




GPT系列模型更新
最近OpenAI推出了新一代的嵌入式模型,全新的GPT-4 Turbo和审查模型。
https://openai.com/blog/new-embedding-models-and-api-updates
其中比较引人关注的是推出了两款全新的嵌入式模型:一个是更小、高效的text-embedding-3-small模型,另一个是更大、更强大的text-embedding-3-large模型。嵌入模型是检索增强生成(RAG)的必备环节。
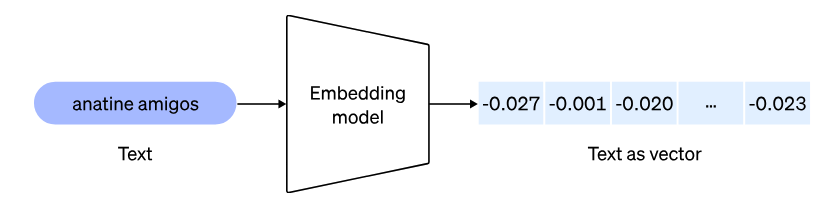
在博客中OpenAI声称两款新嵌入式模型都采用新的技术进行训练,使开发人员可以在使用嵌入式时在性能和成本之间进行权衡。可以通过传递维度API参数来缩短嵌入维度,而不会使嵌入式失去其表示概念的特性。
在MTEB基准测试中,text-embedding-3-large
嵌入维度可以缩短到256的大小,仍然能够胜过一个嵌入维度1536的text-embedding-ada-002
模型。
| text-embedding-3-small | text-embedding-3-large | |
|---|---|---|
| 嵌入维度 | 512 | 1536 |
| MTEB得分 | 61.6 | 62.3 |
OpenAI 所使用的「缩短嵌入」方法,随后引起了研究者们的广泛注意。人们发现,这种方法和 2022 年 5 月的一篇论文所提出的「Matryoshka Representation Learning」方法是相同的。
https://arxiv.org/abs/2205.13147
可扩展的特征编码
Matryoshka Representation Learning(MRL)
的是一种学习表示方法,用于服务于多种下游任务。在训练这种表示时,通常情况下每个下游任务的计算和统计约束是未知的。
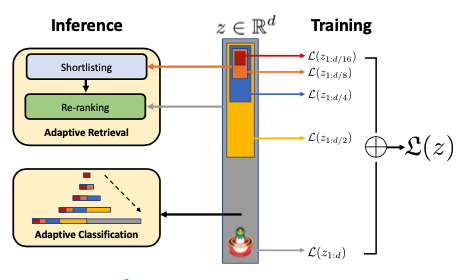
论文提出了一个问题:我们是否可以设计出一种灵活的表示方法,能够适应具有不同计算资源的多个下游任务?**
MRL在不同的粒度上编码信息,并允许单个嵌入适应下游任务的计算约束,在推断和部署过程中不会增加额外成本。 MRL学习了粗粒度到细粒度的表示,至少与独立训练的低维度表示一样准确且丰富。
对于ImageNet-1K分类,嵌入大小可以减少多达14倍,而准确度保持不变; 对于ImageNet-1K和4K的大规模检索,速度提升多达14倍; 对于长尾少样本分类,准确度提高多达2%,同时保持与原始表示一样的稳健性。 MRL可以无缝扩展到Web规模的数据集,如视觉(ViT,ResNet),视觉+语言(ALIGN)和语言(BERT)等。
MRL原理
MRL旨在学习具有多个粒度的表示,以适应不同的任务和数据特征。
表示大小和多粒度学习
对于给定的表示大小,MRL考虑了一个表示大小的集合,其中每个元素表示一个嵌入的维度。MRL通过一个深度神经网络来学习一个维的表示向量,其中是可学习的参数。中的每个维度都可以独立地表示数据点的转移性和通用性。
损失函数和优化
MRL通过标准的经验风险最小化来优化每个嵌套维度的多类分类损失。 具体而言,针对每个,MRL使用一个独立的线性分类器,其中是标签的数量。损失函数通过加权求和来聚合每个嵌套维度的损失,权重由参数控制。
效率改进和适应性
MRL提出了Efficient Matryoshka Representation Learning(MRL-E)
变体,通过在所有线性分类器之间进行权重绑定来减少内存消耗。此外,MRL可以无缝适应大规模表示学习框架,并可以应用于不同的学习范式,如自监督学习和对比学习。
MRL代码
Matryoshka Cross-Entropy Loss
class Matryoshka_CE_Loss(nn.Module):
def __init__(self, relative_importance, **kwargs):
super(Matryoshka_CE_Loss, self).__init__()
self.criterion = nn.CrossEntropyLoss(**kwargs)
# usually set to all ones
self.relative_importance = relative_importance
def forward(self, output, target):
loss=0
for i in range(len(output)):
loss+= self.relative_importance[i] * self.criterion(output[i], target)
return loss
MRL Linear Layer
class MRL_Linear_Layer(nn.Module):
def __init__(self, nesting_list: List, num_classes=1000, efficient=False, **kwargs):
super(MRL_Linear_Layer, self).__init__()
self.nesting_list = nesting_list # set of m in M (Eq. 1)
self.num_classes = num_classes
self.is_efficient = efficient # flag for MRL-E
if not self.is_efficient:
for i, num_feat in enumerate(self.nesting_list):
setattr(self, f"nesting_classifier_{i}", nn.Linear(num_feat, self.num_classes, **kwargs))
else:
# Instantiating one nn.Linear layer for MRL-E
setattr(self, "nesting_classifier_0", nn.Linear(self.nesting_list[-1], self.num_classes, **kwargs))
def forward(self, x):
nesting_logits = ()
for i, num_feat in enumerate(self.nesting_list):
if self.is_efficient:
efficient_logit = torch.matmul(x[:, :num_feat], (self.nesting_classifier_0.weight[:, :num_feat]).t())
else:
nesting_logits.append(getattr(self, f"nesting_classifier_{i}")(x[:, :num_feat]))
if self.is_efficient:
nesting_logits.append(efficient_logit)
return nesting_logits
实验对比
表示学习
首先将MRL应用于各种表示学习设置,通过线性分类/探测(LP)和1-最近邻(1-NN)准确度来评估学习到的表示的质量和容量:
视觉的监督学习:在ImageNet-1K上使用ResNet50,以及在JFT-300M上使用ViT-B/16 视觉+语言的对比学习:在ALIGN数据上使用包含ViT-B/16视觉编码器和BERT语言编码器的ALIGN模型 掩码语言建模:在英文维基百科和BooksCorpus上使用BERT
图像分类
在ImageNet-1K上训练和评估的ResNet50模型的线性分类准确度,实验结果表明,MRL模型在每个维度大小上至少与每个FF模型(常规训练的模型)一样准确,而MRL-E则在16维以上处于1%以内。
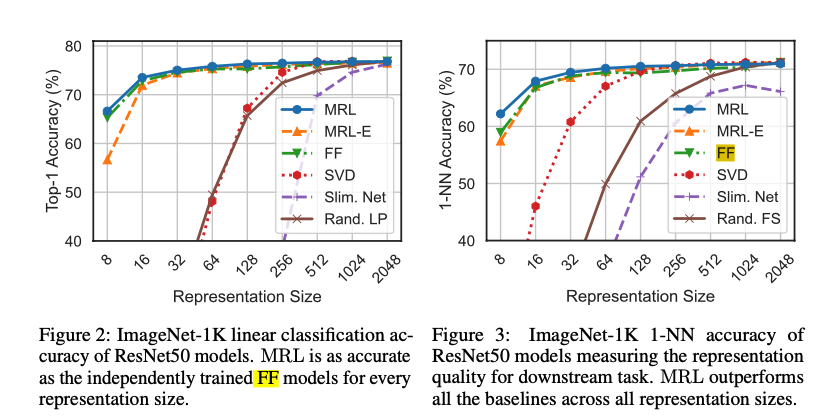
通过在ImageNet-1K上进行1-NN准确度评估来展示了学习表示质量的比较。MRL在较低维度时比固定特征的对应部分准确度高达2%。
自适应分类
MRL 不需要多个昂贵的神经网络前向传播。在 ImageNet-1K 上级联 MRL 表示(MRL-AC)和独立训练的固定特征(FF)模型之间的比较,所有 MRL-AC 模型在相当的表示大小上都比 FF 基线要准确得多。
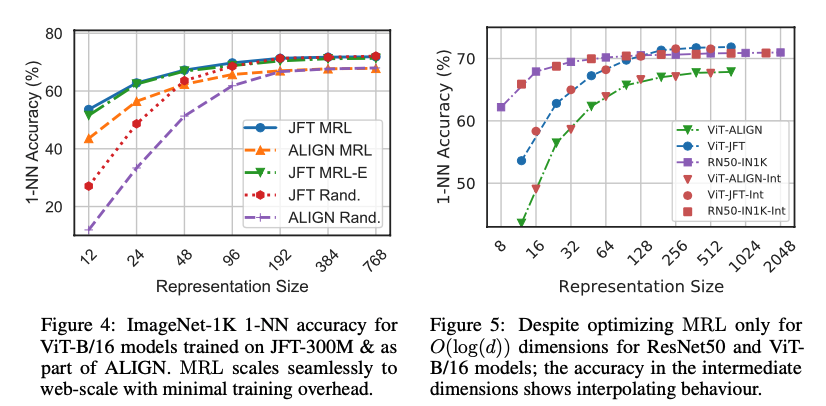
图像检索
ResNet50 的单次前向传播成本4 GFLOPs
,而精确检索每个查询的成本为2.6 GFLOPs
。尽管检索开销占总成本的 ,但检索成本随数据库大小的增加而线性增长。
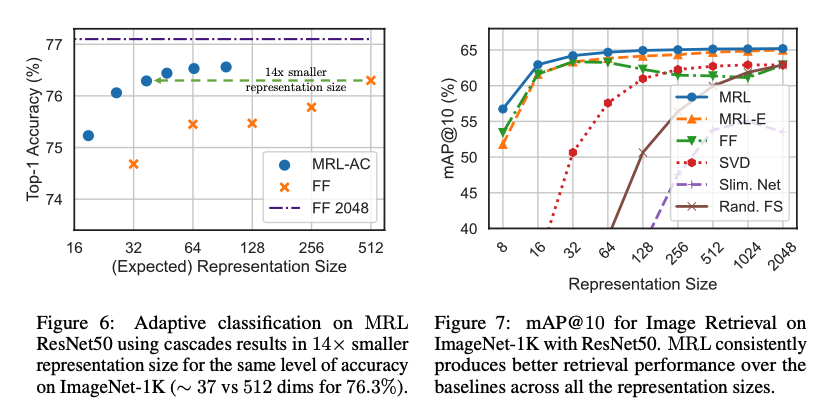
在ImageNet-1K 上的 mAP@ 10 性能,MRL、MRL-E、FF、可压缩网络以及使用 SVD 和随机特征选择的后续压缩的矢量。MRL通常是最准确的,而且比 FF 基线高出多达 3%.
少样本和长尾学习
MRL 学习的表示在不同 shots 和类别数量下的表现与 FF 表示相当。MRL 在分布尾部的新颖类上提供了高达 的准确度提升,而不会牺牲其他类别的准确度。
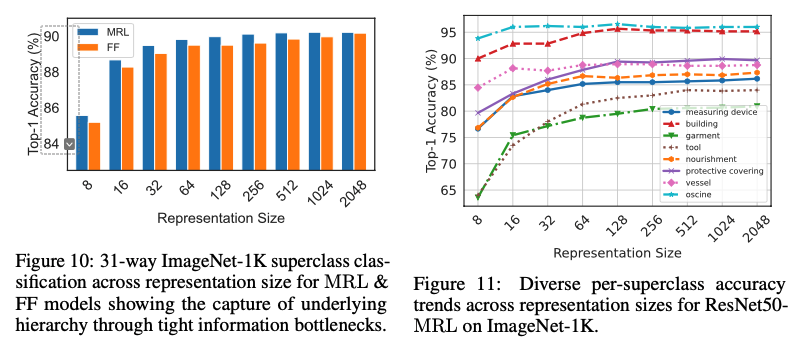
MRL方法总结
MRL思路比较简单,并且对模型的网络结构并没有过多修改,有较强的普适性。 MRL可以在单个嵌入向量中以多个粒度编码信息,使得 MRL 能够适应下游任务。 MRL需要在原有模型的基础上增加额外的分类层,因此会增加少量的计算复杂度。 在部署中MRL并不会因为编码维度而带来时间复杂度的差异,因为都需要完成整个正向传播。

