




RNN
RNN(循环神经网络)通常用来处理语音、文本等具有序列属性的任务。一个基本的RNN包括输入层、隐藏层和输出层。其结构如下:
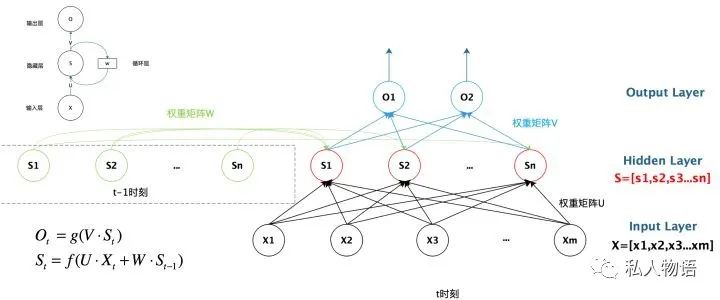 可见某时刻的输出不止和当前输入有关,还和上一次的状态有关。
可见某时刻的输出不止和当前输入有关,还和上一次的状态有关。
根据输出和输入序列不同数量rnn可以有多种不同的结构,不同结构自然就有不同的引用场合。
1. one to one 结构,仅仅只是简单的给一个输入得到一个输出,此处并未体现序列的特征,例如图像分类场景。
2. one to many 结构,给一个输入得到一系列输出,这种结构可用于生产图片描述的场景。
3. many to one 结构,给一系列输入得到一个输出,这种结构可用于文本情感分析,对一些列的文本输入进行分类,看是消极还是积极情感。
4. many to many 结构,给一些列输入得到一系列输出,这种结构可用于翻译或聊天对话场景,对输入的文本转换成另外一些列文本。
5. 同步 many to many 结构,它是经典的rnn结构,前一输入的状态会带到下一个状态中,而且每个输入都会对应一个输出,我们最熟悉的就是用于字符预测了,同样也可以用于视频分类,对视频的帧打标签。
Seq2Seq
Seq2Seq(序列到序列学习)模型是RNN最重要的一个变种:many to many(输入与输出序列长度不同,这种结构又叫Encoder-Decoder模型。
原始的many to many RNN要求序列等长,然而我们遇到的大部分问题序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。
Encoder-Decoder结构先将输入数据编码成一个上下文向量c: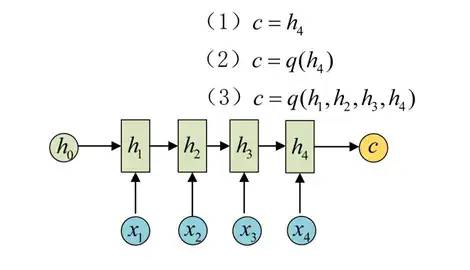
得到c有多种方式,最简单的方法就是把Encoder的最后一个隐状态赋值给c,还可以对最后的隐状态做一个变换得到c,也可以对所有的隐状态做变换。
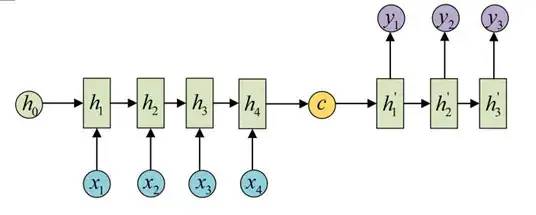
拿到c之后,就用另一个RNN网络对其进行解码,这部分RNN网络被称为Decoder。具体做法就是将c当做之前的初始状态h0输入到Decoder中:
还有一种做法是将c当做每一步的输入:
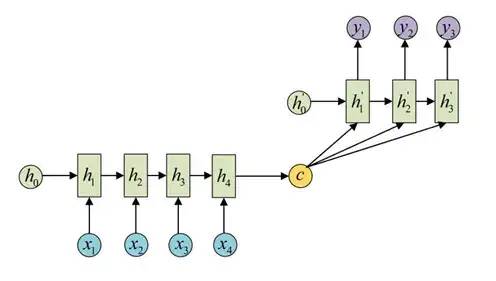
由于这种Encoder-Decoder结构不限制输入和输出的序列长度,因此应用广泛。
机器翻译:Encoder-Decoder的最经典应用,事实上这一结构就是在机器翻译领域最先提出的
文本摘要:输入是一段文本序列,输出是这段文本序列的摘要序列。
阅读理解:将输入的文章和问题分别编码,再对其进行解码得到问题的答案。
语音识别:输入是语音信号序列,输出是文字序列。
