




正撸着代码,突然收到客户的求助信息,说他们有一套PostgreSQL单机数据库最近两周每到周一就会变得很慢,平常秒级的sql慢到了10s左右,平常10s级别的SQL性能退化到了1000s级别,并且在故障期间,PG数据库服务器CPU出现飙升的现象。故障期间,系统基本上不可用,故障持续了1个多小时,现在领导要求对故障进行分析,找出PG数据库性能雪崩的罪魁祸首。
根据客户提供的性能监控工具,发现故障期间CPU一直维持在70%以上的高位

细看之下,发现故障期间IO WAIT占了40%以上,说明有大量的CPU在等待IO,进一步查看IO在故障期间的使用情况:
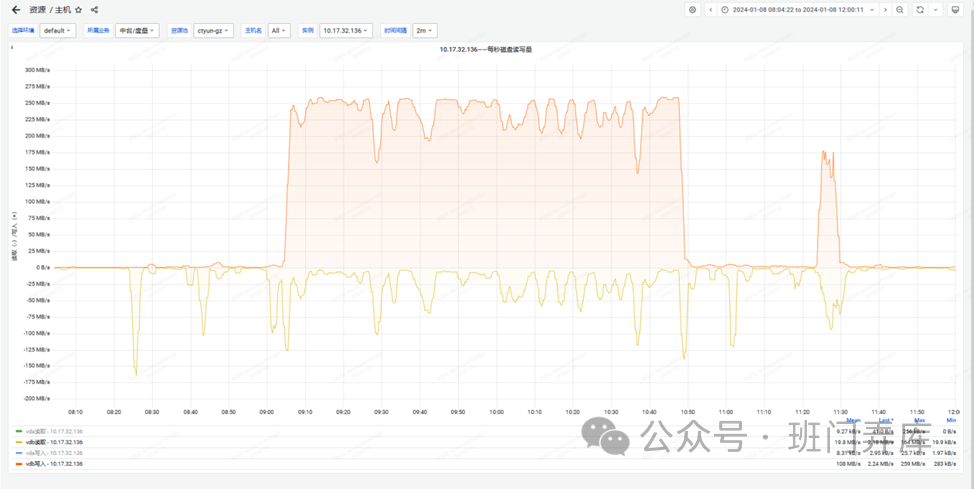
可以看到,故障期间VDB磁盘读写量急剧飙升,并且以写IO主,读IO相对较小,写IO每秒达到250M左右。除了IO量出现飙升以外,IO也表现出长时间的等待。
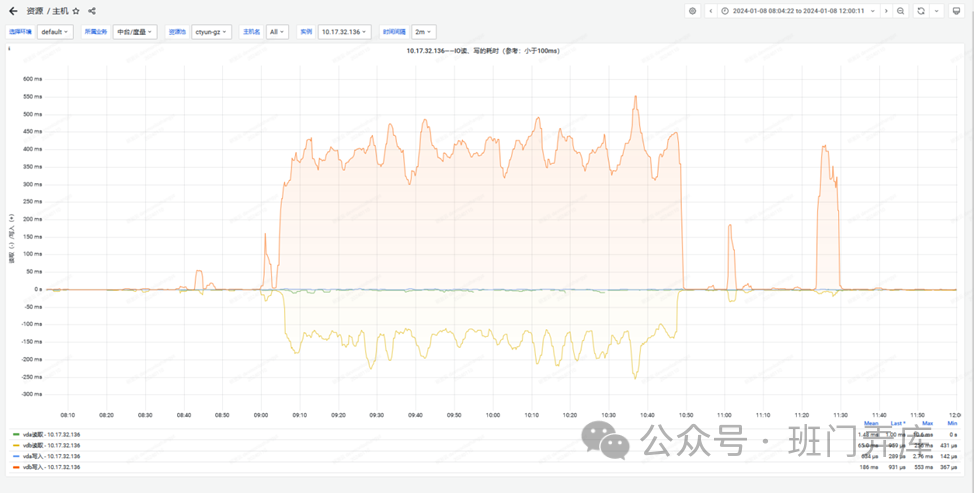
IO延迟竟然高达400多毫秒,这也可以解释为什么IO WAIT CPU占用达到40%以上,由于IO延迟较高,CPU一直在等待IO完成,从而陷入空转,导致CPU飙升。
既然是写IO量比较大,对于数据库来说,写IO一般涉及DML语句,进一步查看故障期间DML语句的情况:

可以看到在故障期间,PG数据库的insert、update、delete操作并不是很多:insert除了两个峰值达到每秒6000次外,其余时间大概只有每秒几个操作;update除了3个峰值达到每秒200次外,其余时间也只有每秒几个操作;delete操作在故障期间每秒都不超过10次执行。这三个操作在故障期间的执行量和故障期间连续的大量IO和高延迟的现象并不能匹配,可以暂时先排除是这三个操作的影响。
既然不是DML语句的影响,那PG数据库中还有什么操作会产生大量的写IO呢?
PG数据库产生写IO的类型主要是:写数据、写日志、写临时文件。一般DML语句会同时导致写数据和写日志,由于故障期间DML语句的执行量并不是很大,基本上可以排除掉写数据和写日志的情况。那么故障期间临时文件的读写情况怎么样呢?
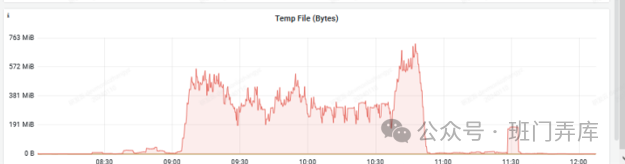
可以看到,在故障期间,存在大量的临时文件读写IO,基本上和操作系统IO读写量在一个级别上。至此,我们可以判断在故障期间,大量的IO读写来自于临时文件的读写。那么问题又来了,在故障期间,PG数据库为什么会产生大量的临时文件读写呢。我们知道,在PostgreSQL数据库中,临时文件一般是用来处理查询和排序操作时所创建的临时文件。这些文件主要用于存储中间结果集或执行排序操作,以便在查询执行过程中进行临时存储和处理数据。但对于每个会话,PG数据库都会设置一个work_mem,如果处理查询或排序的内存使用量超过work_mem参数设置的大小,就会使用临时文件来保存中间结果或磁盘排序,这个时候就会产生临时文件。
为了证实上述猜想,查看PG数据库的work_mem参数设置:

每个会话的work_mem最大为8M,一旦使用超过8M,就会产生临时文件。由于在故障期间每秒会产生大约300M的临时文件,可见当时存在大量的磁盘排序或运行了大查询。
由于客户未提供相关的SQL信息,我也只能分析到这了。不过分析至此,问题大致基本上也清楚了,因为SQL的原因产生了大量的临时文件,从而产生了大量的文件IO,而由于IO延时较高,IO迟迟不能完成,从而导致大量的CPU在等待IO完成,从而使CPU飙升,CPU飙升再加上IO缓慢造成了数据库的性能急剧下降,从而产生了本次故障。
将结论反馈给客户,同时建议他将当前设置的偏小的work_mem值调整为32M。由于work_mem对每于每个连接都有一份,当前128G的内存也比较充足,可以设置的大一点,尽量在内存中进行排序或保存查询的中间结果。但也不宜设置的太大,避免因为会话数太多从而导致内存不足的问题。
通过这个故障案例,可以总结一下,在分析PG数据库IO问题时,要先明确数据库IO的来源,而DML操作、排序、大查询等都可能会产生大量的物理IO。但一般主要的排查顺序:先看DML操作、再看排序、最后再看是否是大查询等,一旦确定了物理IO的来源,再进行针对性的分析即可定位问题。
