




最近公司要把核心的ORACLE项目换成POSTGRES, 整体数据大致40TB左右,数据迁移同步是一个重大的挑战。
之前公司的去O项目,都是采取的ORA2PG,dataX这种的离线方式,虽然需要维护窗口时间,但是比较稳妥。
但是对于数据量大的项目,并且核心项目不能允许长时间down time的核心系统,必须要采取一种基于CDC的数据实时同步的方案。
国际上业内的旗舰产品自然是OGG了, 但是由于甲骨文的OGG 需要在PG 端 安装OOGG4PG 软件并且需要独立的license 费用, 这边先暂时由于cost 方面的考虑暂时放弃。(据说是1万多美刀 per core ,果然是500强企业的高端奢侈品)
偶然间发现了在网上发现了CloudCanal, 感觉web页面风格很像阿里系的DTS,datawork的产品。
而且最最最重要的是有社区免费版!!!! (虽然任务数受限在5个,但是可以先做一个POC体验一下,最基本同步需求是否可以满足)
我们来访问官网首页:https://www.clougence.com/?src=cc-doc-install-windows
可以看到支持的数据源还是十分丰富的:

我们首先需要申请注册一个账号:
注册成功登录后,我们点击 下载私有部署版

目前支持容器部署和tar安装2种模式: 这里我们选择的TAR包的安装模式

我们下载完成后,可以参考安装手册进行安装:
https://www.clougence.com/cc-doc/productOP/tgz/firstinstall_with_tgz
简单的总结如下:
1.需要一个mysql 8.0的数据库,作为保存任务的元数据的库
2.需要promethues 服务进行任务指标的采集监控
3.需要钉钉机器人进行报警(可选微信或者其他的方式)
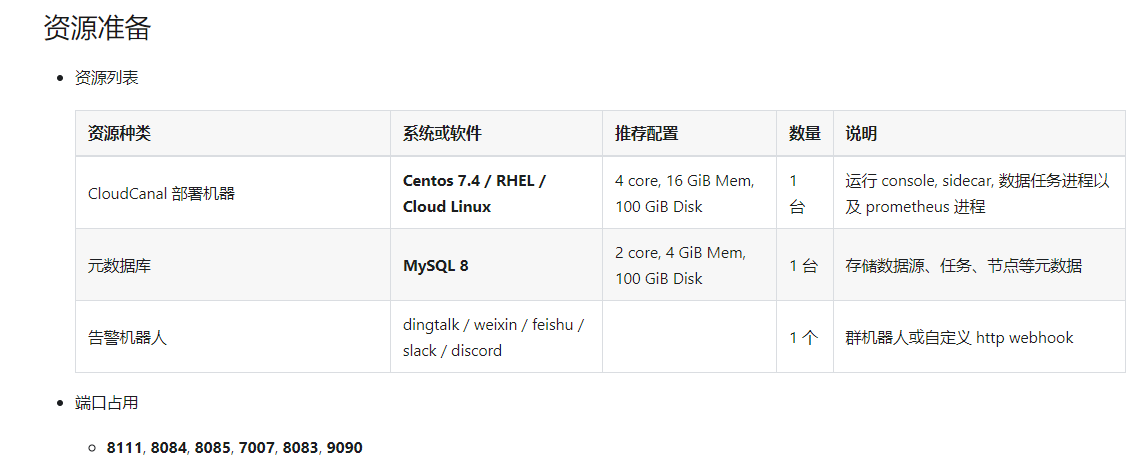
基本环境安装:
yum -y install java-1.8.0-openjdk-devel.x86_64
useradd -d /home/clougence -m clougence
passwd clougence
echo "clougence ALL=(ALL) NOPASSWD:ALL" >> /etc/sudoers
mkdir -p /home/clougence/{logs,backup,tar_gz}
vim /etc/security/limits.conf
# nofile - 可以打开的最大文件数, *通配符表示对所有用户有效
* soft nofile 65535
* hard nofile 65535
# 配置文件名可能是 20-nproc.conf
vim /etc/security/limits.d/90-nproc.conf
# 修改clougence的用户最大进程打开数
* soft nproc 1024
clougence soft nproc 131072
在mysql 8.0中创建用户:(这里我的数据库是提前安装好的,没有的话现成的mysql的话 需要自行独立安装mysql8.0版本)
root@localhost:mysql_uatDB.sock [performance_schema]> CREATE DATABASE `cloudcanal_console` DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
--------------
CREATE DATABASE `cloudcanal_console` DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci
--------------
Query OK, 1 row affected (0.00 sec)
root@localhost:mysql_uatDB.sock [performance_schema]> create user 'cloudcanal'@'%' identified by 'Clougence#2021';
--------------
create user 'cloudcanal'@'%' identified by 'Clougence#2021'
--------------
Query OK, 0 rows affected (0.01 sec)
root@localhost:mysql_uatDB.sock [performance_schema]>
root@localhost:mysql_uatDB.sock [performance_schema]> grant all on cloudcanal_console.* to 'cloudcanal'@'%';
--------------
grant all on cloudcanal_console.* to 'cloudcanal'@'%'
--------------
Query OK, 0 rows affected (0.01 sec)
root@localhost:mysql_uatDB.sock [performance_schema]>
root@localhost:mysql_uatDB.sock [performance_schema]> flush privileges;
--------------
flush privileges
--------------
Query OK, 0 rows affected (0.01 sec)
下载软件并解压
wget "https://tgzdownload.clougence.com/tar_gz/3.3.3.1/cc.tgz?Expires=1705934079&OSSAccessKeyId=LTAI4G5wdUHmu9t19fVLkC2w&Signature=HX7to5JMjIs0zHyRA0K6upPsXd0%3D" -O cc.tgz tar -xaf cc.tgz tar -zxvf cloudcanal-console.tar.gz mv /home/clougence/tar_gz/cloudcanal /home/clougence
修改配置文件参数
cd ~/cloudcanal/console/conf 修改必要的参数: spring.datasource.url=jdbc:mysql://10.67.208.70:3310/cloudcanal_console?serverTimezone=Asia/Shanghai&characterEncoding=utf8&autoReconnect=true&rewriteBatchedStatements=true&socketTimeout=30000&connectTimeout=3000 spring.datasource.username=cloudcanal spring.datasource.password=********* jwt.secret=tpsesJL5AAMZqrlS8Sjg40S3xGKlUxhShYLfqfnNHQKROPx7MNlN9N11W361kDgTr/rNPvPCVruIlwyfW4IYLQ== console.rsocket.dns=10.67.38.173 prometheus.host=http://10.67.39.149:9090
我们需要在linux下生成 jwt.secret( 系统登录验证算法的密钥,可以是一个64位随机码)
openssl rand -base64 64 > jwt.secret >cat jwt.secret tpsesJL5AAMZqrlS8Sjg40S3xGKlUxhShYLfqfnNHQKROPx7MNlN9N11W361kDgT r/rNPvPCVruIlwyfW4IYLQ==
启动项目:第一次启动会初始化mysql数据库里面的表
cd ~/cloudcanal/console/bin sh ./startConsoleAndUpdDB.sh
登录web控制台:http://10.67.38.173:8111/#/login
默认登录账号和密码: 默认账号( test@clougence.com)和密码(clougence2021)
下一步:激活软件,免费获取许可证
点击未激活链接

复制申请码:
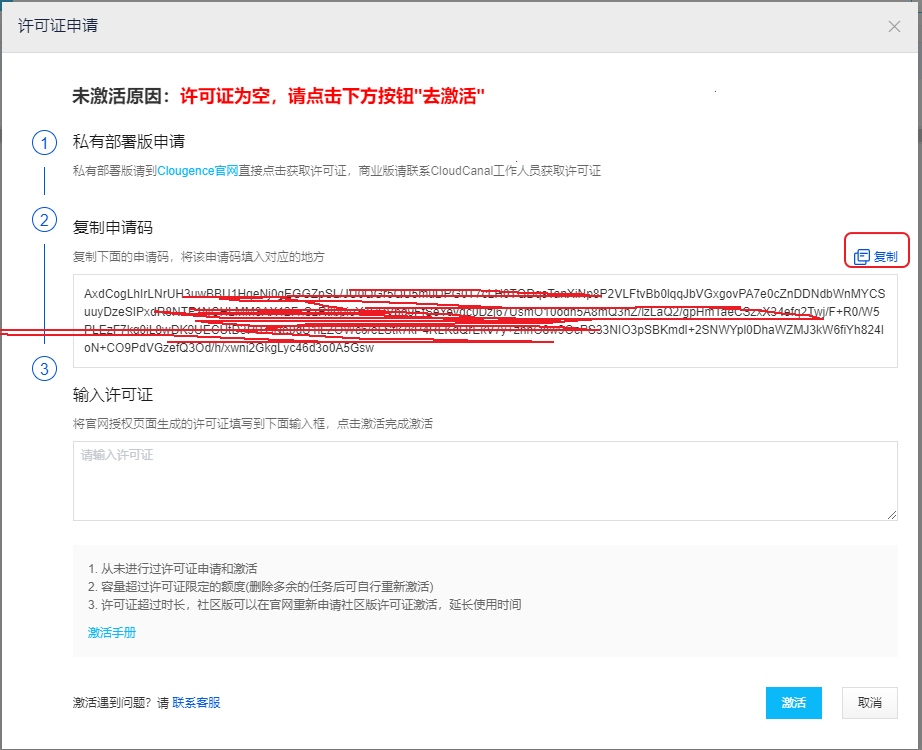
点击首页免费获取许可证

填取申请码:
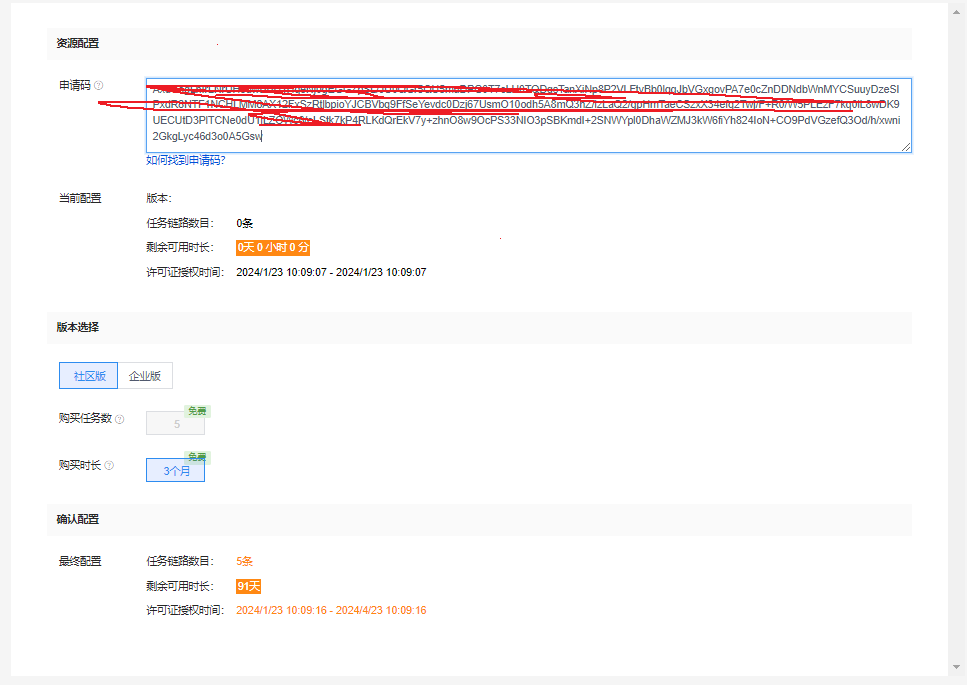
默认是 最大允许5个任务,有效时长是3个月。
我们把生成的许可证填入到激活对话框里:
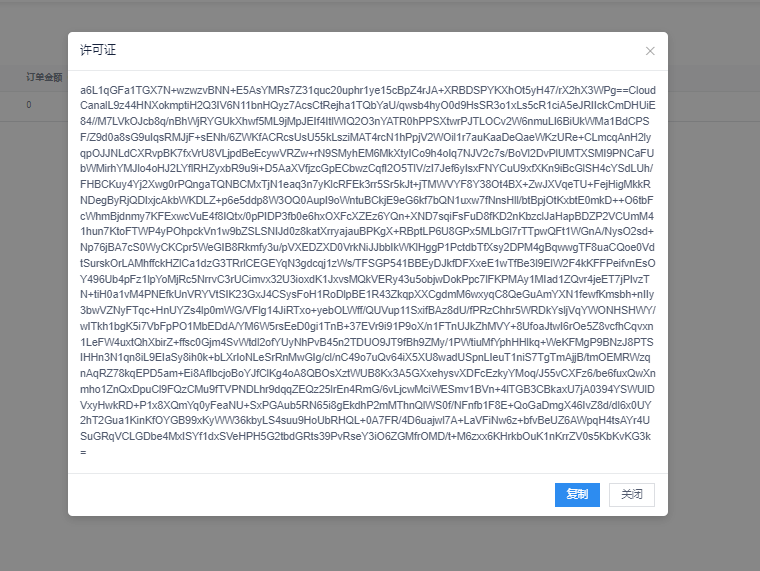
最后我们可以看到地址栏中的产品状态变成了 已激活

======= 如果你采用源码安装的话,还需要删除默认节点和添加机器的额外的步骤=====
先停止,后删除
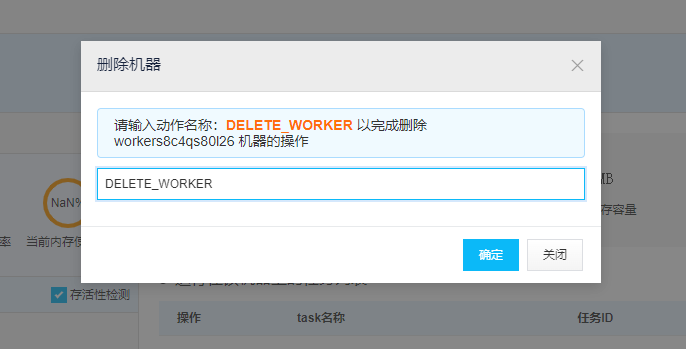
接下来,我们需要新增一台机器:
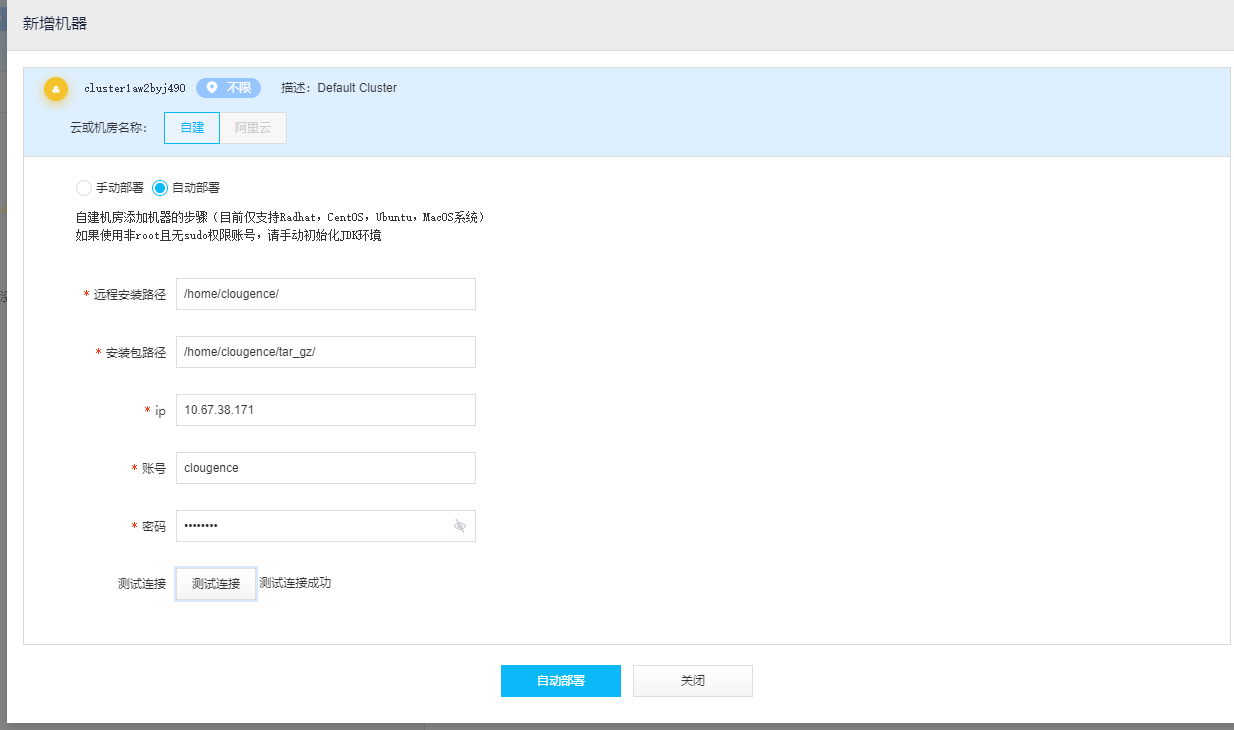
部署成功后机器显示
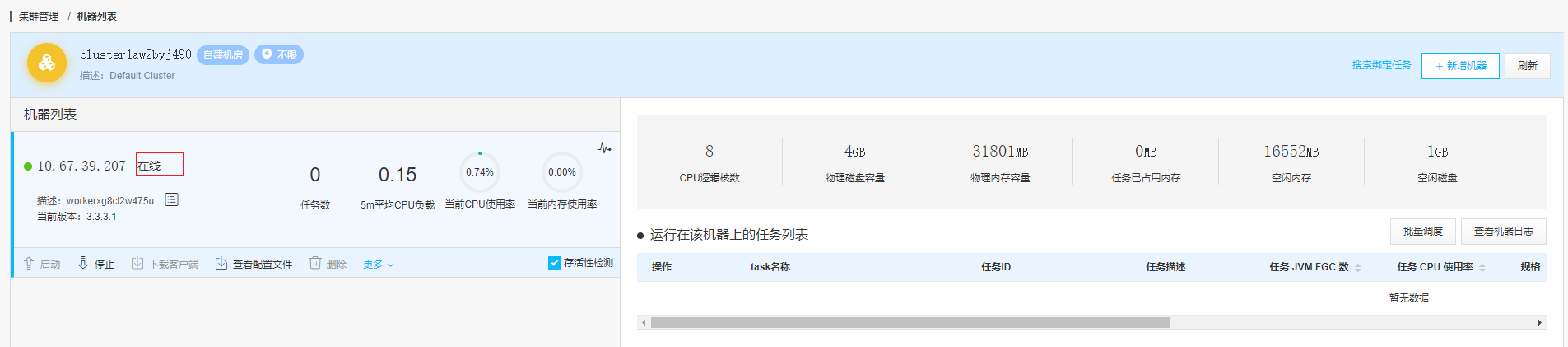
至此我们完成了安装和激活产品的步骤。
下面我们来部署一个任务: 数据源ORACLE (19.4.0.0.0)的表同步到Postgres 16.1
配置同步任务前的准备:
源端ORACLE:
1.需要打开archive log mode: (我的测试环境已经是打开的模式)
SYS@CN00C1CB> archive log list; Database log mode Archive Mode Automatic archival Enabled Archive destination USE_DB_RECOVERY_FILE_DEST Oldest online log sequence 211 Next log sequence to archive 213 Current log sequence 213
如果尚未打开参考命令:
shutdown immediate;
startup mount;
alter database archivelog;
alter database open read write;
2.开启数据库级别的supplemental logging
SYS@CN00C1CB> alter database add supplemental log data;
Database altered.
3.我们创建一张表,并打开别级别的supplemental logging
SYS@CN00C1CB> alter session set current_schema=jason;
Session altered.
SYS@CN00C1CB> create table sync_table(id number primary key, name varchar2(20), cdate date);
Table created.
SYS@CN00C1CB> alter table jason.sync_table add supplemental log data (all,primary key,unique) columns;
Table altered.
4.创建一个同步的账号
create user data_cdc_sync identified by "1234abcD";
grant create session, select_catalog_role, logmining, select any transaction, select any table to data_cdc_sync;
grant execute on sys.dbms_logmnr to data_cdc_sync;
grant execute on sys.dbms_logmnr_d to data_cdc_sync;
grant select on v_$archived_log to data_cdc_sync;
grant select on v_$logmnr_contents to data_cdc_sync;
grant select on v_$log to data_cdc_sync;
grant select on v_$logfile to data_cdc_sync;
grant select on v_$logmnr_logs to data_cdc_sync;
grant select,alter on jason.sync_table to data_cdc_sync;
目标端POSTGRES 16上创建一张表:
postgres=# \c db_cab
psql (12.3, server 16.1)
db_cab=# create user app_data_sync password 'app_data_sync';
CREATE ROLE
db_cab=# create schema app_data_sync authorization app_data_sync;
CREATE SCHEMA
db_cab=# \c db_cab app_data_sync
psql (12.3, server 16.1)
WARNING: psql major version 12, server major version 16.
Some psql features might not work.
You are now connected to database "db_cab" as user "app_data_sync".
db_cab=> create table sync_table (id bigint primary key, name varchar(20), cdate timestamp);
CREATE TABLE
接下来我们登陆web界面,分别创建数据库源端和目标端的数据源。

我们选择创建一个ORACLE的数据源:
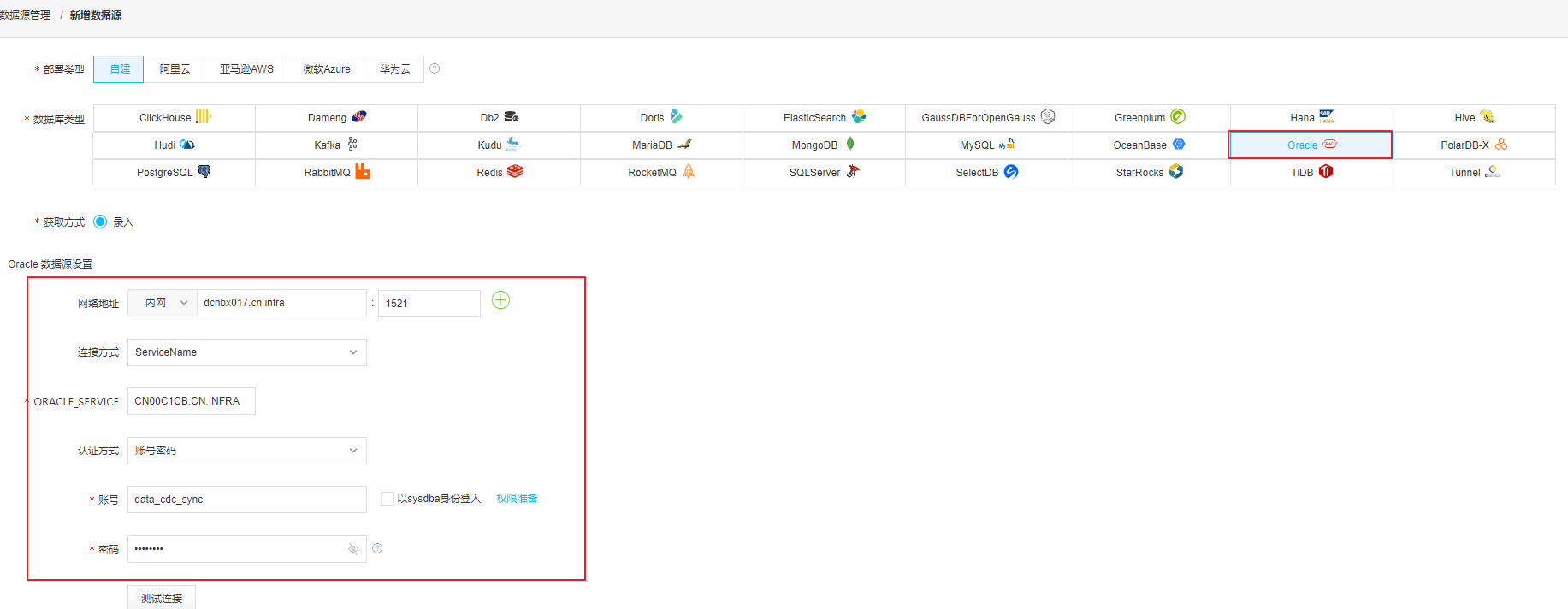
测试通过:
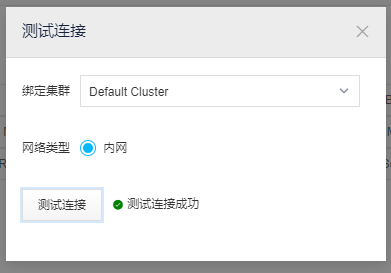
这个时候我们源端的ORACLE和目标端的PG都已经创建好了

下一步,我们创建同步任务:
我们在源端ORACLE插入1万条数据, 然后模拟一下初始化全量同步数据到postgres
SYS@CN00C1CB> begin
for i in 1..100000 loop
insert into sync_table select i , 'jason'||i, sysdate from dual;
end loop;
commit;
end;
/
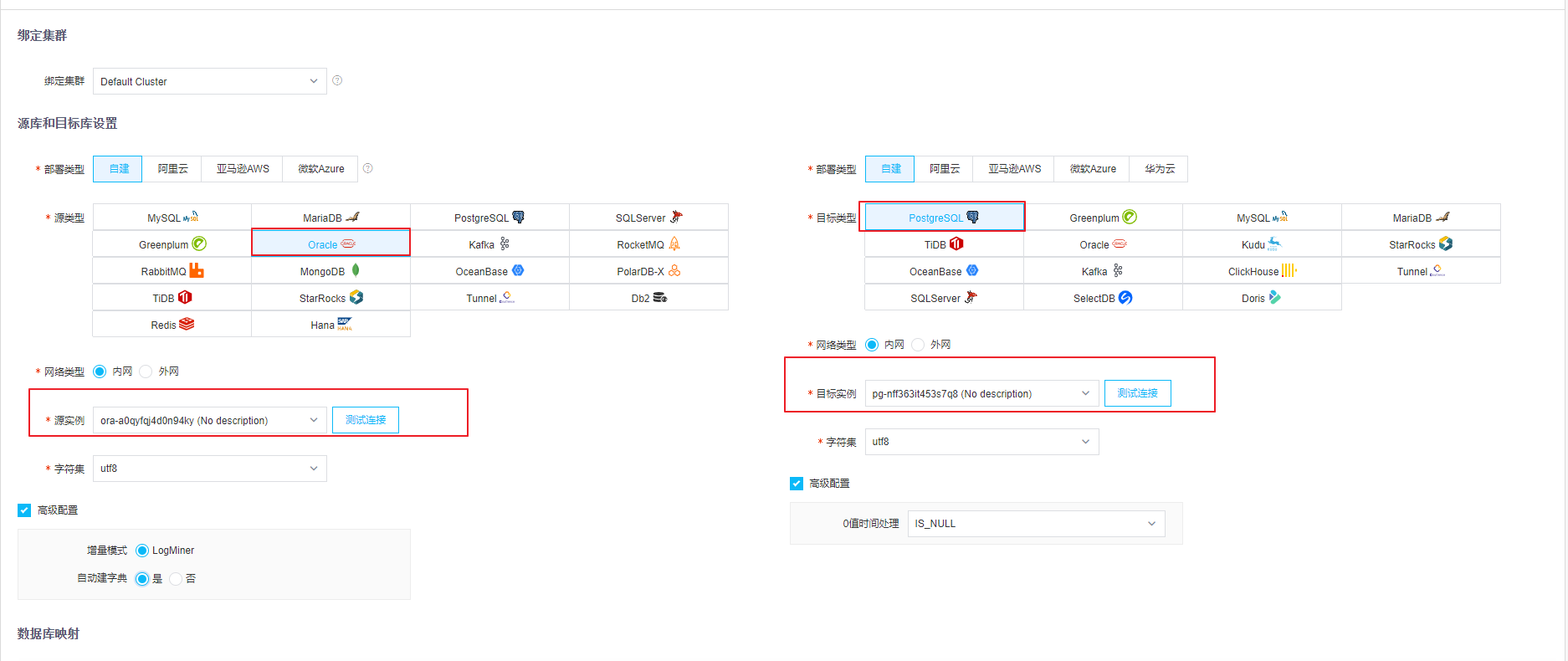
SCHEMA映射这块要选择正确:

我们选取全量同步,全量增强型, 选择全量8GB的最近性能模式
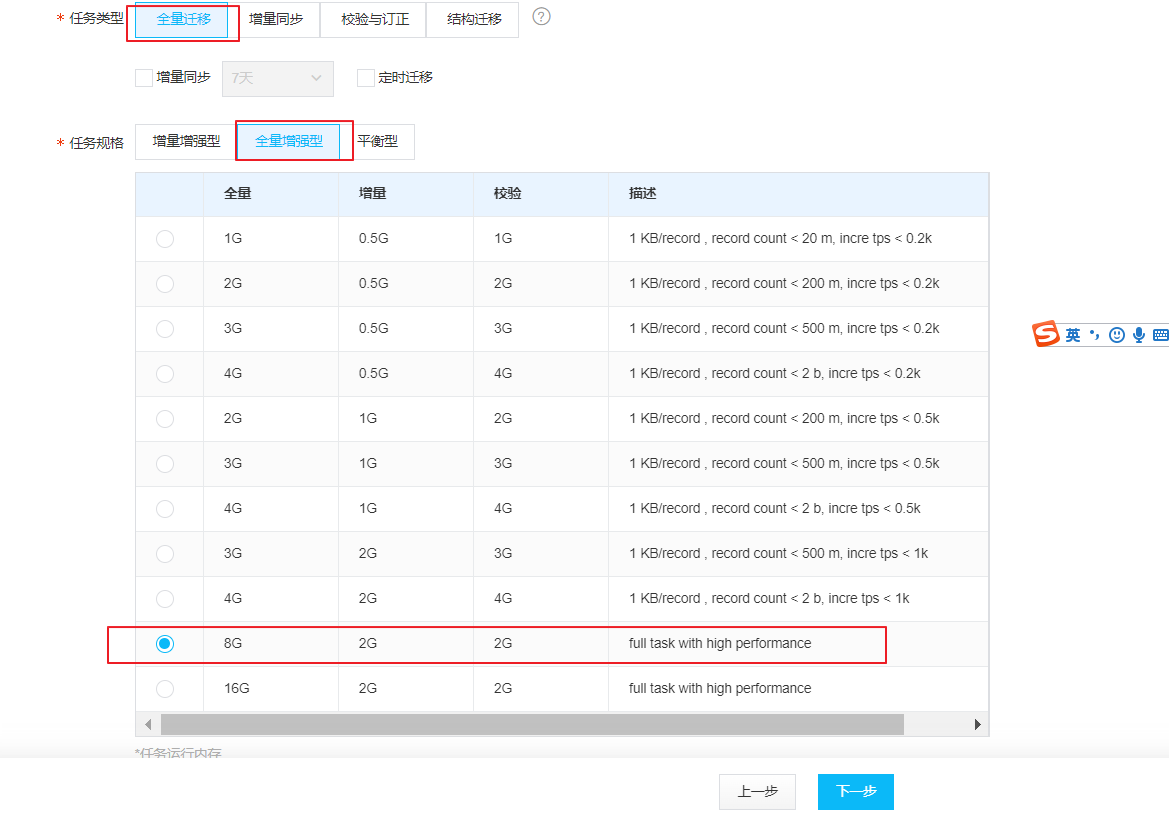
选择表
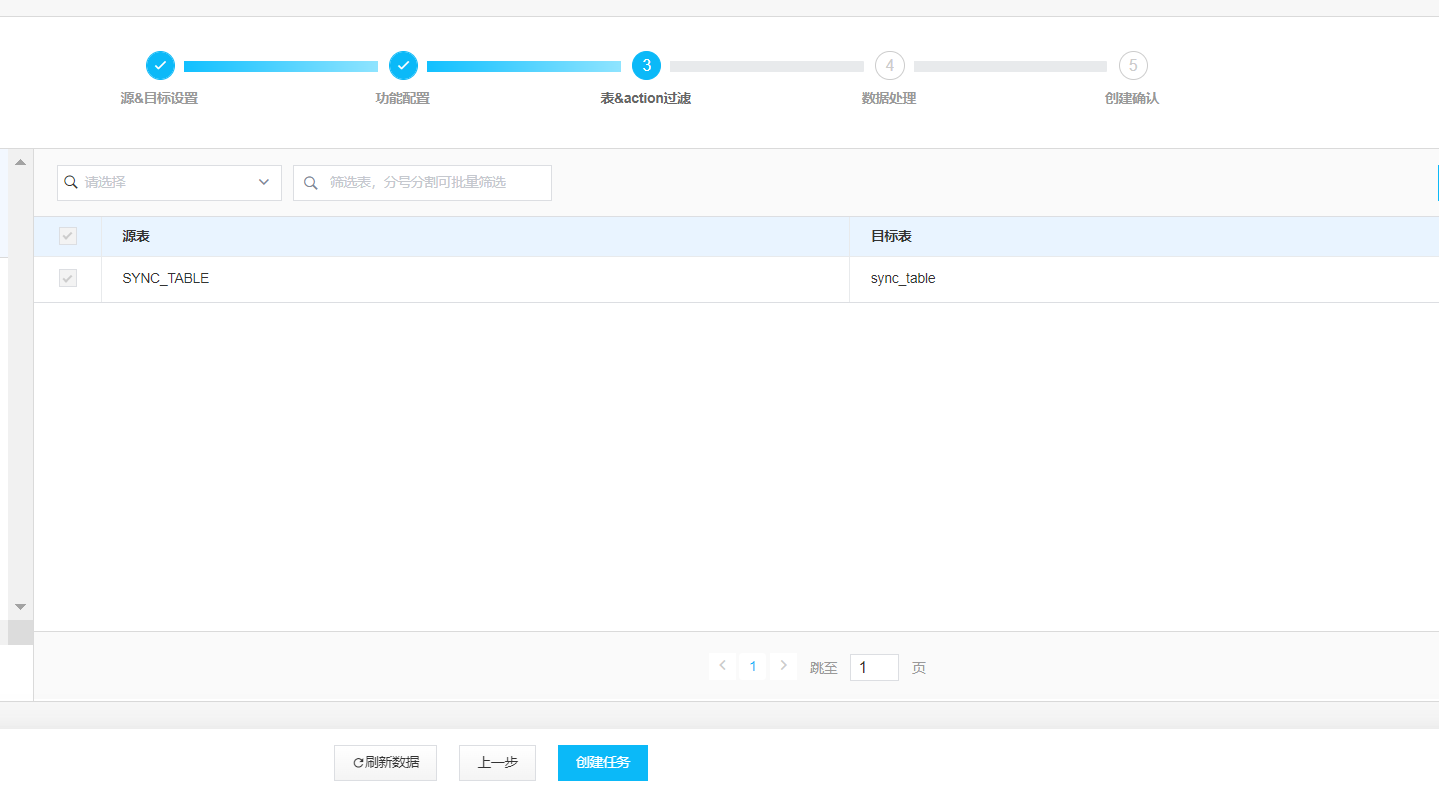
任务创建成功后,出现在列表中,我们点击启动任务
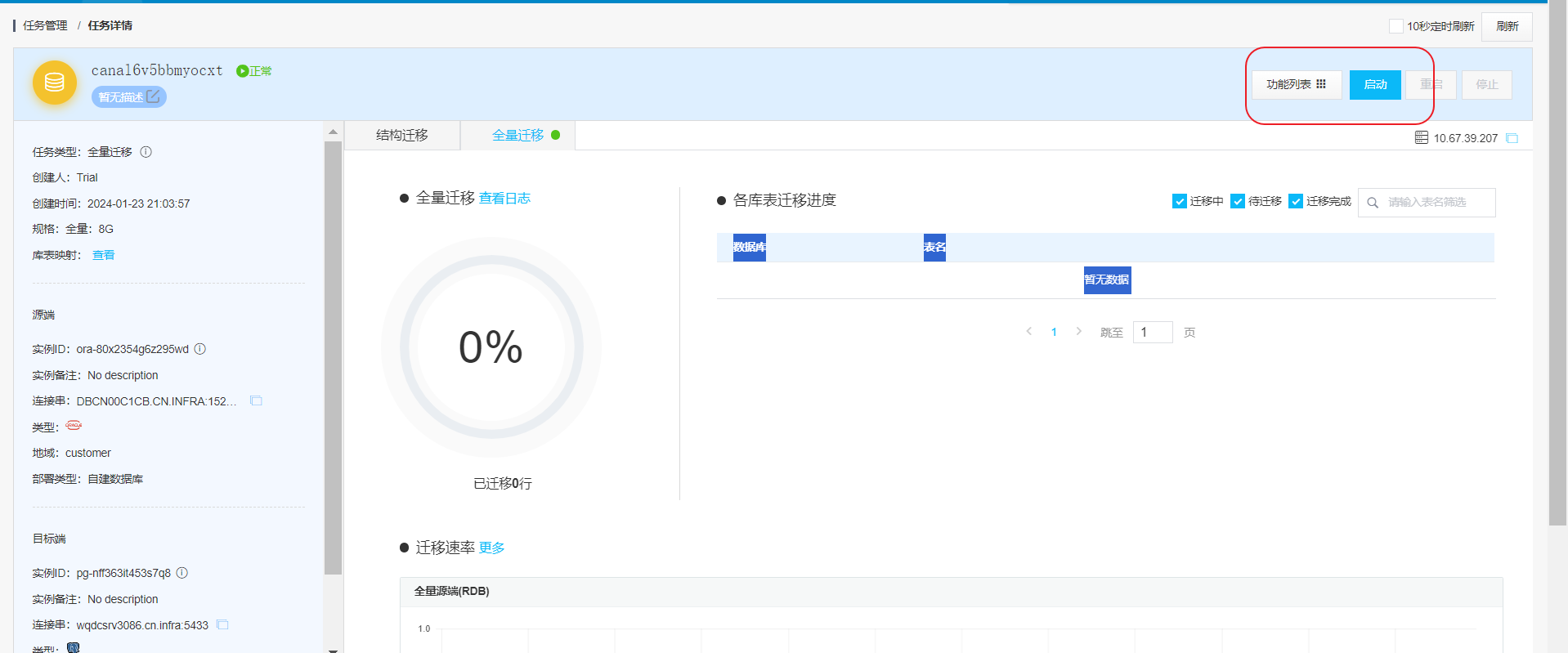
10万数据不算大,瞬间同步完成。
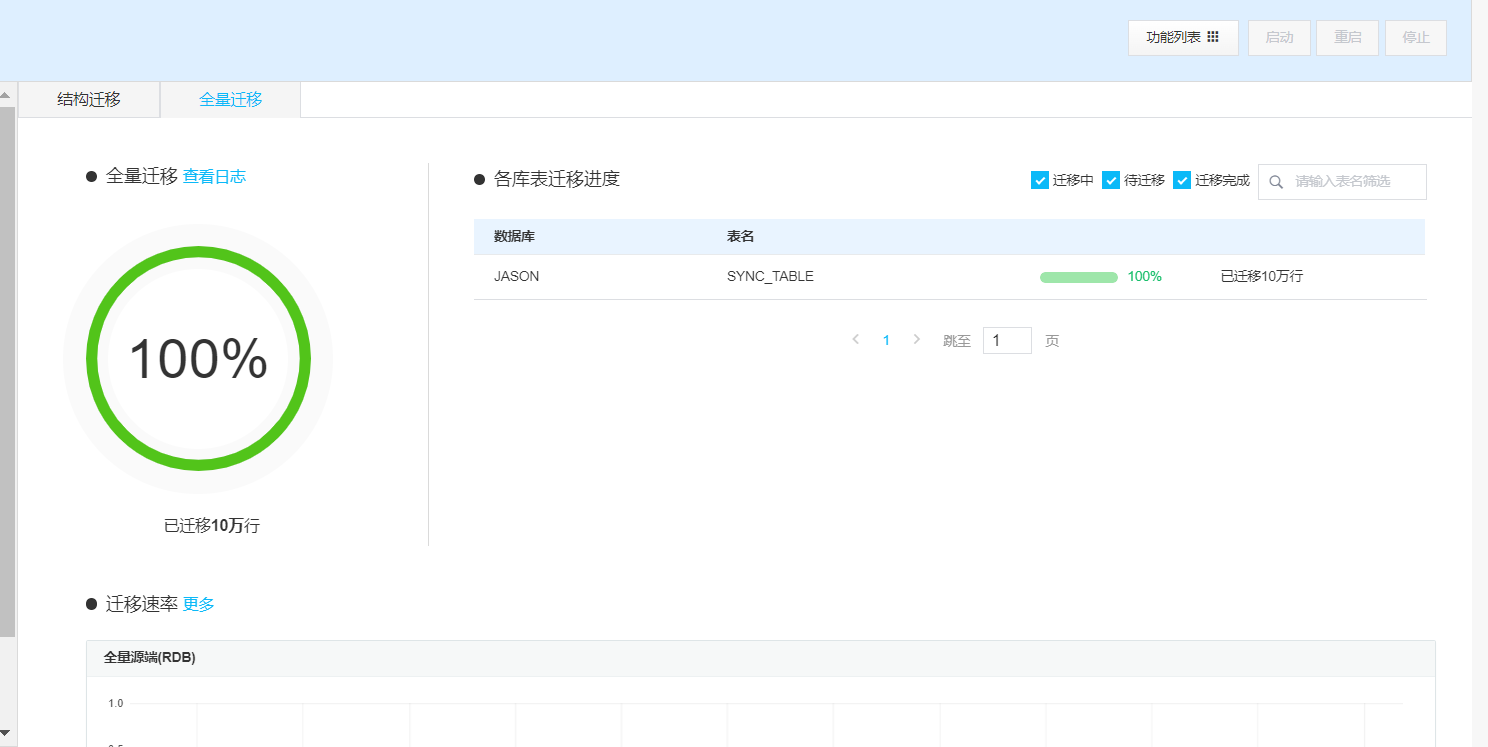
我们在测试一下基于SCN 点增量同步:
获得当前源端ORACLE的SCN:
SYS@CN00C1CB> select to_char(current_scn) from v$database;
TO_CHAR(CURRENT_SCN)
----------------------------------------
10387086027046
我们分别进行修改,删除,和插入操作:
SYS@CN00C1CB> delete from sync_table where id <= 100;
100 rows deleted.
SYS@CN00C1CB> update sync_table set name = 'new version jason', cdate = sysdate where id between 101 and 201;
101 rows updated.
SYS@CN00C1CB> begin
for i in 100001..200000 loop
insert into sync_table select i , 'jason'||i, sysdate from dual;
end loop;
commit;
end;
/ 2 3 4 5 6 7
PL/SQL procedure successfully completed.
SYS@CN00C1CB> commit;
Commit complete.
我们创建一个增量同步的任务 start scn = 10387086027046:
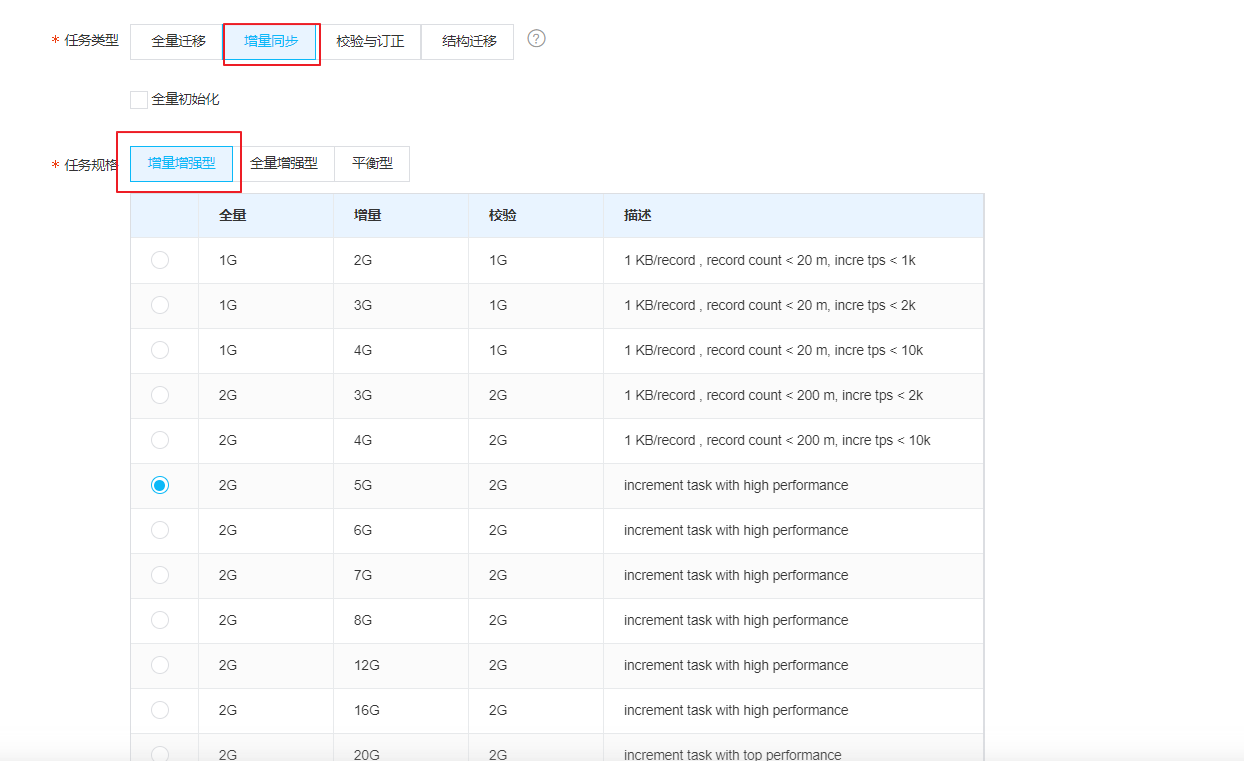
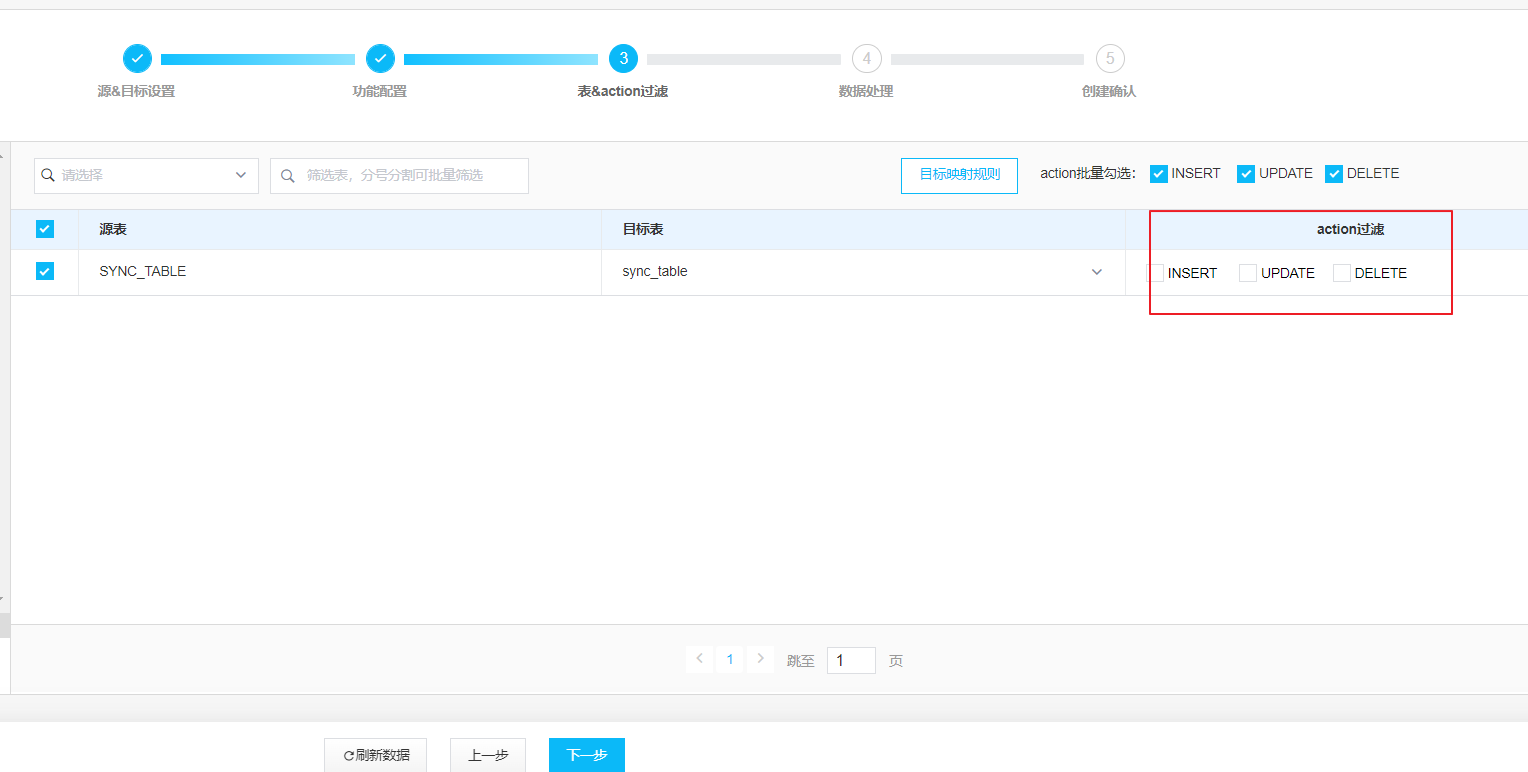
INSERT,UPDATE,DELETE 必须要勾选:
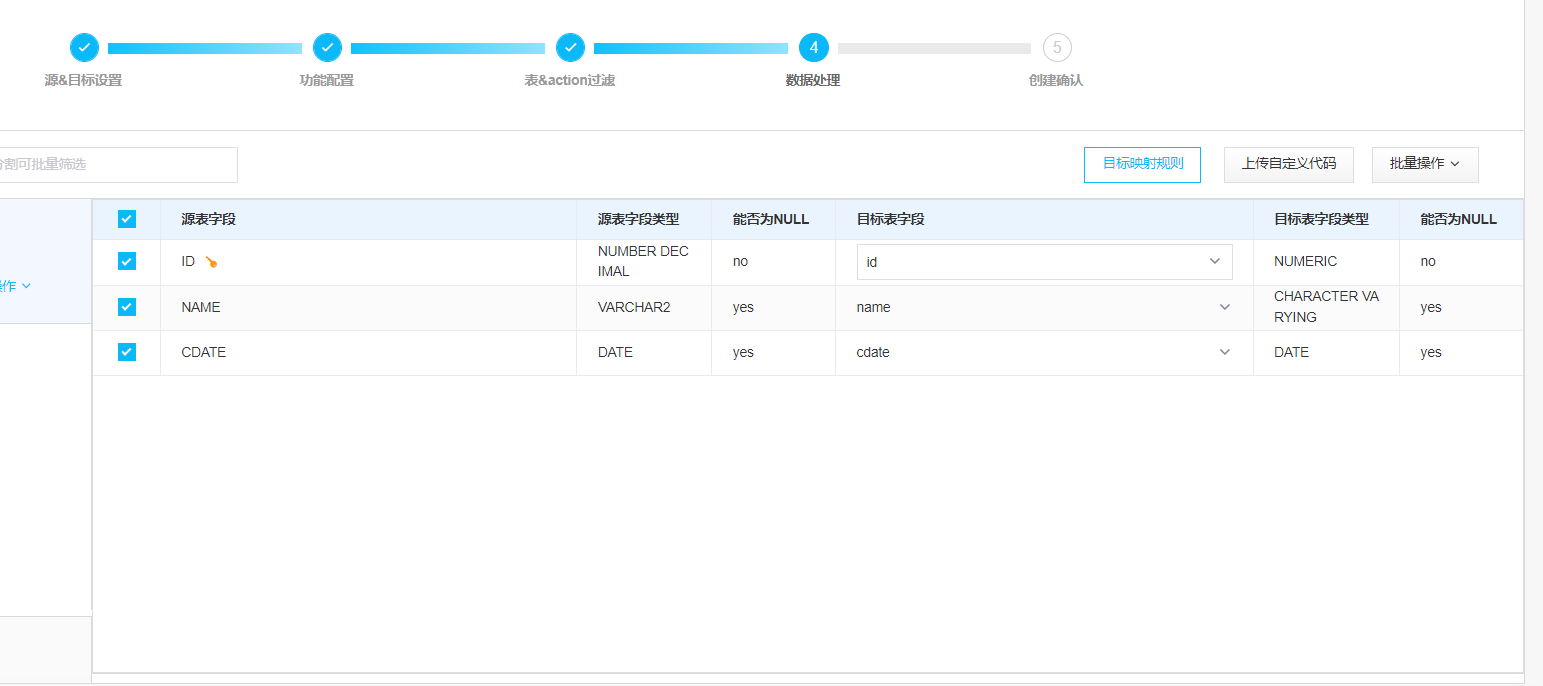
字段过滤:
创建任务:
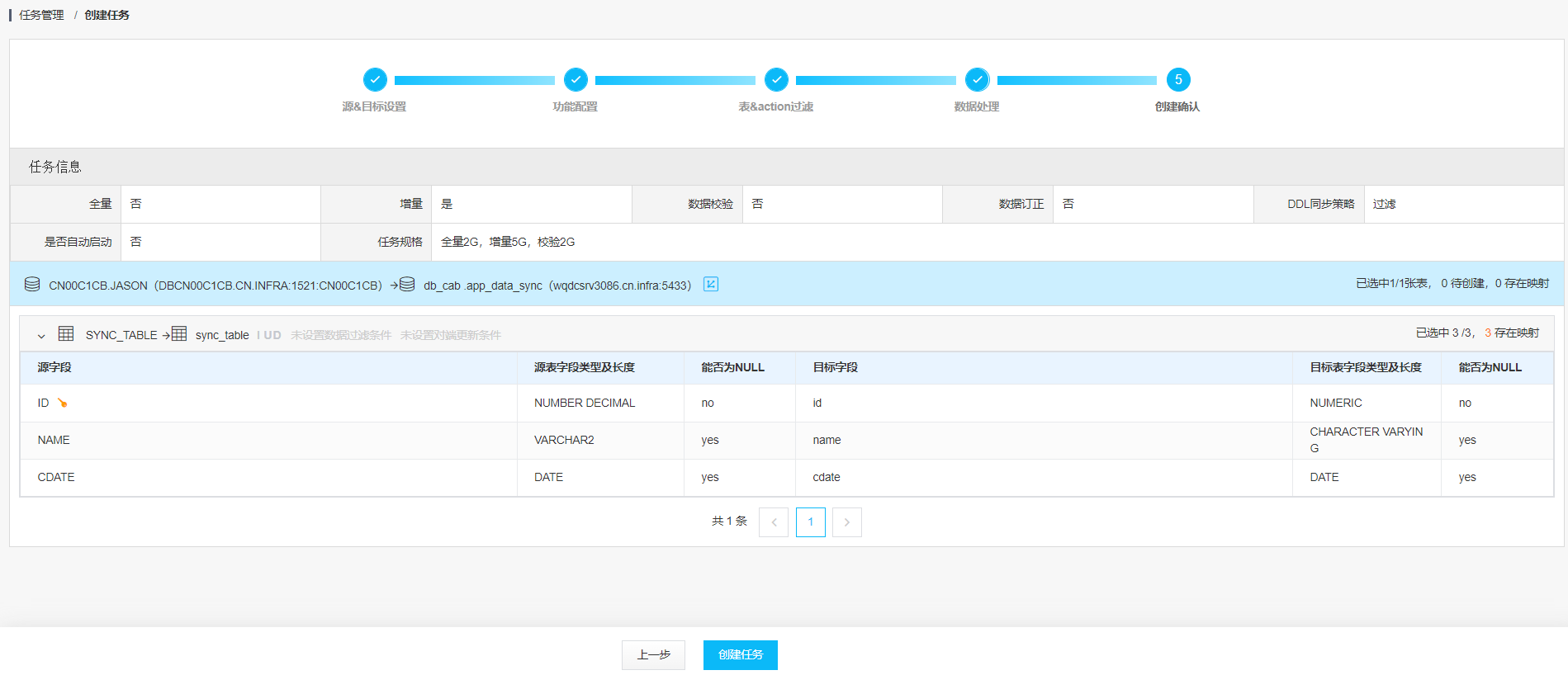
设置起始点SCN: 10387086027046
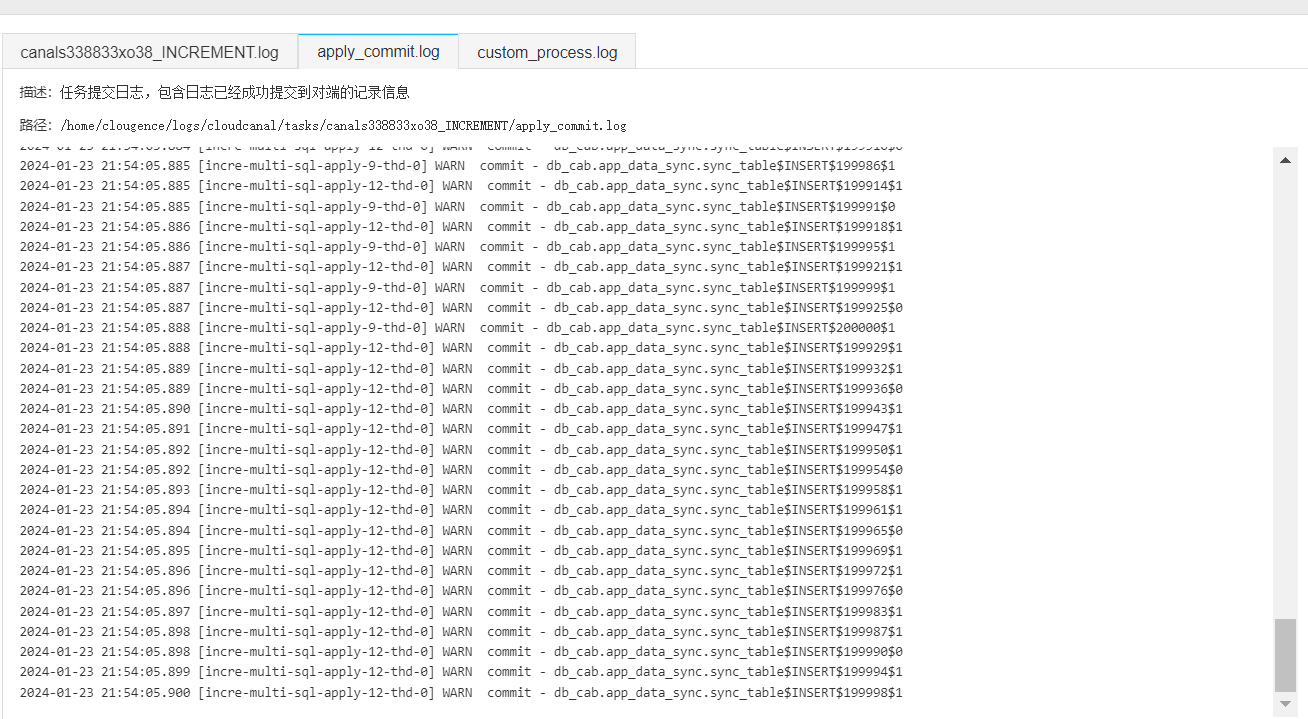
启动任务: 我们可以从commit-log 发现日志在同步
我们登陆目标端数据库PG进行手动校验: 数据是符合我们的预期的
db_cab=> select count(1) from sync_table where id <=100;
count
-------
0
(1 row)
db_cab=> select count(1) from sync_table where name = 'new version jason';
count
-------
101
(1 row)
db_cab=> select count(1) from sync_table;
count
--------
199900
(1 row)
接来下我们通过web自带的数据校验功能,来比较一下源端和目标端的数据是否一致。
我们创建一个全量校验的任务:
我们点击数据校验的按钮查看验证结果:
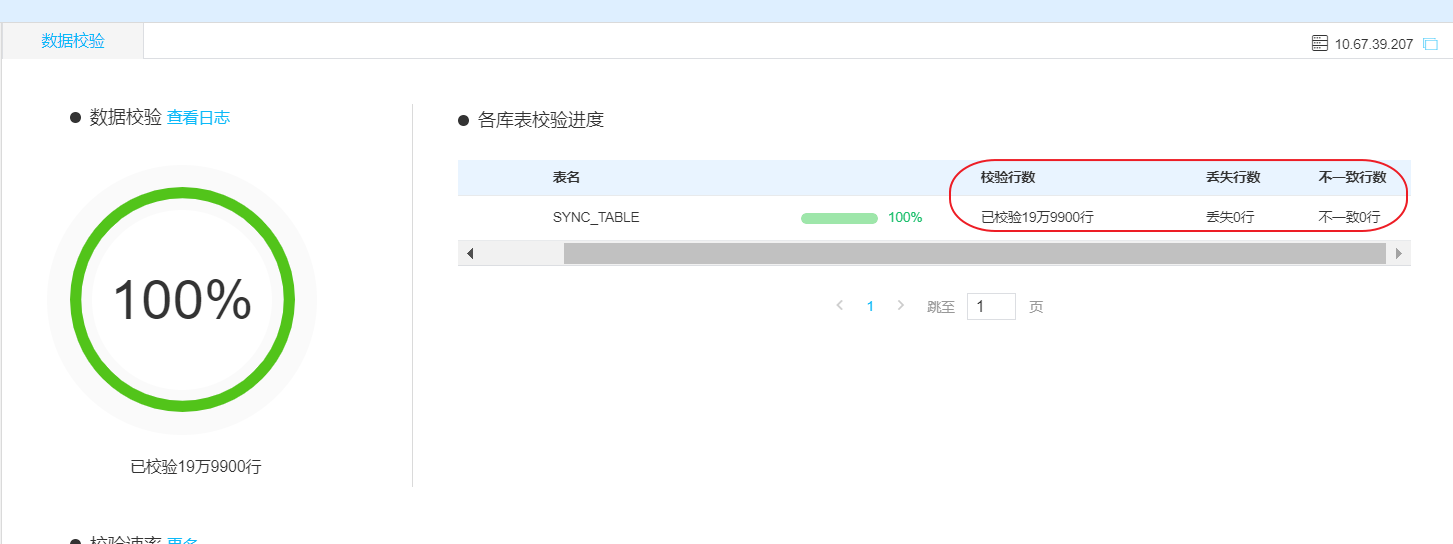
最后我们总结一下:
1.CloudCanal 作为中心化部署方式(非OGG经典模式的端对端方式),提供了容器部署(docker和K8S)和TGZ的多种部署方式。
2.CloudCanal 免费版可以支持5个任务,基本上满足测试环境的POC的任务。
3.CloudCanal 提供类似于阿里云DTS功能的服务web界面,可以选择全量,增量(ORACLE基于SCN number),数据校验和结构迁移等任务.
4.CloudCanal 支持的数据库种类很丰富,而且支持的大多数数据库的最新版。
Have a fun 😃 !
