




Ragas 介绍
https://docs.ragas.io/en/stable/
Ragas是一个大模型评测框架,可以评估检索增强生成(RAG)的效果。Ragas可以帮助分析模型的输出,了解模型在给定任务上的表现。
pip install ragas
使用案例
Ragas依赖于ChatGPT进行评测,因此首先需要设置OpenAI Key。然后需要将待评测数据集构建为dataset
的格式:
question
:提问的问题answer
:模型的回答contents
:上下文内容ground_truths
:标准回答
import os
os.environ["OPENAI_API_KEY"] = "your-openai-key"
from datasets import load_dataset
fiqa_eval = load_dataset("explodinggradients/fiqa", "ragas_eval")
from ragas.metrics import (
answer_relevancy,
faithfulness,
context_recall,
context_precision,
)
from ragas import evaluate
result = evaluate(
fiqa_eval["baseline"].select(range(3)), # selecting only 3
metrics=[
context_precision,
faithfulness,
answer_relevancy,
context_recall,
],
)
评价维度
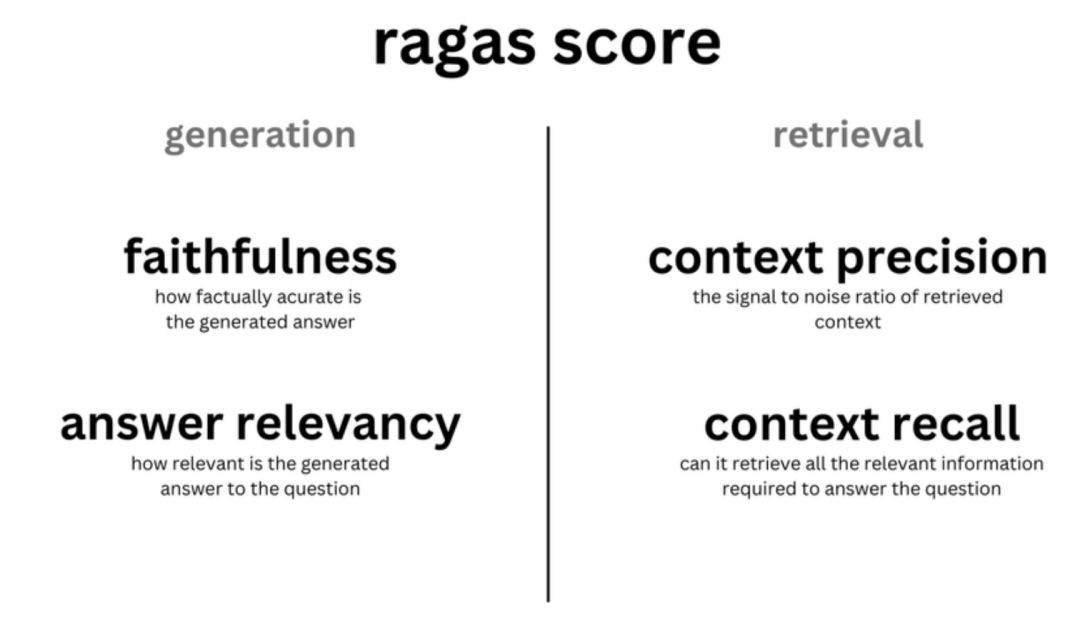
下面由Ragas提供的用于评估语言模型(LLM)和检索增强生成(RAG)应用的一些度量标准:
answer_relevancy
:度量标准评分模型生成的答案相对于给定问题的相关性。它有助于评估生成的答案在问题上下文中的相关性。answer_similarity
:度量标准评分与模型生成答案之间的语义相似性。它提供了生成的答案在意义上与预期答案的接近程度的度量。answer_correctness
:度量标准测量生成答案相对于标签的正确性。它结合了语义相似性和事实性,提供了对答案正确性的全面评估。context_precision
:评估模型选择的所有相关项是否排名较高。它评估了模型在选择相关上下文项方面的精确性。context_recall
:该度量标准通过使用带注释的答案和检索到的上下文来计算真正例(TP)和假负例(FN),从而估计上下文召回率。它提供了模型捕捉相关上下文的效果如何的指示。
评价指标
Faithfulness
Faithfulness衡量了生成的答案相对于给定上下文的事实一致性。它是从答案和检索到的上下文中计算的,并将答案缩放到(0,1)范围内,分数越高越好。
如果答案中提出的所有主张都可以从给定的上下文中推断出来,则生成的答案被视为忠实可信。为了计算这一点,首先需要从生成的答案中识别一组主张。然后,将这些主张中的每一个与给定的上下文进行交叉检查,以确定它是否可以从给定的上下文中推断出来。忠实度得分由以下公式给出:
Answer Relevance
Answer Relevancy侧重于评估生成的答案对于给定提示的相关性有多大。对于不完整或包含多余信息的答案,会分配较低的分数。该度量标准使用问题和答案进行计算,取值范围在0到1之间,其中较高的分数表示更好的相关性。
当答案直接且适当地回答原始问题时,答案被认为是相关的。重要的是,我们对答案相关性的评估不考虑事实性,而是对答案缺乏完整性或包含多余细节的情况进行惩罚。为了计算这个分数,LLM被提示多次为生成的答案生成适当的问题,然后测量这些生成的问题与原始问题之间的平均余弦相似性。基本思想是,如果生成的答案准确地回答了初始问题,LLM应该能够从答案中生成与原始问题一致的问题。
这个度量标准的目标是量化生成的答案对于初始问题有多相关,并通过测量从答案中生成的问题与原始问题之间的相似性来评估这种相关性。
Context Precision
Context Precision评估了在上下文中是否所有标签相关项都被排名得更高。理想情况下,所有相关的片段都应出现在前面的排名中。这个度量标准使用问题和上下文进行计算,取值范围在0到1之间,较高的分数表示更好的精度。
具体公式如下:
其中,Precision@k是在前k个结果中的精度,真正例@k是在前k个结果中正确预测的相关项数量,假正例@k是在前k个结果中错误预测的相关项数量。
Context Relevancy
Context Relevancy衡量了检索到的上下文的相关性,基于问题和上下文进行计算。值落在范围内,较高的值表示更好的相关性。
理想情况下,检索到的上下文应该专门包含用于回答提供的查询的关键信息。为了计算这个度量标准,我们首先通过确定在检索到的上下文中与回答给定问题相关的句子来估计的值。最终的得分由以下公式确定:
其中,是在检索到的上下文中与回答给定问题相关的句子数量,而分母是检索到的上下文中的总句子数量。
Context Recall
Context Recall度量了检索到的上下文与被视为标签的注释答案的一致性程度。它是基于真相和检索到的上下文进行计算的,取值范围在0到1之间,较高的值表示更好的性能。
为了从标签答案估计上下文召回,会分析标签中的每个句子,以确定它是否可以归因于检索到的上下文。在理想情况下,标签中的所有句子都应该可以归因于检索到的上下文。
计算上下文召回的公式如下:
其中,分子是可以归因于检索到的上下文的真相句子的数量,而分母是标签中的句子总数。
Answer semantic similarity
Answer semantic similarity评估生成的答案与标签之间的语义相似程度。这个评估基于真相和生成的答案,取值范围在0到1之间。较高的分数表示生成的答案与标签之间的更好对齐。
测量答案之间的语义相似性可以为生成的响应的质量提供有价值的见解。这个评估利用交叉编码模型来计算语义相似性分数。
Answer Correctness
Answer Correctness评估涉及对生成的答案与标签相比准确性的评估。这个评估依赖于标签和生成的答案,得分范围在0到1之间。较高的分数表示生成的答案与标签之间更紧密的对齐,表明更好的正确性。
答案正确性包含两个关键方面:生成的答案与标签之间的语义相似性以及事实相似性。这些方面使用加权方案结合在一起,形成答案正确性分数。用户还可以选择使用“阈值”值将生成的分数四舍五入为二进制值,如果需要的话。
Aspect Critique
Aspect Critique基于预定义的方面(如无害性和正确性)评估提交内容。此外,用户可以根据其特定标准定义自己的方面,以评估提交内容。方面评价的输出是二进制的,表示提交内容是否符合定义的方面。这个评估是使用“答案”作为输入进行的。
LLM评估器内部的评价器根据提供的方面评估提交内容。Ragas Critiques提供了一系列预定义的方面,如正确性、有害性等(请参考SUPPORTED_ASPECTS获取完整列表)。如果愿意,您还可以创建自定义方面,根据独特的要求评估提交内容。
严格程度参数在维持预测的某种程度的自洽性方面发挥着关键作用,理想的范围通常在2到4之间。需要注意的是,从方面评价中获得的分数是二进制的,由于其非连续性,不会对最终的Ragas得分产生影响。


