





导语
字符集问题有悠久的历史和复杂的背景,是每个软件工程师/数据库工程师绕不开的话题。在如今国产化的浪潮下,应用移植过程中不可避免的会涉及一些字符集问题,有些案例中字符集问题甚至成为移植成败的关键。海量数据结合多年数据库运维和应用移植经验,研发了exBase异构数据迁移平台,为用户准备好了一切,彻底解决了数据迁移和应用移植的烦恼。
什么是字符集
在计算机中所有的数据都是以二进制存储和处理的,通过0和1的排列组合代表我们能理解的文字。
为了形成统一,美国国家标准学会于1967年制定了第一套美国信息交换标准代码(American Standard Code for Information Interchange),这就是我们常说的ASCII。
这套编码在1986年做了最后一次更新,一共收录了128个字符。包括所有的大小写字母、数字、标点符号以及33个不可见字符(如回车、换行等)。这就是最初的字符集。
虽然这套编码对英语国家来说是足够用了,但对非英语国家显然就不够了,于是各个国家又各自编制了适用于自己国家的字符集,如我们耳熟能详的中文字符集:
GB2312:1981发布的简体中文汉字编码国家标准。对汉字采用双字节编码,收录7445个图形字符,其中包括6763个汉字。
BIG5:台湾地区繁体中文标准字符集,采用双字节编码,共收录13053个中文字,1984年实施。
GBK:1995年发布的汉字编码国家标准,是GB2312编码的扩充,对汉字采用双字节编码。共收录21003个汉字,包含国家标准GB13000-1中的全部中日韩汉字,和BIG5编码中的所有汉字。
GB18030:2000年发布的汉字编码国家标准,是GBK编码的扩充,覆盖中文、日文、朝鲜语和中国少数民族文字,其中收录27484个汉字。GB18030字符集采用单字节、双字节和四字节三种方式对字符编码。兼容GBK和GB2312字符集。
Unicode:国际标准字符集,它将世界各种语言的每个字符定义一个唯一的编码,以满足跨语言、跨平台的文本信息转换。Unicode采用四个字节为每个字符编码。
UTF-8:Unicode编码的转换格式,可变长编码,相对于Unicode更节省空间。
请注意上面表述中的“包括”和“兼容”两个字,GBK包括BIG5中的所有汉字;GB18030兼容GBK和GB2312.下面用两个字来说明区别:
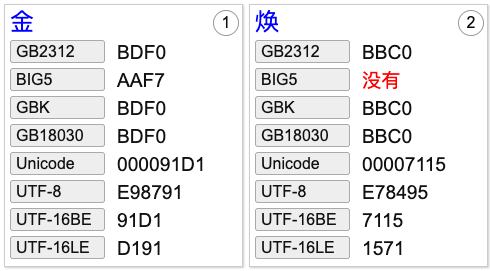
“金”字在见常的字符集中都支持,GB2312、GBK、GB18030中编码一致,用16进制表示都是BDF0,所以说GB18030兼容GB2312、GBK。BIG5中的编码是AAF7,不同于GB18030,所以GB18030不兼容BIG5,只是包括了BIG5中的所有字符。
“焕”字在BIG5中不存在,不包括在BIG5中,但包括在GB18030、GB2312、GBK、UTF-8等字符集中。
数据库中的字符集
字符集并不是数据库厂商编制的,而是各个国家的标准化组织编制的。数据库厂商为了适应不同用户的需求,在数据库中实现了这些编码,这就是数据库中的字符集。在应用设计阶段就要充分考虑应用对字符集的需求,选择合适的字符集。字符集的选择有两个方面的影响:
存储空间:同样一个汉字在GBK中占两个字节,而在UTF-8中要占3-4个字节。
字符数量:GB2312可支持的汉字明显少于GBK和GB18030,所以会遇到生僻字。即使使用GBK也偶尔会遇到生僻字而无法支持。
近期有客户反馈,有个人名中有生僻字,插入成功了,但查看是乱码:
create table mvstest_0111 (id number,name varchar2(20));
insert into mvstest_0111 values(1,'𬎆');
select * from mvstest_0111 where id=1;
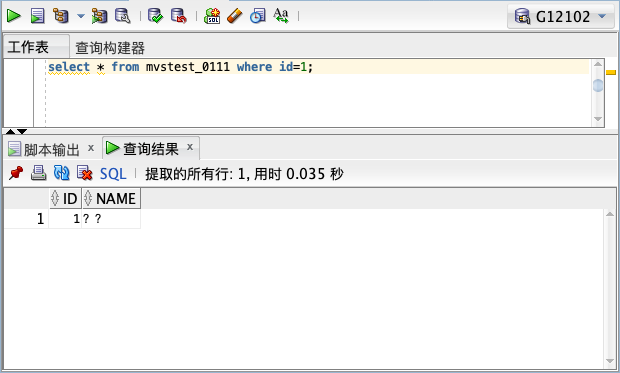
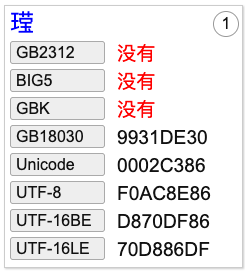
检查这个字的编码可知,GBK字符集中没有这个汉字,而GB18030和UTF-8中做了收录。
换到字符集是UTF-8的数据库里测试,则可以正常显示:
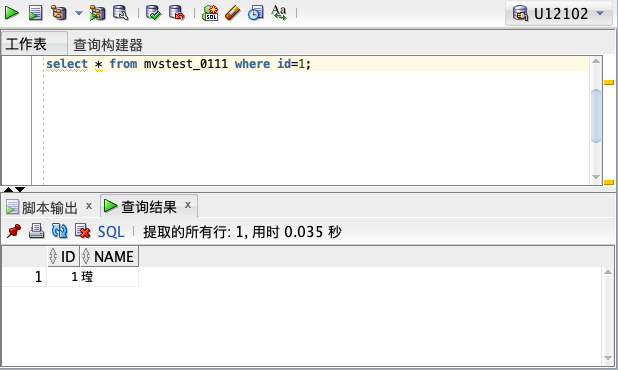
想要正确显示这个字,就需要在创建数据库时选择UTF-8或GB18030字符集。
应用移植中的字符集案例分析
经常会有客户遇到字符集相关的问题,这些问题往往具有普遍性,本节我们通过两个例子进行说明。
案例一
ASCII字符集迁移到UTF-8出现乱码
某客户原数据库的字符集使用的是US7SCII,迁移到字符集为GBK的Vastbase数据库中出现乱码。
通过上文我们知道US7SCII只支持128个字符,如果想存储更多可用字符,需要在应用端进行转码,如下面的例子:
String utf8Str = "aaa";
String gbkStr = new String(utf8Str.getBytes(StandardCharsets.ASCII), Charset.forName("GBK"));
这其实是在一个错误的字符集基础上运行的应用。迁移到GBK的数据库中应用需要进行适当改造,取消转码即可。
案例二
GBK字符集迁移到UTF-8出现乱码
客户源库的字符集为GBK,使用exBase迁移到字符集为UTF-8的Vastbase G100后中文出现乱码。下面我们使用一个简单的例子进行复现说明:
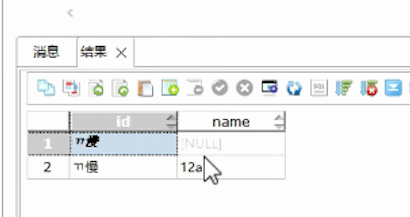
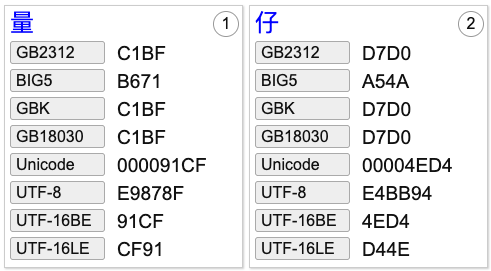
原 name字段值为量仔,迁移后变成了乱码。
源库:
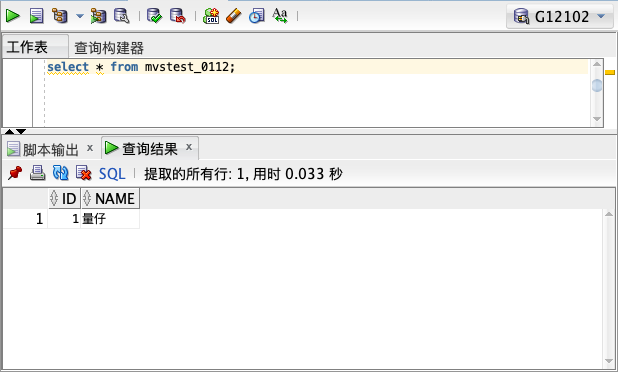
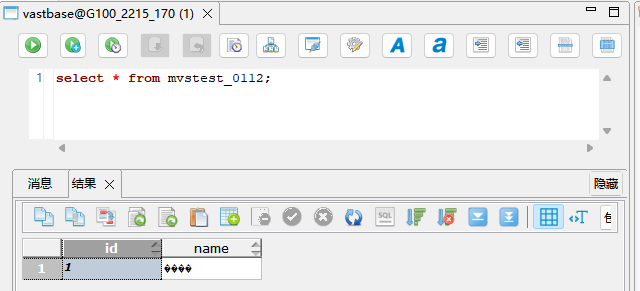
迁移后:
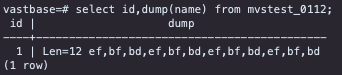
遇到此类问题我们一般需要确认两个数据库中存储的编码是否正确,源数据库提供了dump函数可以很方便的分析:
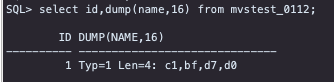
说明:源库存储的数据编码也是GBK的,与数据库字符集一致。
可以看到源库中存储的是正确的编码:
而Vastbase G100中存储的编码明显是不对的:
问题出在哪儿呢?我们要找客户要来的exBase数据源配置信息:
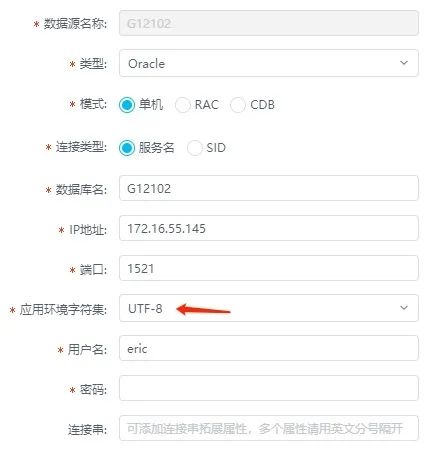
注意箭头所指的地方,原来是选错了字符集。将上面应用环境字符集改为GBK后,再次迁移便不再出现乱码。
(补充说明:如果源库数据存储的编码是UTF-8的,这里则要选择UTF-8。)
应用环境字符集介绍
现实中经常会遇到这样的情况:由于应用端字符集设置与数据库端不一致,导致数据存储的实际编码与数据库字符集不同。迁移工具如果按源数据库字符集迁移过去,实际数据是错的。海量数据的exBase迁移平台则可以实现自动转码功能。当实际存储的编码与数据库字符集不一致时,exBase数据源设置应用环境字符集,exBase会自动实现转码:
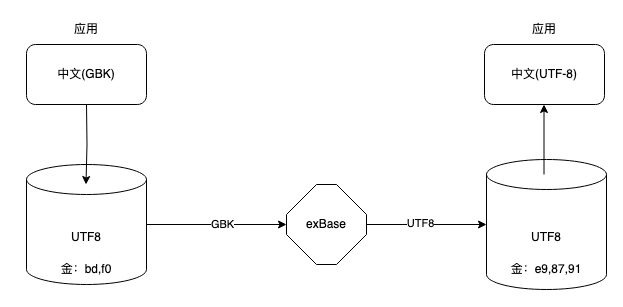
上面的案例二,正是因为客户选错了此处的字符集,导致迁移后中文出现乱码。
结语
字符集问题的处理往往比较复杂,给客户应用移植带来诸多困难,海量数据exBase一键式异构数据库迁移平台从用户实际需求出现,已经为客户准备好了一切。可以很方便的实现数据迁移,即使编码不一致的特殊情况,也做了充分考虑,最大限度的保证应用移植成功。
• END •
关于海量数据
北京海量数据技术股份有限公司(股票代码:603138.SH)成立于2007年,是国内首家以数据库为主营业务的主板上市企业。公司十余年来秉承“专注做好数据库”的初心,始终致力于数据库产品的研发、销售和服务。核心产品海量数据库Vastbase系列、数据库一体机Vastcube系列、海量大数据Datalink系列,全栈国产化,应用满足度高,目前广泛应用于政务、制造、金融、通信、能源、交通等多个重点行业,已成为国产企业级数据库的首选之一。

