




事务系统保证了系统的数据一致性,确保事务更新的原子性或是不同事务之间的数据隔离性等在多线程并发环境下所必不可少的ACID特性。除了使用并发控制协议(concurrency control, CC)使多个事务可以在冲突的情况下并发执行且阻止异常的发生,也可以利用事务分区乃至隔离来避免或错开冲突事务的执行。本次导读介绍两篇论文就分别介绍了事务分区与事务调度的一种方案。


背景介绍
下面介绍一些事务相关的基础知识。
事务
事务是一系列数据库操作作为一组执行单元执行原子操作,这些操作要么都被完成要么都不被完成(事务被拒绝)。并且根据隔离等级,事务的写操作会在某个时刻之后才会被其他事务读取,避免其他事务的数据不一致。例如,一个长时间的图分析任务不会希望在自己执行期间读取到其他事务的修改,某则可能前后两次读取相同属性的值就不同了。
隔离等级
常用的隔离等级有:
读已提交:不会读取其他运行中事务的数据 快照隔离:事务运行期间读取到的数据一致 可串行化:所有事务的运行结果可以与某种串行化执行的结果一致
冲突
事务T与T‘中的某两个数据库操作存在冲突,冲突具体由隔离等级定义。例如任何情况下,两个事务同时修改一个数据项就会造成冲突(写写冲突)。
绑定/未绑定事务
事务的所有操作是否预先可见,典型的如存储过程就是一个绑定事务。
并发控制(CC)
多个事务并发执行时可能存在冲突,引发隔离等级禁止的异常。此时使用并发控制协议来防止这种异常。CC的主要开销有:
协议本身的开销,例如加锁解锁的成本,不论是否产生冲突都需要支付。 冲突发生时产生的开销,例如锁的阻塞/重试的成本。
Strife
动机
并发控制在事务高争用坏境下表现不佳。因为高争用环境下冲突无法用协议避免,在必须承担协议本身带来的开销同时,无法减少冲突发生时的开销。
直觉上,如果将事务按照它们访问的数据项进行分组,那么因为不同组之间的事务访问的数据项不同,因此它们之间不会有冲突。它们就可以由管理该数据项的核心串行执行,而组之间不需要任何同步。这就是事务分区的概念:根据数据分区的结果将事务分为若干个互相不影响的事务组,可以不使用CC直接执行。如下图,我们可以直觉上大致分为4组,仔细观察下其中2,3两组又可以合并为一组。
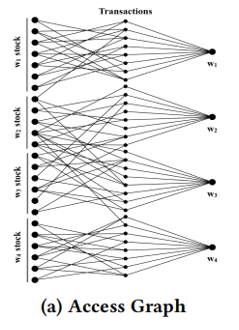
但这种分组会存在大量残差事务,即同时访问至少两个数据组的事务。这种跨分区事务必须在上述事务组执行完后单独利用CC执行。所以如果残差事务大量出现的话,事务分区的效率就迅速下降。因此传统的静态事务分区不适合热数据项会变动(即最佳数据分区不断变化)的workload。
设计思路
Strife解决静态分区的问题的办法就是分批(batch)执行事务,每batch之间进行事务分区。它认为即使workload不适合静态分区,批粒度也足以完美分区,并可以发现动态的热数据项。而跨区事务作为残差,在分区事务执行后使用轻量级CC执行。这里Strife采取的是2PL+无等待死锁避免策略。
因此,Strife的重点就是开发一个可拓展可并发的聚类算法用以将数据分区进而分区事务,其结果可分为无冲突集群与残差事务。
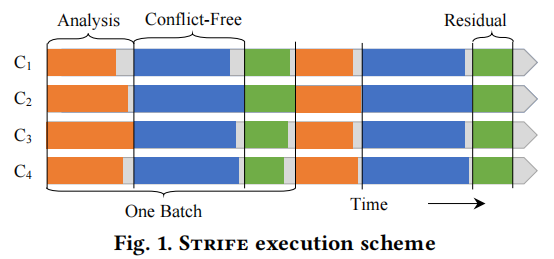
聚类算法
聚类问题可以看作对数据访问图的划分,其目标是最大化无冲突集群的数量并减少残差的大小。本算法是一个可部分并发执行的线性时间运行的近似算法,整体思想是并查集:初始每个数据项为一个聚类,不断将同一个事务访问的所有数据节点合并为一个data集群,最后根据data集群划分事务集群。
本算法有五个步骤:
Prepare:初始化 Spot:随机挑选k个事务,将其访问集聚合并标记为特殊集。此时热数据将极大概率被挑选进特殊集中。 Fuse:对于剩余事务,将其访问集聚合。请注意,此时不会合并两个特殊集。如果有同时访问两个特殊集的事务,则跳过这些事务并记录它们的个数。 Merge:合并关联紧密的特殊集。关联有两种,一种是大量事务同时访问d1/d2的直接关联;一种是大量事务同时访问d1/d3或d2/d3的间接关联。如果满足下列公式,则将这两个特殊集合并。 Allocate:根据数据集合分区事务和残差。


这是一个算法的例子,可以看出图中大致能分出4块数据(仓库),其中访问绿色和红色仓库的事务大都会同时访问这两个仓库,而黄色和蓝色的大都只访问一个仓库。b图中是随机的4个特殊集,c图中由于事务Fuse的顺序(从上到下)因此绿红的关联被发现并大部分被染上绿色。而黄色和蓝色则较好的发现了数据的关联。
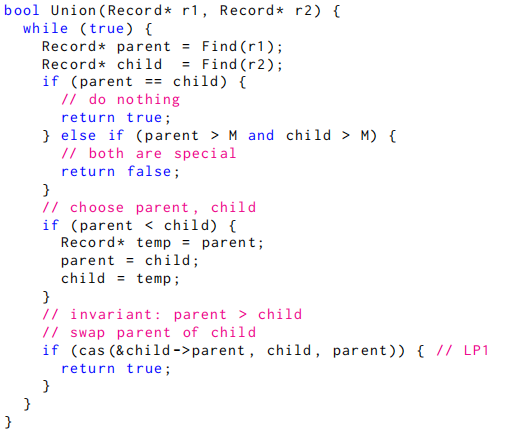
并发并查集
Strife利用根地址是否大于M来标记特殊集合,每次union的时候以小根为子,大根为父,利用根单调递增保证无锁的正确性。

实验
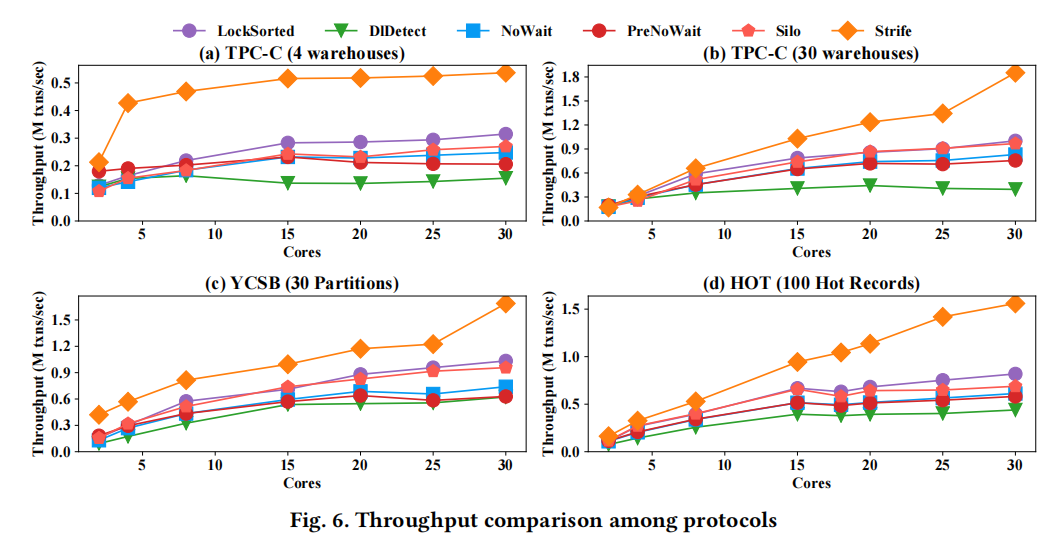
TSkd
动机
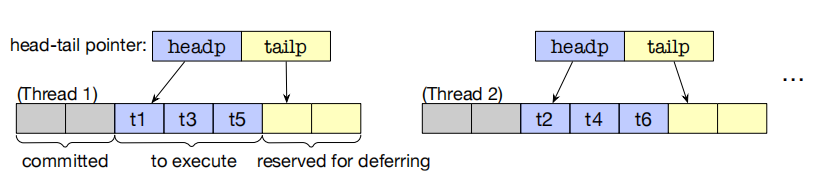
在事务分区的基础上,我们考虑调度事务的执行顺序来增加并发度。事务分区是将事务分配到不同核心上以将可并发事务并行,而调度则可以错开冲突事务的执行时间,使冲突事务在不同时间执行从而可以并发。例如下图中的例子,按照b图中的顺序,T2和T5会冲突导致T2重新执行。但如果能够通过调度交换T1和T2的执行顺序,那么T2和T5在执行时间上就会错开,从而不会冲突;或是类似d图,主动将T2延迟到T3后避免与T5冲突
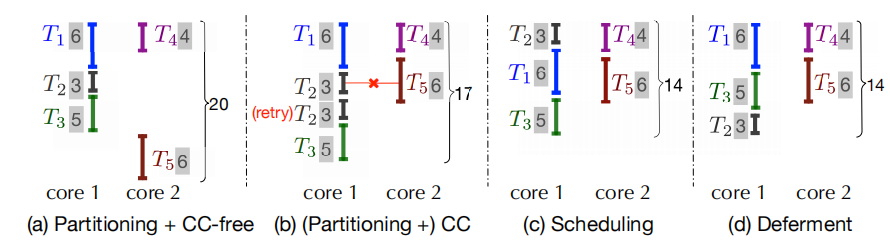
对此,补充一个新的概念:运行时冲突。也就是指事务执行时确实会产生的冲突。而事务调度就是在事务分区的基础上避免运行时冲突从而达到更大的并发度。
设计思想
与事务分区不同,事务调度需要获取事务的执行时间,以此来决定事务的执行顺序,避免运行时冲突。而事务分区主要是将冲突的事务尽可能放在一个线程/核心上运行,不需要知道每个事务的运行时间。
估计事务的执行时间有很多方法,目前主要包括历史记录,读写集大小以及轻量级机器学习方法。此外为了防止估计错误,运行调度后的事务仍然需要使用并发控制。这一点会略微逊色于事务分区。
如下图所示,TSkd首先依赖先前事务分区的工作先获取一个初步结果,然后将事务分区中的残差尝试依次利用调度插入某个事务组。同时对于未绑定事务(无法分区)和执行残差时还采用了一种主动延迟的并发控制优化。
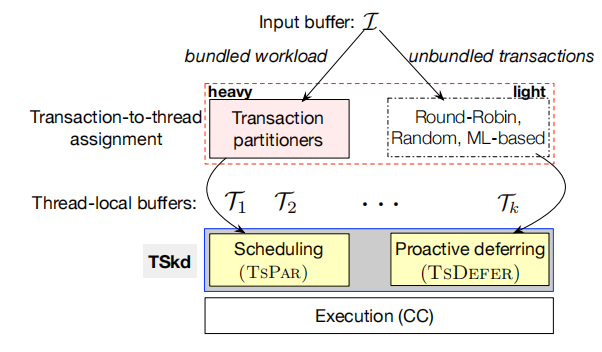
调度算法
该模块被称为TsPar。假设初步分区的结果分别是事务组P~1~ ~ P~n~和残差R,最终调度队列是Q~1~ ~ Q~n~和残差R~s~。依次考虑残差R中的事务,贪心地将其分配给当前总时长最短的队列Q~l~,并将其他待定队列中P~j~(j!=l)与该事务冲突的事务尽可能提前,如果无法成功分配,则进入残差R~s~。

主动延迟
该模块被称为TsDefer。如果即将执行的事务与目前正在执行的事务存在冲突,则考虑主动将该事务延迟到执行队列的最末尾,先执行下一个事务。由于该模块会造成额外的开销,因此需要轻量级处理。
本论文的实现方案是构造无锁结构来查询其他线程正在执行的事务,并随机探查若干次读写数据项,若冲突则概率延迟(防止高争用环境下无限延迟)。
TsDefer的具体操作有:
regPos:事务提交时移动头指针 lookup:返回另一个线程头指针指向的事务的写集的一个随机数据项 defer:将本线程的头指针指向的事务推迟到尾指针处并同时推动两个指针。
其中调用lookup的次数和事务冲突时延迟的概率都是参数。我们注意到采用CAS无锁实现regPos和lookup都可能读取陈旧数据,但实际的影响可以忽略不计。此外对于未绑定事务,TsDefer需要预测事务的读写集。
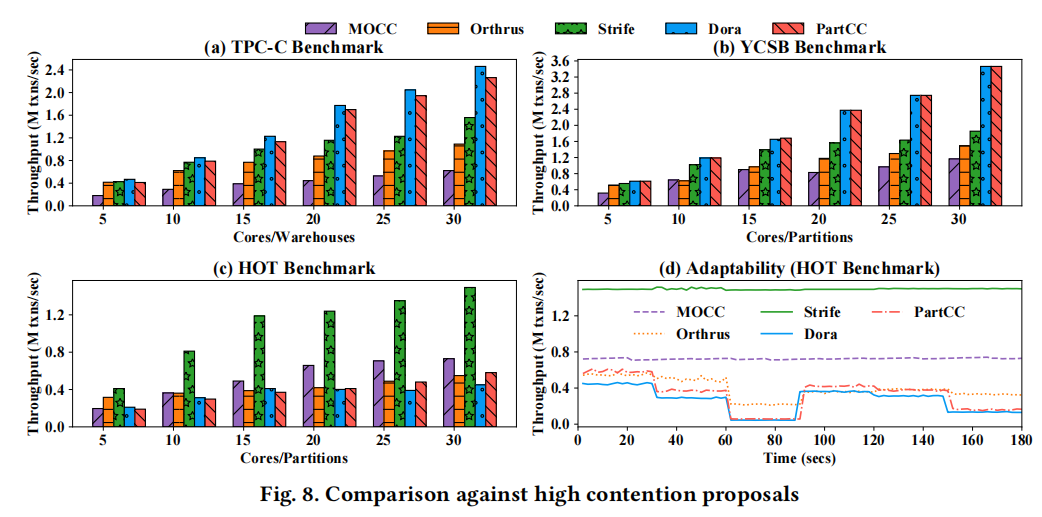
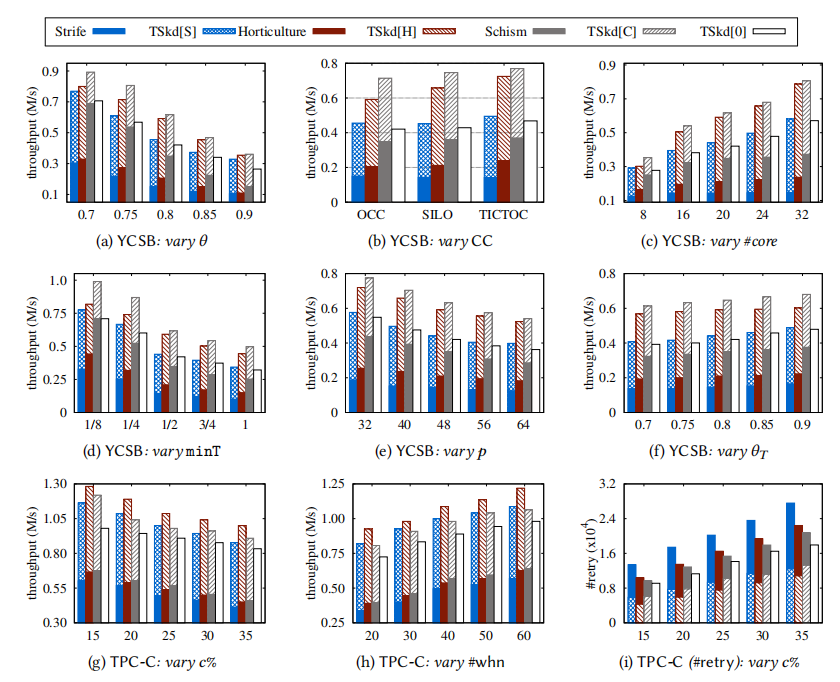
本次实验运行在集合了外部事务分区器的DBx1000平台上,下述TSkd[S/C/H]分别表示在分区器Strife/Schism/Horticulture上的TSkd,TSkd[0]表示无分区器,所有事务初始为残差;TSkd[CC]表示只使用TsDefer而不进行事务调度。
可以注意到,针对分区器的优化是比较显著的,吞吐量大多能达到2.5倍,且TSkd[0]作为对照组可以体现调度的有利性。此外,TsPar模块也能显著降低重试次数,并提供更好的工作负载。
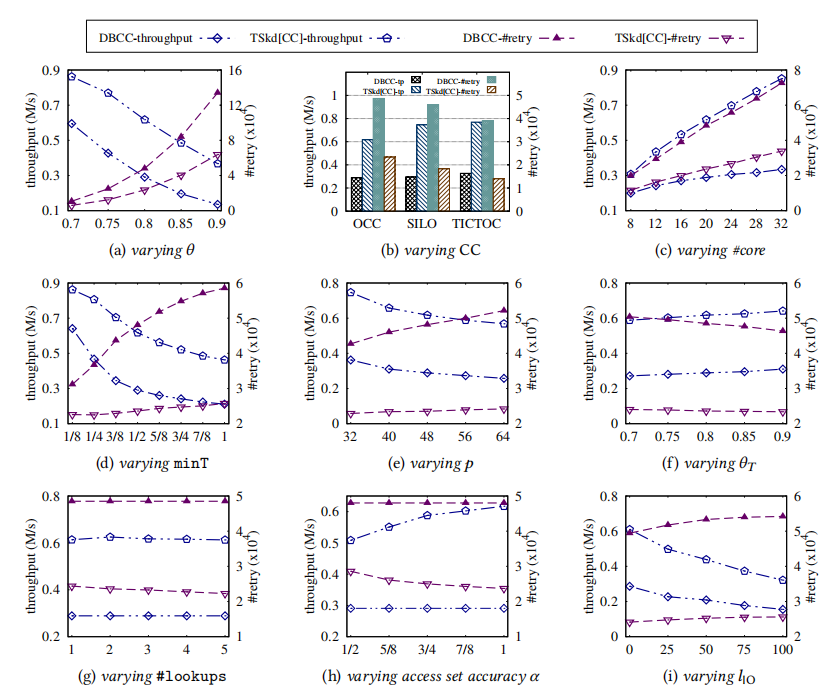
下图是TSkd[CC]针对目前的并发控制协议带的效率对比。可以明显看到TSkd[CC]不论在吞吐量还是重试率都要优于目前的CC。
事务分区是高争用环境下的一种并发解决办法,Strife突破了以往静态分区无法有效聚合具有动态热数据项的workload的问题。而TSkd则在事务分区的基础上上更进一步,引入了事务调度的概念,进一步提高了高争用环境下的并发程度。


欢迎关注北京大学王选计算机研究所数据管理实验室微信公众号“图谱学苑“
实验室官网:https://mod.wict.pku.edu.cn/
微信社区群:请回复“社区”获取
gStore官网:https://www.gstore.cn/
GitHub:https://github.com/pkumod/gStore
Gitee:https://gitee.com/PKUMOD/gStore

