




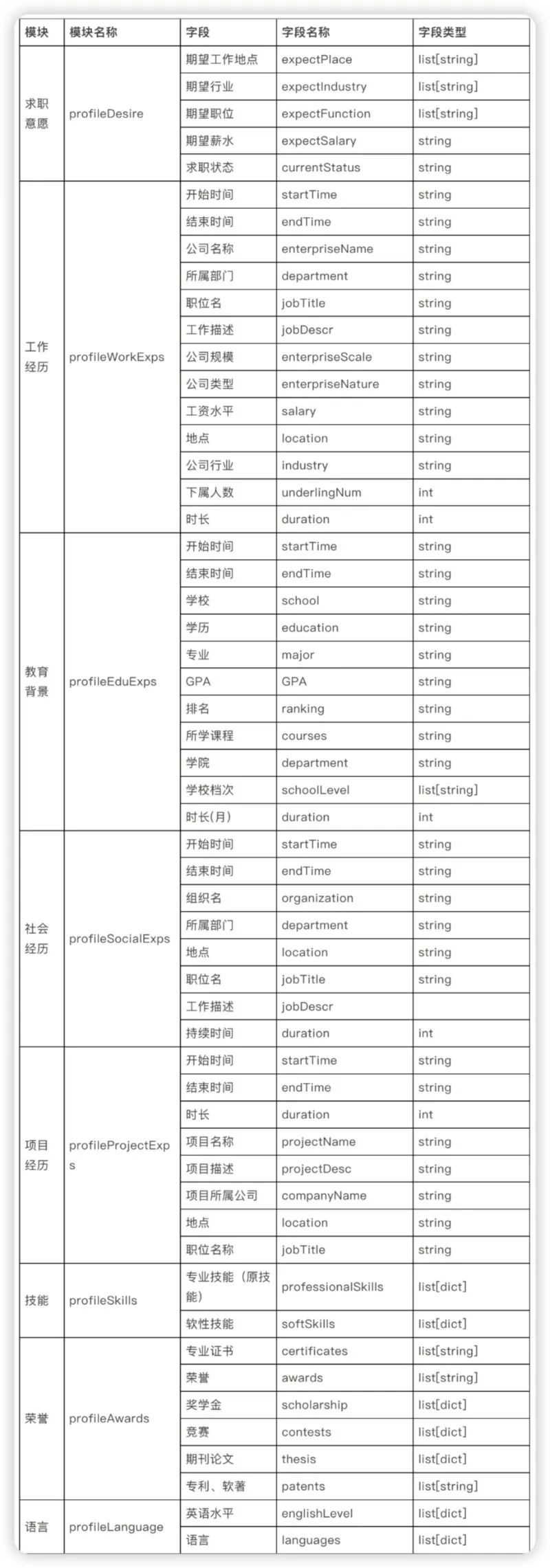
赛题名称:人岗匹配挑战赛2023 赛题类型:文本匹配 赛题任务:基于提供的样本构建模型,预测简历与岗位匹配与否。
比赛地址:https://challenge.xfyun.cn/topic/info?type=person-post-matching-2023
视频答辩地址:https://www.bilibili.com/video/BV1nb4y1T7kr?p=47
赛题背景
讯飞智聘是一款面向企业招聘全流程的智能化解决方案。运用科大讯飞先进的智能语音、自然语言理解、计算机视觉等AI技术及大数据能力,具备业界领先的简历解析、人岗匹配、AI面试、AI外呼等产品功能,助力企业提升招聘效率,降低招聘成本。
人岗匹配是企业招聘面临一个重大挑战,尤其在校园招聘等集中招聘的场景下,面对海量的简历,如何快速分类筛选出最适合招聘岗位的简历,以及在内推和猎头场景下,如何为一份简历找到合适的岗位,做到人适其岗、岗适其人,提升人岗匹配的效率和准确度,是困扰每一个HR和面试官的难题。
赛题任务
智能人岗匹配需要强大的数据作为支撑,本次大赛提供了大量的岗位JD和求职者简历的加密脱敏数据作为训练样本,参赛选手需基于提供的样本构建模型,预测简历与岗位匹配与否。
赛题数据
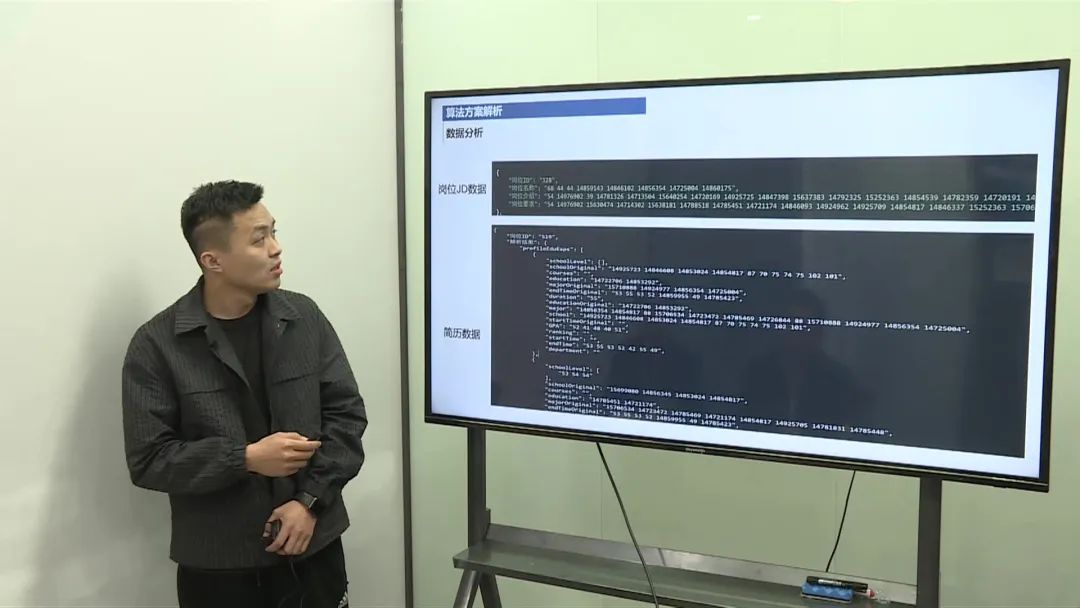
岗位JD数据包含4个特征字段:岗位ID, 岗位名称, 岗位介绍, 岗位要求
评价指标
本模型依据提交的结果文件,采用macro-F1 score进行评价。
本赛题提供训练集下载数据,选手在本地进行算法调试,在比赛页面提交模型进行在线推理。
优胜方案
第一名

数据预处理
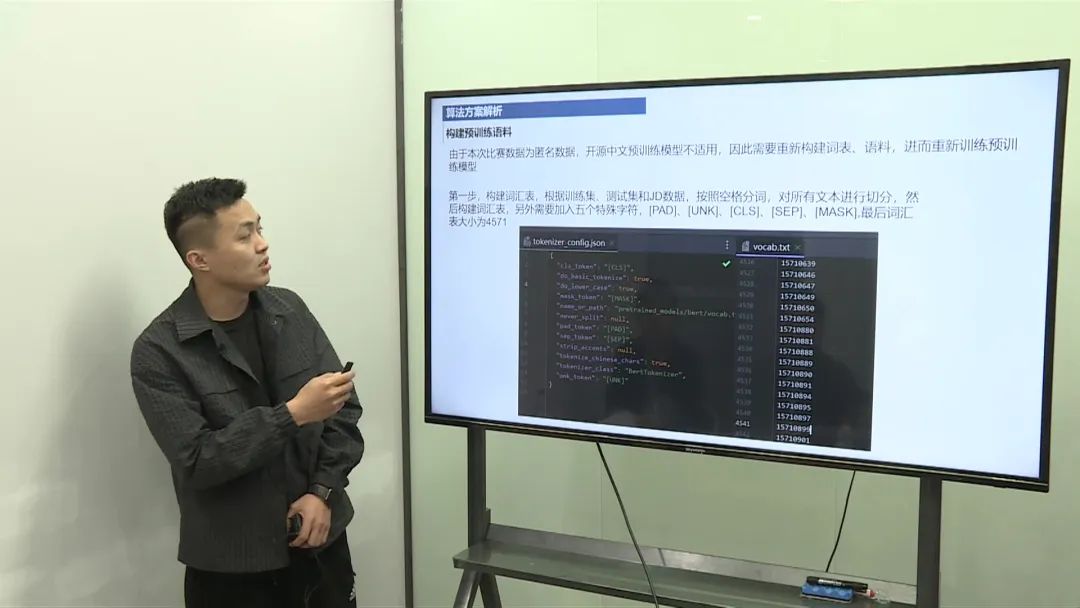
数据拼接:将求职者简历中的不同字段(如教育背景、工作经历等)拼接成一条长文本,岗位JD也同样处理。 匿名化处理:由于数据是匿名化的,构建了一个专门的词表,从零开始进行预训练。
特征工程
文本表示:使用了基于Transformer的预训练模型(如BERT或Nezha),考虑到数据长度和模型复杂度,选择了8层的结构。 注意力机制:在预训练模型输出的隐层表示上,添加了注意力机制或RNN等结构来进一步提升特征表示。

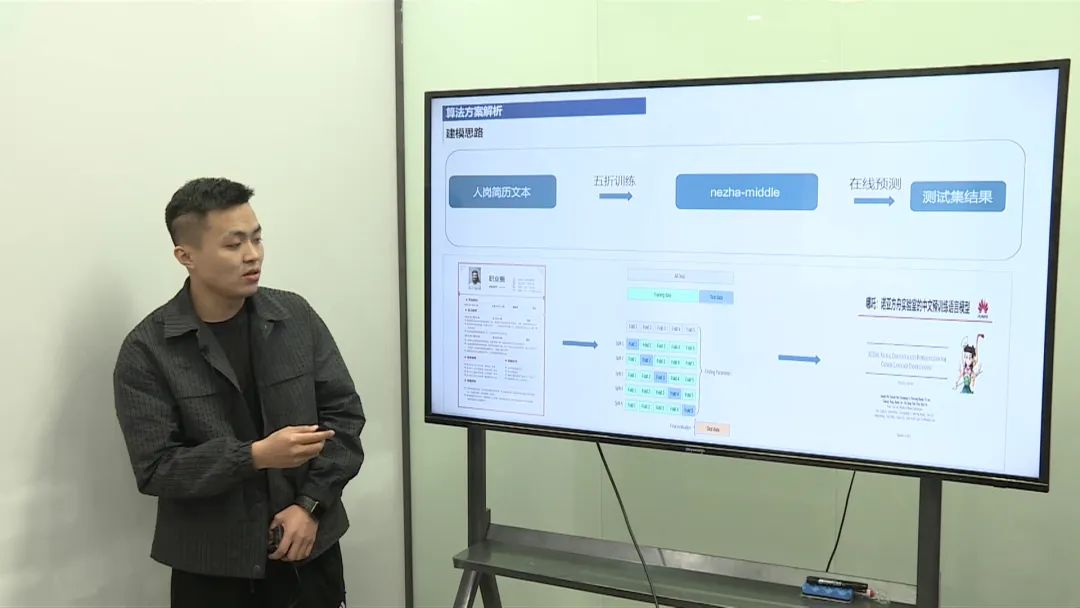
模型架构
分类器设计:在预训练模型的基础上,融合了不同层的表示,并进行了Self-attention加权的特征融合。 层数调整:根据比赛数据特点,调整了模型层数和维度,以优化性能。
模型训练
损失函数:使用了Focal Loss来解决类别不均衡问题,提高模型对少数类的识别能力。 优化策略:应用了如对抗训练(FGM)和指数移动平均(EMA)等策略来避免过拟合。
模型评估
交叉验证:采用了5折交叉验证,确保模型的泛化能力。 评估指标:主要关注Macro F1分数,以评估分类的准确率。
结果分析
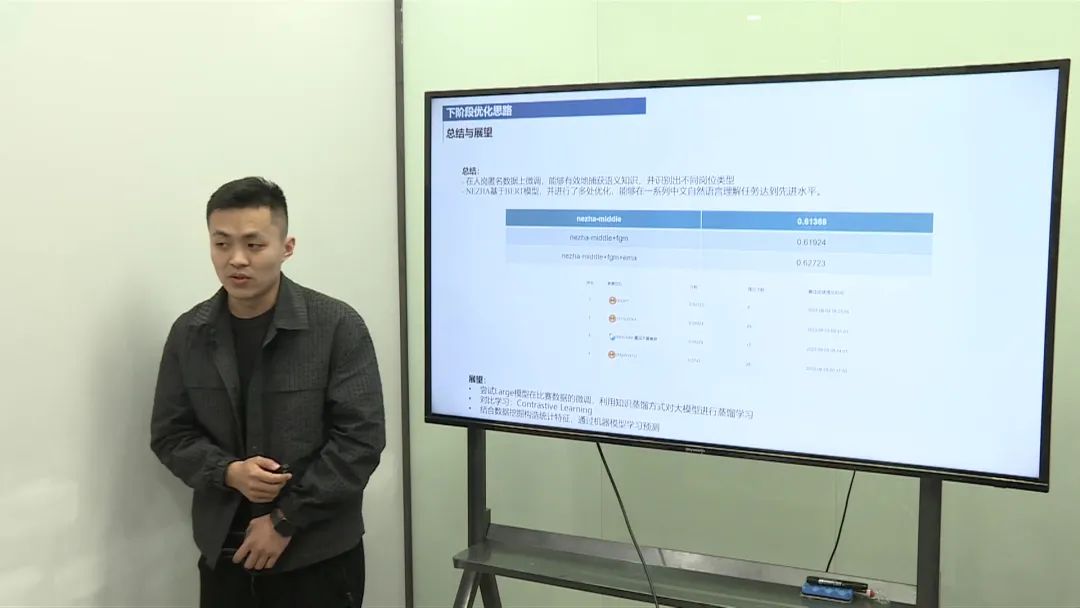
线上推理:通过分层采样,进行线上推理,最终取得了0.62的分数,并在比赛中取得了第一位。 效果提升:通过Focal Loss和其他优化策略,模型效果从0.60提升至0.627。
第二名
方案采用了传统的机器学习方法,通过分模块建模、特征提取和模型融合,实现了对人岗匹配的预测。在优化过程中,通过调整权重和多类F1值优化,提高了模型性能。虽然特征工程方面较为简单,但整体方案在比赛中取得了较好的成绩。

数据预处理
数据划分:将数据分为不同的模块,如教育经历、求职需求、工作经历等。 特征提取:对每个模块进行TF-IDF特征提取,得到文本特征。
模型构建
LGB模型:对每个模块分别进行LGB学习器的训练,得到预测结果。 XGB模型:将LGB模型的预测结果作为输入,进行XGB模型的训练。 模型融合:将XGB模型的预测结果与LGB模型的预测结果进行融合,得到最终的预测值。
模型优化
类别不均衡问题:通过调整权重,优化F1值,解决类别不均衡问题。 多类F1值优化:对每个权重进行优化,实现多类F1值的优化。

特征工程
个人信息与职位相似度:计算个人信息与每个职位之间的相似度,作为特征。 统计特征:提取一些简单的统计特征,如教育经历的段数等。
模型评估
基准模型:最初使用基准模型,得分约为0.50。 统计特征加入:加入统计特征后,得分提升至0.53。 分维度建模:将数据分为多个模块进行建模,得分提升至0.58。 F1优化:进行F1优化后,得分略有提升。
第三名
方案采用了数据增强、模型集成和分层结构等方法,以提高人工匹配器的性能。虽然特征工程方面较为简单,但整体方案在比赛中取得了较好的成绩。
数据预处理
数据读取:直接读取每条求职者简历样本的纯文本。 数据清洗:删除无意义的符号,如无文字的数字序号。
数据增强
岗位信息伪装:将岗位信息伪装成求职者简历,以增强数据。 排列组合:对岗位名称、岗位介绍和岗位要求进行多种排列组合,生成新的样本。 去重:去除重复的文本ids,保留每个ids的一个,以增加样本多样性。

特征工程
文本特征提取:使用1-3 Gram的N-Gram模型提取文本特征。 简单特征:提取一些简单的特征,如词频等。

模型构建
模型集成:采用模型集成的方法,使用7种不同的模型类型。 基础模型训练:根据设置的参数,得到12个基础模型。 模型集成策略:将训练集拆分成5份,每个模型训练一份,得到60个模型。 特征拼接:将60个模型对测试集的预测值与文本特征拼接,作为新的特征。 模型分层:采用三层模型结构,每层重复上述操作,最后进行模型选择。


模型优化思路
数据增强:尝试更多的排列组合,以增强数据。 任务转换:将文本分类任务转换为文本匹配任务,加入更多招聘者信息。 特征工程:尝试使用更多特征提取方法,如FastText、Glove、WordVector等。 模型训练:尝试使用BERT等预训练模型进行训练。 模型融合:将不同模型的预测概率进行融合,如平均、加权和等。 对比学习:尝试使用对比学习方法,如SIMCSE等。 模型优化:尝试使用模型优化技巧,如模型蒸馏等。



文章转载自Coggle数据科学,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
