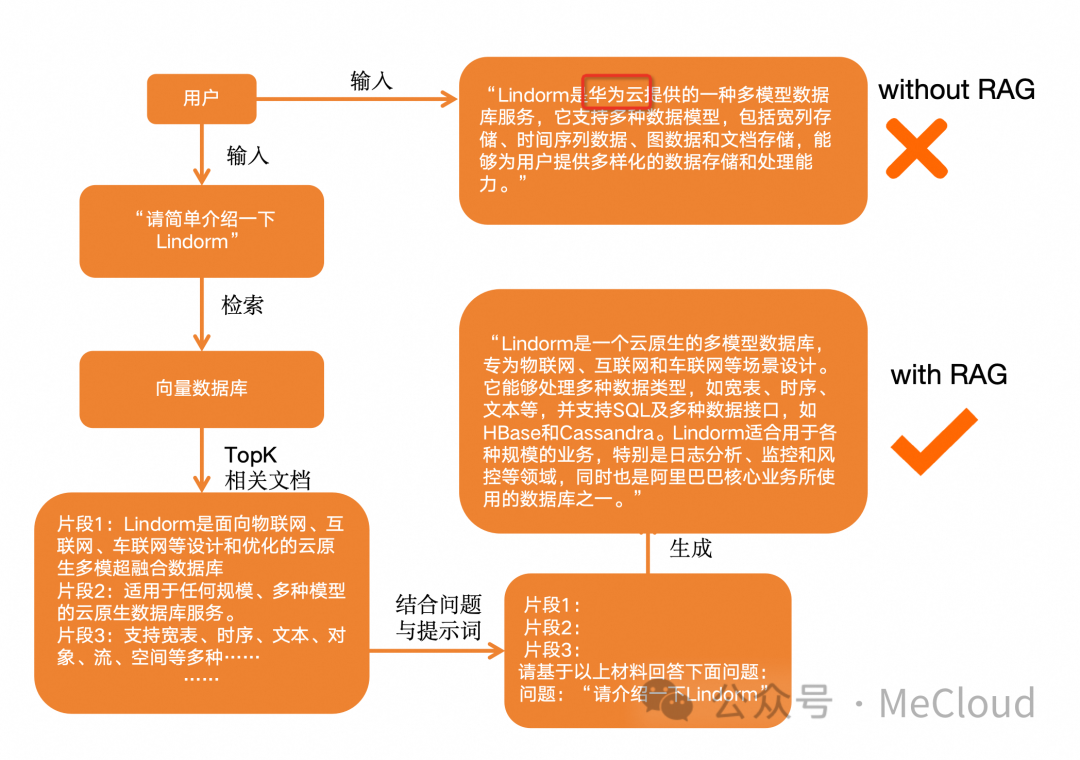
在RAG的实践中,关键的技术挑战可概括为以下三个方面:
数据向量化的信息损失问题:为了有效地检索文档,通常需将文本数据转化为数值向量,即进行数据向量化。此转换涉及将高维的文本数据映射到低维的向量空间,目的是使得向量空间中距离较近的点对应语义相似的文本。尽管此方法在检索效率上具有优势,但转换过程中不可避免地会丢失原始文本的一些信息。文本的多样性和复杂性使得其细节难以被有限维度的向量完全捕捉,从而可能忽视关键特征,影响检索的准确性和效果。
语义搜索的不准确性问题:RAG系统的语义搜索环节致力于基于用户的查询,从数据集中检索出语义上最相关的文档。这一挑战在于准确理解用户查询与文档内容的语义,并衡量二者之间的相似度。常用的方法是基于向量表示来计算语义近似度。然而,由于向量表示并不总能精确捕捉语义相似度,加之向量空间的噪声和异常值可能导致误导,语义搜索结果的准确率存在不确定性。
大型语言模型(LLM)的幻觉问题:在RAG架构中,LLM负责根据检索到的文档与用户查询生成合适的答案。虽然LLM能通过学习大量数据来展现出色的语言理解和生成能力,但它们有时会产生与事实不符或逻辑不连贯的文本,称为幻觉。这种现象源于多种因素,如预训练数据中的错误、偏见,LLM生成过程的随机性和不确定性,以及外部环境因素的干扰。这些问题使得LLM生成的答案准确性受到质疑。
综上所述,我们可以得到一个简单的公式来理解RAG的能力:
RAG输出的准确率=向量信息保留率 * 语义搜索准确率 * LLM的准确率
由于整个过程中这三个环节是串行的,大模型应用整体的准确率取决于这些环节各自准确率的连乘结果。这意味着,如果任何一个环节的准确率出现缺陷,它将成为限制整个系统准确率的瓶颈。换句话说,整体的准确率受限于最弱的那个环节,因为即便其他环节的准确率很高,一个环节的低准确率也会显著降低最终产出的准确性。
02
—
目前来看,业界针对RAG的优化也主要是围绕这三个环节开展
1、通过COT等方式提升LLM对问题的理解程度
大模型思维链CoT(chain of thought)是一种最近开发的提示方法,它鼓励大语言模型解释其推理过程。思维链的主要思想是通过向大语言模型展示一些少量的 exapmles,在样例中解释推理过程,大语言模型在回答提示时也会显示推理过程。这种推理的解释往往会引导出更准确的结果。
以一个数学题为例:

标准 Prompting
可以看到模型无法做出正确的回答。但如果说,我们给模型一些关于解题的思路,就像我们数学考试,都会把解题过程写出来再最终得出答案,不然无法得分。CoT 做的就是这件事,示例如下:
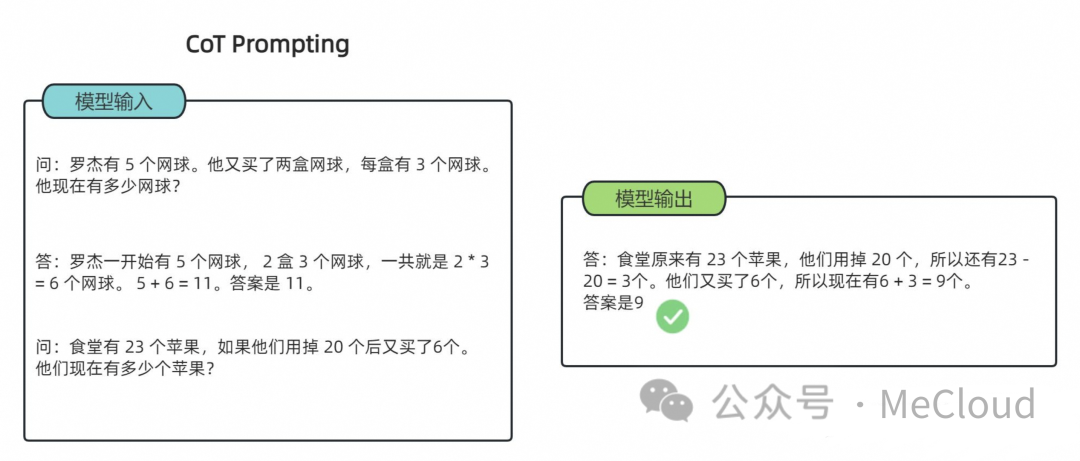
CoT提示
可以看到,类似的算术题,思维链提示会在给出答案之前,还会自动给出推理步骤:
“罗杰先有5个球,2盒3个网球等于6个,5 + 6 = 11” “食堂原来有23个苹果,用了20个,23-20=3;又买了6个苹果,3+6=9”
在CoT 的过程中,观察到其对示例中的目标输出进行了调整:源文本保持不变,但目标文本不再只是简单的答案(a),而是包含推理过程(r)和答案的组合(r+a)。
如图所示,模型产生的输出包括了完整的推理过程和答案,而不仅仅是答案本身。这一变化基于一个认识:对于语言模型而言,直接将所有语义转换成一个方程是一个较为复杂的任务,因为它涉及到更高层次的思考过程。然而,通过展示中间步骤,模型能够更有效地逐部分推理问题,从而提高了处理复杂问题的能力。传统的提示(prompt)方式通常要求大型语言模型直接解决数学问题,结果往往是模型给出了不切实际的答案,这暴露出它在逻辑推理方面的不足。相比之下,思维链方法通过在单次尝试(one-shot)中加入解题的中间步骤,引导模型遵循逐步解题的逻辑。这种方法不是要求模型直接给出计算的结果,而是要求它按步骤推导答案,从而在最终成功引导模型得出正确的结论。
2、使用Sentence Window Retrieve、Re-rank等方式提升语义搜索的准确率
利用Sentence Window Retrieve:这种方法通常是指在检索阶段使用一种滑动窗口机制来捕获文档中的连续句子,作为可能包含答案的语义单元。这样可以防止仅检索到片面或断章取义的内容。滑动窗口检索可以提取出更准确的上下文,因为它保持了文档内连续句子的自然连贯性。 Re-rank(重排):Re-rank是在初步检索结果的基础上,运用一种排名模型进一步评估和排序这些结果的过程。这个模型会考虑检索到的文档与查询的相关性,包括语义相似度和其他可能的评分指标。通过这种方式,可以将最相关的信息或文档置于列表的顶端,使得生成模型能够使用到最高质量的上下文信息。
3、通过针对的选择和优化embedding算法来最大化的保留原始数据的信息。
检索阶段的性能对于最终生成的质量至关重要。为了检索到最相关的信息,需要将查询和文档转换为向量(embeddings),这些向量在一个多维空间中表示文本的语义内容。通过针对性选择和优化嵌入算法,可以最大限度地保留原始数据的信息,并提高检索的效率和准确性。
提高语义表达能力:选用能够更好地捕捉语义信息的嵌入算法,如基于Transformer的BERT或RoBERTa模型,可以产生更丰富的文本表示。这样的嵌入向量能够包含更多的上下文信息和词语间的关联,从而在检索时更准确地匹配查询。
降维和优化:嵌入向量的维度可能非常高,导致计算开销大并增加检索时间。通过降维技术(如PCA或t-SNE)或优化算法,可以减小向量的维度,同时尽量保持原始语义信息。这样既可以加快检索速度,也能维持检索准确度。
然而由于最终结果是三者的乘积,即便是耗费大量精力将每个环节都优化到95%,最终乘积也只有85%。
这显然提示我们需要寻找一种策略,以提高整体效果。比如是否可以在不依赖数据向量化和语义搜索步骤的情况下,直接运用原始数据与大型语言模型(LLM)的交互,来增强RAG的准确性和效率?探索这样的方法将有助于我们绕过单个环节优化所带来的限制,实现整体性能的提升。
03
—
基于结构化数据的RAG
在引入大型语言模型(LLM)之前,传统的信息检索方法依靠将数据结构化来实现。这一过程包括将数据的特征事先抽象化,并将它们作为列存储在行式数据库中,数据通过一套有限的标签集合来描述。用户随后通过标准的SQL查询来检索所需信息。这种方法的优势在于其准确性和高效率,然而它也有明显的劣势:对用户来说,查询有一定的学习门槛,而且这种交互方式缺乏自然流畅的人机交互体验。
当原始数据本身已经是结构化和标签化的,那么并不需要对数据进行额外的嵌入(embedding)处理。因为数据已经处于便于检索和查询的形式,这使得我们可以直接利用现有的结构化数据,无需经过复杂的数据转换步骤。这样一来,可以保留传统检索方式的高效率和准确性,同时避免不必要的数据处理工作。
结构化数据的主要特征在于其数据特征和属性是清晰定义的,能够被一组有限的标签清晰地描述,并且可以通过标准的查询语言(如SQL)进行有效检索。在这种数据的前提下,我们不需要将数据转换成向量形式。所以基本思路是利用结构化数据与大型语言模型(LLM)的交互来提升信息检索和生成的能力。这种方法避免了数据向量化和语义搜索可能带来的问题,采用直接利用原始数据结构和标准查询语句来生成回复。这样做可以依靠结构化数据的清晰属性,可以在保持高效和准确的同时,提高与LLM的交互效果。
当然这其中还有一个环节,那就是将自然语言转化为SQL语句,这里需要使用到NL2SQL模型的能力。
整体交互流程如下图所示:
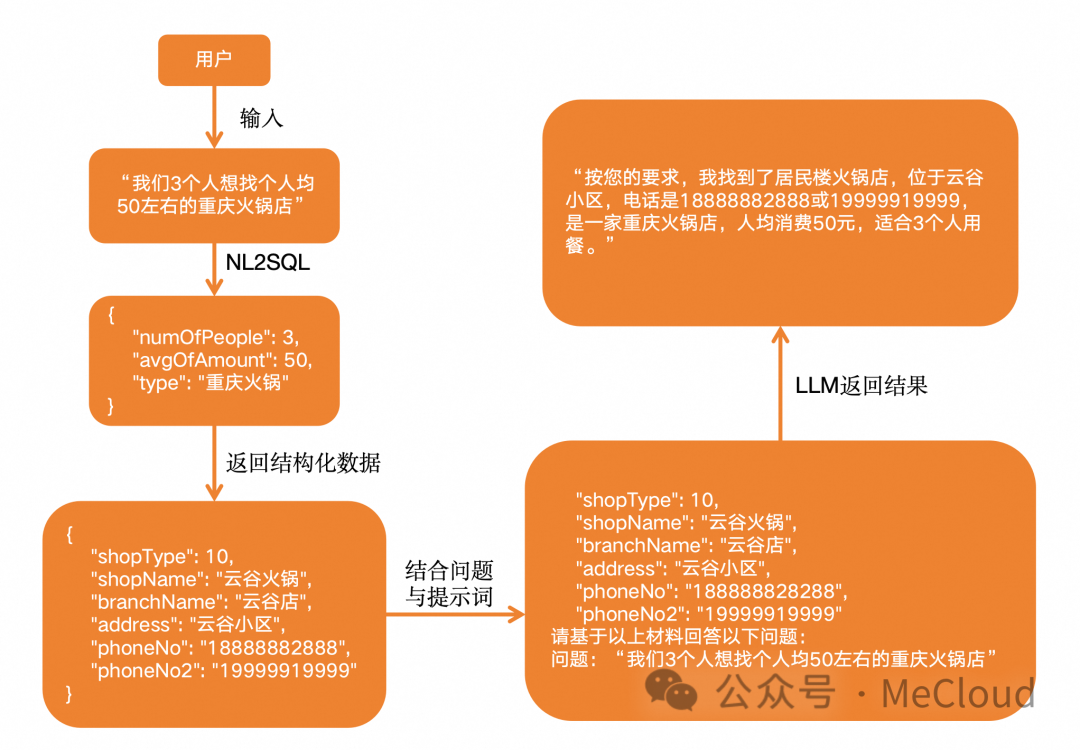
RAG基于结构化数据的基本工作流程具有以下几个显著优势:
准确性:通过直接与原始的结构化数据进行交互,结构化数据RAG避免了数据转换为向量和进行语义搜索时可能出现的误差。结构化数据拥有明确的特性和属性,可以通过有限的、明确定义的标签集进行描述,并使用标准的查询语言进行检索。这样,就不会有信息丢失或语义上的歧义。并且LLM只需从用户问题中提取关键信息以构建查询语句,无需理解整个文档的含义,减少了误解的可能性。
高效率:结构化数据RAG只需要执行标准的查询操作,这是一个快速且简单的过程。此外,结构化数据的存储和更新相比向量数据更为高效。
易于扩展:与基于向量和语义的方法相比,结构化数据RAG便于数据和查询的扩展与修改。向量化和语义搜索的过程相对固定,一旦数据或查询需求发生变化,通常需要重新进行繁琐的向量化和搜索。而结构化数据RAG只需在现有结构化数据上进行添加或修改即可,不会影响到其他数据的准确性和查询效果。同时,扩展或修改查询语句也相对简单,不会影响现有的其他查询结果。
04
—
基于向量检索+结构化数据查询+LLM构建更强的RAG
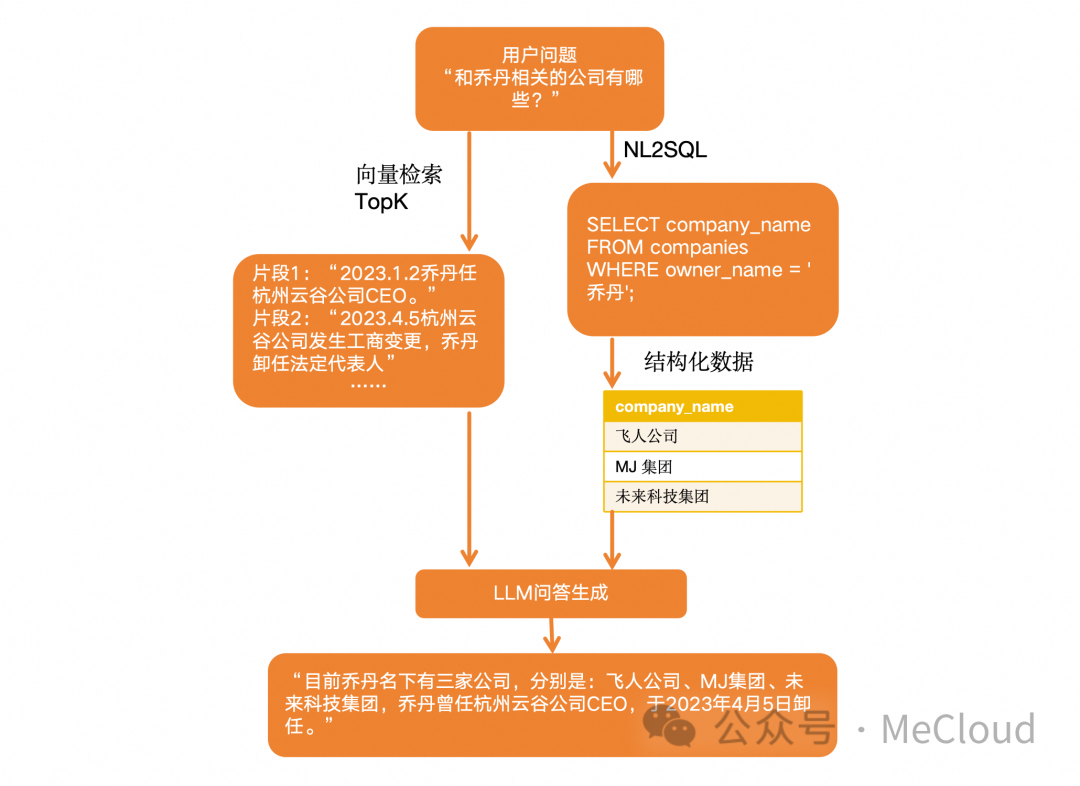
当然我们发现,无论是基于相似性检索+LLM的解决方案还是结构化数据查询+LLM的解决方案,都存在一定的局限性,比如使用向量数据库的LLM的应用会出现回答不够精准的情况,而使用结构化数据查询的应用只能检索出已有的结构化表中的数据,比如在以下场景中:公司有一张企业信息表,用户询问:“与乔丹相关的公司有哪些?”,通过NL2SQL进行结构化查询如:
SELECT company_nameFROM companiesWHERE owner_name = '乔丹';
但实际上与“乔丹”相关的公司可能不止有企业信息表中的这些数据,从而导致不能满足用户实际需求。如果我们把两种召回方式结合在一起,或许可以进一步提升整个系统的准确性。具体流程可以参考下图:
05
—
总结
随着chatbot的流行,基于相似性向量检索的RAG已成为业界的一种流行趋势。尽管RAG模型在提升对话系统的性能方面显示出了巨大潜力,但要进一步优化整体应用效果,可能需要探索现有RAG之外的替代方案。比如结合结构化数据查询和大型语言模型(LLM)的交互,这种方法虽不全然新颖,却可能是一个更为高效的手段。通过这种结合,它不仅利用了结构化数据查询在准确性方面的优势,还融合了相似性向量检索在理解语境上的强大能力。这种融合策略,将结构化数据查询和相似性向量检索结合起来,在目前这个发展阶段,可能是实现chatbot落地的更优选择,而关系型数据库也许有了新的增长动力。
#大模型 #AIGC
