




赛题名称:学术文档要素分类挑战赛 赛题任务:对多种版式下的文档图像、要素位置及其文本内容进行分类 赛题类型:文档多模态分析
比赛链接:https://challenge.xfyun.cn/topic/info?type=academic-documents
答辩视频:https://www.bilibili.com/video/BV1nb4y1T7kr
赛事背景
随着数字化时代的发展,人们越来越依赖电子文档来记录、传递和分享信息。在学术场景中,文档的要素包括标题、作者、邮箱、参考文献、正文、图片、表格等,它们都是文档中不可或缺的元素。然而,在实际应用中,需要将这些要素进行分类,以便更好地管理和利用文档。例如,在学术出版机构中,需要将一篇文章中的标题、作者、摘要、正文、参考文献等进行识别与分类。
针对这个问题,本次比赛——“学术文档要素分类挑战赛”,旨在通过利用机器学习和深度学习等先进技术,在给定学术文档图像、要素位置和文本内容的情况下进行要素分类,从而实现对学术文档的结构恢复与自动化整理。该比赛涉及14种不同的分类类别,包括标题、作者、邮箱、章节标题、正文、图片、表格等。
本次比赛旨在为学术文档要素分类问题提供一个交流和切磋的平台,促进相关领域的研究和应用。希望通过本次比赛的努力,可以进一步为学术文档分类领域的研究和应用做出一定的贡献,提高分类的准确性和效率。
赛事任务
尽管在学术文档分类领域,已经有许多相关的研究成果,但是要素分类仍然是一个具有挑战性的问题。在实际应用中,许多学术文档中的要素种类繁多,位置和大小不一,同时还存在一定的混淆和噪声,这对于算法的准确性和鲁棒性都提出了更高的要求。因此,本次比赛将提供一个具有挑战性的数据集,以检验参赛者算法的准确性和鲁棒性。数据集中将会包含来自多个学科、多种版式下的文档图像、要素位置及其文本内容,比赛者需要构建分类系统来对各个要素进行分类。
数据说明
本次比赛为参赛选手提供了4类数据:文档图像、要素位置、文本内容、分类类别。文档图像为原始论文的PDF文件转换而成的图片,要素位置通过矩形框的左上、右下坐标给出,文本内容指由矩形框中的文本解析结果,分类类别一共包含标题、作者、邮箱、章节标题、正文、图片、表格在内的14种类别。训练数据包含来自500份文档的7043张文档图像,选手可以自由划分训练、验证集进行模型训练。此次比赛只包含一个阶段,测试集不含分类类别,其他的内容均与训练集数据相同。
| 数据类别 | 变量名称 | 数值格式 | 解释 |
|---|---|---|---|
| 文档图像 | 无 | png | 论文PDF文件通过PDF2IMG转换而成的图片 |
| 要素位置 | box | list of int | [x1,y1,x2,y2],(x1,y1)为矩形框左上角坐标,(x2,y2)为矩形框右下角坐标 |
| 文本内容 | text | string | 矩形框中的文本解析结果 |
| 分类类别 | class | string | 包含标题、作者、邮箱、章节标题、正文、图片、表格在内的14种类别 |
分类类别说明如下:
| 分类类别名称 | 解释 |
|---|---|
| title | 文章的主标题,一般只在首页出现 |
| author | 文章的作者名字 |
| 文章作者的联系方式 | |
| affiliation | 文章作者的所属机构 |
| section | 章节标题 |
| fstline | 段落的首行文本 |
| paraline | 段落中的其他行文本 |
| table | 表格区域 |
| figure | 图像区域 |
| caption | 图像或者表格的描述文本 |
| equality | 独立的公式区域 |
| footer | 页脚,例如页数、期刊名称等,位于页面正下方 |
| header | 页眉,例如页数、论文标题等,位于页面正上方 |
| footnote | 文章内容的注释,例如链接、作者信息等,位于正文区域的左下方或者右下方 |
评价指标
本模型依据提交的结果文件,采用对所有类别的F1-score取平均得到的Macro-F1-score进行评价。别) , (模型将X类别的要素预测为其他类别)
通过第一步的统计值计算该类别要素的precision和recall, 计算公式如下:
通过第二步计算结果计算该类别要素的F1-score, 计算方式如下:
通过第三步计算结果, 计算所有类别要素的 的平均值作为最终评价指标, 计算方式如下, 此处 , 含义为类别数:
优胜方案
第一名
第一名的解决方案主要采用了一个基于VSR(Vision Semantic Releasing)方案的模型。这个方案于2021年提出,通过对文档图像中的文本内容和空间布局进行多模态分析和分类。
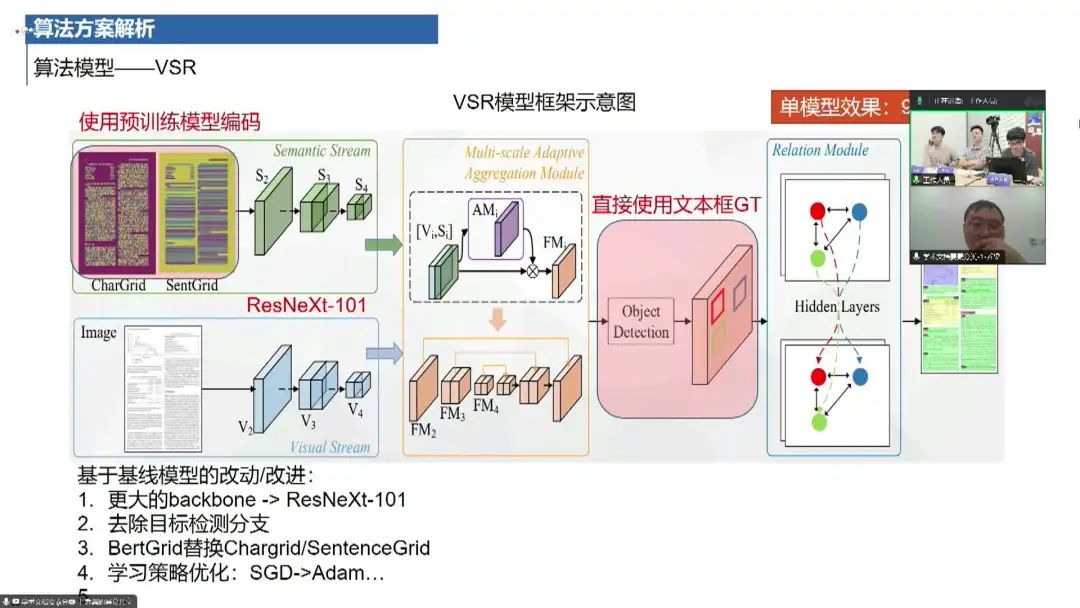
模型架构:采用了一个双分支网络结构。其中一个分支是语义分支,负责对文本进行编码,构建二维语义图,并提取空间上的语义信息;另一个分支是视觉分支,负责对原始图像进行视觉特征提取。 特征融合:两个分支之后进行多尺度特征融合,以获得更丰富和更准确的特征表达。 关系建模:采用了一个关系模型,构建了节点之间的图网络,利用隐层节点之间的关系进行特征增强和分类。 无监督预训练:在模型训练中,可能采用了无监督或半监督的预训练策略,以提高模型的泛化能力和鲁棒性。 模型改进:对原始模型进行了一些改进,包括更大的主干网络、引入外部数据进行训练、样本均衡和样本扩增等技巧,以提升模型性能。 多模型融合:采用了多模型融合的方法,使用了五个不同的模型(如BERT、DeBERTa等)进行投票,以提高分类准确性。 结果分析:该解决方案在单模型效果上可以达到95%到95.7%的准确率水平,在多模型投票后达到了96.88%的准确率。 工程实现:针对具体问题进行了工程上的优化,如类别均衡、样本扩增策略等,以提高模型的鲁棒性和泛化能力。 资源消耗:训练该模型需要大约两天的时间,在A100服务器上运行。
第二名

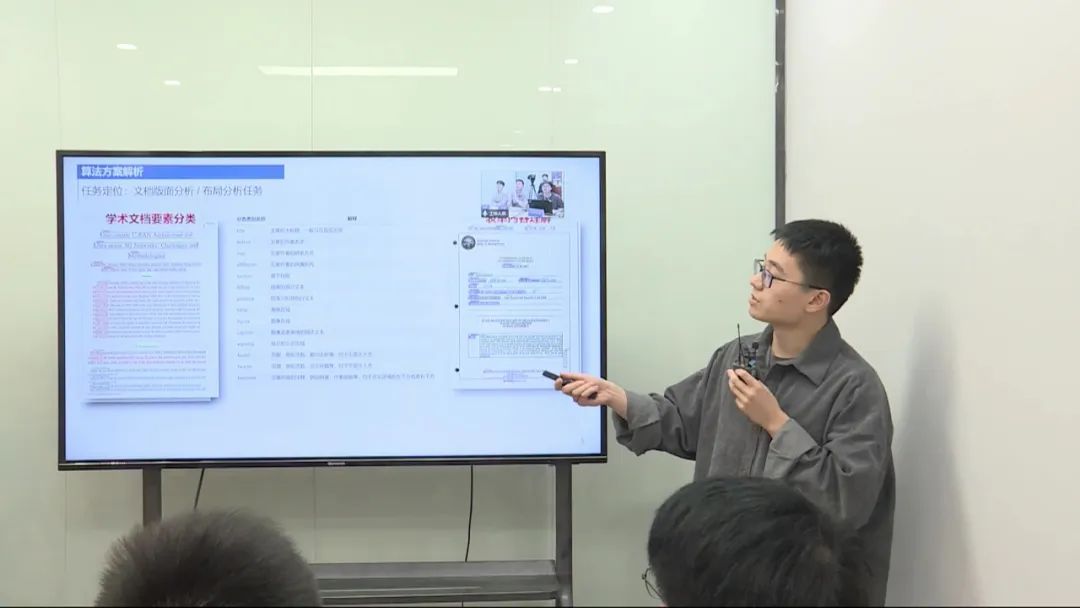
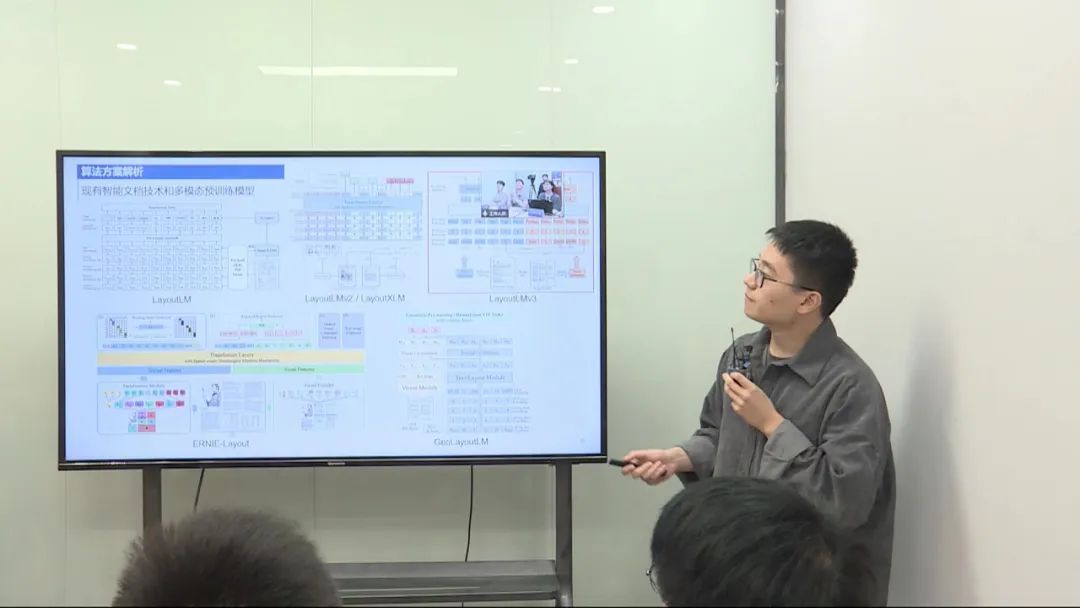




任务定位:该任务是针对文档中每行的linebox进行分类,类似于表单内容的理解任务。左边是训练数据,用于预测每个linebox的类别。 算法选择:在已有的智能文档技术和多模态模型中,选择了最稳定的LayoutLM模型作为基线,并进行微调。 数据集和数据处理:采用了456个样本进行训练,50个样本用于验证。数据处理方面,将数据转换为LayoutLM所需的格式。 模型性能:通过微调和验证,评估了模型的性能。在各个类别上,观察了F1性能指标,并选择了性能最好的模型进行提交。 模型改进与集成:通过单模型和多模型的集成,利用了trick和数据增强策略,逐步提升了模型的性能。 下一步优化思路:考虑引入位置信息作为训练Loss的一部分,以及引入大语言模型进行文本处理,并进行后处理以提高模型性能。 模型集成方案:采用简单的投票方式进行模型集成,选择了三个模型的结果进行投票。
第三名
使用了 YOLO V8 模型和 LayoutLMV3 模型,并进行了一系列的数据预处理、模型训练和后处理操作。
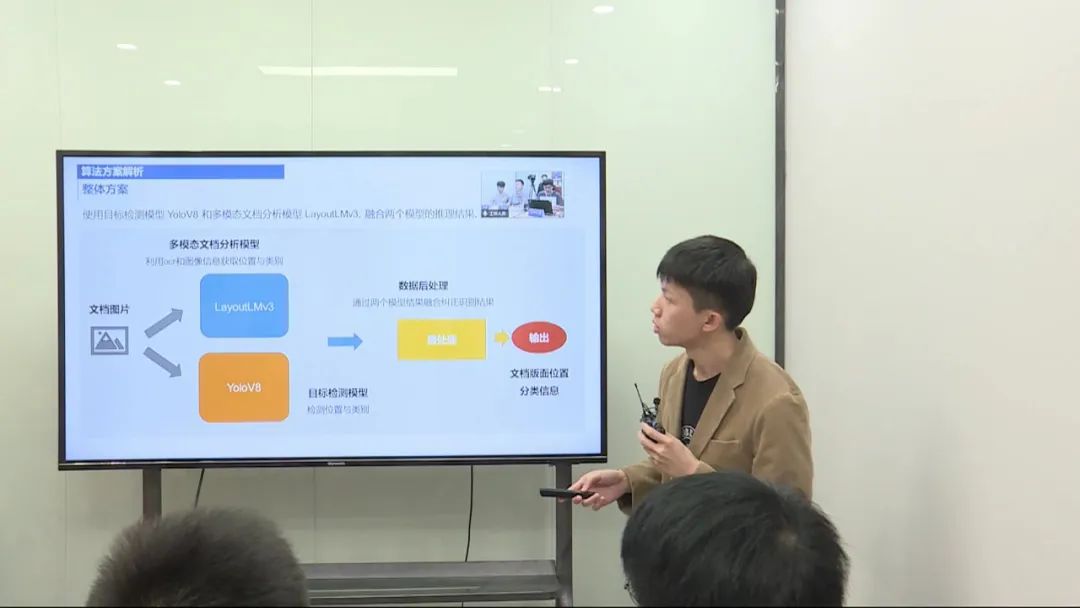
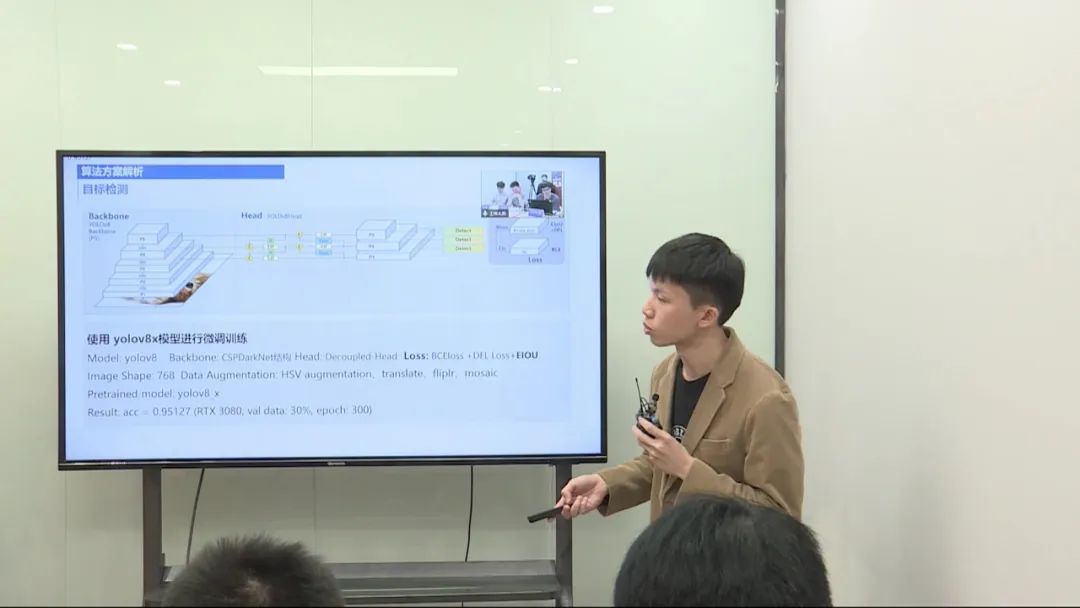
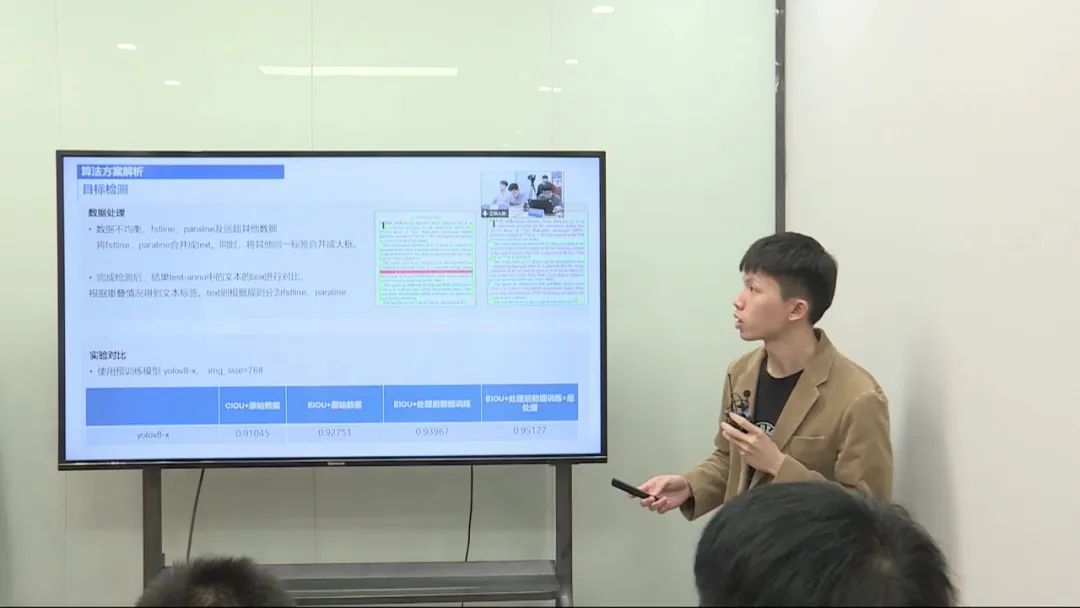

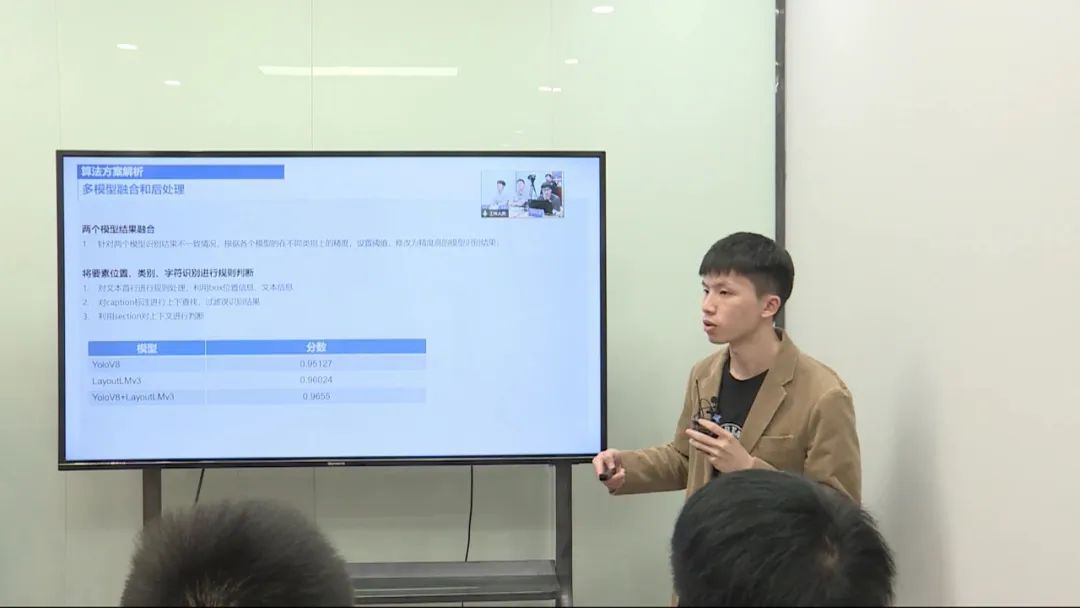
数据预处理: 对数据进行预处理,处理不清晰的文本和样本分布不均衡的情况。 针对目标检测,合并第一行和其他行,进行目标检测。 对于多模态任务,处理超长的文本内容,进行截断处理。 模型训练和调优: 使用 YOLO V8 模型和 LayoutLMV3 模型进行训练。 在训练过程中,改进模型的损失函数以及优化模型的输入。 对模型的输入长度进行调整,控制在较小的范围内,以满足模型的输入限制。 后处理和评估: 对两个模型的输出进行后处理,综合考虑不同类别的检测效果。 最终评估模型集成的性能,得出最终的分数。


