




问题概述
VMEM使用超高引起的查询取消
- 错误日志:ERROR: XX000: Canceling query because of high VMEM usage. Used: 2433MB, available 266MB, red zone: 2430MB GreenPlum自带策略:如果 使用内存 / gp 总内存 > 90%,则会取消后续的 SQL SQL被取消,则数据丢失。
- 问题:使用太多虚拟内存的特定查询被取消。
原因:当一个段上虚拟内存的使用超过了由 runaway_detector_activation_percent 配置的虚拟内存百分比阈值,就会发生此错误。
测试SQL执行计划
twodb=> select count(*) from t_order;
count
---------
1424940
(1 row)
twodb=> explain analyze
twodb-> select count(*) from t_order t1
twodb-> join t_order t2 on t1.order_no =t2.order_no;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------
--------------------------------------
Aggregate (cost=0.00..1030.84 rows=1 width=8) (actual time=1167.128..1167.128 rows=1 loops=1)
-> Gather Motion 16:1 (slice3; segments: 16) (cost=0.00..1030.84 rows=1 width=8) (actual time=951.071..1167.064 rows=16 loops=1)
-> Aggregate (cost=0.00..1030.84 rows=1 width=8) (actual time=1015.334..1015.334 rows=1 loops=1)
-> Hash Join (cost=0.00..1030.84 rows=329834 width=1) (actual time=246.377..532.424 rows=328069 loops=1)
Hash Cond: ((t_order.order_no)::text = (t_order_1.order_no)::text)
Extra Text: (seg7) Hash chain length 4.2 avg, 17 max, using 21380 of 65536 buckets.
-> Redistribute Motion 16:16 (slice1; segments: 16) (cost=0.00..460.09 rows=89059 width=41) (actual time=0.060..51.382 rows=89797 loops=1)
Hash Key: t_order.order_no
-> Seq Scan on t_order (cost=0.00..441.87 rows=89059 width=41) (actual time=0.078..50.652 rows=89715 loops=1)
-> Hash (cost=460.09..460.09 rows=89059 width=41) (actual time=245.145..245.145 rows=89797 loops=1)
-> Redistribute Motion 16:16 (slice2; segments: 16) (cost=0.00..460.09 rows=89059 width=41) (actual time=9.678..170.978 rows=89797 loops=1)
Hash Key: t_order_1.order_no
-> Seq Scan on t_order t_order_1 (cost=0.00..441.87 rows=89059 width=41) (actual time=0.052..92.603 rows=89715 loops=1)
Planning time: 43.822 ms
(slice0) Executor memory: 127K bytes.
(slice1) Executor memory: 60K bytes avg x 16 workers, 60K bytes max (seg0).
(slice2) Executor memory: 60K bytes avg x 16 workers, 60K bytes max (seg0).
(slice3) Executor memory: 17024K bytes avg x 16 workers, 17024K bytes max (seg0). Work_mem: 5872K bytes max.
Memory used: 30720kB = 30MB
Optimizer: Pivotal Optimizer (GPORCA)
Execution time: 1202.367 ms
(21 rows)
程序代码逻辑:
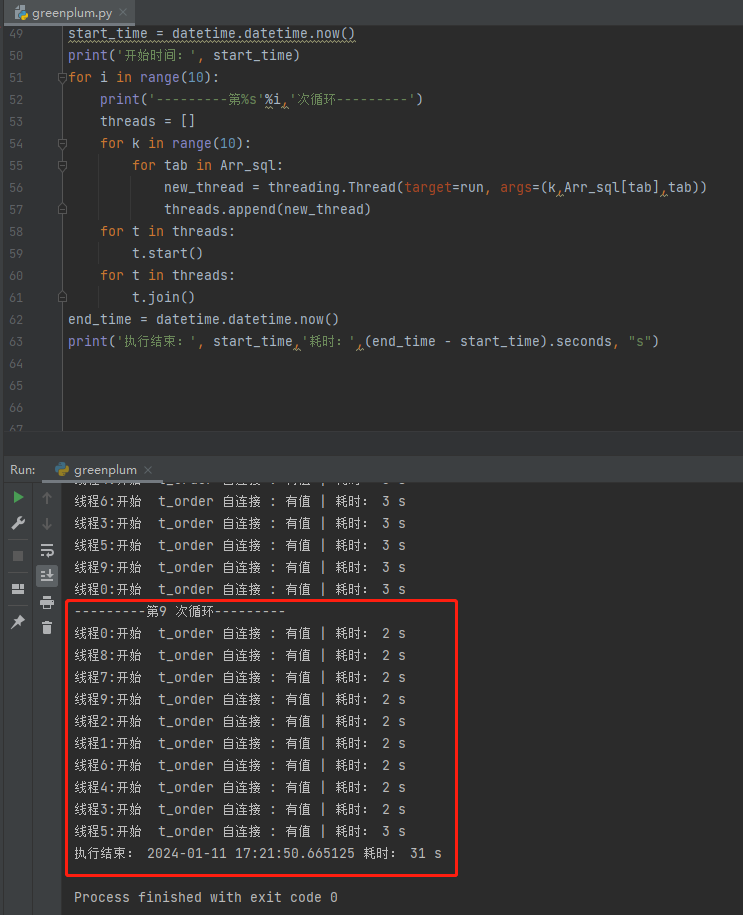
启动10个进程循环调用以上SQL执行10次
查看gp_vmem_protect_limit
[gpadmin@master ~]$ gpconfig -s gp_vmem_protect_limit
Values on all segments are consistent
GUC : gp_vmem_protect_limit
Master value: 443
Segment value: 443
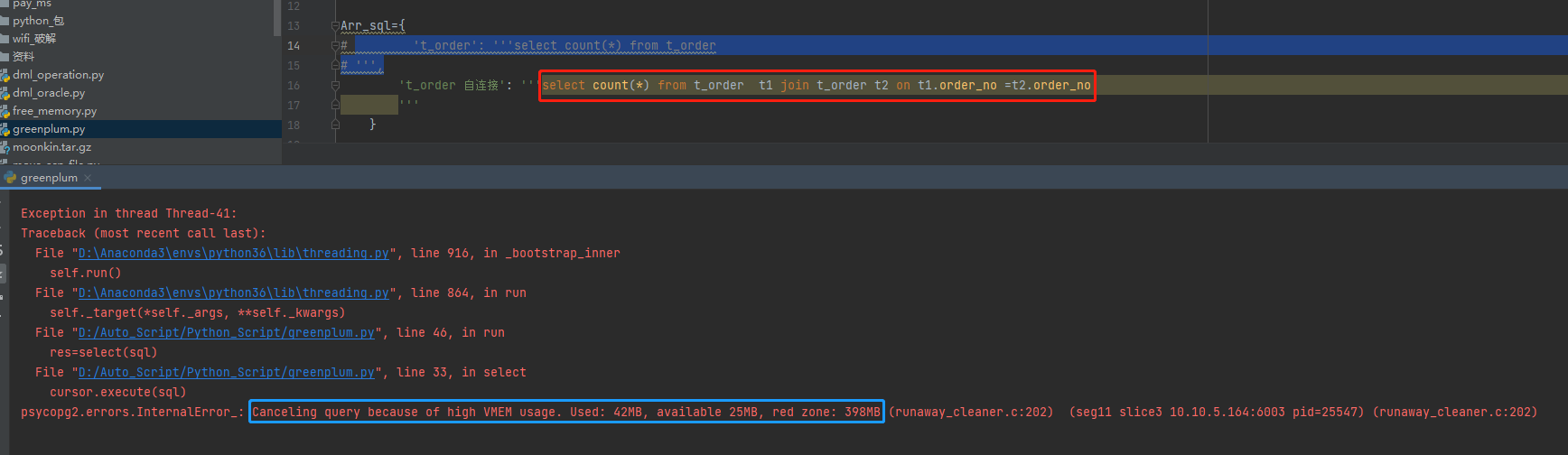
程序执行报错
Canceling query because of high VMEM usage. Used: 42MB, available 25MB, red zone: 398MB
调整 gp_vmem_protect_limit 参数至500MB
# 不要加MB,默认为MB
[gpadmin@master ~]$ gpconfig -c gp_vmem_protect_limit -v 500
# 关闭集群
[gpadmin@master ~]$ gpstop -i
# 启动集群
[gpadmin@master ~]$ gpstart -a
#查看参数
[gpadmin@master ~]$ gpconfig -s gp_vmem_protect_limit
Values on all segments are consistent
GUC : gp_vmem_protect_limit
Master value: 500
Segment value: 500
程序执行仍然报错:
Canceling query because of high VMEM usage. Used: 46MB, available 48MB, red zone: 450MB

调整 gp_vmem_protect_limit 参数至800MB
[gpadmin@master ~]$ gpconfig -s gp_vmem_protect_limit
Values on all segments are consistent
GUC : gp_vmem_protect_limit
Master value: 800
Segment value: 800
执行正常
查看 max_statement_mem
[gpadmin@master ~]$ gpconfig -s max_statement_mem
Values on all segments are consistent
GUC : max_statement_mem
Master value: 50MB
Segment value: 50MB
调小max_statement_mem 至 10MB
太小报错,恢复50MB
[gpadmin@master ~]$ gpconfig -c max_statement_mem -v 10MB
[gpadmin@master ~]$ gpstop -i
# 重启报错
[gpadmin@master ~]$ gpstart -a
20231226:04:33:18:014293 gpstart:master:gpadmin-[INFO]:-Starting gpstart with args: -a
20231226:04:33:18:014293 gpstart:master:gpadmin-[INFO]:-Gathering information and validating the environment...
20231226:04:33:18:014293 gpstart:master:gpadmin-[INFO]:-Greenplum Binary Version: 'postgres (Greenplum Database) 6.20.5 build commit:bd00a8103dd57c80bd98192b5b3516fd5179912b'
20231226:04:33:18:014293 gpstart:master:gpadmin-[INFO]:-Greenplum Catalog Version: '301908232'
20231226:04:33:18:014293 gpstart:master:gpadmin-[INFO]:-Starting Master instance in admin mode
20231226:04:33:18:014293 gpstart:master:gpadmin-[CRITICAL]:-Failed to start Master instance in admin mode
20231226:04:33:18:014293 gpstart:master:gpadmin-[CRITICAL]:-Error occurred: non-zero rc: 1
Command was: 'env GPSESSID=0000000000 GPERA=None $GPHOME/bin/pg_ctl -D /u05/data/master/gpseg-1 -l /u05/data/master/gpseg-1/pg_log/startup.log -w -t 600 -o " -p 5432 -c gp_role=utility " start'
rc=1, stdout='waiting for server to start.... stopped waiting
', stderr='pg_ctl: could not start server
Examine the log output.
# 恢复至50MB
[gpadmin@master gpconfigs]$ gpssh -f hostlist -e ' sed -i "s/max_statement_mem=10MB/max_statement_mem=50MB/g" /u05/data/*/*/postgresql.conf'
[segment1] sed -i "s/max_statement_mem=10MB/max_statement_mem=50MB/g" /u05/data/*/*/postgresql.conf
[ standby] sed -i "s/max_statement_mem=10MB/max_statement_mem=50MB/g" /u05/data/*/*/postgresql.conf
[ master] sed -i "s/max_statement_mem=10MB/max_statement_mem=50MB/g" /u05/data/*/*/postgresql.conf
[segment2] sed -i "s/max_statement_mem=10MB/max_statement_mem=50MB/g" /u05/data/*/*/postgresql.conf
[gpadmin@master gpconfigs]$ gpstart -a
[gpadmin@master gpconfigs]$ gpconfig -s max_statement_mem
Values on all segments are consistent
GUC : max_statement_mem
Master value: 50MB
Segment value: 50MB
查看 statement_mem
[gpadmin@master gpconfigs]$ gpconfig -s statement_mem
Values on all segments are consistent
GUC : statement_mem
Master value: 30MB
Segment value: 30MB
查看runaway_detector_activation_percent
# 值为0禁用基于使用vmem百分比的查询。
[gpadmin@master ~]$ gpconfig -c runaway_detector_activation_percent -m 0 -v 0
[gpadmin@master ~]$ gpconfig -s runaway_detector_activation_percent
Values on all segments are consistent
GUC : runaway_detector_activation_percent
Master value: 90
Segment value: 90
以上三个参数无法设置太小,否则集群无否启动,在次就不做测试了。
总结:
此报错基本都于:gp_vmem_protect_limit 、 max_statement_mem 、 statement_mem 、 runaway_detector_activation_percent 四个参数有关,对应进行调整即可解决。
最后修改时间:2024-01-13 12:07:06
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
