




前言
如果想快速体验大数据库机器人,请访问5 行代码打造你的大模型数据库聊天机器人
如果想体验 DuckDB 的速度与多种数据源的支持,请访问简单代码让你的数据库聊天机器人支持 Excel、CSV、JSON、Parquet 甚至数据湖
如果有兴趣获得更好的准确性,可以访问不同 LLMs 和上下文策略的测试,以最大化 SQL 生成准确性
很多人体验后,然后问可以离线部署吗,答案是肯定的 ,
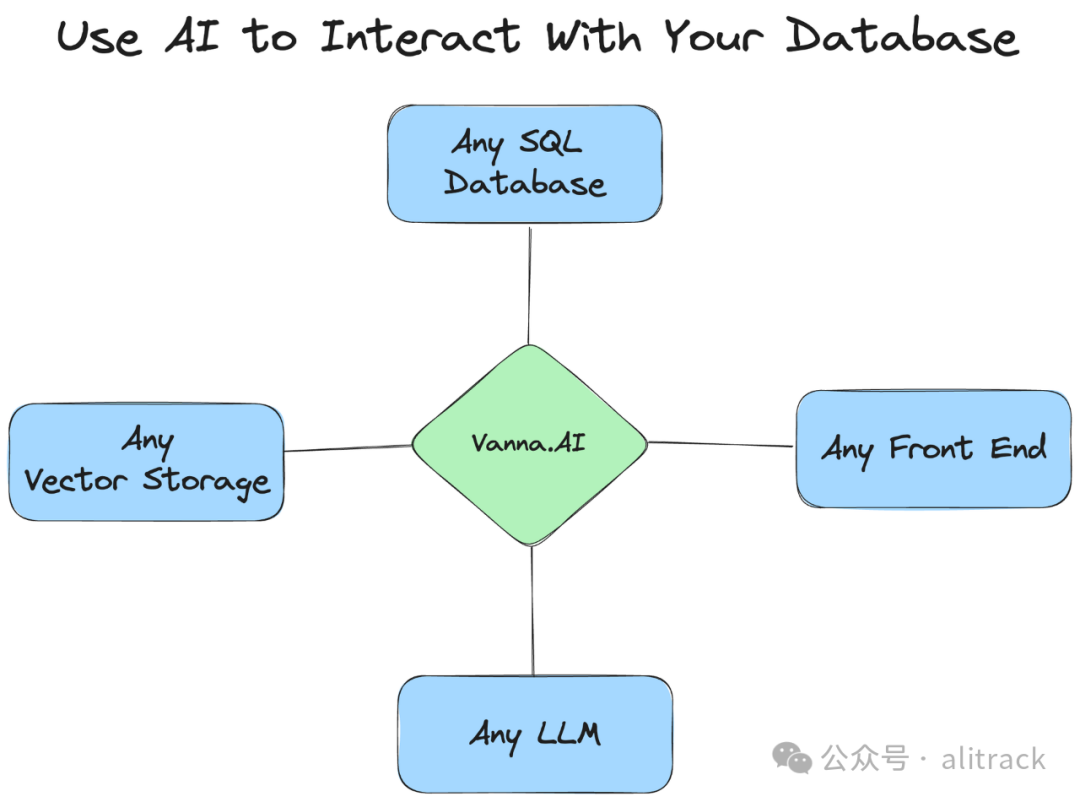
今天就分享下本地部署方法。
部署本地模型
ollama + litellm
暂不支持 Windows
安装
# 安装ollama
curl https://ollama.ai/install.sh | sh
# 安装litellm
pip install litellm
部署
ollama serve
ollama pull mistral-openorca:7b-fp16
litellm --model ollama/mistral-openorca:7b-fp16
测试
curl --location 'https://8000-alitrack-vannaflask-y3vhzwrt5ow.ws-us107.gitpod.io/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
]
}'
vLLM
需要 GPU 支持
安装
pip install vllm
部署
python3 -m vllm.entrypoints.openai.api_server \
--model meta-llama/Llama-2-13b-hf \
--served-model-name llama2-13b
测试
curl -X POST http://0.0.0.0:8000/v1/chat/completions -H "content-type:application/json" -d '{
"messages":[{"role":"user","content":"who are you"}],
"model": "llama2-13b",
"stream": false,
"max_tokens": 256
}'
其它可选方案
FastChat LLaMA-Factory
部署数据库聊天机器人
安装必要 Python 包
pip install flask vanna[openai,chromadb]
附上代码
#main.py
from vanna.local import LocalContext_OpenAI
from vanna.flask import VannaFlaskApp
import json
import os
OPENAI_BASE_URL = 'http://127.0.0.1:8000'
os.environ['OPENAI_BASE_URL'] = OPENAI_BASE_URL
vn = LocalContext_OpenAI(config={'api_key': 'anything', 'model': 'gpt-3.5-turbo','api_base': OPENAI_BASE_URL})
# 训练模型
with open('/data/llm/tpc-h/questions.json') as f:
questions = json.load(f)
for q in questions:
vn.train(q['question'], q['answer'])
init_sql=""
# 使用DuckDB
vn.connect_to_duckdb(url='/data/duckdb0',init_sql=init_sql)
app = VannaFlaskApp(vn)
app.run()
http://127.0.0.1:8000 是 OpenAI API 兼容接口,即上面使用 litellm
或者vllm
部署本地模型。模型: gpt-3.5-turboapi_key, 任意
运行代码
python main.py
P.S.
本次测试,我使用 ollama+litellm, 模型尝试了多个模型,到发文时, mistral-openorca:7b-fp16
效果最好。
如果你有更好的效果,记得分享,谢谢!
文章转载自alitrack,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
