






「关注」并「星标」我们,
每天接收关于亚马逊云科技的最新资讯!
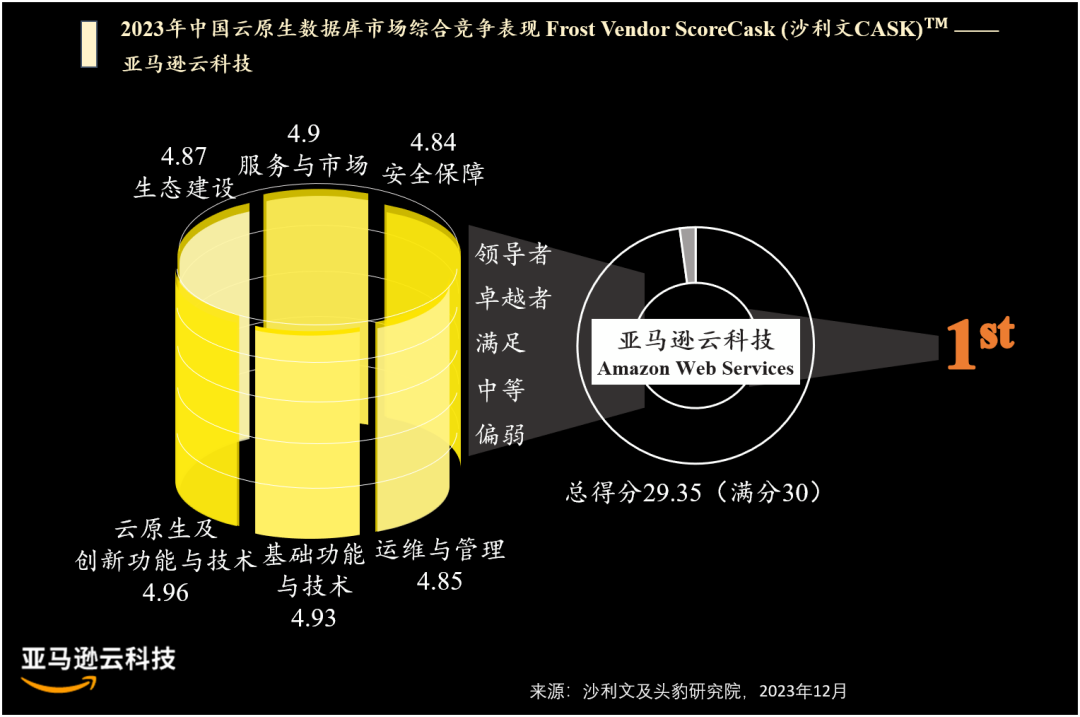
近日,沙利文发布《2023 年中国云原生数据库十大厂商推荐》报告,亚马逊云科技在六项指标中均处于领先地位,综合评分排名第一,被评为 2023 年中国云原生数据库领导者。
该报告是沙利文关于中国数据库市场的系列报告之一,旨在梳理云原生数据库解决方案技术动态,洞察市场核心诉求,并结合市场发展前景判断云原生数据库领域内各类竞争者所处地位。

沙利文从云原生及创新功能与技术、基础功能及技术、运维与管理、安全保障、服务与市场、生态建设六大维度对竞争主体表现分别进行评价。报告指出:

亚马逊云科技将数据库研发能力与云计算基础能力深度结合,打造出多款云原生数据库,在云资源利用率及使用效果方面皆达到市场领先水平。公司不断引领数据库创新,先后推出了多项数据库的 Serverless 功能、实现了多项数据服务之间的 Zero-ETL 集成能力,并为多款数据库新增了向量检索功能,加速生成式 AI 应用的创新。
扫描下方二维码下载报告全文

重塑生成式 AI 时代的数据基础设施
作为数据的核心基础设施之一,数据库是最早一批经历从搬迁上云(lift)到全面托管服务(shift)的云上开发组件。借助云基础设施的超大规模,数据库具备了远超单机限制的性能、容量、安全可靠性及容灾能力。
在此基础上,随着云原生浪潮的兴起,对云上开发体验而言,易用性、开发速度及用云成本等因素变得越来越重要,因此数据库架构也开始全面走向云原生,更加关注极简的上手使用体验、提供无服务器化(Serverless)的免运维能力,通过自动化扩缩容实现使用成本的大幅优化,以及通过无缝集成降低数据搬迁成本。
亚马逊云科技作为全球云计算引领者,早在 2012 年即推出了基于云原生架构的数据库 Amazon DynamoDB,通过无服务器化的使用体验,为用户提供高吞吐、低延迟并可扩展至任意规模的数据存储服务。而于 2018 年,亚马逊云科技推出了 Amazon Aurora Serverless v1,率先实现了关系型数据库 RDS 的无服务器化,并于 2022 年推出升级版本 Amazon Aurora Serveless v2。同年,亚马逊云科技推出 Zero-ETL 愿景,开始推动多个数据库平台的无缝集成。
在 2023 年 re:Invent 上,亚马逊云科技持续投入数据库家族的全线云原生化,在无服务器与 Zero-ETL 方向上推出多项新品。同时,在生成式 AI 爆发式成长的背景下,亚马逊云科技以向量嵌入为主轴,为全线数据库整合向量数据搜索能力,在 Database for AI 层面迈出坚实一步。
全面支持无服务器模式,
以更敏捷超越性能边界
全新发布
Amazon Aurora Limitless Database
Amazon Aurora 提供完全兼容 PostgreSQL 及 MySQL 的关系型数据库,并在此基础上进行了大量创新,有效提升 I/O 效率,并可便捷地按需进行节点的自动扩展。在此基础上,为进一步加强 Aurora 的无服务器扩展能力,亚马逊云科技全新发布 Amazon Aurora Limitless Database(Aurora Limitless),可将 Aurora 集群的写入能力无缝扩展至每秒百万次写入事务,管理 PB 级数据,同时支持数据强一致性。Aurora Limitless 将以单一的无服务器端点面向用户提供服务,帮助用户完全无感地进行数据库的按需扩展或收缩,用户无需更改应用逻辑以及维护复杂的数据库分片节点。

全新发布
Amazon ElastiCache Serverless
Amazon ElastiCache 提供完全兼容 Redis 及 Memcached 的高性能托管缓存服务。在部署 ElastiCache 时,开发者首先需要选择实例规格来确定缓存大小,同时缓存的规模直接受限于物理服务器限制。但面对不确定的负载波动,寻找完美的缓存大小实际上难以实现。缓存过小,数据会被频繁挤出,无法发挥作用;而缓存过大,则会造成不必要的成本浪费。
因此,通常情况下开发者会选择按照峰值配置缓存大小,这也意味着大部分的缓存将被浪费。而在无服务器部署模式下,应对这一情况将变得非常简单。亚马逊云科技全新发布了 Amazon ElastiCache Serverless,在不必选择缓存节点大小、类型、分片数量、副本数量等配置的情况下,帮助用户在一分钟内创建高度可用且可扩展的缓存服务,且内存规模最高可达 5TB。

亚马逊云科技目前已经推出全面覆盖用户需求的无服务器数据库系列,包括:关系数据库服务 Amazon Aurora Serverless 与 Aurora Limitless Database,完全托管的 PB 级云数据仓库服务 Amazon Redshift,支持键-值存储和文档型数据结构的 NoSQL 数据库服务 Amazon DynamoDB,缓存数据库 Amazon ElastiCache Serverless,开源的宽列数据存储 Amazon Keyspaces,时许数据库 Amazon Timestream,完全托管的图形数据库服务 Amazon Neptune 以及完全托管的分类账数据库 Amazon Quantum Ledger Database (QLDB) 等。

全线整合向量化能力,
加速生成式 AI 应用创新
向量化检索是对数据进行向量化处理,并通过向量相似度算法进行数据检索的技术。它可用于基于语义的信息检索,因此也被广泛应用于生成式 AI 场景中,作为大模型的有效补充,例如利用某些领域知识进行的检索增强生成(RAG)。
大多数情况下,将向量与数据库数据进行统一存储,是面向生成式 AI 时代理想的数据策略。用户不用因为引入新的专用平台,而产生额外的数据库许可及管理投入,无需调整适配现有的应用, 也可以减少数据同步和数据移动,同时在关联数据时也将获得更快的体验。
亚马逊云科技在 2023 年持续推进将向量化检索能力嵌入全线数据库服务中。目前 Amazon Aurora、 Amazon RDS、 Amazon OpenSearch Service、Amazon OpenSearch Serverless、Amazon DocumentDB 、Amazon MemoryDB for Redis、Amazon Neptune 已经正式提供向量化能力,可以直接在这些服务中存储并处理向量数据;Amazon DynamoDB 可以通过与 OpenSearch 的 Zero-ETL 集成来获得向量检索功能。

持续推动无缝集成,
实现全面 Zero-ETL
Amazon Redshift 与 Amazon Aurora PostgreSQL、Amazon DynamoDB、以及 Amazon RDS for MySQL 实现完全托管的 Zero-ETL 集成。与稍早发布的 Aurora MySQL 集成一起,目前主要承载事务数据的关系型与非关系型数据库,均已实现与 Amazon Redshift 数仓平台的 Zero-ETL 集成,用户可以通过 Redshift 更轻松地连接和关联这些分布在不同数据库内的事务数据,并提供近乎实时的数据分析,以加速数据决策。
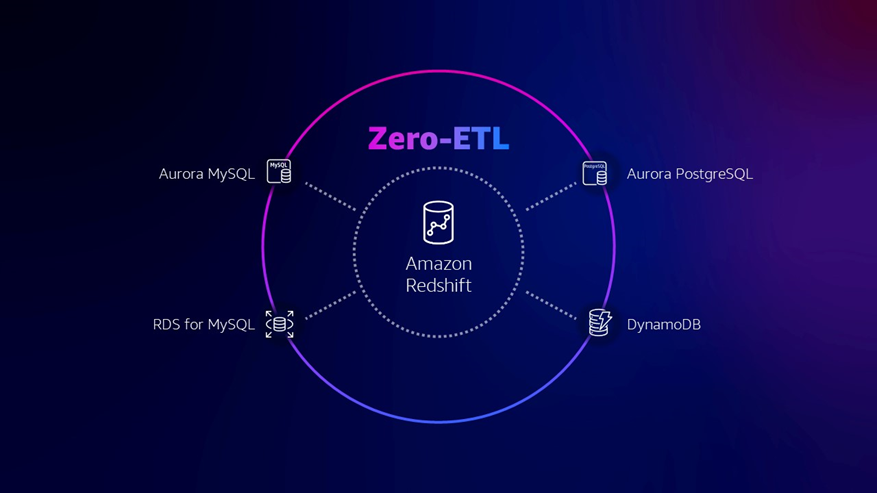
Amazon DynamoDB 与 Amazon OpenSearch Service 实现 Zero-ETL 集成 ,用户可以使用 Amazon OpenSearch 对 Amazon DynamoDB 数据近乎实时地执行全文或向量搜索。DynamoDB 是广受欢迎的文档数据库,大量用户依靠 DynamoDB 来承载他们的核心业务数据,例如电商用户会把产品明细信息存放在 DynamoDB 中。而 OpenSearch 是高效的数据搜索引擎,两者进行 Zero-ETL 集成后,DynamoDB 中的产品信息进行更新后,数据可自动更新至 OpenSearch 中,用户可以在 OpenSearch 中搜索到最新的产品信息,而这一过程基本实时完成,将极大提升业务的运营效率。












马上点击“阅读原文”
查看更多分析师报告
让我们共同见证亚马逊的一小步
云计算的一大步

