




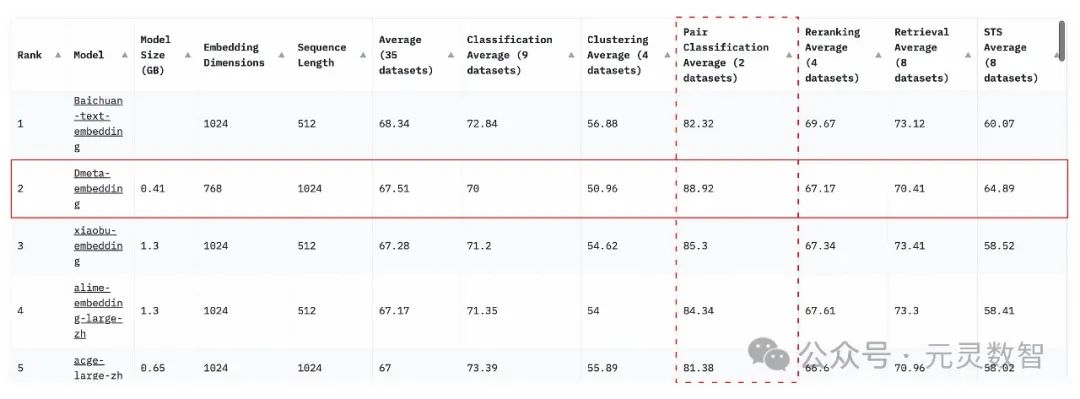
近日,北京数元灵科技有限公司开源了语义向量(Embedding)模型:DMeta-Embedding,目前位列 MTEB 中文场景开源模型第一(总榜第一名百川只提供 API 服务,暂未开源模型),并在 Pair Classification Average 单项位列中文场景第一名,模型已经发布到了 HuggingFace 社区:
https://huggingface.co/DMetaSoul/Dmeta-embedding,以下是榜单排名情况:
MTEB
Leaderboard(https://huggingface.co/spaces/mteb/leaderboard)
Embedding 的重要性
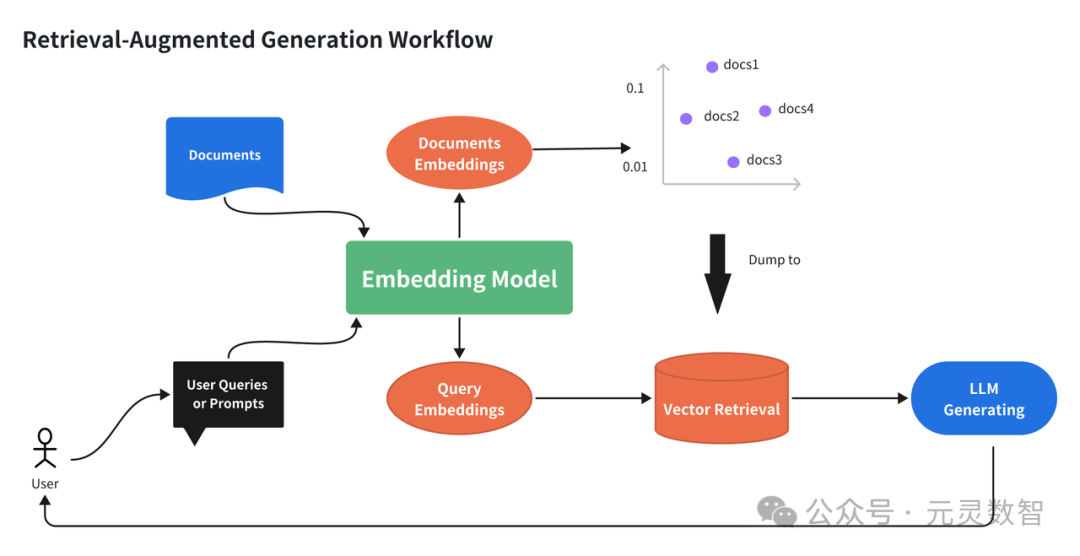
Embedding 是自然语言领域中基础、核心且经典的建模任务,从 Word2Vec 到 BERT 表征模型、再到现如今的大模型,Embedding 建模方法在不断创新迭代。不论在传统的搜索、问答场景,还是如今大语言模型(LLM)驱动的检索增强生成(Retrieval-Augmented Generation, RAG)场景中,Embedding 技术一直扮演着语义理解的核心角色,如下图所示:
MTEB 榜单权威性
技术亮点
这次数元灵推出的 DMeta-Embedding 之所以表现出色,主要得益于以下几个技术点:
1.首先是大规模弱标签对比学习。业界经验表明开箱即用的语言模型在 Embedding 相关任务上表现不佳,但由于监督数据标注、获取成本较高,因此大规模、高质量的弱标签学习成为一条可选技术路线。通过在互联网上论坛、新闻、问答社区、百科等半结构化数据中提取弱标签,并利用大模型进行低质过滤,得到 10 亿级别弱监督文本对数据。
2.其次是高质量监督学习。我们收集整理了大规模开源标注的语句对数据集,包含百科、教育、金融、医疗、法律、新闻、学术等多个领域共计 3000 万句对样本。同时挖掘难负样本对,借助对比学习更好的进行模型优化。
3.最后是检索任务针对性优化。考虑到搜索、问答以及 RAG 等场景是 Embedding 模型落地的重要应用阵地,为了增强模型跨领域、跨场景的效果性能,我们专门针对检索任务进行了模型优化,核心在于从问答、检索等数据中挖掘难负样本,借助稀疏和稠密检索等多种手段,构造百万级难负样本对数据集,显著提升了模型跨领域的检索性能。
后续规划
支持 API 接口访问:功能和 OpenAI Embedding 服务类似,但会以接近成本的价格提供给客户使用。
支持私有化部署:针对于数据敏感的企业,提供容器化部署能力,保障模型即插即用。
支持更长的上下文:与大语言模型更好地直接交互,为 AI Native 应用开发者提供更多的便利。
【关于数元灵】
数元灵科技成立于2021年,专注于一站式的大数据智能平台新基建,在研项目包括云原生湖仓一体框架LakeSoul,一站式机器学习框架MetaSpore, 以及云原生一站式AI开发生产平台AlphaIDE。公司力争打造以数据驱动为中心的标准化pipeline,推动国家数字化经济发展,致力于为帮助企业充分释放业务价值,服务新基建,让更多的行业和技术从业者享受到更普惠的大数据人工智能红利。
数元灵科技是国家高新技术企业、中关村高新技术企业
数元灵获国家信创认证、ISO27001信息安全管理、CMMI等资质认证、海光等生态认证
数元灵产品拥有软件著作12项,授权核心专利多项
入选最具潜力创业企业TOP10榜单、大数据产业国产化优秀代表厂商
GitHub:
https://github.com/lakesoul-io
https://github.com/meta-soul/MetaSpore
AlphaIDE:
https://registry-alphaide.dmetasoul.com/#/login
官网:
https://www.dmetasoul.com
官方交流群:
微信群:关注公众号,点击“了解我们-用户交流”
