赛题名称:Linking Writing Processes to Writing Quality 赛题任务:通过打字来预测论文质量 赛题类型:数据挖掘、自然语言处理 赛题链接👇:
https://www.kaggle.com/competitions/linking-writing-processes-to-writing-quality
比赛介绍
在写作过程中,总结复杂的行为动作和认知活动是困难的。作者可能会使用不同的技巧来规划和修改他们的工作,展示不同的暂停模式,或者在整个写作过程中有策略地分配时间。许多这些小动作可能会影响写作质量。尽管如此,大多数写作评估仅关注最终成果。数据科学可能能够揭示写作过程的关键方面。
这个竞赛的目标是预测文章的整体写作质量。打字行为是否会影响一篇文章的质量?您将开发一个模型,该模型经过大量键盘输入记录的数据集进行训练,这些数据集捕捉了写作过程中的各种特征。
评估指标
我们使用均方根误差(Root Mean Squared Error,RMSE)来评分提交的结果,其定义如下:
其中,𝑦𝑖是每个实例𝑖的原始值,𝑦ˆ𝑖是预测值,n是总实例数。
数据集介绍
这个竞赛的数据集包括约5000份用户在撰写文章过程中的输入日志,包括键盘输入和鼠标点击。每篇文章都在0到6的评分范围内进行了评分。您的目标是根据用户输入的日志来预测文章的评分。
train_logs.csvNonproduction
- 事件不以任何方式改变文本Input
- 事件向文章添加文本Remove/Cut
- 事件从文章中删除文本Paste
- 事件通过粘贴输入更改文本Replace
- 事件将文本的一部分替换为另一个字符串Move From [x1, y1] To [x2, y2]
- 事件将跨越字符索引x1
、y1
的文本部分移动到新位置x2
、y2用作训练数据的输入日志。为了防止重新生成文章文本,所有的字母数字字符输入都已被替换为 "anonymous" 字符;标点符号和其他特殊字符没有被匿名化。 id
- 文章的唯一IDevent_id
- 事件的索引,按时间顺序排列down_time
- 按下事件的时间(以毫秒为单位)up_time
- 弹起事件的时间(以毫秒为单位)action_time
- 事件的持续时间(down_time
和up_time
的差值)activity
- 事件所属的活动类别down_event
- 键盘/鼠标按下时的事件名称up_event
- 键盘/鼠标释放时的事件名称text_change
- 事件导致的文本更改(如果有的话)cursor_position
- 事件后文本光标的字符索引word_count
- 事件后文章的字数test_logs.csv
- 用作测试数据的输入日志,包含与train_logs.csv
相同的字段。公开版本的此文件中的日志仅用作示例以说明格式。train_scores.csvid
- 文章的唯一IDscore
- 文章获得的评分(最高6分,是竞赛的预测目标)
赛题赛程
2024 年 1 月 2 日 - 报名截止日期 2024 年 1 月 9 日 - 团队合并截止日期 2024 年 1 月 9 日 - 最终提交截止日期
优胜方案
第一名
https://www.kaggle.com/competitions/linking-writing-processes-to-writing-quality/discussion/467154
团队采用了多模型集成的方法,其中包括了LightAutoML、LGBM、Ridge、以及基于Deberta-v3-xsmall的NLP模型等。
在模型选择方面,团队使用了LGBM、Ridge、LightAutoML denselight、以及NLP模型等多个模型,并通过集成它们的预测结果来提高性能。此外,团队还使用了交叉验证策略来评估模型的稳定性和泛化能力。
最终方案
最终的"Private LB 0.557, Public LB 0.575"提交使用了以下8个模型。
MODELS = [
{'path': f'{my_data_path}silver-bullet.py','weight':0.116999},
{'path': f'{lwp_models}nn-silver-216-59084/','weight':0.211786},
{'path': f'{my_data_path}v3-base-inference.py','weight':0.100021},
{'path': 'ridge', 'ngram_range':[4], 'weight':[0.175801]},
{'path': f'{lwp_models}KAA_model2/KAA_model2_infer.py','weight':0.120928},
{'path': f'{lwp_models}v8_model_weights/ayaan-v8-LGBM.py','weight': 0.070233},
{'path': f'{lwp_models}v8_model_weights/ayaan-v8-MLP.py','weight': 0.089275},
{'path': f'{lwp_models}v9_model_weights/ayaan-v9-LGBM.py','weight': 0.169505},
]
INTERCEPT = -0.200474
交叉验证
所有模型的交叉验证都是使用以下拆分方式创建的。这可以正确权衡整体集成的模型。
skf = StratifiedKFold(n_splits=5,shuffle=True,random_state=42)
fold = np.zeros(len(train),dtype='int8')
for n, (_, val_idx) in enumerate(skf.split(train, (train['score'] * 2).astype(int))):
fold[val_idx] = n
train['fold'] = fold
特征工程
在特征工程方面,团队使用了多种技巧,包括句子和段落的聚合特征、非空格ngram特征、CountVectorizer和TFidfVectorizer特征等。此外,还使用了一些lagged特征、时间差异和聚合统计等特征,以及对暂停持续时间的统计。对于NLP模型,团队通过重构文章,使用Deberta-v3-base等模型进行训练,以提高文章质量评分的预测性能。
句子聚合特征 段落聚合特征 无空格n-gram特征 CountVectorizer特征 TFidfVectorizer特征 滞后特征 时间差异和聚合统计 KNNFeature PCA
第二名
https://www.kaggle.com/competitions/linking-writing-processes-to-writing-quality/discussion/466873
https://www.kaggle.com/code/tomooinubushi/2nd-place-solution-training-and-inference-code
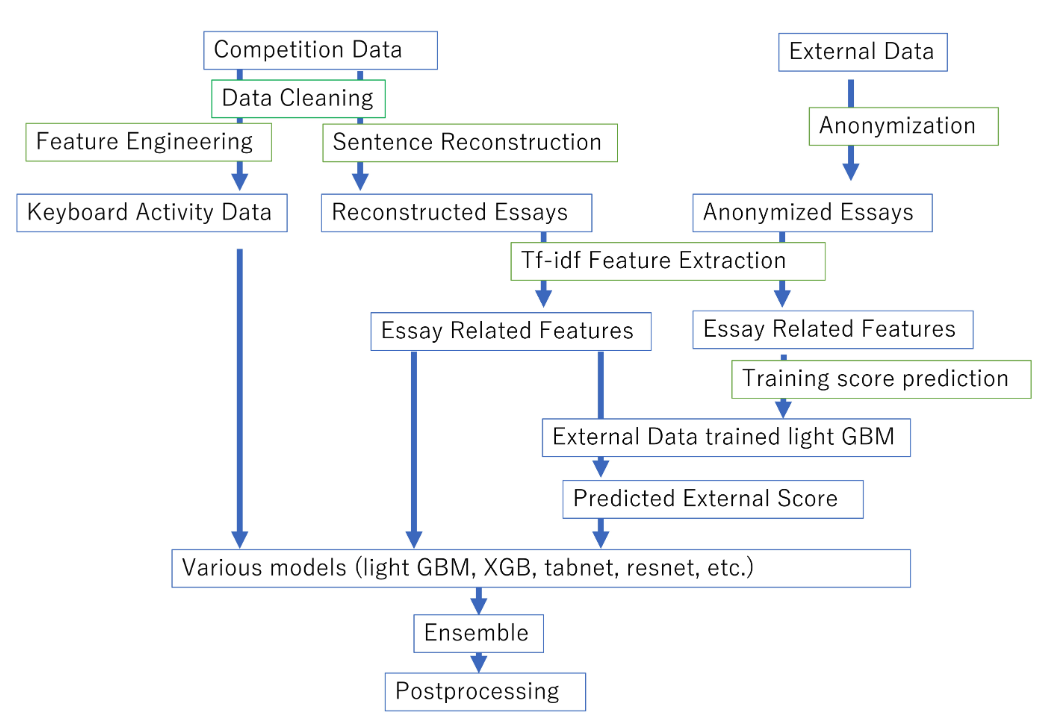
数据清理
丢弃首次输入前十分钟的事件: 从第一次输入开始的前十分钟的事件可能不具有代表性,因此被丢弃。 修正up times: 对于up times,进行了从零开始且连续增加的修正,以保持一致性。 限制gap times和action times: 对up times和down times进行了修正,以确保它们不会过大(分别限制在十分钟和五分钟内)。 修复Unicode错误: 使用ftfy修复了up events、down events和text change列中的Unicode错误。 丢弃Unidentified用户的事件: 删除了与用户ID 2f74828d相关的事件。
句子重构和特征工程
句子重构: 从键盘活动中重构了句子,因为评分仅基于最终文本,这被认为是竞赛中最重要的一部分。 改进句子重构: 对光标位置和文本更改信息与重构文本不匹配的情况进行了修正,使用最近的模糊匹配搜索序列。 修正Undo操作: 如果光标位置和文本更改信息与重构文本不匹配,进行了Undo(Ctrl+Z)操作的修正。
特征工程
团队参考了其他一些公开笔记本,并使用了378个特征,包括:
Inter Key Latency、Press Latency和Release Latency的统计信息。 每个活动和事件的总计数。 达到200、300、400和500字所需的时间。 与暂停相关的特征。 单词-时间比例、单词-事件比例等。 重构文本的统计信息(例如,每句单词数,单词长度等)。 重构文本中标点错误的总计数。 与暂停和修订突发相关的特征。 活动、事件和分类的Inter Key Latency的tf-idf特征。 重构文本的单词级和字符级tf-idf特征。 基于单词级和字符级tf-idf特征的外部文章分数的预测。
通过使用截断SVD将tf-idf特征的维度降低到64。
使用外部数据
由于训练数据规模较小,团队使用了关于文章评估的外部数据,对所有文章进行了匿名处理,并提取了与训练数据相同的tf-idf特征。然后,使用相同的特征提取器在外部数据上训练了light GBM模型,以预测外部分数。这些预测的外部分数被用作增加模型泛化性能的特征。
构建和集成多个模型
为了提高得分,使用了树模型和神经网络模型的组合。light autoML的应用是通过学习@alexryzhkov的公共笔记本获得灵感的。表格展示了多个模型的性能,包括LGBRegressor、XGBRegressor、CatBoostRegressor、tabnet等。
模型集成
使用线性回归、逻辑回归和平均值等方法对多个模型进行了集成,包括LinearRegressor、LogisticClassifier、Mean等。尝试了前向集成方法,但在CV、公共LB和私人LB得分中并没有带来明显的提升。
后处理
最终预测结果进行了简单的剪裁,将预测值限制在0.5到6.0之间,而不是采用四舍五入的方式。
一些建议
LB分数和CV分数的一致性: 作者强调了他的LB分数始终比CV分数差,但认为CV分数更为可信。这种情况可能是由于LB分数的数据分布与训练集相似。 效率奖放弃: 由于使用了额外的推理时间,作者放弃了效率奖,选择了使用外部数据来提高模型泛化性能。 模型选择中的幸运因素: 作者在模型选择中感到幸运,因为最终的获胜模型是公共LB得分最差的模型。
第三名
https://www.kaggle.com/competitions/linking-writing-processes-to-writing-quality/discussion/466775
特征工程+树模型训练 https://www.kaggle.com/code/leonshangguan/gpu-all-in-training-with-context-fe-generation/notebook
Deberta特征提取 https://www.kaggle.com/code/leonshangguan/training-deberta-based-regressor-as-fe-extractor?scriptVersionId=158377154
训练深度模型 https://www.kaggle.com/code/leonshangguan/all-fe-of-nn-models-training-pipeline-saved-fe?scriptVersionId=158376311
训练树模型 https://www.kaggle.com/code/leonshangguan/all-fe-of-tree-models-training-pipeline-saved-fe?scriptVersionId=158376408
预测提交 https://www.kaggle.com/code/leonshangguan/gpu-all-fe-inference?scriptVersionId=158374031
方法概述
训练Deberta回归器: 使用重建的文章,例如“Essays reconstructed”,通过在Deberta底部添加3个神经网络层,训练了一个Deberta回归器。这个过程遵循了类似于NLP过程(例如Feedback Prize - English Language Learning)的步骤,只是将字符替换为“anonymous”字符q。通过训练Deberta-based回归器,可以达到大约0.75的CV分数。 上下文特征提取: 删除Deberta回归器的最后一层,并使用倒数第二层的输出,即128维向量,作为由语言模型(即Deberta)提取的上下文特征。 特征选择: 基于在公共LB排行榜上表现良好的公共笔记本(主要来自@yunsuxiaozi的Writing Quality(fusion_notebook))中的特征,训练了lightgbm/xgboost/catboost模型,并保存了特征重要性。然后,从每个模型中选择了前64/128/256个最重要的特征,并取它们的并集。 特征融合: 最终,从公共笔记本和使用Deberta生成的上下文特征中选择的特征进行了串联。同时,训练了lightgbm/xgboost/catboost模型(CV分数在0.588到0.595之间),以及nn模型(mlp/autoint/denselight,CV分数在0.580到0.590之间)。 其他可能性: 由于时间限制,仅训练了一个基于Deberta的模型作为上下文提取器,但作者认为其他语言模型(例如Bert)甚至是llms(例如llama)也值得尝试。由于Deberta和nn模型需要GPU资源,作者没有考虑效率赛道。
一些观点
LB分数的变化: 作者选择相信CV分数,最终在公共LB中取得了第3名的成绩。作者预期会有一些波动,但没有预料到会上升到第3名。 模型选择和GPU资源: 由于时间和GPU资源的限制,作者选择只训练了一个Deberta-base模型作为上下文提取器。然而,作者建议尝试其他语言模型和llms,以获得更好的性能。
第四名
https://www.kaggle.com/competitions/linking-writing-processes-to-writing-quality/discussion/466906
解决方案是两个部分的集成:
首先,基于论文级别的热门公共特征构建了一个梯度提升树(GBT)集成。 其次,使用最终的论文文本构建了一个deberta模型的集成,该模型在persuade语料库上进行了mlm预训练,其中我们对文章进行了与竞赛训练集相似的模糊处理。我们通过40/60的比率对GBT集成和deberta集成进行加权。
交叉验证
我们使用8折交叉验证,在CV和LB之间得到了一些相关性。一个重要的观点是,GBT模型相对于deberta模型具有更好的LB/CV比率。换句话说,Deberta在CV上表现更好,而GBT在CV上相对较差,但在LB上表现良好。这表明LB和训练集之间存在轻微的领域偏移。猜测可能是论文按主题或学生年级分割。
数据预处理
与大多数团队类似,我们提取了每篇论文的最终文本,并训练了一个模型来分析它。在使用最终模糊的论文文本时,Deberta模型非常强大。通过将模糊字符q
替换为i
或X
,我们发现了显著的改进。对于这两种情况,可以理解到预训练的debertas在标记化方面比使用q
更好。
模型
对于GBT集成中的所有模型,我们使用了与@awqatak的公共内核中展示的相同的165个特征。然后,我们训练了一些类似于公共内核的模型。
最终的组件如下:
LGB(使用optuna调整的参数) XGB(使用optuna调整的参数) CatBoost(使用公共内核的参数) Lightautoml(使用公共内核的参数) 浅层神经网络(Shallow NN)
Deberta集成部分之一是在重建的文章文本上训练的transformer模型(Deberta)的集成。
训练过程
我们发现,使用MLM目标在persuade语料库上对transformer进行预训练显著提高了CV和LB。为此,persuade语料库中的文章必须与训练集产生的文章类似地进行模糊处理。然后,在第二步中,我们在训练数据上对这些模型进行了微调,添加了额外的特征,如光标位置等,并使用Squeezeformer层提取语义特征。在我们添加的三个特征上,需要大量的dropout/增强。
最终的组件如下:
deberta-v3-base(用i替换q进行训练) deberta-v3-large(用i替换q进行训练,微调时前12层被冻结以避免过拟合) deberta-v3-base(用X替换q进行训练) deberta-v3-base(使用自定义spm标记器进行训练)
集成
对于一些模型,我们在[0.5,6.]范围内剪切了预测值,但这并没有真正产生差异。在Deberta集成和GBT集成中,我们使用正Ridge回归对Out-of-fold(OOF)预测进行了融合权重的确定。最终对两个部分的加权是手动完成的,代表我们更信任CV还是LB。对于最终提交,我们选择了50/50内核和一个40/60内核。
第五名
https://www.kaggle.com/competitions/linking-writing-processes-to-writing-quality/discussion/466961
https://www.kaggle.com/code/chaudharypriyanshu/light-automl-lgbm-22/notebook
特征工程
段落长度(第一、第二、第三……段):字数和字符长度,一些累积长度特征。 句子长度(第一、第二、第三):字数和字符长度。 文本中的总大写字母。 文本中的总名词(总大写字母-总句子数)。 添加的非连续单词的数量。 以相同单词开头的句子数(第一个单词,前两个单词,前三个单词)。 基于时间窗口的特征:7/15/22/35分钟前添加了多少单词。 逗号的总数。 Tfidf特征ngram(1,1),共20个特征。 更多的标点统计。主要是基于计数。 问号和感叹号的总数。 超过1个字符替换的总数。 基于光标位置的特征,我使用了在重建的文章中存在的光标位置,这样我就知道了实际的标准差。作者将光标与多个位置相关联的次数。 写入具有特定长度的单词的总操作时间。 其余的特征是从公共笔记本中采用的。
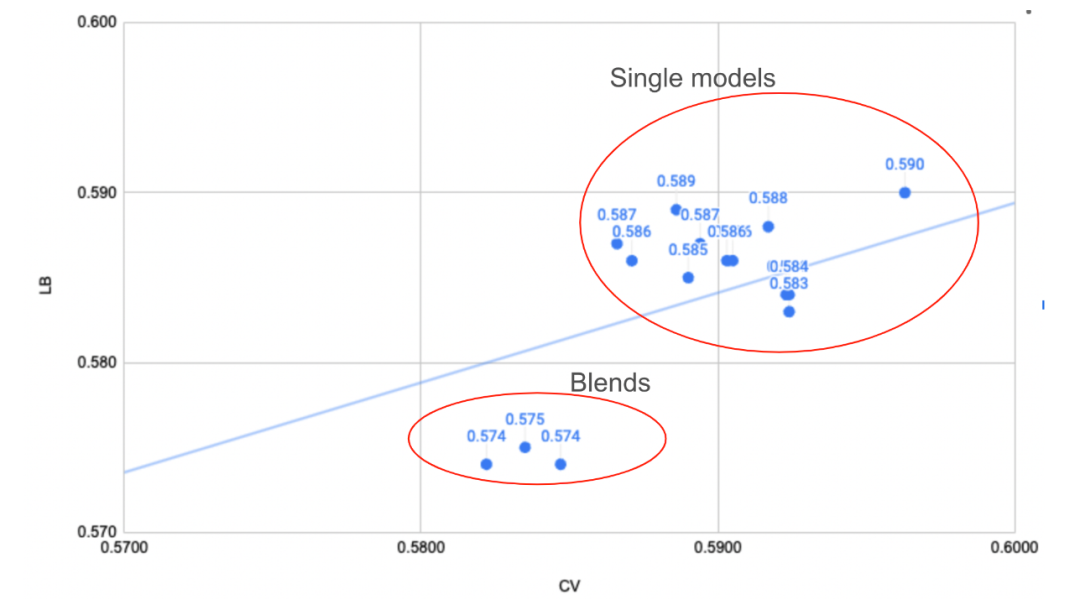
建模
对于建模,我们的团队使用了4个神经网络,其中包括1个基于1DCNN的模型和3个基于树的模型。
深度学习模型
大多数神经网络都是从lightautoML分享的公共笔记本中采用的。我们使用的架构有:
| 模型 | CV | LB |
|---|---|---|
| MLP | 0.589 | - |
| Denselight | 0.590 | - |
| Autoint | 0.599 | - |
| NODE | 0.593 | - |
| 1DCNN | 0.602 | 0.592 |
| Ensemble | 0.5868 | 0.582 |
梯度提升模型
| 模型 | CV | LB |
|---|---|---|
| LGBM | 0.598 | 0.580 |
| CATBoost | 0.6007 | - |
| XGBoost | 0.6001 | - |
| Ensemble | 0.5963 | 0.582 |
模型集成
我们独立地优化了NN和树的权重,并为两者分配了相等的权重。 使用Optuna确定每个模型的权重。
最终CV得分为0.5858,LB = 0.578,Private = 0.560。
避免不稳定的策略
使用相同的种子进行集成。 不在CV上过拟合,而是试图改善CV和LB并对两者取平均。 通过使用不同的特征集,增加了多样性,因为在不同特征上训练的模型将产生不同的结果。 分别集成了使用提前停止的NN和梯度提升模型(不使用提前停止)。 减小CV-LB之间的差异。这是最重要的。 在相同的种子上训练所有模型。
第六名
https://www.kaggle.com/competitions/linking-writing-processes-to-writing-quality/discussion/466945
选定的提交内容
交叉验证
Kfold - 10折,我们的许多模型都是用多个种子构建的,但折叠保持不变。
特征工程
波动性特征 - 随时间变化的活动百分比变化。 P-Burst - (R-Burst效果不佳) 计数矢量化器特征 TF-IDF特征与字符和ngram(4,4)即4个字符的单词 作文特征 - 单词级别、二元组、三元组 具有论文的句子、段落特征 用于活动、事件和文本更改的IDF特征 输入、非生产和删除/切割活动的顺序特征 IKI特征(IWI特征效果不佳) 按键特征 输入的打字速度变化特征(WPM) 仅在TF-IDF和CountVectorizer特征上使用BorutaPy进行特征选择
NN模型
在我们的神经网络流水线中,我们采用了一种多方面的方法来处理具有1356个特征的数据集,包括不同类型的特征缩放和复杂的神经网络架构:
特征缩放:对于浮点列,我们应用了三种类型的缩放器:鲁棒缩放器、标准缩放器和功率变换缩放器,每种都旨在根据分布的不同方面对数据进行归一化。对于整数列,使用MinMaxScaler确保值在特定范围内。
神经网络架构:
第一个NN模型:这是一个混合模型,将1D CNN与LSTM、GRU、RNN和Transformer编码器结合在一起。输出是这些模型的加权平均值,旨在捕捉数据中的空间和时间关系。 第二个NN模型:该层使用LSTM和RNN,并带有自注意机制。它从嵌入序列开始,然后通过双向LSTM和单向RNN处理它们,在将结果集成之前对每个序列应用自注意。 第三个NN模型:在结构上类似于第二层,但将RNN替换为单向GRU,同样使用自注意并集成输出。这些不同的配置在本地实现了0.590的交叉验证分数,在私人排行榜上为0.568。
集成
我们手动选择了权重。我们尝试过NelderMead以及使用Ridge进行堆叠,但我们最终选择了手动选择的权重。
Ridge / NelderMead失败的原因之一是因为模型及其分数的不一致。NN模型的CV低但公共LB高,而LGBM模型的CV与NN相当或更高,但公共LB要好得多。
Ridge / NelderMead会将更高的权重分配给NN模型(CV较低),这在公共LB上不起作用。由于公共LB占测试集的50%,我们手动选择了权重 - LGBM模型为65%,NN模型为35%。
后处理
我们将在范围(3.95,4.05)内的值四舍五入为4.0,以及在范围(3.45,3.55)内的值四舍五入为3.5。其他四舍五入的可能性并没有奏效。还将预测裁剪到(0.5,6.0)
第九名
https://www.kaggle.com/competitions/linking-writing-processes-to-writing-quality/discussion/466941
基线特征
从@awqatak的notebook中选择前100个LGBM特征,使用5折交叉验证(Group-Kfold)的验证策略,提供了CV和LB之间的很好的正相关性。
作文特征工程
no_comma: 作文中逗号“,”的数量 no_quotes: 作文中引号“"和'的数量 no_spaces: 作文中空格的数量 no_dot: 作文中句号“.”的数量 no_dot_space = np.log(no_dot) * np.log(no_spaces)
使用单词和段落生成词袋=> 90个特征
BOW (words): 对于一篇作文"qq qqqq qq",词袋是[qq: 2, qqqq: 1] BOW (paragraphs): 对于带有段落的作文"qqq q qq\n\nqq q qq",词袋是["qqq q qq": 1, "qq q qq": 1]
作文预测作为特征
为了使用作文作为特征,我们在q上训练了一个简单的自定义BPE标记器,用于生成BPE标记,然后在CountVectorizer和TfidfVectorizer中使用ngram_range=(1,3)。最后,分别在两个向量化器上训练了两个LGBM模型,并将它们各自的二进制和回归预测作为另一个特征。
(x2 essay_binary_preds) 使用编码/二进制标签作为目标,在Count/Tfidf向量上使用二进制目标和binary_logloss作为指标训练的两个LGBM。 如果概率≥0.5,则为1,否则为0。 作文CV准确性为86%。 (x2 essay_regression_preds) 使用原始标签作为目标,在Count/Tfidf向量上使用回归目标和rmse作为指标训练的LGBM。 作文CV rmse为0.614
模型
所有模型都使用相同的特征进行训练,并使用optuna进行调整。通过使用Nelder-Mead优化确定了最终权重。