




前言
今晚在我吭哧吭哧学GO写GO的时候,一位学员在群里问了这样一个问题,案例虽小,但是十分值得分享~
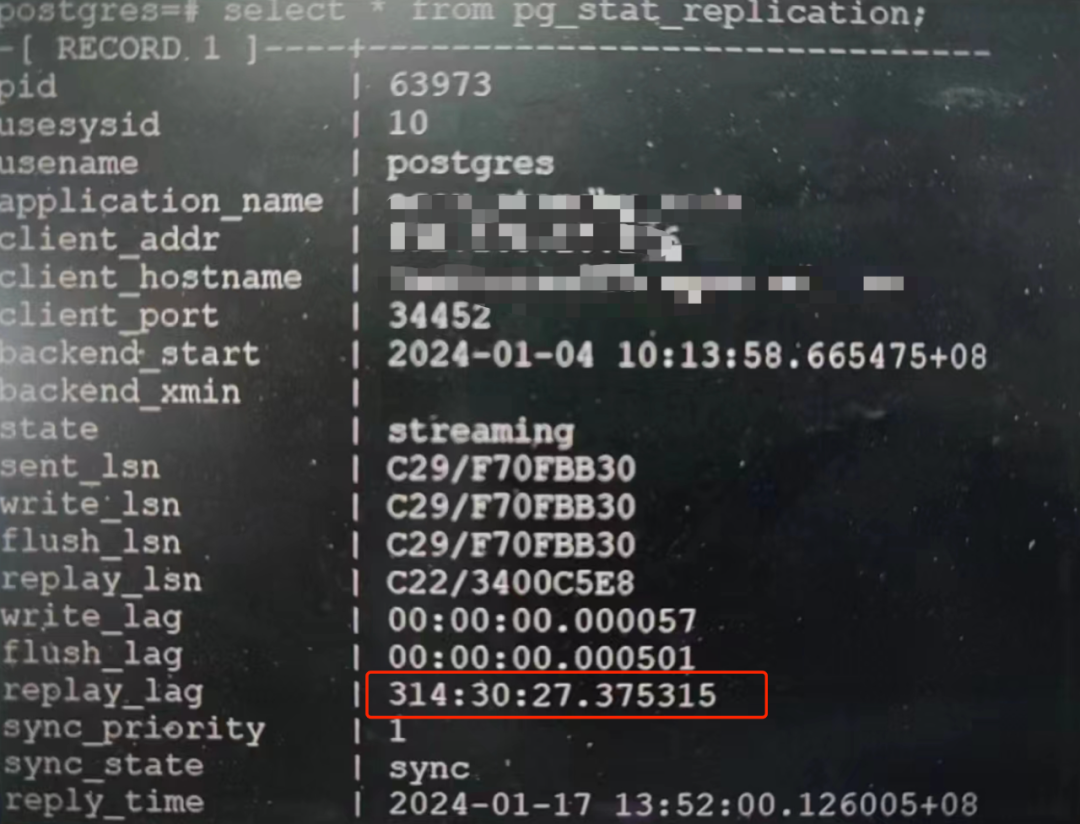
可以看到,复制延迟达到了夸张的 314 小时!
分析
按照常规思路,一开始以为是遇到了recovery conflict,那么典型现象便是备库的 startup 进程会处于 waiting 的状态,比如
postgres: startup process recovering 0000000100000000000000A6 waiting
但是排查了一下并不是这样,难道又是流复制断了?典型现象便是备库日志中提示 WAL has been removed,但是转念一想,断了的话,pg_stat_replication 中压根就不会有相关条目,说明也不是这个问题。
于是继续看了一下 startup 进程的状态,发现其等待事件是 RecoveryPause

官网上的解释是:等待 recovery 继续,貌似说了点什么,暂时不太清楚这个等待事件做什么的。
Waiting for recovery to be resumed.
难道是遇到了和我之前碰到的由于网络故障导致的罕见案例?👉🏻 一则不同寻常的复制冲突案例,于是用 pg_waldump dump了一下当前正在回放的 WAL,但是也能正常解析,没有报错,说明也不太一样。
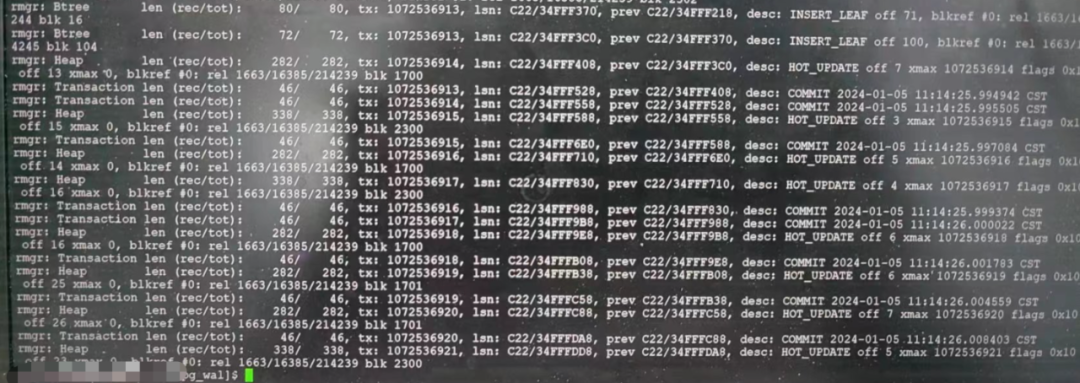
至此常规分析思路陷入了死胡同。那让我们从代码里找找端倪,先根据等待事件找找——RecoveryPause
/*
* pg_wal_replay_pause - Request to pause recovery
*
* Permission checking for this function is managed through the normal
* GRANT system.
*/
Datum
pg_wal_replay_pause(PG_FUNCTION_ARGS)
{
if (!RecoveryInProgress())
ereport(ERROR,
(errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
errmsg("recovery is not in progress"),
errhint("Recovery control functions can only be executed during recovery.")));
if (PromoteIsTriggered())
ereport(ERROR,
(errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
errmsg("standby promotion is ongoing"),
errhint("%s cannot be executed after promotion is triggered.",
"pg_wal_replay_pause()")));
SetRecoveryPause(true);
/* wake up the recovery process so that it can process the pause request */
WakeupRecovery();
PG_RETURN_VOID();
}
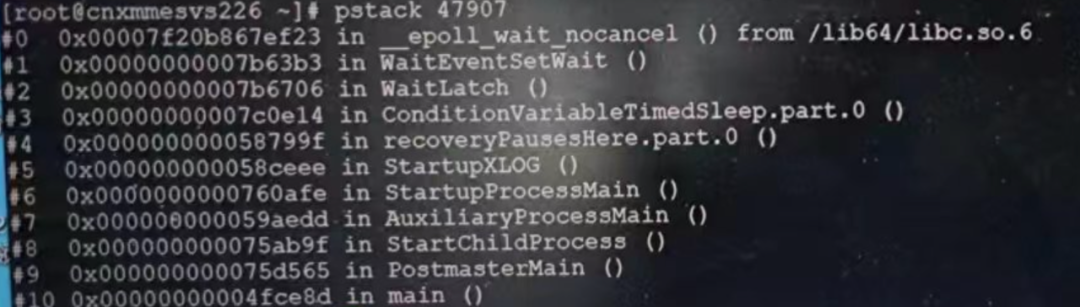
立马就找到了相关线索,pg_wal_replay_pause,顾名思义,暂停恢复!并且 startup 进程的堆栈也十分明显,进入到了 recoveryPausesHere。
pg_wal_replay_pause() issues a request to PostgreSQL to pause replay; once successful, no further changes are applied. Execute pg_wal_replay_resume() to resume WAL replay.
Note that although pg_wal_replay_pause() returns immediately, there may be a delay before WAL replay is actually paused. The point at which reply was paused is noted in the PostgreSQL logfile with an entry like:
代码很清晰,相当于人为操作使其暂停,另外一个场景就是 PITR,如果恢复到了指定点位,如果没有配置为自动 promote (recovery_target_action,默认是 pause,需要执行 pg_wal_replay_resume 才能变得可写,为什么默认是 pause,之前也讲过原理,此处不在赘述),也会自动暂停,只能读取无法写入。
/*
* Wait until shared recoveryPauseState is set to RECOVERY_NOT_PAUSED.
*
* endOfRecovery is true if the recovery target is reached and
* the paused state starts at the end of recovery because of
* recovery_target_action=pause, and false otherwise.
*/
static void
recoveryPausesHere(bool endOfRecovery)
{
/* Don't pause unless users can connect! */
if (!LocalHotStandbyActive)
return;
/* Don't pause after standby promotion has been triggered */
if (LocalPromoteIsTriggered)
return;
if (endOfRecovery)
ereport(LOG,
(errmsg("pausing at the end of recovery"),
errhint("Execute pg_wal_replay_resume() to promote.")));
else
ereport(LOG,
(errmsg("recovery has paused"),
errhint("Execute pg_wal_replay_resume() to continue.")));
...
...
复现
现在让我们复现一下,正常搭建一个集群
postgres=# select * from pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 32687
usesysid | 10
usename | postgres
application_name | walreceiver
client_addr |
client_hostname |
client_port | -1
backend_start | 2024-01-17 23:34:47.43299+08
backend_xmin |
state | streaming
sent_lsn | 0/2201A410
write_lsn | 0/2201A410
flush_lsn | 0/2201A410
replay_lsn | 0/2201A410
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | async
reply_time | 2024-01-17 23:35:07.449149+08
按照代码中注释,如果手动调用 pg_wal_replay_pause() 的话,会在日志中打印一条日志:
[postgres@xiongcc 16data_bak]$ psql -p 5433
psql (16.1)
Type "help" for help.
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
postgres=# select pg_wal_replay_pause();
pg_wal_replay_pause
---------------------
(1 row)
2024-01-17 23:37:23.819 CST,,,32685,,65a7f397.7fad,6,,2024-01-17 23:34:47 CST,1/0,0,LOG,00000,"recovery has paused",,"Execute pg_wal_replay_resume() to continue.",,,,,,,"","startup",,0 ---相关日志
确实如此,此时这个备库就"延迟"了,在这个点位卡住了
postgres=# create table test_syn(id int);
CREATE TABLE
postgres=# insert into test_syn values(1);
INSERT 0 1
主库上新建的表,在备库上是看不到的
[postgres@xiongcc log]$ psql -p 5433 -c "select * from test_syn"
ERROR: relation "test_syn" does not exist
LINE 1: select * from test_syn
只有当我们人为执行 pg_wal_replay_resume 使其继续恢复才行.
postgres=# select pg_is_wal_replay_paused();
pg_is_wal_replay_paused
-------------------------
t
(1 row)
postgres=# select pg_wal_replay_resume();
pg_wal_replay_resume
----------------------
(1 row)
postgres=# \d test_syn
Table "public.test_syn"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | |
思考
至此这个案例算是分析清楚了,那么不妨让我们发散一下,如果人为暂停了恢复,比如暂停了 5 小时,主库会为这个备库保留相关 WAL 吗?还是说会有其他行为?
简单验证一下,主库不断插入,同时不断执行 checkpoint 回收 WAL
postgres=# insert into test_syn values(generate_series(1,1000));\watch 0.01
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
现在延迟便会越来越大,不过值得注意的是,备库还是会不断回传心跳,返回 ACK,再次温顾一下流复制原理:
后端进程通过执行XLogInsert和XLogFlush函数,将WAL数据写入并刷新到WAL段文件中。 walsender进程将写入WAL段的WAL数据发送给walreceiver进程。 发送WAL数据后,后端进程继续等待备用服务器的ACK响应。更准确地说,后端进程通过执行内部函数SyncRepWaitForLSN获得一个latch,并等待它被释放。 备用服务器上的walreceiver将接收到的WAL数据写入备用的WAL段中,使用write系统调用,并向walsender返回一个ACK响应。 walreceiver使用如fsync等系统调用将WAL数据刷新到WAL段,向walsender返回另一个ACK响应,并通知启动进程关于WAL数据的更新。 startup进程回放已写入WAL段的WAL数据。 当walsender收到来自walreceiver的ACK响应时,释放后端进程的 latch,然后后端进程的提交或中止操作将完成。latch释放的时机取决于参数synchronous_commit。如果设为on (默认值),当收到步骤(5)的ACK时释放latch;如果设为remote_write,则在收到步骤(4)的ACK时释放latch。
postgres=# select write_lag,write_lag,flush_lag,sync_state,reply_time from pg_stat_replication;
-[ RECORD 1 ]-----------------------------
write_lag | 00:00:00.000192
write_lag | 00:00:00.000192
flush_lag | 00:00:00.002586
sync_state | async
reply_time | 2024-01-17 23:44:50.987609+08
postgres=# select write_lag,write_lag,flush_lag,sync_state,reply_time from pg_stat_replication;
-[ RECORD 1 ]-----------------------------
write_lag | 00:00:00.000203
write_lag | 00:00:00.000203
flush_lag | 00:00:00.000942
sync_state | async
reply_time | 2024-01-17 23:44:56.987491+08 ---ACK更新了
可以看到,PostgreSQL 的行为是:
主库上正常执行其逻辑,产生 WAL,发给备库 备库正常接收 WAL,但是不会继续回放
因此不难想到,假如暂停地越久,备库就有可能将磁盘撑爆!
If streaming replication is disabled, the paused state may continue indefinitely without a problem. If streaming replication is in progress then WAL records will continue to be received, which will eventually fill available disk space, depending upon the duration of the pause, the rate of WAL generation and available disk space.
如果禁用流复制,暂停状态可能会无限期地持续下去,不会出现问题。如果流复制正在进行中,则将继续接收 WAL 记录,这最终将填满可用磁盘空间,具体取决于暂停的持续时间、WAL 生成速率和可用磁盘空间。
[postgres@xiongcc ~]$ ll 16data_bak/pg_wal/ | wc -l ---备库
65
[postgres@xiongcc ~]$ ll 16data/pg_wal/ | wc -l ---主库
7
当暂停恢复之后,可以看到,备库在全速追赶中... 直至复制追平。
postgres=# select pg_wal_replay_resume();
pg_wal_replay_resume
----------------------
(1 row)
postgres=# select pg_get_wal_replay_pause_state();
pg_get_wal_replay_pause_state
-------------------------------
not paused
(1 row)
postgres=# select count(*) from test_syn ;
count
---------
5473001
(1 row)
postgres=# select count(*) from test_syn ;
count
---------
7546001
(1 row)
postgres=# select count(*) from test_syn ;
count
----------
16146001
(1 row)
小结
真是一个有趣的复制延迟案例!那么这个函数用在什么场景呢?官网上也有介绍
and no further query conflicts will be generated until recovery is resumed.
在恢复恢复之前不会生成进一步的查询冲突。
主要还是为了解决 recovery conflict 的问题。
参考
https://www.postgresql.org/docs/current/functions-admin.html
https://pgpedia.info/p/pg_wal_replay_pause.h
