





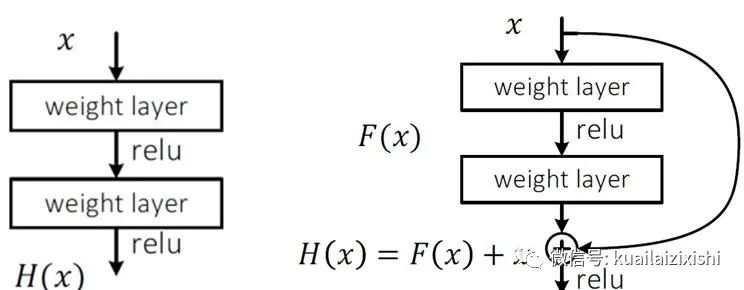
上图的左半部分是常规的神经网络形式,每层有权值和激活函数,这里的激活函数采用的是RELU函数,目的是为了避免梯度消失的问题,右半部分是残差网络的基本单元,和左边最大的不同在于多了一个身份即多了一个直接到达输出前的连线,这代表什么意思呢?刚开始输入的X,按照常规的神经网络进行权值叠加然后通过激活函数,在次权值叠加后此时在把输入的信号和此时的输出叠加然后在通过激活函数,就是这样的一个网络,而那条线称为捷径,也称为高速公路,加这个高速公路有什用呢?这个残差怎么理解呢?大家可以这样理解在线性拟合中的残差说的是数据点距离拟合直线的函数值的差,那么这里我们可以类比,这里的X就是我们的拟合的函数,而H(x)的就是具体的数据点,那么我通过训练使的拟合的值加上F(x)的就得到具体数据点的值,因此这 F(x)的就是残差了。
2.ResNet构建代码
#深度残差网络ResNet--这里包含了 ResNet18 & ResNet34
import tensorflow as tf
from tensorflow.keras import layers,Sequential
from tensorflow import keras as keras
#自定义层
class BasicBlock(layers.Layer):#这是一个小的BasicBlock
def __init__(self,filter_num,stride):#这里我们定义用到的两个参数filter_num(卷积核个数),stride步长
super(BasicBlock,self).__init__()
#unit-1
self.conv1 = layers.Conv2D(filter_num,(3,3),strides=stride,padding='same')
'''注意这里的strides是变量,因为strides=stride,而上面的stride=1定义是可以改变的,所以可能直接经过
conv下采样,而不需要多写一层subsampling/pooling-layer
与此同时,padding=same在CONV卷积层后尺寸是否不变由步长strides是否大于1决定,因为padding='same'有
两种方式,当strides=1时,这样前后尺寸大小一致,当strides=2时,前面如果是32*32,那么后面就
补0-padding成16*16的尺寸,strides=3,前面如果是30*30,后面就是10*10'''
self.bn1 = layers.BatchNormalization(trainable=True)
self.relu = layers.Activation('relu')
#unit-2-这一unit不再做可能的下采样,可能的下采样通过unit1-strides>1实现
self.conv2 = layers.Conv2D(filter_num, (3, 3), strides=1, padding='same')
self.bn2 = layers.BatchNormalization(trainable=True)
#然后我在这里设置shortcut连接线
if stride != 1:
#stride不等于1的时候就要将x进行形状变换
#将32*32-->16*16(stride=2(上下stride,channel不做stride)时)
self.shortcut = layers.Conv2D(filter_num,(1,1),strides=stride,padding='same')
else:
self.shortcut = lambda t:t
#lambda [arg1 [,arg2,.....argn]]:expression这个函数就一个表达式
#sum = lambda arg1,arg2: arg1 + arg2 #sum(10,20) #30
def call(self,inputs,training=True):#定义这两个参数
#学习网络
out = self.conv1(inputs)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
#shortcut网络
shortcut = self.shortcut(inputs)
#相加求和
output = layers.add([shortcut,out])
output = tf.nn.relu(output)
return output
#自定义网络
class ResNet(keras.Model):
def __init__(self,sicengdemeicengbasicblockgeshu):#__init__()一定要在最上方
super(ResNet,self).__init__()
#预处理层
self.preprocess = Sequential([
layers.Conv2D(64,(3,3),strides=(1,1)),
layers.BatchNormalization(trainable=True),
layers.Activation('relu'),
layers.MaxPool2D(pool_size=(2,2),strides=(1,1),padding='same')
])
#接下来是四个ResBlock-units
self.layer1 = self.build_resblock(64, sicengdemeicengbasicblockgeshu[0])
self.layer2 = self.build_resblock(128, sicengdemeicengbasicblockgeshu[1])
self.layer3 = self.build_resblock(256, sicengdemeicengbasicblockgeshu[2])
self.layer4 = self.build_resblock(512, sicengdemeicengbasicblockgeshu[3])
#TENSORSHAPE自适应变换层-将[b,H,L,512]当中的[H,L]做平均值计算之后->[b,1,1,512]->[b,512]
self.avgpool = layers.GlobalAveragePooling2D()
#全连接层
self.fc = layers.Dense(100)#输出维度100
def call(self,inputs,training=True):
#Fisrt
out = self.preprocess(inputs)
#Second
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
#[b,512]
out = self.avgpool(out)
#[b,100]
out = self.fc(out)
return out
#自定义网络当中还需要先进行自定义一个resblock-unit
def build_resblock(self,filter_num,BasicBlock_num):#这些参数都是下面函数内容需要的
#建立容器之后再往里面添加层
resblock = Sequential()
resblock.add(BasicBlock(filter_num,stride=2))#类的API要填写__init__()初始化类函数当中的参数
#前面在BasicBlock内部只做一层下采样,这里我规定在一个ResBlock当中,仅仅第一个BasicBlock做下采样
for i in range(1,BasicBlock_num):
resblock.add(BasicBlock(filter_num,stride=1))
return resblock
#ResNet18实现
def ResNet18():
return ResNet([2,2,2,2])#每个ResBlock包括两个BasicBlock,一共四个ResBlock
#ResNet34实现
def ResNet34():
return ResNet([3,4,6,3])
3.训练和测试代码
import tensorflow as tf
from tensorflow.keras import optimizers,datasets
import os
from qaz import ResNet18
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
tf.random.set_seed(1234)
def preprocess(x,y):
#tf.cast(x,dtype=tf.float32)/255.是转换到[0,1]然后×2-1转换到[-1,1]
x = 2*(tf.cast(x,dtype=tf.float32)/255.)-1
y = tf.cast(y,dtype=tf.int32)
return x,y
(x,y),(x_test,y_test)=datasets.cifar100.load_data()
y = tf.squeeze(y,axis=1)#[b]
y_test = tf.squeeze(y_test,axis=1)#[b]
db_train = tf.data.Dataset.from_tensor_slices((x,y))
db_train = db_train.map(preprocess).shuffle(50000).batch(64)#shuffle后面是buffer-存放缓冲区
db_test = tf.data.Dataset.from_tensor_slices((x_test,y_test))
db_test = db_test.map(preprocess).shuffle(10000).batch(64)
sample=next(iter(db_train))
sample_test=next(iter(db_test))
print(sample_test[0].shape,sample_test[1].shape)
def main():
model = ResNet18()
model.build(input_shape=(None,32,32,3))
model.summary()
optimizer = optimizers.Adam(lr=3e-4)
for epoch in range(20):
#训练数据
for step,(x,y) in enumerate(db_train):
with tf.GradientTape() as tape:
#logits[b,100]
logits = model(x)
#[b]->[b,100]
y_onehot = tf.one_hot(y,depth=100)
loss = tf.losses.categorical_crossentropy(y_onehot,logits,from_logits=True)
loss = tf.reduce_mean(loss)
grads = tape.gradient(loss,model.trainable_variables)
optimizer.apply_gradients(zip(grads,model.trainable_variables))
if step % 100 == 0:
print(epoch,step,'loss:',loss.numpy())
#测试模型
total_num = 0
total_correct = 0
for _,(x,y) in enumerate(db_test):#这里都是一个batch一个batch的做测试,所以有step的概念存在
#logits[b,100]
logits = model(x)
prob = tf.nn.softmax(logits,axis=1)
pred = tf.argmax(prob,axis=1)
pred = tf.cast(pred,dtype=tf.int32)#pred[b]
correct = tf.cast(tf.equal(y,pred),dtype=tf.int32)
correct = tf.reduce_sum(correct)
total_num += x.shape[0]#每个batch的x.shape[0]不一样
total_correct += int(correct)
acc = total_correct / total_num
#打印每个epoch的test-set的acc结果
print(epoch,'acc:',acc)
if __name__ == '__main__':
main()
4.运行结果
使用1080Ti—11G在经过100次训练之后,在一次测试集上达到0.7129的准确率ACC。
GPU测试温度:65度
GPU占用率:35.7%—64batch
