





 第 23 篇 | LINSHIYI
第 23 篇 | LINSHIYI 
 读写系列(一):对文件的打开&关闭&读&写读写系列(二):对CSV文件的读写读写系列(三):对JSON的读写
读写系列(一):对文件的打开&关闭&读&写读写系列(二):对CSV文件的读写读写系列(三):对JSON的读写
XML(Extensible Markup Language, 可扩展标记语言)是一种用来标记电子文件使其具有结构性的语言,它被用来标记、传输和存储数据。

XML1.0 LOGO
XML1.0标准由W3C(World Wide Consortium, 万维网联盟)在1998年2月10日首次公布,W3C官网中(https://www.w3.org/standards/xml/core)这样定义XML:
简单来说,XML就是一种表示结构化信息的文本格式,主要被用来描述数据。我们先举一个XML的例子看一下:
1<!--示例: test.xml-->
2<?xml version="1.0" encoding="utf-8"?>
3<example>
4 <name>麟十一</name>
5 <type>公众号</type>
6 <total_num>22</total_num>
7 <content id="Python">
8 <category>Python学习笔记</category>
9 <num>11</num>
10 </content>
11 <content id="Work">
12 <category>工作笔记</category>
13 <num>7</num>
14 </content>
15 <content id="Travel">
16 <category>旅行笔记</category>
17 <num>4</num>
18 </content>
19</example>
从这个例子中,我们可以看到XML的一些特点:
(1)XML的标签必须有开始标签和关闭标签(例如<example>和</example>,如果是空元素可以是<example/>),XML中所有元素都必须正确嵌套
(2)XML文档必须有一个根元素,这个元素是所有元素的父元素,上面例子中的根元素就是<example>
(3)XML的属性值必须要加引号,无论是数字还是字符串。例如代码中的id="Python",如果换成数字1的话应该是id="1"而不是id=1
1#示例: test.json
2{
3 "name": "麟十一",
4 "type": "公众号",
5 "total_num": "22",
6 "content1":{
7 "id":"Python",
8 "category":"Python学习笔记",
9 "num":"11"
10 }
11 "content2":{
12 "id":"Work",
13 "category":"工作笔记",
14 "num":"7"
15 }
16 "content3"{
17 "id":"Travel",
18 "category":"旅行笔记",
19 "num":"4"
20 }
21}
下面简单比较一下XML和JSON的异同:
相同之处:

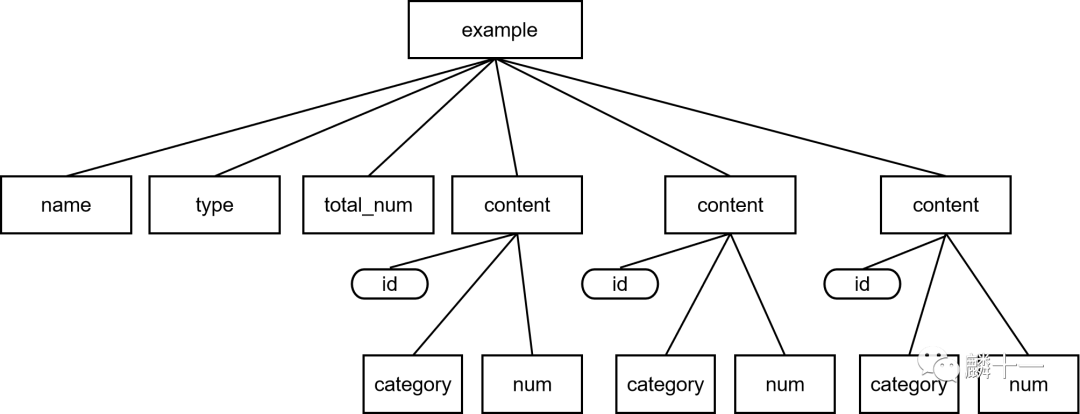
文档树示意图
可以看到,示例中有一个根节点example,根节点下的直属子节点有6个,每个content节点都有一个叫"id"的属性,而且每个节点下还都包括了category和num两个子节点。下面先来解析文件并提取节点:
1#1.解析XML
2#1.1 DOM方法
3import xml.dom.minidom
4#1.1.1解析XML文件,获取文档对象
5DOMTree = xml.dom.minidom.parse('test.xml')
6print(DOMTree)
7#1.1.2提取根节点root
8root = DOMTree.documentElement
9#1.1.2.1 根节点
10print(root)
11#1.1.2.2 根节点名称
12print(root.nodeName)
13#1.1.3提取子节点
14#1.1.3.1 根节点提取子节点content_node1
15content_node1 = root.getElementsByTagName('content')[0]
16print(content_node1)
17#1.1.3.2 根节点提取子节点category
18print(root.getElementsByTagName('category'))
19#1.1.3.3 父节点content_node1提取子节点category
20print(content_node1.getElementsByTagName('category')[0])
21#1.1.3.4 节点name_node提取节点category
22name_node = root.getElementsByTagName('name')[0]
23print(name_node.getElementsByTagName('category'))
#1.1.1和#1.1.2从文档中提取出了文档对象DOMTree和根节点root。其中#1.1.2.2中的DOM属性nodeName可以输出节点的名称。#1.1.3中使用的DOM方法getElementsByTagName可以获取带有指定标签名称的所有元素列表,如果想对节点进行操作的话需要先将元素从列表中提取出来,这也是上文中[0]的作用。
从#1.1.3的结果中我们可以看到,根节点可以提取文档中的所有子节点,但是其他节点只能提取出自己的直属子节点,比如节点content_node1可以提取自己的直属子节点category,而category不是name_node的子节点,所以name_node无法提取到该节点,#1.1.3.4的提取结果为空。
1#1.解析XML
2#1.1 DOM方法
3#1.1.1 解析XML文件,获取文档对象
4<xml.dom.minidom.Document object at 0x000001BAA1832AC8>
5#1.1.2 提取根节点root
6#1.1.2.1 根节点
7<DOM Element: example at 0x1baa14f5930>
8#1.1.2.2 根节点名称
9example
10#1.1.3 提取子节点
11#1.1.3.1 根节点提取子节点content_node1
12<DOM Element: content at 0x1baa14f5508>
13#1.1.3.2 根节点提取子节点category
14[<DOM Element: category at 0x1baa14f50e0>,
15 <DOM Element: category at 0x1baa14f5b90>,
16 <DOM Element: category at 0x1baa14f5d58>]
17#1.1.3.3 父节点content_node1提取子节点category
18<DOM Element: category at 0x1baa14f50e0>
19#1.1.3.4 节点name_node提取节点category
20[]
提取完了子节点,下面我们来提取文本和属性。XML中的文本位于标签对(例如<num></num>)中,属性会跟随节点保存于“开始标签”内。
下面我用两种方法分别获取文本和属性。#1.1.4.1中DOM属性childNodes可以返回标签对中的文本元素列表,firstChild会返回该列表的第一个元素。#1.1.4.2中使用DOM方法getAttribute和attributes并指定属性名称来获取相应的属性值。
1#1.1.4 提取节点的文本和属性
2#1.1.4.1 提取节点的文本内容
3print(name_node.childNodes)
4print(name_node.firstChild)
5print(name_node.childNodes[0].nodeValue)
6print(name_node.firstChild.data)
7#1.1.4.2 提取节点属性
8print(content_node1.getAttribute('id'))
9print(content_node1.attributes['id'].value)
这几种方法获取的结果都是一样的,使用哪个都可以。具体结果如下:
1#1.1.4 提取节点的文本和属性
2#1.1.4.1 提取节点文本内容
3[<DOM Text node "'麟十一'">]
4<DOM Text node "'麟十一'">
5麟十一
6麟十一
7#1.1.4.2 提取节点属性
8Python
9Python
最后,我们结合刚刚用到的方法,把整个XML的内容打印出来:
1#1.1.5 输出XML的所有内容
2node = ["name", "type", "total_num", "content"]
3for i in range(len(node)):
4 text = root.getElementsByTagName(node[i])[0]
5 #如果是没有文本节点的父节点,标签对中是换行符
6 if text.firstChild.data == '\n ':
7 text.firstChild.data = '无'
8 #打印第一层子节点
9 print("第 {} 个子节点 - {}, 内容 - {}".format(i+1, node[i], text.firstChild.data))
10 #继续打印content节点
11 if node[i] == "content":
12 content_node = root.getElementsByTagName('content')
13 for j in range(len(content_node)):
14 print(" content节点中第 {} 个子节点id - {}, 类别 - {}, 共发 {} 篇".format(j+1,
15 content_node[j].getAttribute('id'),
16 content_node[j].getElementsByTagName('category')[0].firstChild.data,
17 content_node[j].getElementsByTagName('num')[0].firstChild.data))
1#1.1.5 输出XML的所有内容
2第 1 个子节点 - name, 内容 - 麟十一
3第 2 个子节点 - type, 内容 - 公众号
4第 3 个子节点 - total_num, 内容 - 22
5第 4 个子节点 - content, 内容 - 无
6 content节点中第 1 个子节点id - Python, 类别 - Python学习笔记, 共发 11 篇
7 content节点中第 2 个子节点id - Work, 类别 - 工作笔记, 共发 7 篇
8 content节点中第 3 个子节点id - Travel, 类别 - 旅行笔记, 共发 4 篇
DOM方法整体来说还是很方便的,而且可以轻松实现对文档内容的增删改。不过这个方法的缺点在于一次性读取整个XML文档耗费的时间和内存较大,如果文件体积比较大的话很容易导致内存溢出。
有关minidom模块的更多内容见Python官方文档https://docs.python.org/3.7/library/xml.dom.minidom.html
ElementTree(元素树)是一个轻量级的DOM,它也拥有处理可拓展标记语言(XML)的接口,不过它比DOM的解析速度更快,消耗内存也更少。而且ElementTree也是一个基于对象的API。
接下来使用ElementTree解析文件并提取出节点:
1#1.2 ElementTree方法
2from xml.etree import ElementTree as ET
3#1.2.1 解析文件生成节点树对象
4ElementTree = ET.parse('test.xml')
5print(ElementTree)
6#1.2.2 获取根节点元素
7root = ElementTree.getroot()
8#1.2.2.1 根节点元素
9print(root)
10#1.2.2.2 根节点名称
11print(root.tag)
12#1.2.3 提取子节点
13#1.2.3.1 获取根节点root下子节点个数
14print("根节点root共有 {} 个子节点".format(len(root)))
15#1.2.3.2 获取子节点content_node1下子节点个数
16print(root[3])
17print("子节点content1共有 {} 个子节点".format(len(root[3])))
18print(root[3][0])
#1.2.1和#1.2.2分别获取了节点树对象ElementTree和根节点元素root,#1.2.2.2中属性tag可以输出元素名称。
另外,从#1.2.3中可以看出,ElementTree方法将XML表示为列表结构,我们可以直接通过列表索引来获取各个节点元素。
1#1.2 ElementTree方法
2#1.2.1 解析文件生成节点树对象
3<xml.etree.ElementTree.ElementTree object at 0x000001BA9D366748>
4#1.2.2 获取根节点元素
5#1.2.2.1 根节点元素
6<Element 'example' at 0x000001BAA17D3EF8>
7#1.2.2.2 根节点名称
8example
9#1.2.3 提取子节点
10#1.2.3.1 获取根节点root下子节点个数
11根节点root共有 6 个子节点
12#1.2.3.2 获取子节点content_node1下子节点个数
13<Element 'content' at 0x000001BAA1355BD8>
14子节点content1共有 2 个子节点
15<Element 'category' at 0x000001BAA1F31F48>
这里主要说一下#1.2.3的结果。由于根节点元素被表示成了列表,所以可以通过函数len()获取列表长度,也就是根节点中直属子节点的个数。列表索引由0开始,所以root[3]代表列表中第4个元素,也就是节点content_node1。root[3][0]代表content_node1节点中的第一个子节点元素category。
下面提取节点元素的文本和属性,ElementTree可以直接调用text和attrib来获取文本值和属性值:
1#1.2.4 提取节点的文本和属性
2#1.2.4.1 提取节点文本内容
3print(root[0].text)
4print(repr(root[3].text)) #repr()可以显示原始字符串
5#1.2.4.2 提取节点属性
6print(root[0].attrib)
7print(root[3].attrib)
如果标签对中存在文本数据,text属性会返回字符串格式的文本数据;如果没有文本数据(如<num></num>或<num/>),返回None;如果像content_node1这样包含了子节点的话,会返回'\n ',即换行符和空值。
从#1.2.4.2的结果可以看出,ElementTree会将XML中的属性转换成字典格式,属性名称为key,属性值为value,如果一个节点没有属性的话,返回空字典。
1#1.2.4 提取节点的文本和属性
2#1.2.4.1 提取节点文本内容
3麟十一
4'\n '
5#1.2.4.2 提取节点属性
6{}
7{'id': 'Python'}
最后还是结合之前的内容,打印出整个XML文档:
1#1.2.5 输出XML的所有内容
2for i in range(len(root)):
3 text = root[i].text #获取节点的文本数据
4 if text == '\n ':
5 #无文本内容
6 text = '无'
7 print("第 {} 个子节点 {}, 内容 - {}".format(i+1, root[i].tag, text))
8 if len(root[i]) > 0:
9 #有子节点
10 for j in range(len(root[i])):
11 #每一个子节点
12 print(" 子节点 {}, id - {}, - {}".format(root[i][j].tag, root[i].attrib['id'], root[i][j].text))
1#1.2.5 输出XML的所有内容
2第 1 个子节点 name, 内容 - 麟十一
3第 2 个子节点 type, 内容 - 公众号
4第 3 个子节点 total_num, 内容 - 22
5第 4 个子节点 content, 内容 - 无
6 子节点 category, id - Python, 内容 - Python学习笔记
7 子节点 num, id - Python, 内容 - 11
8第 5 个子节点 content, 内容 - 无
9 子节点 category, id - Work, 内容 - 工作笔记
10 子节点 num, id - Work, 内容 - 7
11第 6 个子节点 content, 内容 - 无
12 子节点 category, id - Travel, 内容 - 旅行笔记
13 子节点 num, id - Travel, 内容 - 4
由于XML文档被转换成了列表格式,所以ElementTree相比DOM来说解析速度更快,且占用内存更少,通过列表索引来获取节点会更方便,而且ElementTree也可以轻松实现对XML的增删改。
有关这个库的更多内容见Python官方文档:https://docs.python.org/3.7/library/xml.etree.elementtree.html,这个文档真的超级详细,还有各种例子。
最后来说SAX(Simple API for XML),DOM和ElementTree都是基于对象的解析方法,而SAX是基于事件的。这是一种边扫描边解析的方法,它会从头开始逐行扫描文档,在扫描过程中通过触发一系列事件并调用回调函数来解析XML文件。
这个方法仅凭描述会有些难以理解,所以我把SAX扫描文档并触发事件的过程画了出来:
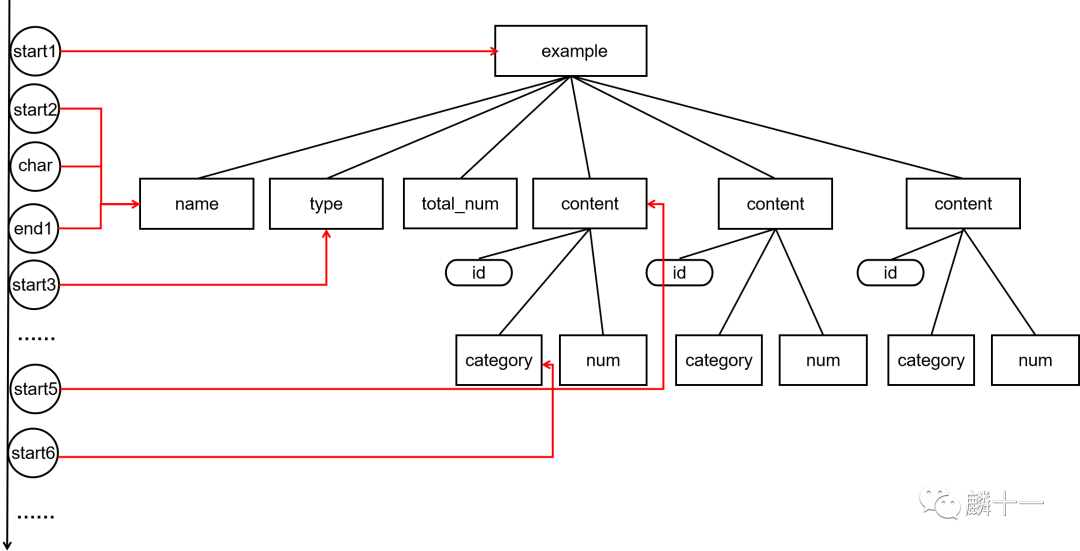
上图左边的圆圈就是SAX触发的一系列事件,当解析器遇到根节点的开始标签<example>时,触发开始事件start1,根据XML文件顺序,接下来会遇到第一个子节点的开始标签<name>,触发start2。由于name节点中包含了文本数据“麟十一”,所以紧接着会触发处理文本事件char,之后遇到name节点的结束标签</name>时触发结束事件end1,结束第一个子节点的扫描。再之后解析器会遇到第二个子节点的开始标签<type>触发事件start3,以此类推。
另外,当解析器开始读取XML文档时会触发文档开始事件startDocument,解析器到达文档底部时会触发文档结束事件endDocument。
在使用SAX解析时,我们可以直接继承SAX模块中定义好的ContentHandler类,通过对类中函数的重写来实现我们的不同需求。当然,我们也可以在类添加各种自定义函数,例如增加函数Output(名字随意)将XML结果写入TXT等:
1import xml.sax
2#创建XMLHandler类,继承ContentHandler类
3class XMLHandler(xml.sax.ContentHandler):
4 #初始化
5 def __init__(self):
6 self.text = '' #节点中的文本数据
7 self.node = '' #节点名称
8 #1.3.1 解析器开始读取文档时执行
9 def startDocument(self):
10 print('*-*-*-*开始解析文件*-*-*-*')
11 #1.3.2 遇到开始标签<tag>时执行
12 #参数tag表示节点名称,attrs表示属性
13 def startElement(self, tag, attrs):
14 #想进行操作的节点名称列表
15 node_list = ['name', 'type', 'total_num', 'content']
16 #记录正在解析节点的名称
17 self.node = tag
18 if self.node in node_list:
19 #如果节点名称在node_list中,输出节点名称
20 print("====" + self.node + "====")
21 #获取正在解析节点的属性名称列表
22 attrs_list = attrs.getNames()
23 #如果该节点有属性
24 if len(attrs_list) > 0 :
25 #挨个输出属性名称和属性值
26 for i in range(len(attrs_list)):
27 print(attrs_list[i] + ' : ' + attrs[attrs_list[i]])
28 print("- - - - - - - - -")
29 #1.3.3 遇到标签对<tag></tag>之间的文本时执行
30 #参数content代表文本数据
31 def characters(self, content):
32 #想进行操作的节点名称列表
33 node_list = ['name', 'type','total_num', 'category', 'num']
34 #如果正在解析的节点名称在node_list中
35 if self.node in node_list:
36 #保存该节点的文本数据
37 self.text = content
38 #1.3.4 遇到结束标签</tag>时执行
39 #参数tag表示节点名称
40 def endElement(self, tag):
41 #想进行操作的节点名称列表
42 node_list = ['name', 'type', 'total_num', 'category', 'num']
43 #记录该节点的名称
44 self.node = tag
45 #如果正在解析的节点在node_list中,输出节点名称和文本数据
46 if self.node in node_list:
47 print('{} : {}'.format(self.node, self.text))
48 #1.3.5 解析器到达文档结尾时执行
49 def endDocument(self):
50 print('*-*-*-*-*解析完成*-*-*-*-*')
51#调用类和函数
52if __name__ == '__main__':
53 #创建并返回一个SAX XMLReader对象
54 parser = xml.sax.make_parser()
55 #调用类和函数
56 handler = XMLHandler()
57 parser.setContentHandler(handler)
58 parser.parse('test.xml')
#1.3中一共重写了5个函数,分别是#1.3.1中的文档开始函数--startDocument(),#1.3.2中的开始解析节点函数--startElement(),#1.3.3的解析文本函数--characters(),#1.3.4的结束解析节点函数--endElement()和#1.3.5的文档结束函数--endDocument()。
#1.3.1和#1.3.5中的内容都很简单,在开始和结束解析文档时打印一条语句。#1.3.2至#1.3.4全部都是根据我自己的想法设置的内容:在#1.3.2中,当解析器遇到开始标签<tag>时,打印出6个根节点直属子节点的名称并输出该节点的属性,在#1.3.3中,当解析器遇到标签对之间的文本时,保存文本数据,#1.3.4中,当解析器遇到结束标签</tag>时,输出除了content节点之外所有节点的名称和文本数据。下面是输出的结果:
1#1.3 SAX方法
2*-*-*-*开始解析文件*-*-*-*
3=====name=====
4name : 麟十一
5=====type=====
6type : 公众号
7=====total_num=====
8total_num : 22
9=====content=====
10id : Python
11- - - - - - - - -
12category : Python学习笔记
13num : 11
14=====content=====
15id : Work
16- - - - - - - - -
17category : 工作笔记
18num : 7
19=====content=====
20id : Travel
21- - - - - - - - -
22category : 旅行笔记
23num : 4
24*-*-*-*-*解析完成*-*-*-*-*

 END
END ~
~
