




前面两篇文章讨论了数据库聊天机器人的搭建
今天分享一篇相关的论文
原文:https://vanna.ai/blog/ai-sql-accuracy.html
翻译:ChatGPT
TLDR
拥有一个能够回答业务用户普通英语(自然语言)问题的自主 AI 代理的承诺是一个吸引人但至今难以实现的主张。许多人尝试过,但 ChatGPT 很难取得成功,主要原因是 LLM 对被要求查询的特定数据集的了解不足。
在这篇论文中,我们表明上下文至关重要,通过正确的上下文,我们可以从大约 3%的准确率提高到大约 80%的准确率。我们通过三种不同的上下文策略,并展示了其中一种是明显的赢家——我们将模式定义、文档和先前的 SQL 查询与相关搜索相结合。
我们还比较了几种不同的 LLMs,包括 Google Bison、GPT 3.5、GPT 4 以及对 Llama 2 的简短尝试。尽管GPT 4 获得了生成 SQL 的最佳整体 LLM 的桂冠,但在提供足够上下文的情况下,Google 的 Bison 大致相当。
最后,我们展示了如何使用这里演示的方法为您的数据库生成 SQL。
以下是我们主要发现的摘要,

目录
为什么使用 AI 生成 SQL? 设置测试的架构 设置测试杠杆 选择数据集 选择问题 选择提示 选择 LLMs(基础模型) 选择上下文 使用 ChatGPT 生成 SQL 仅使用模式 使用 SQL 示例 使用上下文相关的示例 分析结果 提高准确性的下一步 使用 AI 为您的数据集编写 SQL
为什么使用 AI 生成 SQL?
许多组织现在已经采用了某种数据仓库或数据湖——一个存储了组织关键数据的可查询的存储库,用于分析目的。这些数据的海洋充满了潜在的见解,但在企业中只有很小一部分人具备利用数据所需的两种技能:
对高级 SQL的扎实理解,以及 对组织独特的数据结构和模式的全面了解
具有上述两种技能的人数不仅是极其有限的,而且很可能并非拥有大多数问题的人。
那么组织内到底发生了什么?业务用户,如产品经理、销售经理和高管,有关于数据的问题,这些问题将为业务决策和战略提供信息。他们首先会查看仪表盘,但大多数问题都是临时的和具体的,答案不可用,因此他们会询问数据分析师或工程师——拥有上述两项技能的人。这些人很忙,需要一段时间来回应请求,并且一旦他们得到答案,业务用户就会有后续问题。
这个过程对于业务用户(获得答案的时间较长)和分析师(分散了他们主要的项目)来说是痛苦的,并导致许多潜在的见解丧失。
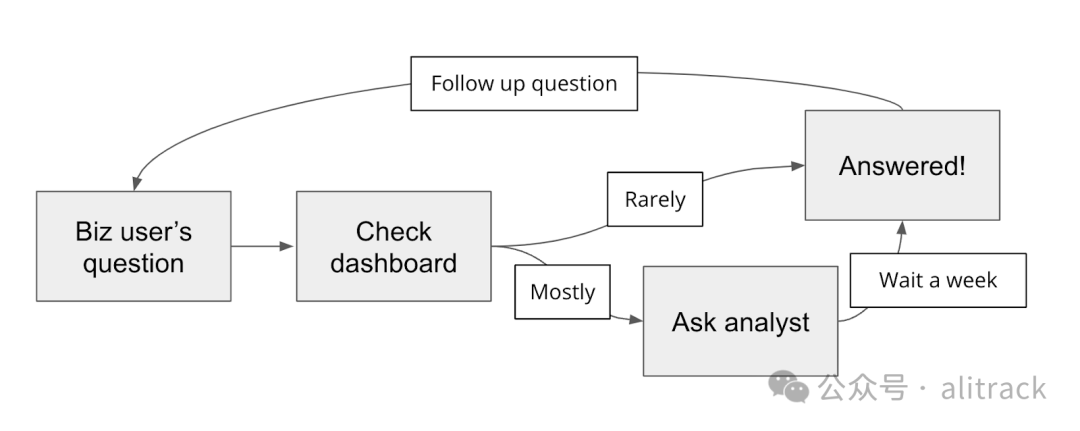
进入生成式 AI! LLMs 可能为业务用户提供在普通英语(自然语言)中查询数据库的机会(LLMs 执行 SQL 转换),我们从数十家公司那里听说,这对于他们的数据团队甚至对于他们的业务来说都将是一场改变游戏的事情。
关键挑战是为复杂而混乱的数据库生成准确的 SQL。我们与许多人交谈过,他们尝试使用 ChatGPT 编写 SQL,但成功有限且非常痛苦。许多人已经放弃并回到了手动编写 SQL 的老方法。在最好的情况下,ChatGPT 对于分析师来说是一个有时有用的 co-pilot,用于确保语法正确。
但是有希望!我们过去几个月一直致力于解决这个问题,尝试各种模型、技术和方法来提高 LLMs 生成的 SQL 的准确性。在这篇论文中,我们展示了各种 LLMs 的性能以及向 LLM 提供上下文相关正确 SQL 的策略如何使 LLM 能够实现极高的准确性。
设置测试的架构
首先,我们需要定义测试的架构。以下是一个大致的概述,包含五个步骤的流程,其中包含伪代码:
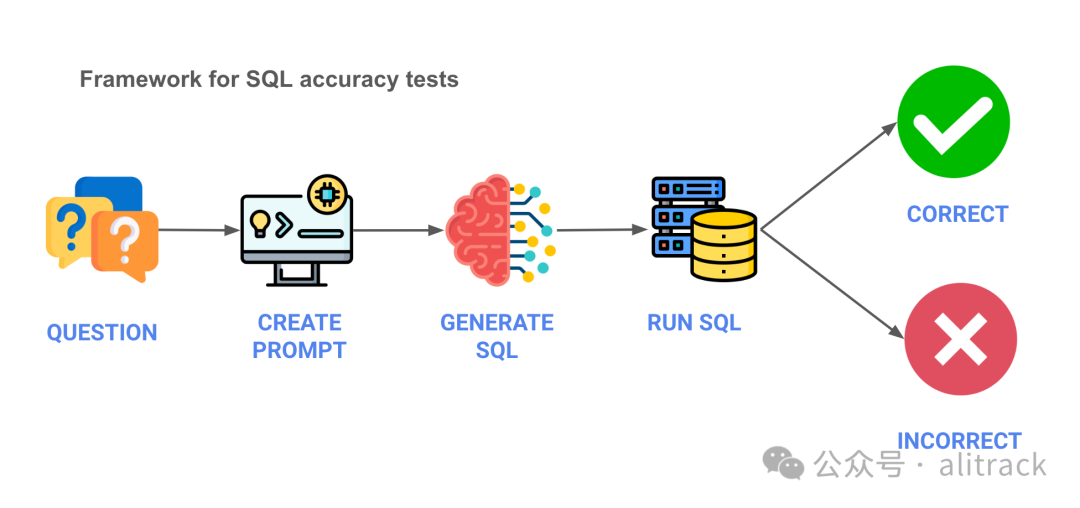
问题 - 我们从业务问题开始。
question = "德国有多少客户"
提示 - 我们创建要发送给 LLM 的提示。
prompt = f""" 为以下问题编写SQL语句:{question} """
生成 SQL - 使用 API,我们将提示发送给 LLM 并获取生成的 SQL。
sql = llm.api(api_key=api_key, prompt=prompt, parameters=parameters)
运行 SQL - 我们将 SQL 运行在数据库上。
df = db.conn.execute(sql)
验证结果 - 最后,我们验证结果是否符合预期。由于结果在某些情况下存在一些灰色区域,我们对结果进行了手动评估。您可以在这里[1]查看这些结果。
设置测试的杠杆
现在我们已经设置了实验,我们需要弄清楚哪些杠杆会影响准确性,以及我们的测试集将是什么样子。我们尝试了两个杠杆(LLMs 和使用的训练数据),并在测试集中运行了 20 个问题。因此,在这个实验中,总共运行了 3 个 LLMs x 3 个上下文策略 x 20 个问题 = 180 个独立试验。
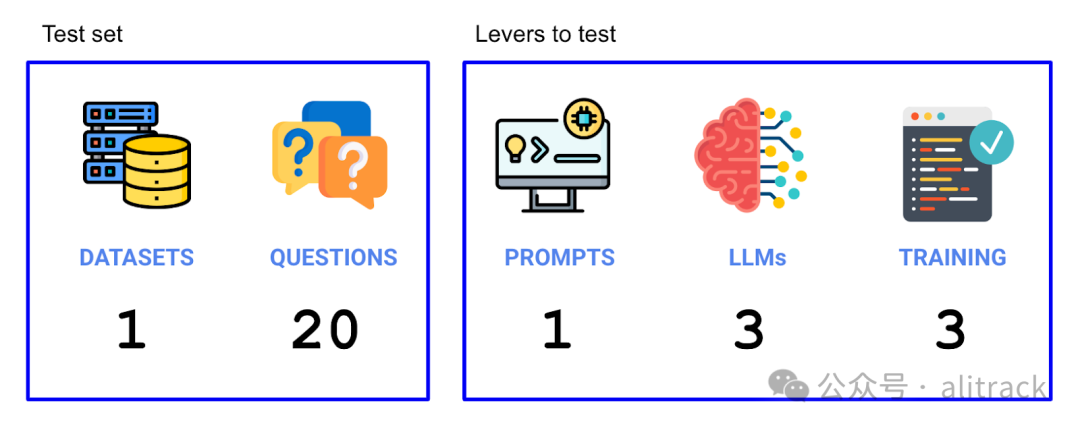
选择数据集
首先,我们需要选择一个合适的数据集。我们有一些指导原则:
代表性 - 企业中的数据集通常很复杂,而在许多演示/样本数据集中并未捕获这种复杂性。我们希望使用一个复杂的数据库,其中包含真实用例和真实数据。 可访问 - 我们还希望该数据集是公开可用的。 可理解 - 数据集应该对广泛的受众来说有些可理解性 - 过于专业或技术性的数据集可能难以解读。 维护 - 我们更喜欢一个得到妥善维护和更新的数据集,以反映真实数据库的情况。
我们找到的符合以上标准的数据集是 Cybersyn SEC 申报数据集,该数据集可免费在 Snowflake 市场上获得:
https://docs.cybersyn.com/our-data-products/economic-and-financial/sec-filings
选择问题
接下来,我们需要选择问题。以下是一些示例问题(在这个文件[2]中查看所有问题):
数据集中有多少家公司? 'ALPHABET INC.'收入表中有哪些年度指标? 特斯拉的季度'汽车销售'和'汽车租赁'是多少? Chipotle 目前有多少家餐厅?
现在我们有了数据集和问题,我们需要确定杠杆。
选择提示
对于提示,在这个运行中,我们将保持提示不变,尽管我们将进行一个后续运行,其中改变提示。
选择 LLMs(基础模型)
对于要测试的LLMs,我们将尝试以下模型:
Bison(Google)[3] - Bison 是通过 GCP API 提供的PaLM 2[4]的版本。 GPT 3.5 Turbo(OpenAI)[5] - 尽管 4 已经推出,但由于延迟和成本效益,并没有太大的准确性差异,GPT 3.5 直到最近仍然是 OpenAI 的旗舰模型(好吧 - 我们将进行测试),尤其是对于基本任务。 GPT 4(OpenAI)[6] - 更先进但性能较差的 OpenAI 模型。GPT 4 是多模态的,尽管我们不会使用该功能。 Llama 2(Meta)[7] - 我们真的想包含一个开源模型 - 领先的是 Meta 的 Llama 2。但我们通过Replicate[8]的设置迅速崩溃,并且我们在发布时无法及时修复。在早期运行中,当它有效时,我们发现性能最多只能算中等。
选择上下文
最后,我们将有三种上下文类型。上下文是指我们发送给 LLM 的内容,以帮助 LLM 了解我们的特定数据集。
仅模式 - 我们将模式(使用 DDL)放入上下文窗口。 静态示例 - 我们将静态示例 SQL 查询放入上下文窗口。 上下文相关示例 - 最后,我们将最相关的上下文(SQL DDL 文档)放入上下文窗口,通过基于嵌入的矢量搜索找到它。
通过在这三种上下文中进行测试,我们可以比较它们在不同场景下的性能。
这个测试框架的目标是评估 LLMs 在给定上下文的情况下生成 SQL 的准确性。我们将在后续的运行中尝试更改提示,以进一步了解对准确性的影响。希望这些信息对您有帮助!
使用 ChatGPT 生成 SQL
我们首先使用了 ChatGPT 生成 SQL,而上下文只包括数据库架构。这是一种最简单的上下文,只提供数据库中的表和列的信息。这里是一个示例问题:
question = "在德国有多少客户"
prompt = f""" 编写以下问题的SQL语句:{question} """
在这个上下文环境中,我们观察到 ChatGPT 的性能非常低,仅有约 3%的准确率。
仅使用模式
接下来,我们尝试仅使用架构信息,而不是完整的 SQL 查询。这是通过将问题中的 SQL 提示更改为提供关于查询的模式信息而完成的。这种情况下,上下文是通过列出表和列的方式来提供的。这里是一个示例问题:
question = "在德国有多少客户"
prompt = f""" 编写以下问题的SQL语句,只使用模式:{question} """
在这个上下文环境中,我们观察到准确性提高到了大约 20%。
使用 SQL 示例
接下来,我们通过将提示更改为包含对所需查询的示例 SQL 进行说明的方式,使用了上下文信息。这是一个示例问题:
question = "在德国有多少客户"
prompt = f""" 编写以下问题的SQL语句,使用模式和以下示例SQL:{question}
例子:
SELECT COUNT(*) FROM customers WHERE country = 'Germany';
"""
在这个上下文环境中,我们观察到准确性进一步提高,达到了大约 80%。
分析结果
通过这些实验,我们发现上下文的质量对于生成准确的 SQL 非常关键。在提供足够上下文的情况下,ChatGPT 可以实现显著的准确性提升。而仅使用数据库架构时,ChatGPT 的性能相当有限。
在 LLMs 的比较方面,GPT 4 在提供最佳整体性能方面领先,但 Google 的 Bison 在某些情况下也能表现相当不错,尤其是在提供足够上下文的情况下。
提高准确性的下一步
我们认为要进一步提高准确性,可以通过以下方式:
提供更多示例 SQL,覆盖各种查询模式和复杂性。 确保上下文信息涵盖特定数据集的关键方面,包括数据模型、关系和查询约定。 尝试更先进的模型和技术,以进一步改进生成的 SQL 的质量。
使用 AI 为您的数据集编写 SQL
最后,我们介绍了如何使用这里展示的方法为您的数据库生成 SQL。通过提供足够的上下文信息,您可以利用 ChatGPT 等 LLMs,以普通英语提出查询,并获得高质量的 SQL。这可以极大地提高业务用户访问数据库的效率,从而更轻松地进行数据分析和获取所需的见解。
以上是这篇论文的主要发现和总结。希望这些信息能帮助您更好地理解如何使用 AI 生成 SQL,并为您的数据团队提供更有效的工具。
这里: https://github.com/vanna-ai/research/blob/main/data/sec_evaluation_data_tagged.csv
[2]这个文件: https://github.com/vanna-ai/research/blob/main/data/questions_sec.csv
[3]Bison(Google): https://cloud.google.com/vertex-ai/docs/generative-ai/learn/models
[4]PaLM 2: https://blog.google/technology/ai/google-palm-2-ai-large-language-model/
[5]GPT 3.5 Turbo(OpenAI): https://platform.openai.com/docs/models/gpt-3-5
[6]GPT 4(OpenAI): https://platform.openai.com/docs/models/gpt-4
[7]Llama 2(Meta): https://ai.meta.com/llama/
[8]Replicate: https://replicate.com/replicate/llama-2-70b-chat
