




ICLR 24, Large Language Models Are Not Robust Multiple Choice Selectors
https://openreview.net/forum?id=shr9PXz7T0
论文出发点
大型语言模型(LLMs)在多项选择题(MCQs)的选项位置的变化很容易受到影响,原因在于它们固有的“选择偏差”,即它们更倾向于选择特定的选项ID作为答案(如“选项A”)。

论文通过对三个基准测试中的20个LLMs进行广泛的实证分析,我们指出这种行为偏差主要源于LLMs的“标记偏差”,即在预测答案时,模型会先验地为特定的选项ID标记(例如A/B/C/D)分配更多的概率质量。
大模型的多项选择偏见
MCQ通常包括一个问题和多个备选选项,模型的任务是从中选择最合适的答案。当前LLM相关的场景广泛使用MCQ的任务格式,例如在评估LLMs的基准测试中以及LLM-based的自动评估框架中。
作者观察到LLMs对于MCQ中选项位置的改变是脆弱的。在0-shot MMLU评估中,通过简单的"answermoving attack",将正确答案始终移动到特定位置会导致LLMs性能的剧烈波动。作者在表1中展示了这一现象,说明移动答案到特定位置会显著影响LLMs的准确性。
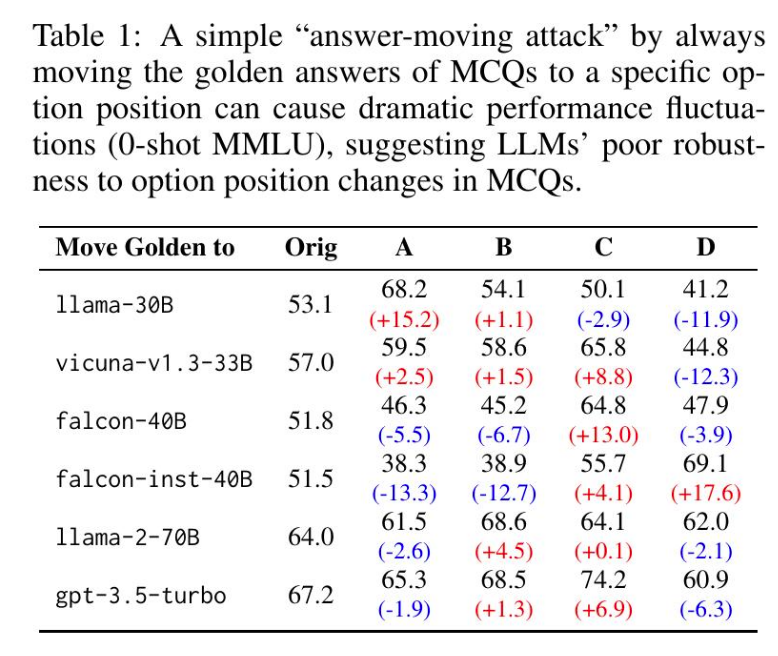
LLMs对选项位置变化的差异敏感主要是因为它们存在偏向性行为:它们倾向于选择特定选项ID作为答案,被称为选择偏差。
作者通过随机抽样了1000个MMLU测试样本进行简单验证,其中控制了正确答案为A/B/C/D的数量分别为250。结果显示,1lama-30B在这些样本中选择A/B/C/D的比例分别为34.6% / 27.3% / 22.3% / 15.8%,而gpt-3.5-turbo为22.5% / 25.6% / 32.3% / 19.6%,这些比例在统计上是不均匀的,与表1中的性能波动相符。
选择偏见的实验
选择偏差在各种LLMs中普遍存在
直观地说,选择偏差可能起源于LLMs的训练数据,其中一些答案(例如C)可能比其他答案更频繁出现。然而,在相同模型家族内,即使使用相同的训练数据进行训练(例如llama-7/13/30/65B、llama-2-7/13/70B),我们并未观察到一致的选择偏差模式。我们推测选择偏差是由训练数据组成和顺序、模型容量(参数数量)以及其他因素(如超参数)之间复杂交互的产物。
相同LLM内的选择偏差在呈现相似性
例如,在0-shot设置下,Llama-30B在各种基准测试中一致地偏爱A/B,而gpt-3.5-turbo更倾向于。尽管偏好排序可能在任务或领域之间不严格持续,但每个模型都有一种倾向于特定选项ID(例如A和B)而远离其他选项(例如C和D)的总体趋势。这表明选择偏差是LLMs的一种固有行为偏差,受任务或领域影响较小。
上下文示例可以减少但同时可能改变选择偏差
正如图3所示,1lama-30B在0-shot设置下对不利,但在5-shot设置下变得偏向于它。我们发现这种改变在相同模型家族内仍然没有显示出明显的模式。这表明上下文示例可能引入新的偏差,并与固有的选择偏差交织在一起,使得后者变得复杂且不规律。
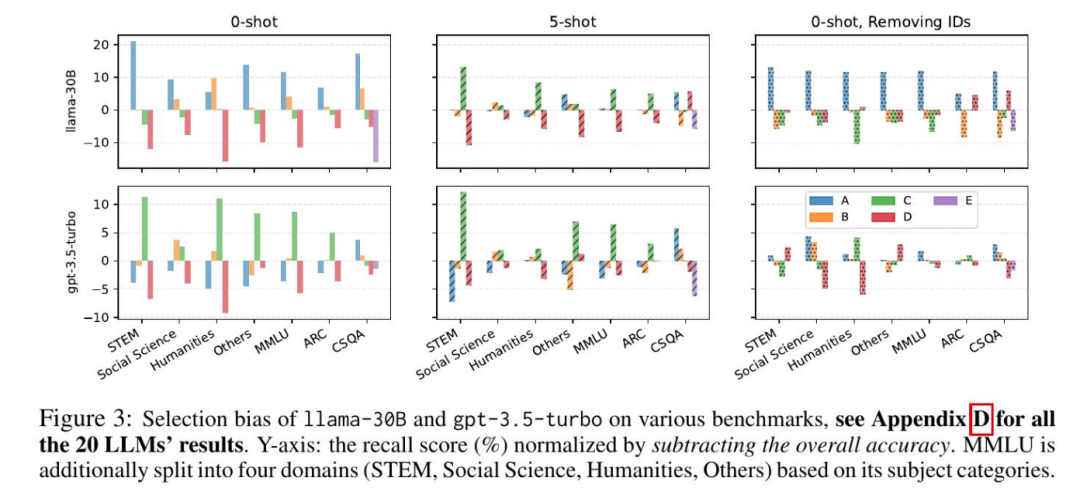
偏见产生的来源
在对各种LLMs进行广泛评估之后,研究现在试图找出导致这种行为偏差的内在原因。作者提出两个假设:
令牌偏差。在标准的MCQ提示中(图1),当从选项ID中选择答案时,模型可能会在先验上给特定的ID令牌(如A或C)分配更多的概率质量。 位置偏差。模型可能更偏向于出现在特定排序位置的选项(比如第一个或第二个)。
为了区分两种假设原因的影响,作者进行了两个消融实验:
实验1:洗牌选项ID
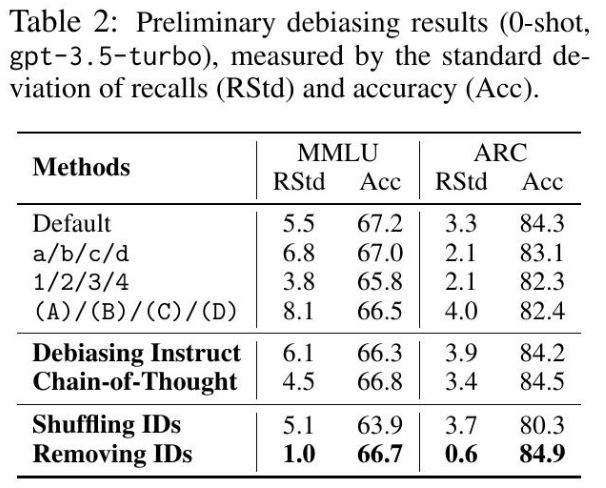
随机洗牌默认的ID顺序,例如,洗牌成或等。通过这种方式,B可以表示任何排序位置的选项,从而消除了位置偏差的影响,只留下了令牌偏差。但是这种消融显然会影响MCQ提示的自然性和质量,并可能导致模型性能下降(如表2所示)。
实验2:去除选项ID并要求模型直接选择选项内容
这种方式下,选择偏差的变化将表明令牌偏差的影响,而剩余部分对应于位置偏差。在评估没有选项ID的LLMs时,我们要求gpt-3.5-turbo生成整个选项,然后与黄金答案进行比较。对于开源模型,我们计算选项的可能性,归一化为它们的长度,然后使用最大值作为模型的预测。
思考:通过去除选项ID来消除LLMs的选择偏差是否可行?
尽管选择偏差明显减少,但我们发现去除选项ID通常会降低模型性能(除了在5-shot设置下的少数情况),详见附录F的表4和表5。这种性能降级是因为我们利用LLMs在没有选项ID的情况下回答MCQs的方式,即计算和比较选项的可能性,这被称为Robinson & Wingate (2022)中的“填空提示”格式。
他们的研究表明,要求LLMs预测选项ID形成了比“填空提示”更好的MCQ提示,这与我们的观察一致。此外,通过计算和比较选项的可能性来选择答案不如直接预测选项ID方便和直接。因此,我们建议去除选项ID并不是缓解选择偏差的实际方法。
思考:简单的提示策略是否能够缓解选择偏差?
作为初步的去偏尝试,我们对gpt-3.5-turbo应用了两种简单的提示策略:
显式的去偏指导:我们在gpt-3.5-turbo的系统消息中附加了一个明确的去偏指导("请注意,所提供的选项已经被随机洗牌,因此公正而没有偏见地考虑它们是至关重要的。")。 思维链提示法(Wei et al. 2022, Kojima et al., 2022):首先使用"让我们一步一步地思考:"提示gpt-3.5-turbo生成其思考过程,然后产生最终答案。我们遵循OpenAI Evals中的实现,详见附录C的图10。
如表2所示,这两种提示策略不能很好地缓解选择偏差。这表明选择偏差是LLMs的固有行为偏差,无法通过简单的提示工程来解决。
编辑推荐
《深度学习与计算机视觉:核心算法与应用》内容翔实,实例丰富,适合人工智能初学者尤其是计算机视觉初学者阅读,也适合有一定基础的机器学习、深度学习和计算机视觉从业人员阅读,另外还适合作为高等院校人工智能相关专业的教材。
转发本文到朋友圈,集赞30个免费领书
只有三个名额!
# 联系👇小助手领书 #
每天大模型、算法竞赛、干货资讯

