




1 概述
GPT-3 经历的测试:
标准自然语言处理(Natural Language Processing,NLP)测试(如问题回答(Question Answering,QA) 特殊的一次性演示,如在句子中使用新词
以下是 GPT-3 的测试结果:
在某些任务上,GPT-3 大幅超越现有技术的最高水平 在其他任务上,GPT-3 和训练较好且拥有大量标签数据的系统比较显得明显落后
我们如何理解这样的结果?
GPT3 并未针对某些任务进行训练,只是通过训练预测下一个词 因为没有针对某些任务进行训练,GPT-3 未出现过拟合,于是有较大的潜力 如果希望 GPT-3 在特定任务上表现良好,可以使用大量的标签来调整之,以超过当前的技术水平
2 LM 的适应性:从语言模型到任务模型
在前面已经提到,语言模型是对一个词元序列的分布进行建模;还可以用于在给定提示条件下完成序列。任务被定义为输入到理想输出的映射。例如在问答任务中,理想输出就是我们想要的答案。将语言模型转化为任务模型的过程成为适应(Adaptation),这个过程需要两个输入:
任务的自然语言描述 训练数据(输入-输出二元组)
我们可以使用两种方法使得模型达到这种适应:
训练(监督学习):训练一个新模型满足这种条件,或从已有的语言模型出发微调得到结果 提示:根据任务描述建立若干组提示(上下文信息),将其输入模型以达到调整的目的。现有以下三种方法: 零样本(Zero-shot):不提供提示,直接让模型按照自己的“理解”输出结果 单样本(One-shot):提供一组提示 少样本(Few-shot):提供几组提示
在调整的这几个方法中,我们可以看到迁移学习和元学习的思想:
语言模型的初始训练位于一个较大的域,而将其对某任务进行适应即将模型从较大的域迁移到该特定的任务域。J. Yosinski等在How transferable are features in deep neural networks ? 这篇论文中讨论了神经网络的可迁移性,网络的最初几层提取了某些通用特征,而剩下的部分做具体任务的工作:这为微调这一技术提供了一定的支撑 在提示训练中,我们假定模型已经掌握语言的某些结构,并具有回答任务中问题的“元知识”,因此我们可以使用较少的样本让模型在任务上的表现提升。 但需注意,以上两条均建立在模型训练良好且无过拟合的情形下
在训练的过程中,模型容易过拟合。如何进行有效训练将在后续章节讨论。值得注意的是,在使用提示时,我们智能利用少量训练示例,这种局限性是 Transformer 自身性质导致的:模型的输入长度有约束
3 对任务的讨论
在 GPT3 的论文中,作者评估了模型在大量任务上的表现,对于每一个任务,我们都会讨论以下几个方面:
定义:任务的内容和动机 适应:如何通过提示将任务简化为语言模型可理解的内容 结果:与该任务的最先进模型(State-of-the-art,SOTA)相比,模型的性能如何
在多个任务中,GPT-3 的实验参数如下
模型:完整(davinci),共有 1750 亿(175,000,000,000)参数 使用尽可能多的数据实行上下文学习
实验任务选择如下:
语言建模(Language Modeling) 问题回答(Question Answering) 翻译(Translation) 算术(Arithmetic) 新闻稿生成(News Article Generation) 创新任务(Novel Tasks)
在训练中,作者对模型进行了消融实验(Ablation Study),以查看模型大小和提示实例数量是否重要。接下来我们逐个分析这些任务
3.1 语言建模(Language Modeling)
3.1.1 困惑度
在语言建模中,困惑度(Perplexity) 是一个重要指标。用于衡量语言模型的性能。其定义如下:
其中是测试集中的某个词元序列,是测试集中的总词元数。可以看出,越大,该词元序列的困惑度越小。考虑到当词元序列长度增加时,可能趋近零,于是我们采用几何平均来抹除长度的影响。
困惑度和交叉熵的联系
定义语言,与模型的交叉熵为
回顾交叉熵的定义,如果模型可以完美的建模语言,将会降至最低。
定义 (依概率收敛) 给定随机变量序列,称序列依概率收敛至随机变量,如果对任意,.
定理 (Breiman渐进均分定理,Breiman's Asymptotic Equipartition Property) 若随机变量序列独立同分布,,则
可以看出若是稳态遍历随机过程,则
显然可以看出
这里的困惑度是模型对语言中所有序列的困惑度。意识到这样的事实后,“困惑度越低表示模型越优秀”就显得十分自然了。
类似地,我们可以将困惑度的定义做变形,得到下面的公式
从上面的式子可以看出,困惑度将条件概率的倒数以一种方法求平均,回想关于信息熵的讨论,这里的倒数对数项类比于“提问的次数”,即每个词元的位置平均要选择几次,因此这被称为分支因子(Branch Factor)。
3.2.2 两类错误
(好怪,不知道为什么教程里面讲这个)
语言模型会犯错误,这些错误可以分为两类:
召回错误:语言模型未能正确地给某个词元分配正确的概率。假如模型将某个条件概率计算为零,这会导致困惑度趋于无穷大 精确度错误:模型给某些词元分配了过高的概率。此时困惑度会上升:假设某词元条件分布中混入了噪声:
则序列的困惑度为
3.2.3 GPT-3 在数据集上的结果
| Model | Penn Tree Bank | LAMBADA | HellaSwag |
|---|---|---|---|
| GPT-3 | 20.5 | 1.92 | 79.3 |
| SOTA | 31.3 | 8.63 | 85.6 |
Penn Tree BankNLP 的经典数据集,测试方法是将整个文本作为提示输入模型,然后计算其困惑度
LAMBADA该数据集需要模型通过句子的前面所有词预测最后一个词。需要将输入输出二元组输入模型使之学习
HellaSwag评估模型的常识推理能力,从一系列选项中选出最优选项。在这个数据集中,SOTA 使用该数据集进行微调,而 GPT-3 在不适用该数据集训练的结果也接近领先水平
3.2 问题回答(Question Answering)
下面对 GPT-3 和其他 SOTA 模型在不同问答数据集上的正确率比较。模型的提示如下:
Q: Who played tess on touched by an angel?
A: Delloreese Patricia Early (July 6, 1931 - November 19, 2017), known professionally as Della Reese.
| Model | TrivialQA | WebQuestions | NaturalQuestions |
|---|---|---|---|
| GPT-3 | 64.3(Few-Shot) 71.2(Zero-Shot) | 41.5(Few-Shot) 14.4(Zero-Shot) | 29.9(Few-Shot) 14.6(Zero-Shot) |
| SOTA | 68.0 | 45.5 | 44.5 |
3.3 翻译(Translation)
翻译任务需要将一个语言中的句子翻译到另一个语言中。刚开始时,统计机器翻译占主流,紧随其后的是神经机器翻译。由于翻译并不是严格一对一的,其自动评估指标是BLEU-Score。实验表明,经过微调的 GPT-3 性能已经超过了当时的 SOTA 模型。
关于神经机器翻译
曾出现过基于对偶学习的机器翻译方法,下面给出一个简单的例子:构建一个从语言映射至语言的映射,相应地也构建模型。这两个模型同时训练,我们期望两模型的复合在”表意相同“的意义下相等:
这与范畴意义下的”可逆态射(箭头)“定义十分相似。
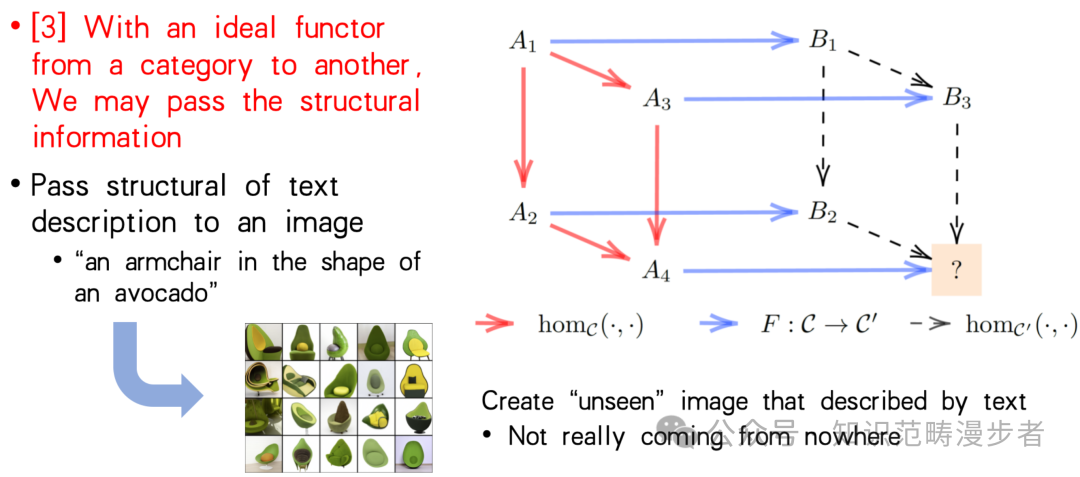
通过上面的描述,可能读者会想到:某语言中的句子就像是在一个网络中按照一定规律游走产生的路径。而翻译这个动作在于找到在一个网络中的一条路径与领一个网络中的对应路径的映射。清华大学的袁洋老师正通过这样的视角,以范畴论的角度切入讨论大模型的边界问题,下图表明,如果满足一定的条件,在两个范畴之间构造理想的函子,则这个函子可以传递范畴的结构信息。
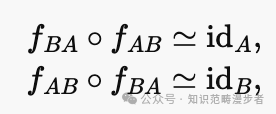
3.4 算术(Arithmetic)
算术任务帮助我们检查 GPT-3 的抽象推理能力,其中包含诸如”等于几?“这样的问题。然而 GPT-3 的表现却不尽如人意。
近年来,大模型运用于数学这一课题,尤其是自动定理证明(Automatic Theorem Proving) 随着以Lean为主的数学形式化工具逐渐变得热门。大模型可以借助树搜索、强化学习等方式在问题解决方案空间中进行搜索,生成对应的 Lean 代码,最后由 Lean 编译器接管证明过程的验证工作。在更早一些的时间,有工作将 LLM 和 Wolfram 结合,也实现了不错的数学推理能力。
3.5 新闻稿生成(News Article Generation)
该任务需要模型在给定新闻稿的标题和副标题的情况下完成整篇文章。然后使用类似 Turing 在《计算机器与智能》论文中提出的”模仿游戏“(后被称为图灵测试)中让人类区分新闻稿是否由模型生成。实验的结果是人类只有 52% 的时间可以正确分类新闻稿是否由机器撰写。
3.6 创新任务(Novel Tasks)
使用新词 给一个新造的词和定义,生成使用该次的句子 纠正英语语法 给定一个不合语法的句子,模型输出合乎语法的版本。
3.7 其他
除此之外,还有很多其他任务:
SWORDS:同义词替换 Massive Multitask Language Understanding:包括数学、美国历史、计算机科学等若干多选问题 TruthfulQA:人类由于误解而错误回答的问答数据集
参考资料
Datawhale So-Large-LLM 教程第二章 Yosinski J, Clune J, Bengio Y, et al. How transferable are features in deep neural networks?[J]. Advances in neural information processing systems, 2014, 27. Brown T, Mann B, Ryder N, et al. Language models are few-shot learners[J]. Advances in neural information processing systems, 2020, 33: 1877-1901. Yuan Y. On the power of foundation models[C]//International Conference on Machine Learning. PMLR, 2023: 40519-40530.
