




本文会介绍几种主流的深度学习并行训练方法, 包括
模型并行(model parallel) 层间流水线并行(pipeline parallel) 层内张量并行(tensor parallel) 数据并行(data parallel) Zero Redundancy Data Parallelism(ZeRO)
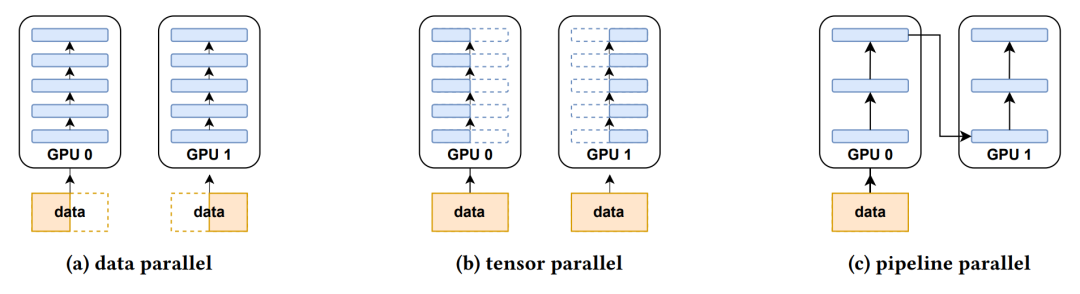
图1
1 模型并行
随着神经网络模型规模的增长,现有单个GPU的显存往往无法容纳训练过程中的高额占用。一个自然的解决思路是,对模型以及相关的梯度、优化器状态(optimizer states)作拆分,放到不同的显卡上并行计算。按照拆分方式的区别,模型并行(model parallel, MP)大体可以分为流水线并行(按层拆分)、张量并行(层内矩阵运算拆分)以及二者的混合。由拆分方式可见,模型并行一般是模型结构相关的,即,针对不同的架构需要做不同的设计,往往没有通用的优解。
1.1 流水线并行:GPipe
1.1.1 动机
按层对模型拆分需要(1)依次计算,(2)不同设备间传递计算中间值。因此,一个自然的问题是,在某张显卡上计算时,其余显卡会处于闲置状态,从而造成计算资源的浪费。
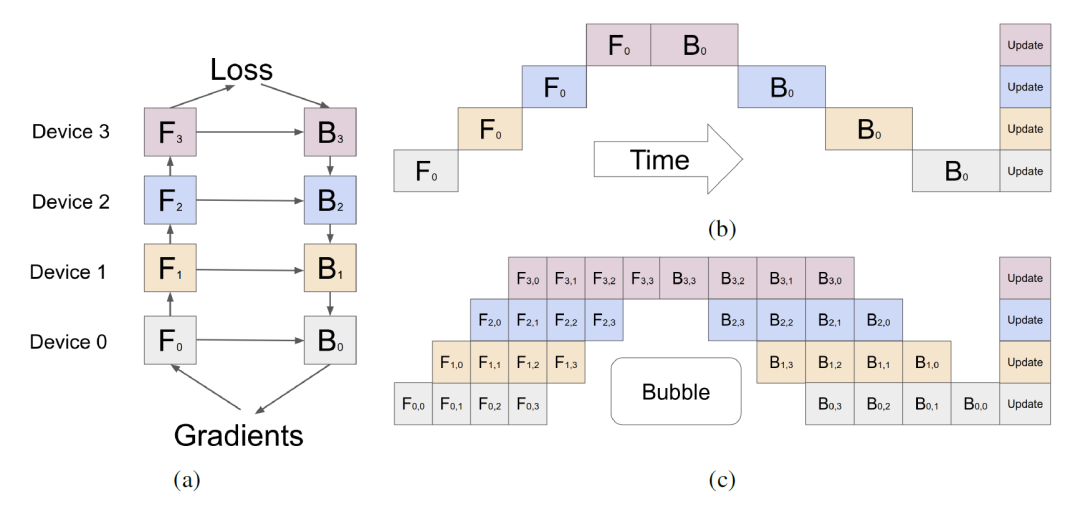
图2
GPipe1对此问题的解决思路是,将原有的数据批量(mini batch)进一步等分成若干micro batch,并以流水线的方式进行执行,从而减少计算中空泡(bubble)的比例,如图2所示。在一个阶段所有的micro batch反向传播结束后,再同步进行参数的更新。
在决定不同层的partition时,GPipe需要用户自己预估每层的计算时间开销,并通过最小化方差的方式对不同设备上的计算负载进行平衡。除此之外,GPipe还做了两点优化:(1)使用梯度检查点(gradient/activation checkpointing)技术,只存储设备通信边缘处的中间值,内部的中间值通过重计算的方式在反向传播时恢复;(2)实验发现,当 # micro batch # device 时,空泡的开销基本可以忽略,并且可以通过在反向传播时掩盖重计算和信息传输的方式进一步减小。
1.1.2 实验
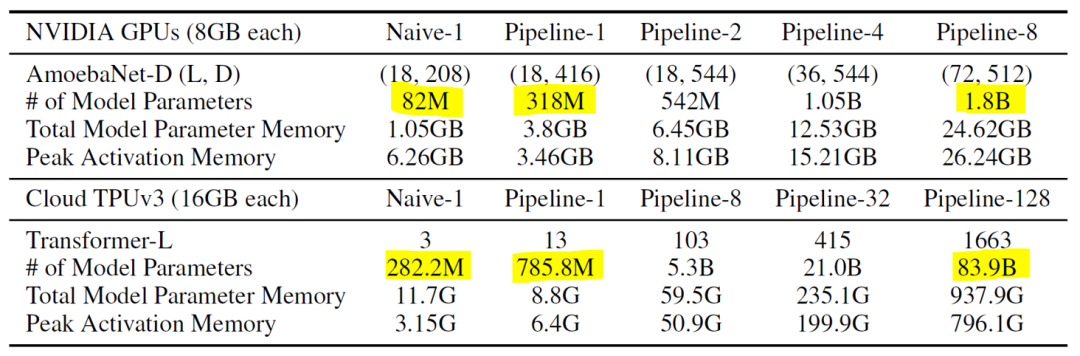
图3
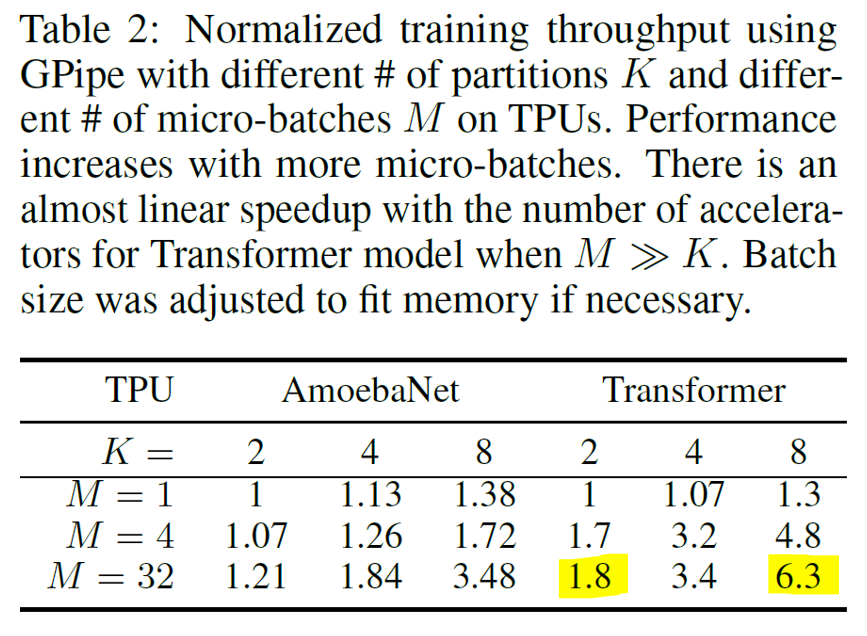
图4
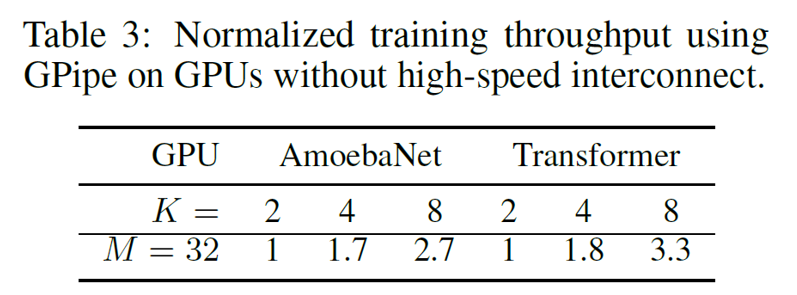
图5
实验中,主要关注可扩展性(scalability),效率和交流传输三方面。作者在CNN和Transformer架构上进行了实验。如图3所示,流水线并行极大地拓展了模型的规模,CNN模型的参数量在8路下达到了1.8B,Transformer模型参数量在128路下可达83.9B。效率方面,当时,可以取得线性/次线性的吞吐量提升;当时,一个设备在计算时其余设备都会处于闲置状态,因此此时吞吐量基本保持不变(图4)。此外,对比CNN和Transformer模型的加速比可见,划分partition时的平衡性对性能影响比较大。在划分均匀时能减少bubble开销,提升性能。最后,作者在PCI-E(不使用NVLinks)的传输环境下做了对比实验,发现加速比差距不大(图5)。这说明GPipe只在设备边缘传输中间值,传输量较小,带宽因此不构成瓶颈。
1.2 张量并行:Megatron-LM
Megatron-LM2大概是Transformer架构下最出名的张量并行工作。他为Transformer实现了层内的张量并行,并可以和数据并行、流水线并行搭配使用。在512张GPU的规模下可以取得76%的扩展效率。
1.2.1 GEMM的两种并行方式
在介绍Megatron-LM前,我们需要先简单回顾一下通用矩阵乘法(GEMM)的并行计算方式。一般地,我们的计算目标是,其中是数据,是模型参数。
第一种划分方式是将参数按行划分,即。
第二种划分方式是将参数按列划分,此时。
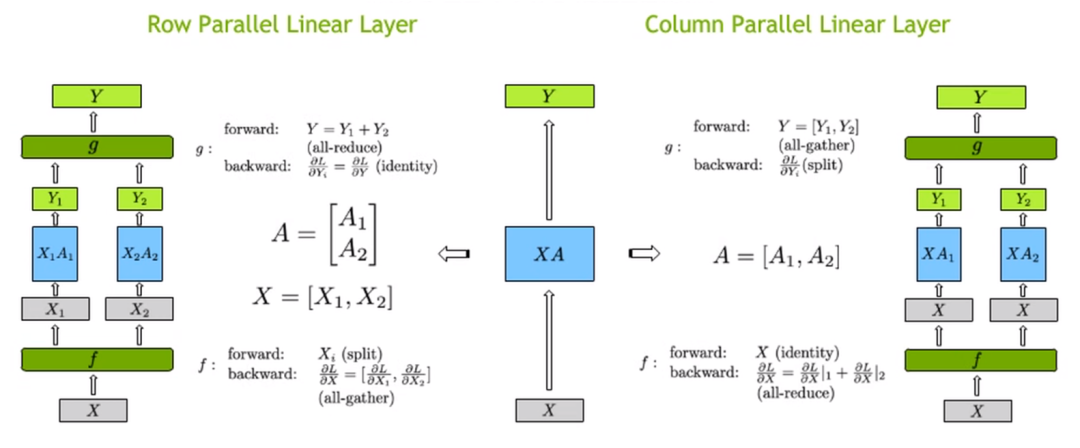
图6
在实现时,我们只需要实现两个额外的交流同步算子即可。行并行中,前向需要一次额外的all-reduce,反向需要一次额外的all-gather;列并行中,前向需要一次额外的all-gather,反向需要一次额外的all-reduce。
1.2.2 Megatron-LM的并行思路
Transformer单元中除了残差连接、归一化之外,可以分为两部分:(1)一个两层的MLP,(2)多头自注意力模块。
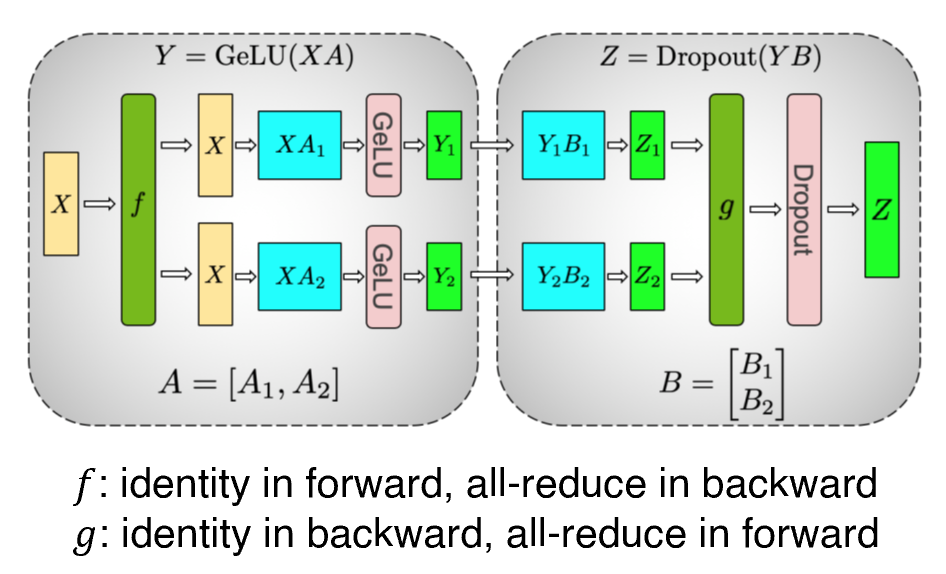
图7
在两层MLP这里,我们可以对第一层列并行,第二层行并行,从而可以避免对中间计算结果做一次额外的同步通信。因此,只需要在前向和反向中各进行一次同步,我们就可以完成两层MLP的并行计算。
如果我们对第一层行并行,即得。问题在于,因此这种方式必然需要一次额外all-reduce操作。
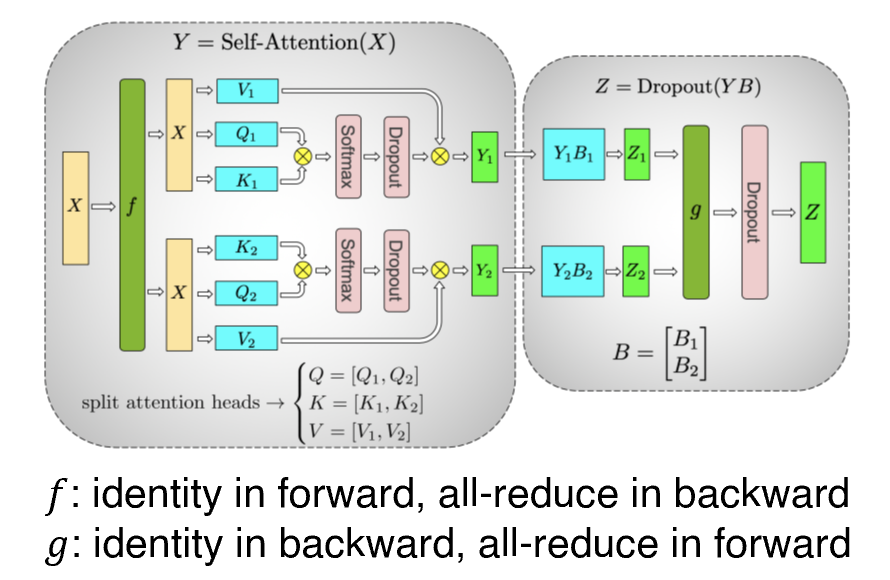
图8
对于多头自注意力模块,作者将不同的头按列分布到不同的GPU上并行计算,并对随后的GEMM行并行,如图8所示。
总结上述过程,对于一层Transformer结构我们需要4次额外的同步即可。Dropout/LayerNorm的计算没有做并行处理。除此之外,Megatron-LM还做了两点小优化:(1)对embedding矩阵列并行;(2)将预测的logit和交叉熵损失融合,减少通信量。
1.2.3 实验
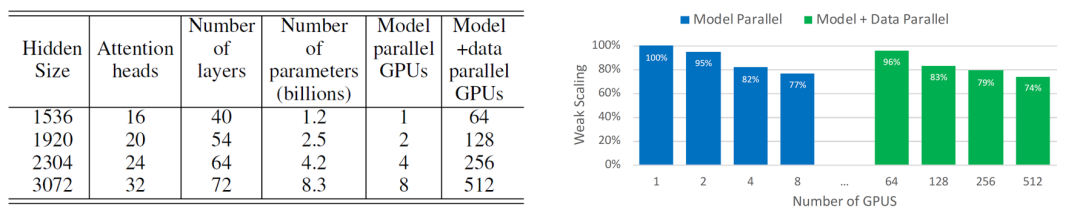
图9
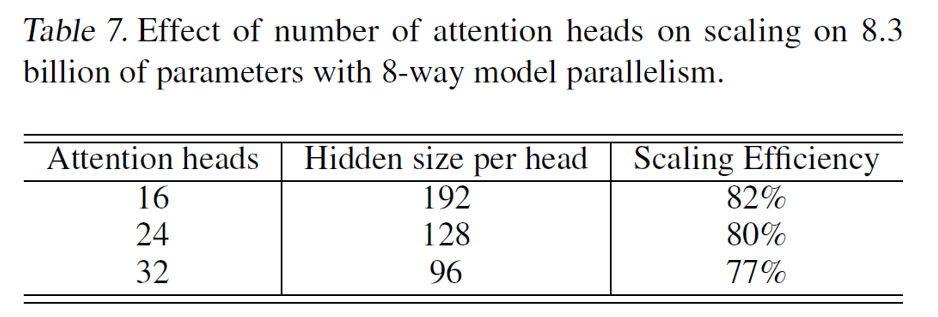
图10

图11
如图9所示,在仅使用模型并行和混合使用模型并行与数据并行的设置下,Megatron-LM都取得了良好的吞吐量扩展。而当模型参数量不变时,我们可以看到(1)模型结构(影响了计算粒度)对吞吐量有一定影响(图10);(2)当模型参数量不变,增加并行的GPU时,加速比的收益会边际递减,8卡上的吞吐量只有3x加速(图11)。
2 数据并行
数据并行(data parallel, DP)算法的主要目的是线性扩展计算吞吐量。DP在多个设备上拷贝模型参数、梯度、优化器状态,通过对数据分批,不同设备独立计算各自数据,并在反向传播时进行梯度的同步。虽然DP往往比MP有更优的计算效率(MP的通信开销往往较大,在多节点的带宽受限环境下加速比也受限),但DP没有办法减小显存的开销,因此随着模型参数的增加显得捉襟见肘。
3 Zero Redundancy Data Parallelism(ZeRO)
为了解决DP的显存问题,Microsoft的研究者提出了ZeRO3,一种显存友好的数据并行算法,并开源实现了DeepSpeed。
3.1 显存分析
在介绍ZeRO之前,我们先简单回顾一下在训练时的显存开销,主要可以分为两部分:(1)模型状态:参数、梯度、优化器状态,这些部分长期存储;(2)其余状态:激活值、通信缓冲区(buffer)、显存碎片(fragmentation)。
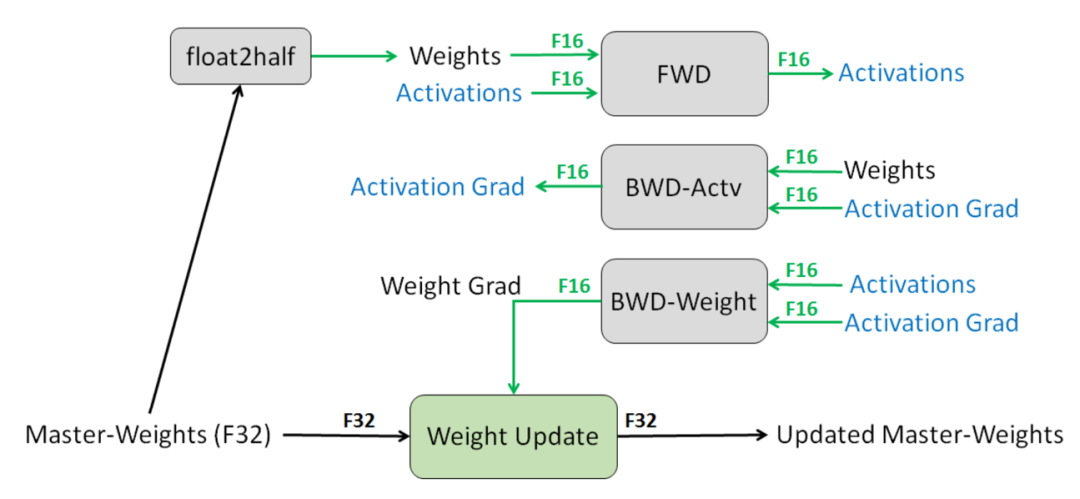
图12
模型状态: 以使用Adam优化器的混合精度训练为例,一个参数需要存储一份fp16参数、fp16梯度以及fp32的优化器状态(参数拷贝、一阶动量、二阶动量)。因此参数量需要字节的显存开销。以GPT-2为例,它含有1.5B个参数,如果用fp16格式存储参数,只需要3GB显存,但是模型状态实际上需要耗费24GB。
其余状态: 以Transformer结构为例,激活值的显存开销约为字节。缓冲区主要是为了all-reduce操作预留,其大小取决于通信量。显存碎片在一般情况下不会太大,但也会在一些极端情况下产生大量开销(比如在剩余30%显存时就OOM)。
3.2 ZeRO动机
ZeRO针对模型状态和其余状态都分别作了显存上的优化。
3.2.1 优化模型状态:ZeRO-DP
在DP的通信中,作者的一个关键洞察是:不是所有的存储内容是同时需要的。比如,每层的参数只在当前层前向和反向传播时需要,其余时间完全用不到,这就导致了冗余。因此,作者提出可以通过分片(partition)的方式替代DP中的拷贝。每张卡只存储的模型状态,这样系统内只需维护一份模型状态。
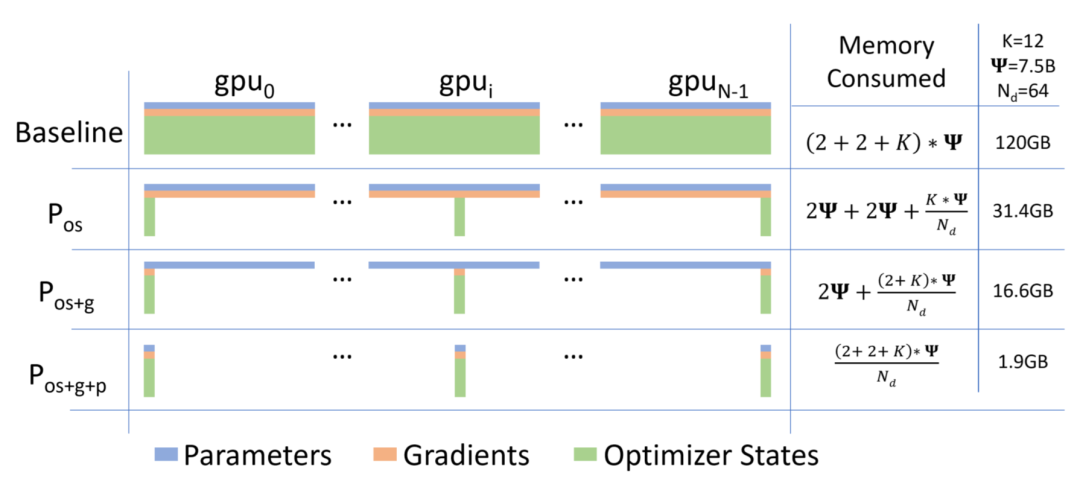
图13
ZeRO-1/:首先进行分片操作的是优化器状态,占的大头。参数和梯度仍旧是每张卡保持一份,此时,每张卡的模型状态所需显存是字节,当比较大时,趋向于,也就是原来的。 ZeRO-2/:继续对梯度分片,此时,每张卡的模型状态所需显存是字节,当比较大时,趋向于,也即是原来的。 ZeRO-3/:继续对参数分片,此时每张卡的模型状态所需显存是字节,随DP规模线性递减。
在实现上,ZeRO-1/2需要对梯度进行reduce-scatter,并对更新后的参数(在优化器状态里)进行all-gather;ZeRO-3由于对参数也做了分片,因此在前向和反向传播时在计算到对应参数时需要各broadcast一遍,并在更新梯度时进行reduce-scatter。由于参数分片因此最后不再需要参数上的all-gather。对比经典DP,需要对梯度进行all-reduce(reduce-scatter + all-gather),可以发现ZeRO-1/2不增加额外通信量,而ZeRO-3会额外增加50%的通信量。尽管如此,这部分的通信代价还是远小于以Megatron-LM为首的MP方法。
3.2.2 优化其余状态:ZeRO-R
对于其余状态的优化可以分为三方面:
激活值:当训练的数据规模()很大时,激活值也会占用相当的开销。因此,ZeRO对激活值也做了分片,并且这部分可以进一步被offload到CPU上存储。这虽然减少了GPU上的显存开销,但会带来CPU-GPU间额外的通信,尽管可以和其余计算过程相掩盖。因此,是否进行offload需要对具体的运算负载具体分析。 缓冲区:设置了常数大小的缓冲区,避免过大的缓冲区占用。 显存碎片:作者发现显存碎片的原因主要是临时变量的生命周期长短不一。因此,作者为长生命周期的临时变量分配了连续的存储空间,从而避免过多显存碎片。
3.3 实验
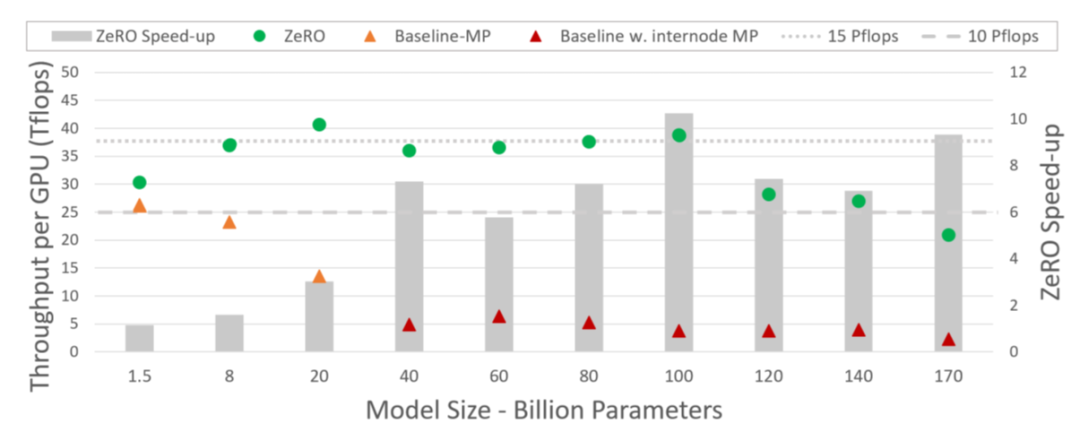
图14
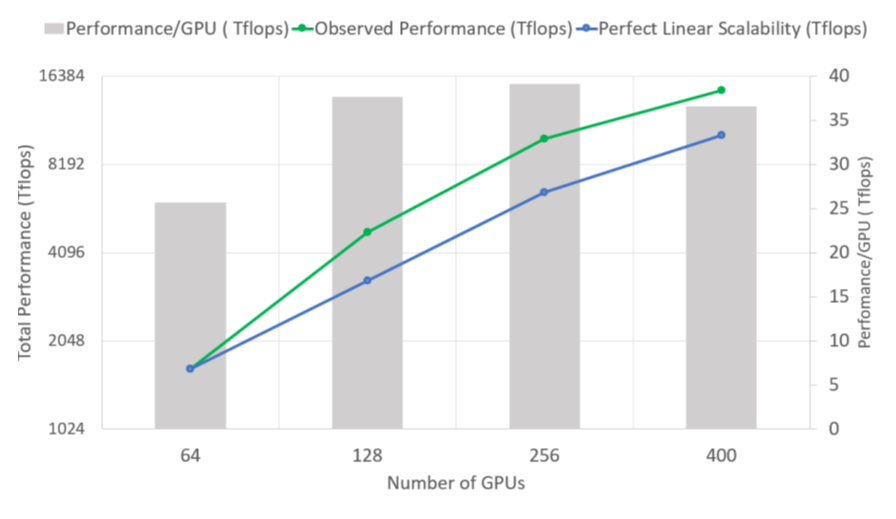
图15
实验部分作者主要测试了ZeRO的吞吐量与可扩展性。如图14所示,当Megatron-LM从单机切换到多机环境时,扩展性出现了显著的下滑,证明了带宽对于MP方法的限制。而ZeRO不仅在1/2阶段不产生额外的通信开销,并且还能提供更大的batch size,因此甚至可以取得超线性的吞吐量加速(图15)。
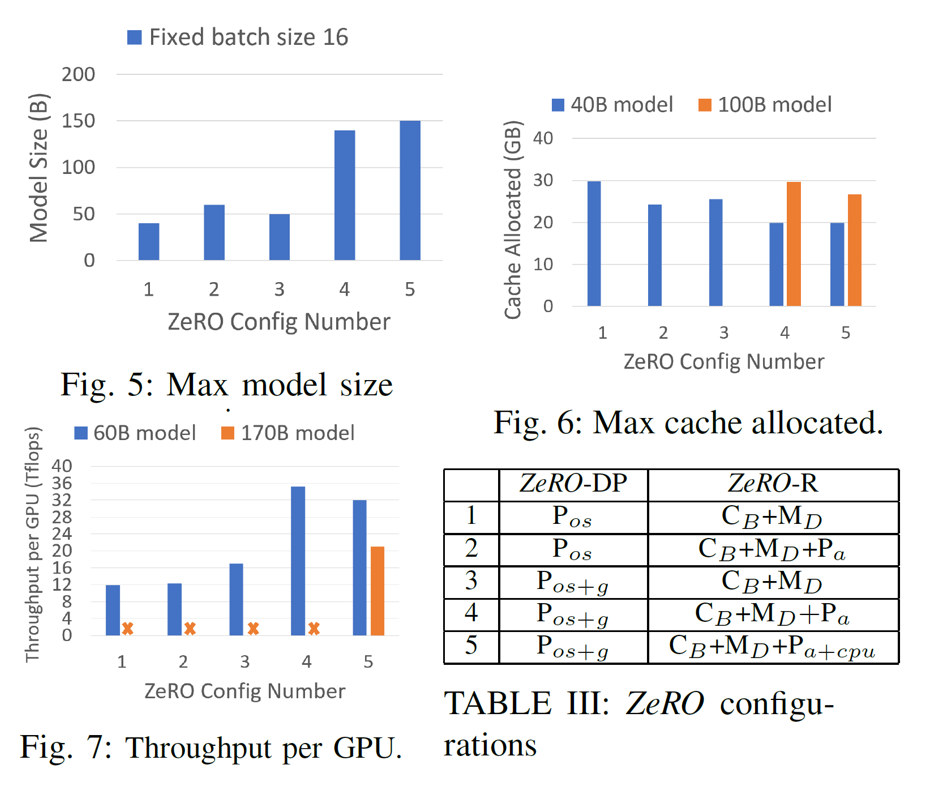
图16
最后作者还在不同的ZeRO配置下进行了模型规模、显存消耗、吞吐量的对比实验。
总结
本文简要介绍了几种主流的并行训练方法。可以看出,随着模型规模和训练规模的增长,需要解决的核心问题有两方面:(1)显存开销;(2)计算/通信/存储之间的trade-offs。
参考文献
[1] Huang, Yanping, et al. "Gpipe: Efficient training of giant neural networks using pipeline parallelism." Advances in neural information processing systems 32 (2019).
[2] Shoeybi, Mohammad, et al. "Megatron-lm: Training multi-billion parameter language models using model parallelism." arXiv preprint arXiv:1909.08053 (2019).
[3] Rajbhandari, Samyam, et al. "Zero: Memory optimizations toward training trillion parameter models." SC20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2020.


欢迎关注北京大学王选计算机研究所数据管理实验室微信公众号“图谱学苑“
实验室官网:https://mod.wict.pku.edu.cn/
微信社区群:请回复“社区”获取
gStore官网:https://www.gstore.cn/
GitHub:https://github.com/pkumod/gStore
Gitee:https://gitee.com/PKUMOD/gStore

