




前言:
在任何数据库的学习中,如果想深入的理解一种数据库系统,对于体系结构的理解和掌握都是重中之重,本篇开始为大家正式开始HaloDB的体系结构介绍。
上一期留给大家的小问题的答案在这里公布下。上一期的问题给大家回忆下:
要求查询出每门课都大于80分的学生姓名
create table s1(name char(6),subject char(8),score int);
insert into s1 values('张三','语文',79);
insert into s1 values('张三','数学',75);
insert into s1 values('李四','语文',76);
insert into s1 values('李四','数学',90);
insert into s1 values('王五','语文',90);
insert into s1 values('王五','数学',100);
insert into s1 values('王五','英语',81);在上一篇我们介绍了Having子句以及分组函数的使用方法,如题所示,要求查询出S1表每门课都大于80的学生的姓名
答案如下:
select name from s1 group by name having min(score)>80;开始今天的正式内容。
一、HaloDB的体系结构:
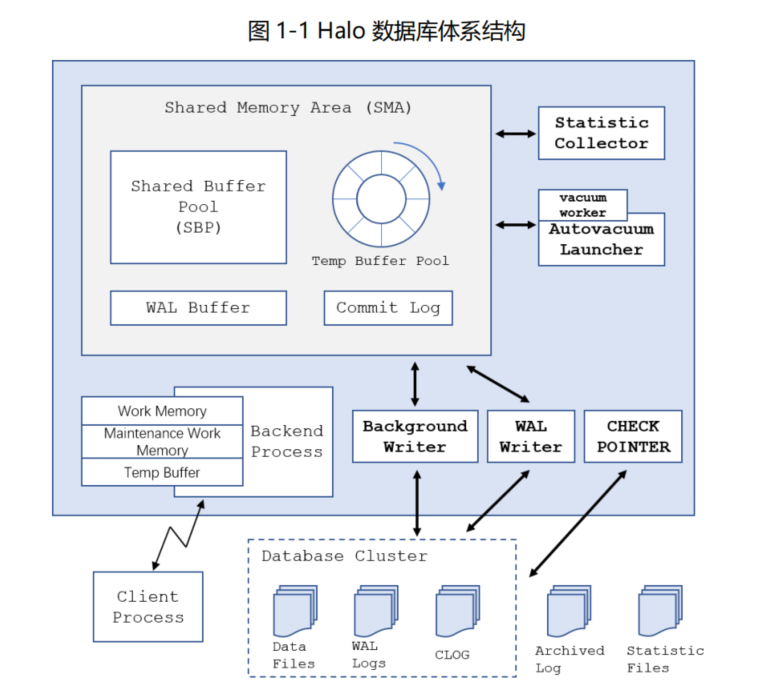
1、HaloDB中的共享内存区域和本地内存区域:
在我们的HaloDB中,内存架构部分主要分为,本地内存区域(Local Memory Area)和共享内存区域(Shared Memory Area)两个部分,下面针对每个部分做详细的说明;
a. 本地内存区域(Local Memory Area): 本地内存区域是每个后台进程(Backend Process)独立使用的内存空间。每个后台进程都有自己的本地内存区域,用于存储会话相关的数据和临时数据。本地内存区域包括以下几个重要的组件:
- 栈(Stack):用于存储函数调用和局部变量等信息。
- 上下文(Context):用于管理内存分配和释放,每个上下文都有一个父上下文,形成一个层次结构。
- 缓冲区(Buffer):用于存储查询结果集的数据,以及排序和哈希操作的中间结果。
- 连接信息(Connection Information):用于存储与客户端连接相关的信息,如会话状态、权限等。
b. 共享内存区域(Shared Memory Area): 共享内存区域是多个后台进程共享的内存空间,用于存储全局数据和缓存数据,以提高性能和效率。共享内存区域包括以下几个重要的组件:
- 缓冲池(Buffer Pool):用于缓存磁盘上的数据页,减少磁盘访问次数。
- 内存上下文(Memory Context):用于管理共享内存的分配和释放。
- 后台进程信息(Backend Process Information):用于存储后台进程的状态和信息。
- 锁表(Lock Table):用于管理并发访问的锁信息。
- WAL(Write-Ahead Logging)缓冲区:用于存储事务日志的中间结果。
- 共享内存区域的大小是在启动 HaloDB时配置的,可以根据系统的硬件资源和负载情况进行调整。本地内存区域的大小则由每个后台进程独立管理,通常受到系统的内存限制。
HaloDB的后台进程
后台进程:
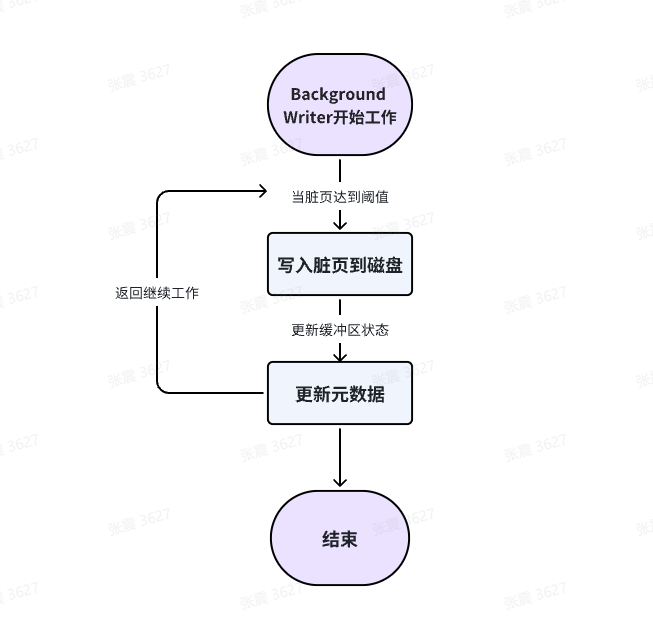
1、Background Writer(数据写进程):
Background Writer(数据写进程)工作过程如下:
a. 监控脏数据页:Background Writer 定期扫描数据库缓冲区,监控其中的脏数据页。脏数据页是指已经被修改但尚未写入磁盘的数据页。
b. 决定写入时机:Background Writer 根据一定的策略决定何时将脏数据页写入磁盘。这个策略通常基于缓冲区的使用情况、脏数据页的数量和系统负载等因素。
c. 异步写入数据:一旦决定将脏数据页写入磁盘,Background Writer 将这些数据异步地写入磁盘,而不是等待前台进程需要这些数据时再写入。这样可以减轻前台进程的写入压力,提高数据库的性能。
d. 更新元数据:Background Writer 在写入数据的同时,还会更新相关的元数据信息,包括系统表中的数据库统计信息。这些统计信息用于查询优化器,以帮助生成更有效的查询计划。
通过执行这些操作,Background Writer 减轻了前台进程的写入压力,提高了数据库的性能和响应能力。它异步地将脏数据页写入磁盘,并更新相关的元数据信息,以保证数据的一致性和持久性。同时,Background Writer 的工作是基于一定的策略,以适应不同的系统负载和数据库使用情况。
简单画了一个Background Writer的工作流程图如下,方便各位理解
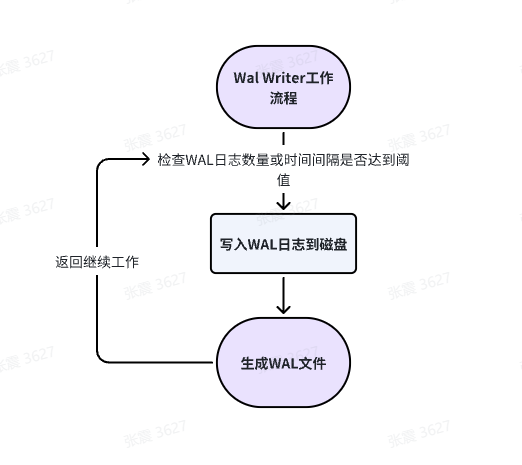
2、WAL Writer(事务日志写进程):
WAL Writer工作过程如下:
a. 监控WAL缓冲区:WAL Writer 定期扫描WAL缓冲区,监控其中的WAL日志条目。WAL缓冲区是一个内存区域,用于暂存事务日志。
b. 决定写入时机:WAL Writer 根据一定的策略决定何时将WAL日志条目写入磁盘。这个策略通常基于WAL缓冲区的使用情况、WAL日志条目的数量和系统负载等因素。
c. 异步写入日志:一旦决定将WAL日志条目写入磁盘,WAL Writer 将这些日志条目异步地写入磁盘,而不是等待事务提交时再写入。这样可以提高数据库的性能,因为事务提交时不需要等待日志写入完成。
d. 更新WAL位置:WAL Writer 在写入日志的同时,还会更新WAL位置(WAL LSN)。WAL位置是一个递增的标识符,用于记录已经写入磁盘的WAL日志的位置。这个位置信息对于数据库的恢复和故障恢复非常重要。
通过执行上述的操作,WAL Writer 确保了事务日志的持久性和一致性。
简单画了一个WAL Writer的工作流程图如下,方便各位理解
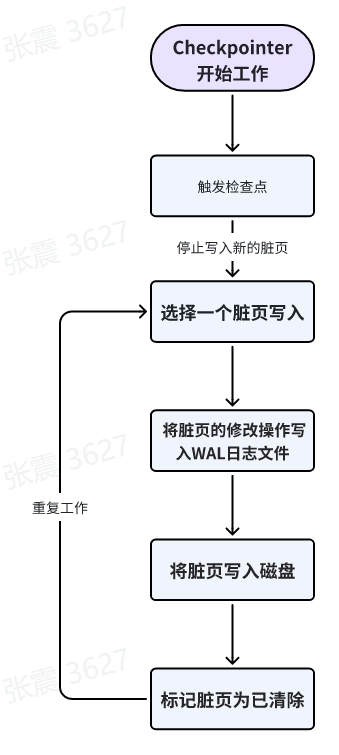
3、Checkpointer(检查点进程):
b. 写入脏页:一旦检查点被触发,Checkpointer开始将脏页(已被修改但尚未写入磁盘)写入磁盘。脏页是指在内存中已被修改的数据页。
c. 停止写入:在开始写入脏页之前,Checkpointer会通知其他进程停止向磁盘写入新的脏页。这是为了确保在检查点期间不会有新的修改被写入磁盘,以保持一致性。
d. 写入过程:Checkpointer按照一定的顺序将脏页写入磁盘。在HaloDB中,Checkpointer使用了一种称为"Write-Ahead Logging"(WAL)的机制。它将脏页的修改操作写入到WAL日志文件中,然后再将脏页本身写入磁盘。这种方式可以提高写入的效率和可靠性。
e. 更新检查点位置:在写入完成后,Checkpointer会更新检查点位置,以记录已经完成的检查点。这样,在系统恢复时,可以根据检查点位置来确定从哪里开始进行恢复操作。
f. 恢复写入:一旦检查点完成并且检查点位置被更新,Checkpointer会通知其他进程可以继续向磁盘写入新的脏页。
此外:
在我们的HaloDB中,Checkpointer还有一些额外的工作:
a. 自适应检查点:HaloDB的Checkpointer会根据系统的负载情况和性能指标来自动调整检查点的触发频率,以平衡写入性能和系统负载。
b. 后台写入:HaloDB的Checkpointer可以与其他后台进程(如Background Writer)协同工作,以提高写入的效率和并发性。
通过Checkpointer的工作,HaloDB数据库可以保证数据的持久性和一致性。它定期将内存中的数据写入磁盘,并使用WAL机制来确保写入的可靠性。这样,在系统故障或崩溃时,可以通过检查点位置和WAL日志来进行数据恢复和一致性保证。
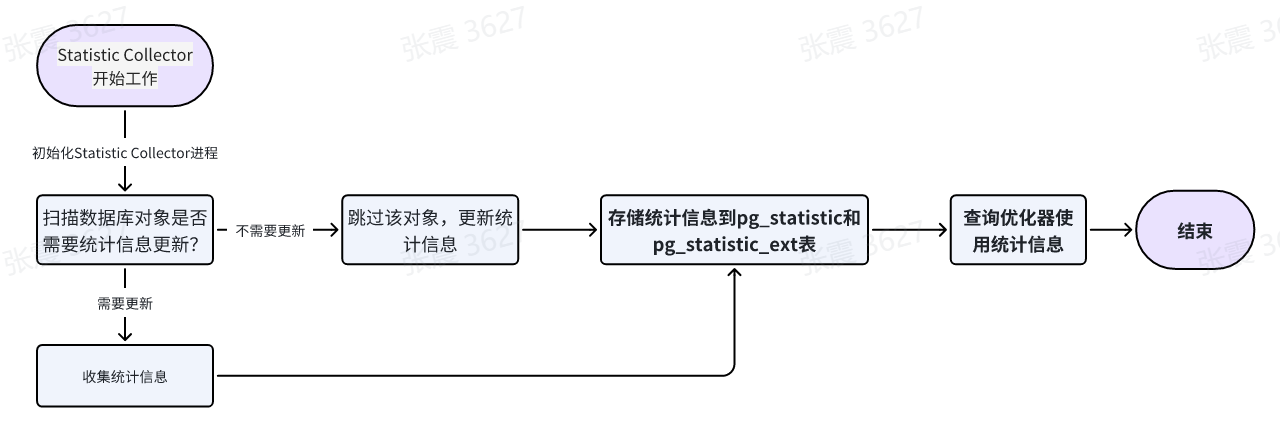
4、Statistic Collector(统计信息收集进程):
a. 目的:Statistic Collector的主要目的是收集和维护数据库对象的统计信息,包括表、索引、列等。这些统计信息对于查询优化器来说非常重要,它们帮助优化器选择最佳的查询计划,提高查询性能。
b. 统计信息类型:Statistic Collector收集的统计信息包括行数、唯一值数量、空值数量、最小值、最大值等。这些信息可以帮助优化器估计查询的选择性和数据分布情况。
c. 统计信息更新:Statistic Collector会定期扫描数据库对象,收集最新的统计信息。它会根据配置的参数(如autovacuum参数)来确定统计信息更新的频率和方式。通常情况下,当表或索引的数据发生变化时,Statistic Collector会自动触发统计信息的更新。
d. 统计信息存储:Statistic Collector将收集到的统计信息存储在系统表pg_statistic和pg_statistic_ext中。这些表包含了每个数据库对象的详细统计信息,以及一些全局统计信息。
e. 查询优化器使用:查询优化器在生成查询计划时会使用Statistic Collector收集的统计信息。通过分析统计信息,优化器可以选择最佳的索引、连接顺序和操作符等,以提高查询性能。
f. 配置参数:在PostgreSQL的配置文件中,可以通过一些参数来控制Statistic Collector的行为,如autovacuum参数用于控制统计信息的自动更新频率。
总之,Statistic Collector是PostgreSQL数据库中负责收集和维护统计信息的重要组件。它通过定期扫描数据库对象,收集最新的统计信息,并存储在系统表中。这些统计信息对于查询优化器来说非常重要,它们帮助优化器选择最佳的查询计划,提高查询性能。
工作过程如下:
a. 启动:Statistic Collector在PostgreSQL数据库启动时自动启动,并在后台运行。
b. 扫描对象:Statistic Collector会定期扫描数据库中的表、索引和列等对象,以收集它们的统计信息。扫描的频率和方式可以通过配置参数进行调整。
c. 统计信息收集:当Statistic Collector扫描到一个对象时,它会收集该对象的统计信息。这些统计信息包括行数、唯一值数量、空值数量、最小值、最大值等。
d. 统计信息更新:Statistic Collector会将收集到的统计信息与已有的统计信息进行比较,并根据一定的算法和策略来更新统计信息。通常情况下,当表或索引的数据发生变化时,Statistic Collector会自动触发统计信息的更新。
e. 统计信息存储:Statistic Collector将更新后的统计信息存储在系统表pg_statistic和pg_statistic_ext中。这些表包含了每个数据库对象的详细统计信息,以及一些全局统计信息。
f. 查询优化器使用:查询优化器在生成查询计划时会使用Statistic Collector收集的统计信息。通过分析统计信息,优化器可以选择最佳的索引、连接顺序和操作符等,以提高查询性能。
g. 自动更新:Statistic Collector可以根据配置参数(如autovacuum参数)来确定统计信息的自动更新频率和方式。这样可以确保统计信息始终与实际数据保持一致。
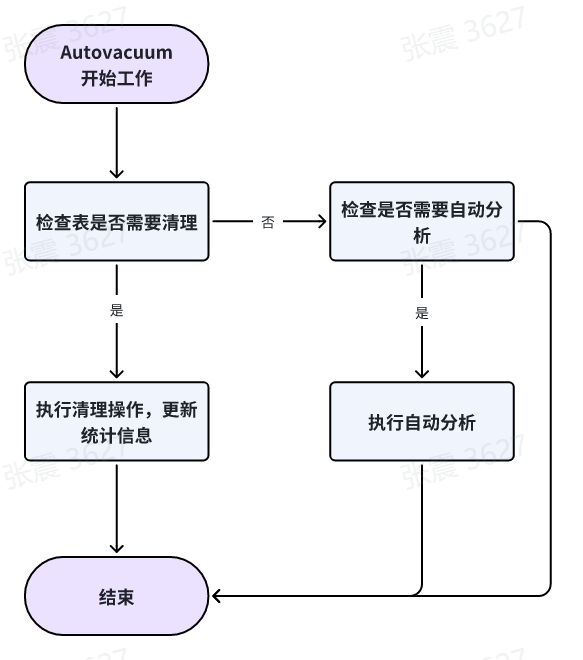
5、Autovacuum(自动清理进程):
工作内容如下:
a. 清理过期行:Autovacuum会检查表中的过期行(已被标记为删除但尚未被实际清理的行),并将其删除。这有助于回收磁盘空间,并提高查询性能。
b. 合并碎片化的页面:当表中的行被删除时,可能会导致页面碎片化。Autovacuum会合并碎片化的页面,以减少磁盘访问和提高查询性能。
c. 更新统计信息:统计信息对于查询优化器的性能决策非常重要。Autovacuum会更新表的统计信息,以确保查询优化器能够做出准确的执行计划。
d. 自动分析:Autovacuum还负责自动分析表的统计信息。它会检查表的更新频率和配置参数,判断是否需要进行自动分析。自动分析将收集表的统计信息,以便查询优化器能够做出更好的执行计划。
e. 配置参数:PG数据库提供了一些配置参数,用于控制Autovacuum的行为。这些参数包括自动清理的阈值、自动分析的频率、并发清理的并发度等。管理员可以根据实际需求进行配置。
f. 自动触发:Autovacuum会根据表的更新情况和配置参数自动触发清理和分析操作。它会根据表的更新频率、删除操作、空闲空间等因素来判断是否需要执行自动操作。
g. 手动触发:除了自动触发,管理员也可以手动触发Autovacuum操作。这可以通过执行VACUUM、ANALYZE或VACUUM ANALYZE语句来实现。
h. 进程调度:PG数据库可以同时运行多个Autovacuum进程,以处理多个表的清理和维护工作。进程调度器会根据系统负载和配置参数来决定启动和停止Autovacuum进程。
二、HaloDB的物理结构:
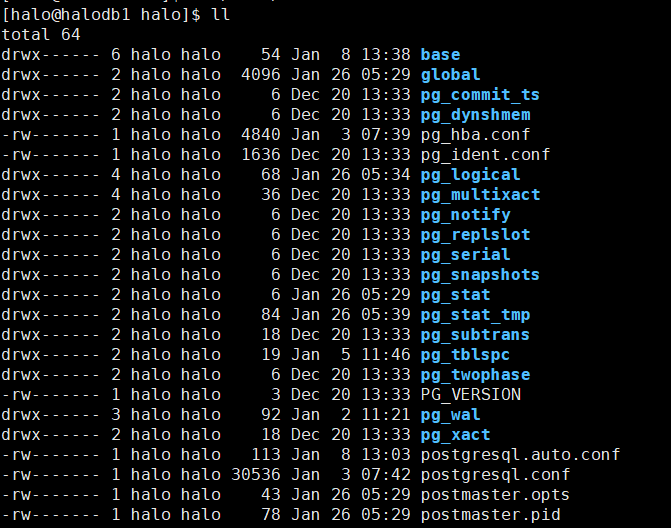
下面针对这些配置文件,做些简单的说明:
postgresql.conf:HaloDB的主配置文件,基本所有的参数配置均在此文件中。
postgresql.auto.conf:HaloDB的附加配置文件,使用后alter system 修改的配置存储在该文件中。
pg_hba.conf:HaloDB数据库的认证配置文件。
pg_ident.conf:ident认证方式的用户映射文件。
postmaster.opts:记录服务器上次启动的命令行参数,此目录下还会生成若干的的子目录。

1、数据存储结构:
在 Halo 数据库中,数据库群集是一组数据库的集合。每个数据库又是一组对象的集合。详细的架构图如下图所示:
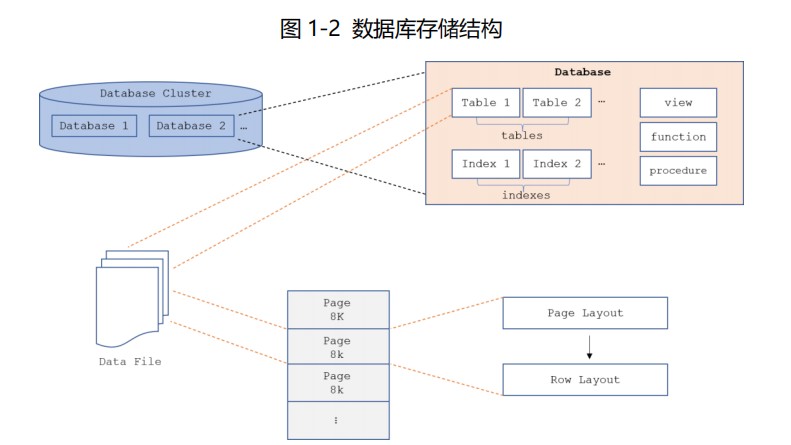
在 Halo 数据库体系中,数据库群集(Database Cluster)类似一个容器,在该容器内可以创建多个独立的数据库,分别对应不同的系统,即多租户。数据库群集初始化后,会创建 3 个默认的数据库:halo0root、template1 和template0。
- halo0root:管理库,群集管理使用,请不要删除。
- template1:正如其名称所示,这是一个模板库,后面通过 CREATE DATABASE 命令创建的库默认都以它为模板进行创建。
- template0:也是一个模板库。和 template1 的区别在于,通过template1 创建的库部分库属性,如字符集是无法更改的。而通过template0 就可以。
上图所述表空间所存放的物理位置放置在$HALODATA/base目录下,该目录下的存放很以OID命名的文件夹,就是该集簇下数据库存放的物理位置。接下来我们看下具体例子:
查询目前HaloDB中现有的数据库
halo0root=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+-------+----------+-------------+-------------+-------------------
halo0root | halo | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
halozz1 | halo | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =Tc/halo
template0 | halo | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/halo +
| | | | | halo=CTc/halo
template1 | halo | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/halo +
| | | | | halo=CTc/halo
testzz | halo | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
(5 rows)查询每个数据库所对应的OID号码
halo0root=# select oid,datname from pg_database;
oid | datname
-------+-----------
14509 | halo0root
1 | template1
14508 | template0
16385 | testzz
24987 | halozz1
(5 rows)进入到物理存储位置:
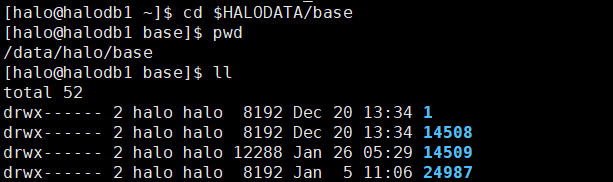
如上图所示,14509所对应的halo0root模板库的OID为14509跟物理路径下的文件夹名称是一一对应关系,该文件下下存放该库的表,索引等数据文件。图 1-2 描述了这种关系。其中,表的数据文件内部又被划分为固定长度的页(Page),通常为 8KB。每个文件中的页从 0 开始按顺序编号,该编号即为页号。页通常又被划分为页头和数据,即 Page Layout 中的内容。数据按行(Row)进行存储,每一行又被划分为行头和实际数据,即Row Layout 中的内容。索引的布局与表的布局类似。
2、HaloDB数据库内核架构:
HaloDB数据库的核心设计思想是插件式内核,这也是 Halo 数据库的一个最显著的特性。
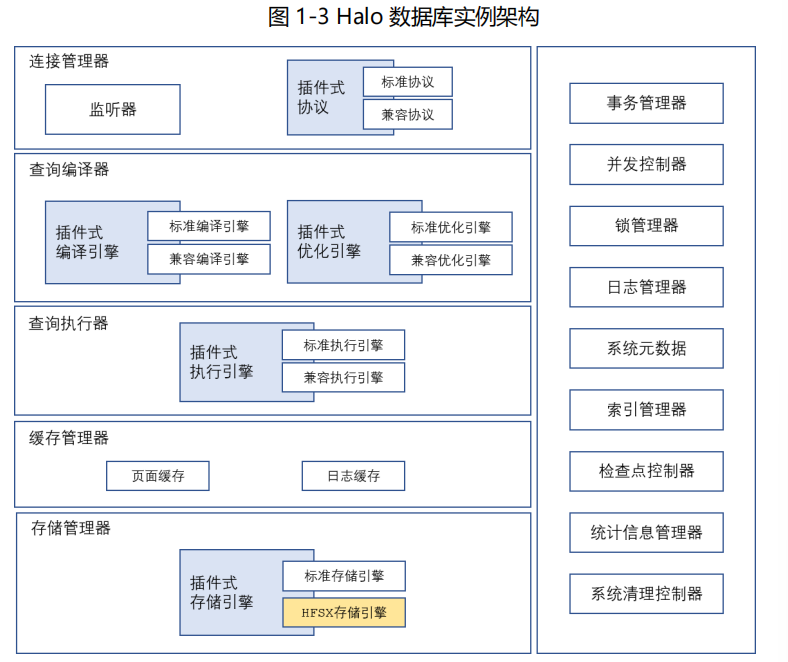
图 1-3 描述了 Halo 数据库实例的主要成分。通过插件式内核的设计,可以非常灵活的实现多种协议的兼容、多种语法的兼容、以及分布式存储引擎(HFSX,发展中技术)的支持等,这个重要特性也是 Halo 能够称之为新一代统一数据库的重要原因。 如果有对内核层面感兴趣的朋友,可以考虑加入我们公司进行深入的学习和体验。
三、HaloDB的逻辑架构:
说到逻辑结构,确实对新手来说理解起来有一些的难度,来话不多说,直接上图。
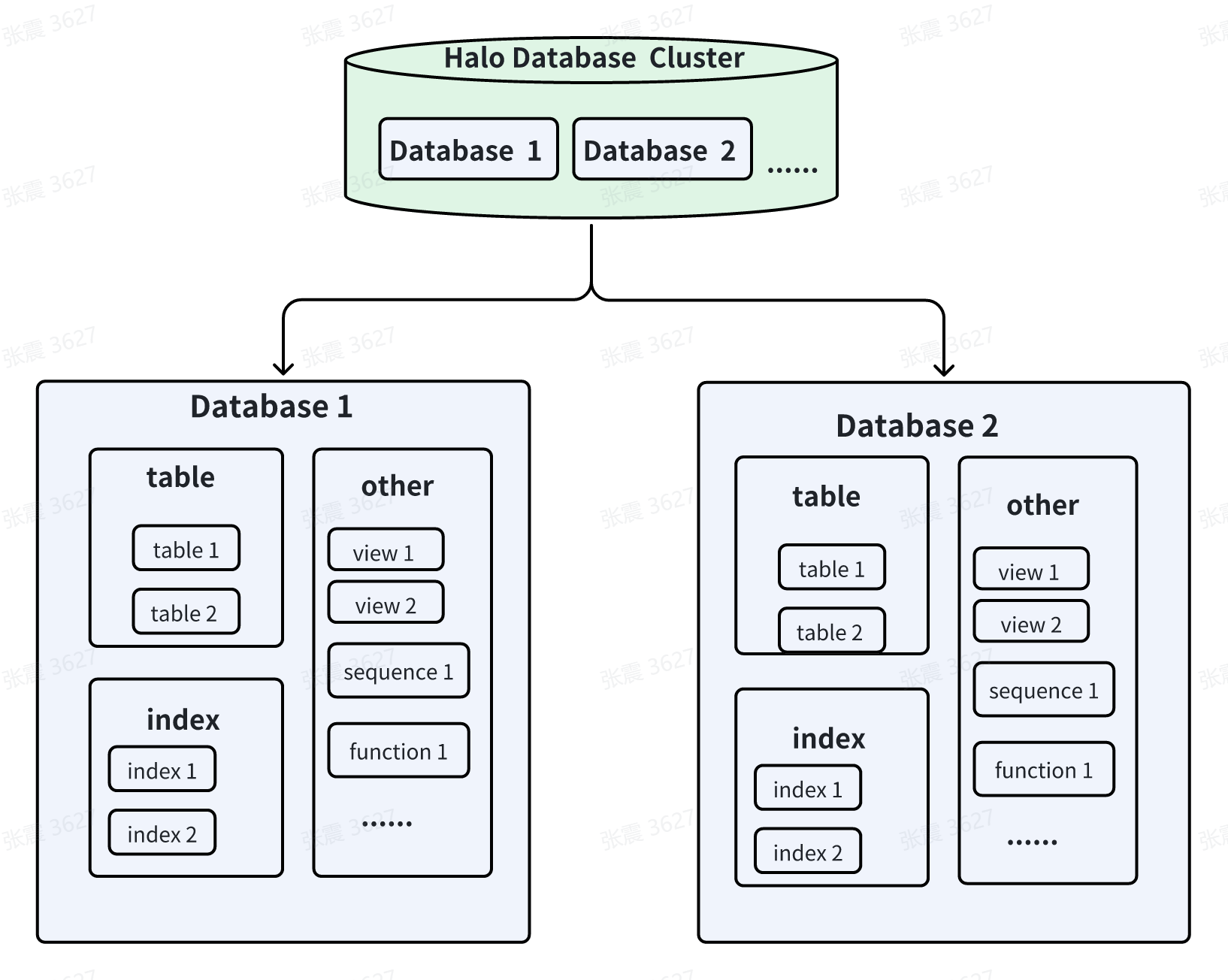
1、数据库集簇(Database cluster):
它是指有单个HaloDB服务器实例管理的数据库集合,组成数据库集群的这些数据库使用相同的全局配置文件和监听端口、共用进程和内存结构。一个DataBase Cluster可以包括:多个DataBase、多个User、以及Database中的所有对象。如上图所示。
2、数据库(Database):
在HaloDB中,数据库本身也是数据库对象,并且在逻辑上彼此分离,除数据库之外的其他数据库对象(例如:表、索引等等)都属于他们各自的数据库。
3、表空间(tablespace):
在HaloDB中,数据库在逻辑上分成多个存储单元,称作表空间。表空间用作把逻辑上相关的结构放在一起。数据库逻辑上是由一个或多个表空间组成。初始化的时候,会自动创建pg_default和pg_global两个表空间。
halo0root=# \db
List of tablespaces
Name | Owner | Location
------------+-------+-----------
halozz_tbs | halo | /data/tbs ###自行创建的表空间,非默认
pg_default | halo |
pg_global | halo |
(3 rows)创建表空间的语句可以参考如下:
halo0root=# create tablespace 表空间名称 location '所创建表空间的物理路径';
4、模式(Schema):
halo0root=# \dn
List of schemas
Name | Owner
--------+-------
public | halo
sys | halo
(2 rows)5、段(segment):
在HaloDB中,一个段是分配给一个逻辑结构(一个表、一个索引或其他对象)的一组区,是数据库对象使用的空间的集合;段可以有表段、索引段、回滚段、临时段和高速缓存段等。
6、区(extent):
7、块-block(Page):
数据块是HaloDB 管理数据文件中存储空间的单位,为数据库使用的I/O的最小单位,是最小的逻辑部件。默认值8K。
halo0root=# SHOW block_size;
block_size
------------
8192
(1 row)
8、数据库对象(Database object):
halo0root=# select oid,datname from pg_database;
oid | datname
-------+-----------
14509 | halo0root
1 | template1
14508 | template0
16385 | testzz
24987 | halozz1
(5 rows) 而数据库中的表、索引、序列等数据库对象的OID则存在了pg_class系统表中,例如可以通过下面的语句查询前面创建的表的OID。
testzz=# select oid,relname,relkind,relfilenode from pg_class where relname ='emp';
oid | relname | relkind | relfilenode
-------+---------+---------+-------------
16391 | emp | r | 16391
(1 row)小tips : pg_database,pg_class这两个视图真的很常用,请务必熟悉~
