




翻译自
https://www.timescale.com/blog/postgresql-as-a-vector-database-create-store-and-query-openai-embeddings-with-pgvector/
向量数据库可以有效地存储和搜索向量数据。它们对于使用大型语言模型 (LLM) 开发和维护 AI 应用程序至关重要。
在 pgvector 扩展的帮助下,您可以利用 PostgreSQL 作为向量数据库来存储和查询 OpenAI 嵌入。OpenAI 嵌入是一种数据表示(以向量的形式,即数字列表),用于衡量 OpenAI 模型的文本字符串的相似性。
在本文中,我们将通过创建聊天机器人来回答有关时间刻度的问题。聊天机器人将接受Timescale Developer Q&A博客文章中的内容培训。此示例将说明使用 PostgreSQL 和 pgvector 创建、存储和查询 OpenAI 嵌入的关键概念。此示例包含三个部分:
第 1 部分:如何使用 OpenAI API 从内容创建嵌入。
第 2 部分:如何使用 PostgreSQL 作为向量数据库并使用 pgvector 存储 OpenAI 嵌入向量。
第 3 部分:如何使用从向量数据库中检索到的嵌入来增强 LLM 生成。
人们可以将其视为一个“hello world”教程,用于构建可以引用公司知识库或开发人员文档的聊天机器人。
Jupyter 笔记本和代码:您可以在 Jupyter Notebook 中找到本教程中使用的所有代码,以及 Timescale GitHub 上的示例内容和嵌入:timescale/vector-cookbook。
链接地址:
https://github.com/timescale/vector-cookbook/tree/main/openai_pgvector_helloworld?ref=timescale.com
建议克隆存储库,并在阅读本教程时执行代码单元。
大图:开放式 AI 嵌入
人工智能的基础模型(例如 GPT-3 或 GPT-4)可能缺少对某些特定问题给出良好答案所需的一些信息。这是因为用于训练模型的数据集中没有相关信息。(例如,信息存储在私人文档中,或者最近才可用。这种数据的缺乏可能使这些模型不适合作为特定信息库的聊天机器人。
检索增强生成 (RAG:Retrieval Augmented Generation)提供了一个简单的解决方案:在提示中为基础模型提供额外的上下文。例如,如果模型没有关于可乐果的数据,而你问,“什么是可乐果?”你可能会得到一个不正确的答案。在这种情况下,您可以通过添加上下文来转换提示:“可乐果类似于甜甜圈,由羊角面包状面团制成,里面装满了调味奶油,并用葡萄籽油油炸。什么是可乐果?
然后,基础模型可以利用其对甜甜圈和羊角面包的知识来雄辩地介绍可乐果。这种技术很强大——它允许你 “教授 ”关于只有你所知道的事情的基础模型,并使用它来为你的用户创造 ChatGPT++ 体验!
但是,您为模型提供了什么上下文?如果你有一个信息库,你怎么知道什么与给定的问题相关?这就是嵌入的用途。OpenAI 嵌入(OpenAI Embeddings)是一段文本语义含义的数学表示,允许进行相似性搜索。
使用此表示形式,如果您得到用户问题并计算其嵌入,则可以对库中的数据嵌入使用相似性搜索来查找最相关的信息。但这需要具有库的嵌入表示形式。
此处引用通义千问关于OpenAI 嵌入的理解:
OpenAI Embeddings 是 OpenAI 提供的一种技术,它能够将文本数据(如单词、短语或整个句子)转换成数学向量。这个过程被称为嵌入(Embedding),它可以理解为一种“翻译”:将我们日常使用的语言转化为机器学习模型可以理解的数字形式。
想象一下,每个单词或短语都有一个对应的高维空间中的点,这些点的位置不是随意的,而是根据它们在大量文本文档中的上下文关系和含义来确定的。这样一来,相似或相关的词语在高维空间中会更接近彼此,而不同含义或无关的词语则相距较远。
例如,使用 Open AI Embeddings 后,“猫”和“狗”的嵌入向量可能很接近,因为它们都是宠物类别;而“猫”和“宇宙飞船”的嵌入向量则可能相距较远,因为它们在语义上关联度较低。
这种嵌入技术被广泛应用于自然语言处理任务,比如文本分类、信息检索、问答系统以及机器翻译等场景,通过计算嵌入向量之间的相似度,可以有效地捕捉词汇间的语义关联,从而提升模型的理解和生成能力。
这篇文章是使用 pgvector 创建、存储和查询 OpenAI 向量嵌入的指南,pgvector 是将 PostgreSQL 转换为向量数据库的扩展。
什么是pgvector?
Pgvector 是 PostgreSQL 的开源扩展,支持存储和搜索机器学习生成的嵌入,使用户能够识别精确和近似的最近邻。Pgvector 旨在与其他 PostgreSQL 功能无缝协作,包括索引和查询。
现在我们准备开始构建我们的聊天机器人了!
准备工作:先决条件和配置
安装 Python。
安装和配置 Python 虚拟环境,我们推荐Pyenv。
使用以下命令安装此笔记本的要求:
pip install -r requirements.txt
导入我们将使用的所有包:
import openai
import os
import pandas as pd
import numpy as np
import jsonimport tiktoken
import psycopg2
import astimport pgvector
import mathfrom psycopg2.extras
import execute_valuesfrom pgvector.psycopg2
import register_vector
您需要注册一个 OpenAI 开发者帐户并创建一个 OpenAI API 密钥——我们建议获得一个付费帐户以避免速率限制并设置支出上限,这样您就可以避免账单出现任何意外。
获得 OpenAI API 密钥后,最佳做法是将其存储为环境变量,然后让 Python 程序读取它。
#First, run export OPENAI_API_KEY=sk-YOUR_OPENAI_API_KEY...
# Get openAI api key by reading local .env file
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
openai.api_key = os.environ['OPENAI_API_KEY']
第 1 部分:使用 OpenAI API 为您的数据创建嵌入
嵌入测量文本字符串的相关程度。首先,我们将使用 OpenAI API 在我们希望 LLM 回答问题的一些文本上创建嵌入。
在此示例中,我们将使用 Timescale 博客中的内容,特别是开发人员问答部分的内容,其中有 Timescale 用户谈论其实际用例的帖子。
您可以将此博客数据替换为要嵌入的任何文本,例如您自己的公司博客、开发人员文档、内部知识库或您希望获得“类似 ChatGPT”体验的任何其他信息。
# Load your CSV file into a pandas DataFrame
df = pd.read_csv('blog_posts_data.csv')
df.head()
输出如下所示: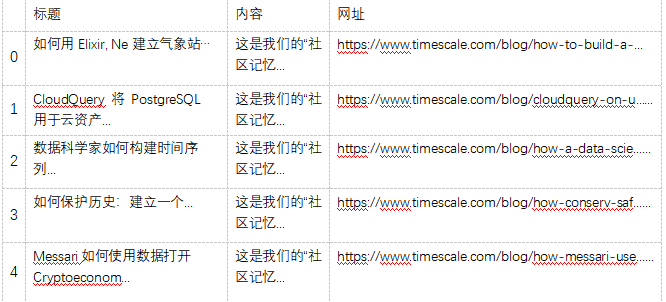
1.1 计算嵌入数据的成本
计算为所选内容创建嵌入的成本通常是一个好主意。我们提供了许多辅助函数,用于在创建嵌入之前计算成本估算,以帮助我们避免意外。
对于 OpenAI,您需要按每个token支付创建的嵌入费用。对于我们想要嵌入的博客文章,总成本将低于 0.01 美元,这要归功于 OpenAI 最近宣布将他们最受欢迎的嵌入模型 text-embedding-ada-002 的成本降低 75%。
什么是标记(tokens)?token是文本中常见的字符序列。粗略地说,token是一个单词的四分之三 (3/4)。大型语言模型,如 OpenAI 制作的 GPT-3 和 GPT-4,经过训练可以理解token之间的统计关系并预测序列中的下一个token。使用 OpenAI 的 Tokenizer 工具了解有关token的更多信息。
引用通义千问关于token的理解:在大模型(如自然语言处理中的预训练模型)中,“token”通常是指文本数据的基本单元。文本经过分词或编码处理后被分割成一系列的标记,每个标记就是一个token。这些token可以是单个单词、子词(如BERT模型采用的WordPiece分词方法生成的tokens)、字符或其他定义好的基本单位。
例如,在一个句子“Hello, how are you?”中:
如果以单词为token,则有5个token:[“Hello”, “,”, “how”, “are”, “you?”]。
如果模型使用了更细粒度的分词方式,可能会将标点符号单独作为一个token,此时可能有6个token:[“Hello”, “,”, “how”, “are”, “you”, “?”]。
Token化是将连续的自然语言文本转化为机器学习模型能够理解和处理的形式的关键步骤之一。大型语言模型通过学习大量token序列之间的统计关系和上下文依赖来理解并生成文本内容。
# Helper functions to help us create the embeddings
# Helper func: calculate number of tokens
def num_tokens_from_string(string: str, encoding_name = "cl100k_base") -> int:
if not string:
return 0
# Returns the number of tokens in a text string
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokens
# Helper function: calculate length of essay
def get_essay_length(essay):
word_list = essay.split()
num_words = len(word_list)
return num_words
# Helper function: calculate cost of embedding num_tokens
# Assumes we're using the text-embedding-ada-002 model
# See https://openai.com/pricing
def get_embedding_cost(num_tokens):
return num_tokens/1000*0.0001
# Helper function: calculate total cost of embedding all content in the dataframe
def get_total_embeddings_cost():
total_tokens = 0
for i in range(len(df.index)):
text = df['content'][i]
token_len = num_tokens_from_string(text)
total_tokens = total_tokens + token_len
total_cost = get_embedding_cost(total_tokens)
return total_cost
# quick check on total token amount for price estimation
total_cost = get_total_embeddings_cost()
print("estimated price to embed this content = $" + str(total_cost))
1.2 创建更小的内容块
OpenAI API 对它可以在单个请求中创建嵌入的最大token数量有限制:具体为 8,191 个。
为了绕过这个限制,我们将文本分解成更小的块。通常,最佳做法是将要创建的文档“分块”嵌入到具有固定token大小的组中。
要包含在块中的确切token数取决于您的用例和模型的上下文窗口,即它可以在提示中处理的输入token数。
就我们的目的而言,我们的目标是每个块大约 512 个token。将文本分块是一个复杂的话题,值得单独写一篇博客文章。我们将在下面说明一种我们发现行之有效的简单方法。如果您想了解其他方法,我们推荐这篇博文(此处提供链接不能访问)和LangChain文档的这一部分(此处文档链接:https://python.langchain.com/docs/modules/data_connection/document_transformers/?ref=timescale.com)。
注意:如果希望跳过此步骤,可以使用提供的 file:blog_data_and_embeddings.csv,其中包含将在此步骤中生成的数据和嵌入。
下面的代码创建了博客内容的新列表,同时保留了与文本关联的元数据,例如与文本关联的博客标题和 URL。
# Create new list with small content chunks to not hit max token limits# Note: the maximum number of tokens for a single request is 8191# https://openai.com/docs/api-reference/requests
# list for chunked content and embeddings
new_list = []
# Split up the text into token sizes of around 512 tokens
for i in range(len(df.index)):
text = df['content'][i]
token_len = num_tokens_from_string(text)
if token_len <= 512:
new_list.append([df['title'][i], df['content'][i], df['url'][i], token_len])
else:
# add content to the new list in chunks
start = 0
ideal_token_size = 512
# 1 token ~ 3/4 of a word
ideal_size = int(ideal_token_size // (4/3))
end = ideal_size
#split text by spaces into words
words = text.split()
#remove empty spaces
words = [x for x in words if x != ' ']
total_words = len(words)
#calculate iterations
chunks = total_words // ideal_size
if total_words % ideal_size != 0:
chunks += 1
new_content = []
for j in range(chunks):
if end > total_words:
end = total_words
new_content = words[start:end]
new_content_string = ' '.join(new_content)
new_content_token_len = num_tokens_from_string(new_content_string)
if new_content_token_len > 0:
new_list.append([df['title'][i], new_content_string, df['url'][i], new_content_token_len])
start += ideal_size
end += ideal_size
现在我们的文本被更好地分块了,我们可以使用 OpenAI API 为每个文本块创建嵌入。
我们将使用此帮助程序函数为一段文本创建嵌入:
# Helper function: get embeddings for a text
def get_embeddings(text):
response = openai.Embedding.create(
model="text-embedding-ada-002",
input = text.replace("\n"," ")
)
embedding = response['data'][0]['embedding']
return embedding
然后为每个内容块创建嵌入:
# Create embeddings for each piece of content
for i in range(len(new_list)):
text = new_list[i][1]
embedding = get_embeddings(text)
new_list[i].append(embedding)
# Create a new dataframe from the list
df_new = pd.DataFrame(new_list, columns=['title', 'content', 'url', 'tokens', 'embeddings'])
df_new.head()
新数据框应如下所示: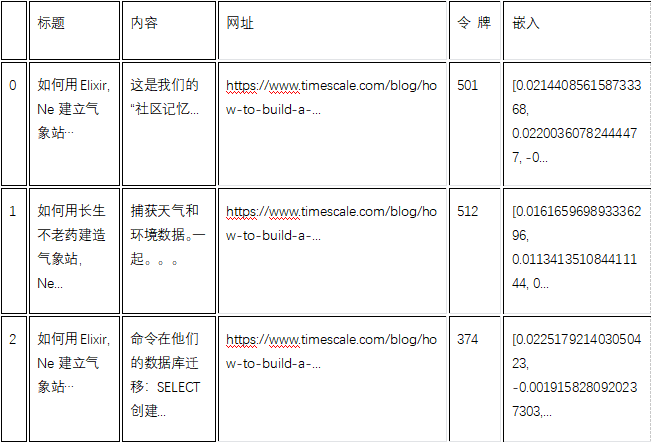

作为可选但建议的步骤,您可以将原始博客内容以及关联的嵌入保存在 CSV 文件中以供以后参考,这样,如果要在另一个项目中引用嵌入,则不必重新创建嵌入。
# Save the dataframe with embeddings as a CSV file
df_new.to_csv('blog_data_and_embeddings.csv', index=False)
第 2 部分:使用 pgvector 将 OpenAI 嵌入存储在向量数据库中
现在我们已经为博客内容创建了嵌入向量,下一步是将嵌入向量存储在向量数据库中,以帮助我们对许多向量进行快速搜索。
什么是向量数据库?
向量数据库是可以处理向量数据的数据库。向量数据库可用于:
1)语义搜索:向量数据库促进了语义搜索,它考虑了搜索词的上下文或含义,而不仅仅是完全匹配。它们对于推荐系统、内容发现和问答系统很有用。
2)高效的相似性搜索:向量数据库专为高效的高维最近邻搜索而设计,这是传统关系数据库难以完成的任务。
3)机器学习:向量数据库存储和搜索由机器学习模型创建的嵌入。此功能有助于查找在语义上与给定项目相似的项目。
4)多媒体数据处理:向量数据库在处理多媒体数据(图像、音频、视频)方面也表现出色,将它们转换为高维向量,以实现有效的相似性搜索。
5)NLP和数据组合:在自然语言处理(NLP)中,向量数据库存储表示单词、句子或文档的高维向量。它们还允许将传统 SQL 查询与相似性搜索相结合,以容纳结构化和非结构化数据。
我们将使用安装了 pgvector 扩展的 PostgreSQL 作为我们的向量数据库。Pgvector 扩展了 PostgreSQL 以处理向量数据类型和向量相似性搜索,例如最近邻搜索,我们将使用它来查找数据库中给定用户提示的最相关的嵌入。
为什么要使用 pgvector 作为向量数据库?
以下是 PostgreSQL 是存储和处理向量数据的不错选择的五个原因:
1)集成解决方案:通过使用 PostgreSQL 作为向量数据库,您可以将数据保存在一个地方。这可以通过减少对多个数据库或其他服务的需求来简化体系结构。
2)企业级稳健性和操作:PostgreSQL 拥有 30 年的血统,提供世界一流的数据完整性、操作和稳健性。这包括备份、流式复制、基于角色和行级别的安全性以及 ACID 合规性。
3)全功能 SQL:PostgreSQL 支持一组丰富的 SQL 功能,包括联接、子查询、窗口函数等。这允许强大而复杂的查询,可以包括传统的关系数据和向量数据。它还与大量现有的数据科学和数据分析工具集成。
4)可扩展性和性能:PostgreSQL 以其健壮性和处理大型数据集的能力而闻名。将其用作向量数据库,您也可以将这些特征用于向量数据。
5)开源:PostgreSQL 是开源的,这意味着它可以免费下载和使用,您可以根据需要对其进行修改。这也意味着它受益于世界各地开发人员的集体投入,这通常会产生高质量、安全和最新的软件。PostgreSQL 有一个庞大而活跃的社区,因此随时可以获得帮助。有许多资源(例如文档、教程、论坛等)可帮助您对 PostgreSQL 数据库进行故障排除和优化。
2.1 创建PostgreSQL数据库并安装pgvector
首先,我们将创建一个 PostgreSQL 数据库。您可以在 Timescale 上免费在几分钟内创建云 PostgreSQL 数据库,也可以在此步骤中使用本地 PostgreSQL 数据库。
创建 PostgreSQL 数据库后,将连接字符串导出为环境变量,就像 OpenAI API 密钥一样,我们会将其从环境文件读入 Python 程序:
# Timescale database connection string
# Found under "Service URL" of the credential cheat-sheet or "Connection Info" in the Timescale console
# In terminal, run: export TIMESCALE_CONNECTION_STRING=postgres://<fill in here>
connection_string = os.environ['TIMESCALE_CONNECTION_STRING']
然后,我们使用流行的 psycopg2 python 库连接到我们的数据库,并安装 pgvector 扩展,如下所示:
# Connect to PostgreSQL database in Timescale using connection string
conn = psycopg2.connect(connection_string)
cur = conn.cursor()
#install pgvector
cur.execute("CREATE EXTENSION IF NOT EXISTS vector");
conn.commit()
2.2 连接并配置您的向量数据库
安装 pgvector 后,我们使用 register_vector() 命令将向量类型注册到我们的连接中:
# Register the vector type with psycopg2
register_vector(conn)
连接到数据库后,让我们创建一个表,用于存储嵌入和元数据。我们的表格如下所示:
id表示表中每个向量嵌入的唯一 ID。
title是从中获取与嵌入关联的内容的博客标题。
url是从中获取与嵌入关联的内容的博客 URL。
content是与嵌入关联的实际博客内容。
tokens是嵌入所表示的标记数。
embedding是内容的向量表示形式。
使用 PostgreSQL 作为向量数据库的一个优点是,您可以轻松地将元数据和嵌入向量存储在同一个数据库中,这有助于提供与他们收到的响应相关的用户相关信息,例如阅读更多内容的链接或与其相关的博客文章的特定部分。
# Create table to store embeddings and metadata
table_create_command = """
CREATE TABLE embeddings (
id bigserial primary key,
title text,
url text,
content text,
tokens integer,
embedding vector(1536)
);
"""
cur.execute(table_create_command)
cur.close()
conn.commit()
2.3 使用 pgvector 将向量数据摄取并存储到 PostgreSQL 中
现在,我们已经创建了数据库并创建了用于容纳嵌入和元数据的表,最后一步是将嵌入向量插入到数据库中。
对于此步骤,最佳做法是批量插入嵌入,而不是逐个插入。
#Batch insert embeddings and metadata from dataframe into PostgreSQL database
register_vector(conn)
cur = conn.cursor()
# Prepare the list of tuples to insert
data_list = [(row['title'], row['url'], row['content'], int(row['tokens']), np.array(row['embeddings'])) for index, row in df_new.iterrows()]
# Use execute_values to perform batch insertion
execute_values(cur, "INSERT INTO embeddings (title, url, content, tokens, embedding) VALUES %s", data_list)
# Commit after we insert all embeddings
conn.commit()
让我们通过对新插入的数据运行一些简单的查询来检查健全性:
cur.execute("SELECT COUNT(*) as cnt FROM embeddings;")
num_records = cur.fetchone()[0]print("Number of vector records in table: ", num_records,"\n")
# Correct output should be 129
# print the first record in the table, for sanity-checking
cur.execute("SELECT * FROM embeddings LIMIT 1;")
records = cur.fetchall()print("First record in table: ", records)
2.4 为数据编制索引以便更快地检索
在这个例子中,我们只有 129 个嵌入向量,因此搜索所有这些向量的速度非常快。但对于较大的数据集,您需要创建索引以加快搜索相似嵌入的速度,因此我们包含用于构建索引的代码以进行说明。
Pgvector 支持 ivfflat 索引类型,以加快近似最近邻 (ANN) 搜索的速度(高维数据的相似性搜索索引通常是近似的)。
您始终希望在插入数据后构建此索引,因为索引需要发现数据中的聚类才能生效,并且它仅在首次构建索引时才执行此操作。
该索引具有要使用的列表数的可调参数,下面的代码显示了优化此参数的最佳实践。您还需要指定用于编制索引的距离度量值,并确保它与查询中使用的度量值匹配。在我们的例子中,我们使用余弦距离进行下面的查询,因此我们使用 .vector_cosine_ops
# Create an index on the data for faster retrieval
#calculate the index parameters according to best practices
num_lists = num_records / 1000
if num_lists < 10:
num_lists = 10
if num_records > 1000000:
num_lists = math.sqrt(num_records)
#use the cosine distance measure, which is what we'll later use for querying
cur.execute(f'CREATE INDEX ON embeddings USING ivfflat (embedding vector_cosine_ops) WITH (lists = {num_lists});')
conn.commit()
第 3 部分:使用 pgvector 进行最近邻搜索
给定用户问题,我们将执行以下步骤,使用存储在向量数据库中的信息,通过检索增强生成来回答他们的问题:
1)为用户问题创建嵌入向量。
2)使用 pgvector 执行向量相似性搜索,并从表示博客内容的嵌入向量中检索嵌入问题的最邻近对象。在我们的示例中,我们将使用k=3,找到三个最相似的嵌入向量和相关内容。
3)提供从数据库中检索到的内容作为模型的附加上下文,并要求它执行完成任务来回答用户问题。
3.1 定义您要回答的问题
首先,我们将定义一个示例问题,用户可能希望回答有关存储在数据库中的博客文章的问题。
# Question about Timescale we want the model to answer
input = "How is Timescale used in IoT?"
由于 Timescale 在物联网传感器数据中很受欢迎,因此用户可能希望了解有关如何在该用例中利用它的详细信息。
3.2 在数据库中查找最相关的内容
下面是我们用来查找用户问题最近的三个邻居的函数。请注意,它使用 pgvector 运算符<=>,该运算符查找两个嵌入向量之间的余弦距离(也称为余弦相似度)。
# Helper function: Get top 3 most similar documents from the databasedef get_top3_similar_docs(query_embedding, conn):
embedding_array = np.array(query_embedding)
# Register pgvector extension
register_vector(conn)
cur = conn.cursor()
# Get the top 3 most similar documents using the KNN <=> operator
cur.execute("SELECT content FROM embeddings ORDER BY embedding <=> %s LIMIT 3", (embedding_array,))
top3_docs = cur.fetchall()
return top3_docs
3.3 定义辅助函数查询 OpenAI
我们提供辅助函数来为用户问题创建嵌入,并从 OpenAI 模型获取完成响应。我们使用 GPT-3.5,但您可以使用 GPT-4 或 OpenAI 的任何其他模型。
我们还指定了一些参数,例如模型响应中最大标记数的限制和模型温度,用于控制模型的随机性,您可以根据自己的喜好进行修改:
# Helper function: get text completion from OpenAI API
# Note we're using the latest gpt-3.5-turbo-0613 model
def get_completion_from_messages(messages, model="gpt-3.5-turbo-0613", temperature=0, max_tokens=1000):
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=temperature,
max_tokens=max_tokens,
)
return response.choices[0].message["content"]
# Helper function: get embeddings for a text
def get_embeddings(text):
response = openai.Embedding.create(
model="text-embedding-ada-002",
input = text.replace("\n"," ")
)
embedding = response['data'][0]['embedding']
return embedding
3.4 把它们放在一起
我们将定义一个函数来处理用户输入,方法是从数据库中检索最相似的文档,并将用户输入以及相关的检索上下文传递给 OpenAI 模型以提供完成响应。
请注意,我们还修改了系统提示,以影响模型响应的基调。
我们使用助手角色将与三个最相似的嵌入相关的内容传递给模型,以输入用户输入。您还可以将其他上下文附加到用户消息中。
# Function to process input with retrieval of most similar documents from the database
def process_input_with_retrieval(user_input):
delimiter = "```"
#Step 1: Get documents related to the user input from database
related_docs = get_top3_similar_docs(get_embeddings(user_input), conn)
# Step 2: Get completion from OpenAI API
# Set system message to help set appropriate tone and context for model
system_message = f"""
You are a friendly chatbot. \
You can answer questions about timescaledb, its features and its use cases. \
You respond in a concise, technically credible tone. \
"""
# Prepare messages to pass to model
# We use a delimiter to help the model understand the where the user_input starts and ends
messages = [
{"role": "system", "content": system_message},
{"role": "user", "content": f"{delimiter}{user_input}{delimiter}"},
{"role": "assistant", "content": f"Relevant Timescale case studies information: \n {related_docs[0][0]} \n {related_docs[1][0]} {related_docs[2][0]}"}
]
final_response = get_completion_from_messages(messages)
return final_response
让我们看一个模型输出到原始输入问题的示例:
input = "How is Timescale used in IoT?"
response = process_input_with_retrieval(input)print(input)print(response)
以下是模型的响应:
用户输入:如何在物联网中使用Timescale ?
模型响应:
TimescaleDB 通常用于 IoT(物联网)应用程序,用于存储和分析 IoT 设备生成的时间序列数据。随着时间推移,IoT 设备会生成大量数据,例如传感器读数、设备状态更新和警报信息。TimescaleDB 为存储和查询此时间序列数据提供了可扩展且高效的解决方案。
借助 TimescaleDB,IoT 应用程序可以从自动数据分区、压缩和保留策略等功能中受益。这些功能允许有效地存储和检索时间序列数据,即使数据量增长也是如此。TimescaleDB 还支持 SQL 查询,因此可以轻松地对时间序列数据执行复杂的分析和聚合。
在物联网应用中,TimescaleDB 可用于监控和分析各个方面,例如环境条件(温度、湿度)、能耗、设备性能和预测性维护。它支持实时监控、异常检测和趋势分析,帮助企业做出数据驱动的决策并优化运营。
总体而言,TimescaleDB 提供了一个可靠且可扩展的数据库解决方案,用于处理物联网设备生成的大量时间序列数据,使企业能够解锁有价值的见解并改进其物联网应用程序。
我们还可以向模型询问有关数据库中特定文档的问题,在本例中是关于在博客文章中谈到其体验的特定 Timescale 用户的问题:
input_2 = "Tell me about Edeva and Hopara. How do they use Timescale?"
response_2 = process_input_with_retrieval(input_2)
print(input_2)
print(response_2)
这是上述输入问题的模型输出;请注意它如何使用博客文章中的特定详细信息。
用户输入:请介绍一下 Edeva 和 Hopara。他们如何使用Timescale?
模型响应:
Edeva 和 Hopara 是两家利用 TimescaleDB 来满足其数据存储和可视化需求的公司。
Edeva 使用 TimescaleDB 作为其智慧城市系统中的主数据库。他们的客户可以控制他们的物联网设备并查看捕获的数据,从趋势和历史数据中获得洞察力。它们利用 TimescaleDB 的连续聚合功能来加快查询速度并提高仪表板性能。
另一方面,Hopara 提供了一个复杂的可视化系统,允许用户从各种类型的数据中获得见解。他们使用 TimescaleDB 来存储来自带有传感器标记的机器的实时振动数据。Hopara 的可视化系统由 TimescaleDB 提供支持,使用户能够深入研究数据并识别振动问题。
Edeva 和 Hopara 都受益于 TimescaleDB 的时间序列功能及其高效处理大量数据的能力。
结论
检索增强生成 (RAG) 是一种使用 LLM 构建应用程序的强大方法,使您能够向基础模型传授最初未训练的内容,例如私有文档或最近发布的信息。
我们现在已经了解了创建聊天机器人来回答有关博客的问题的基础知识。这个项目是如何在 OpenAI 嵌入上创建、存储和执行相似性搜索的一个示例。 我们使用 PostgreSQL 和 pgvector 作为我们的向量数据库来存储和查询嵌入。如果您正在为向量工作负载寻找生产 PostgreSQL 数据库,请尝试 Timescale。免费 30 天,无需信用卡。
Jupyter 笔记本和代码:您可以在 Jupyter Notebook 中找到本教程中使用的所有代码,以及 Timescale GitHub 上的示例内容和嵌入:timescale/vector-cookbook。
链接地址:
https://github.com/timescale/vector-cookbook/tree/main/openai_pgvector_helloworld?ref=timescale.com


