





对于CSV文件的处理,Python中的csv库和pandas库都可以实现。csv库属于标准库,pandas属于第三方库。
标准库和第三方库的区别简单来说就是是否需要使用pip命令安装。标准库不需要使用pip命令安装,第三方库需要。有关标准库的具体内容可以在Python官网中找到:https://docs.python.org/3/library/,各种第三方库的信息可以在PyPI(Python Package Index)网站里查到:https://pypi.org/。

PYPI
Python标准库(The Python Standard Library)由一系列的模块组成,包括了Python的数据类型、内置函数、内置异常和实现各种功能的模块。标准库是随着Python一起安装在电脑中的,所以不需要通过pip命令进行安装。
简单介绍一下标准库里的内容。首先是数据类型(Data Types),它包括了数字类型、映射类型、序列类型等Python语言定义的数据类型。例如数字类型有整型int,浮点型float,映射类型有字典dict,序列类型有列表list,元组tuple,文本序列类型有字符串str等,这些数据类型都是Python的语言核心。
Python中的内置函数(Built-in Functions)涵盖了计算、转换、输出等内容,不同版本Python的内置函数个数不同,具体内容在官网上可以找到,网址:https://docs.python.org/3/library/functions.html。下图是Python3.7的内置函数列表:
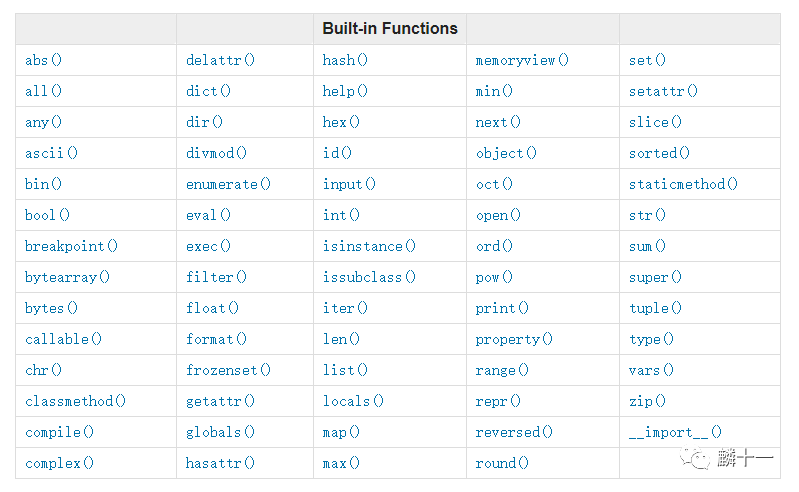
Python3.7内置函数
在之前的文章中我们用到的很多函数都属于内置函数,例如print(),bin(),bytes(),chr()等等。在这里推荐一个非常好用的内置函数:help(),使用这个函数可以查看相应Python库的基本信息和具体函数的用法,拿csv库来举例,help(csv)输出的内容如下:
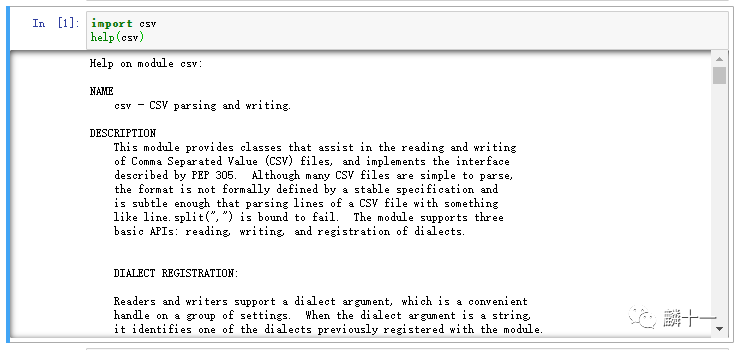
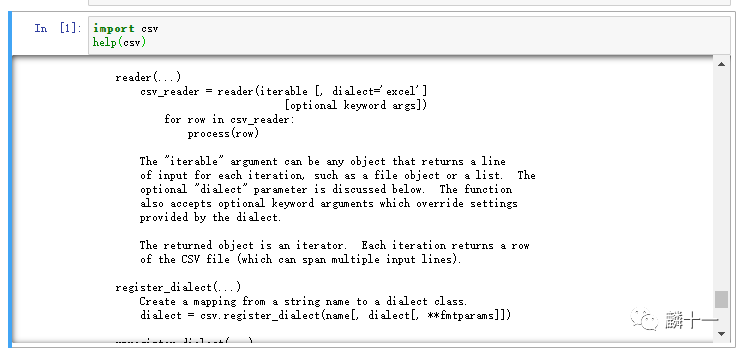
从上图中可以看到,help()函数返回了csv库的功能描述、参数设置、具体函数等内容,非常详细。
内置异常(Built-in Exceptions)一般都是在函数返回错误时被引发,返回错误也就是我们常说的“报错”。被引发的异常其实有很多种,常见的如OSError(操作系统错误),ImportError(导入模块/对象失败),NameError(未声明/初始化对象)等。举个例子,如果我们刚刚在使用help(csv)时没有先用语句import csv载入模块的话,就会出现如下异常:
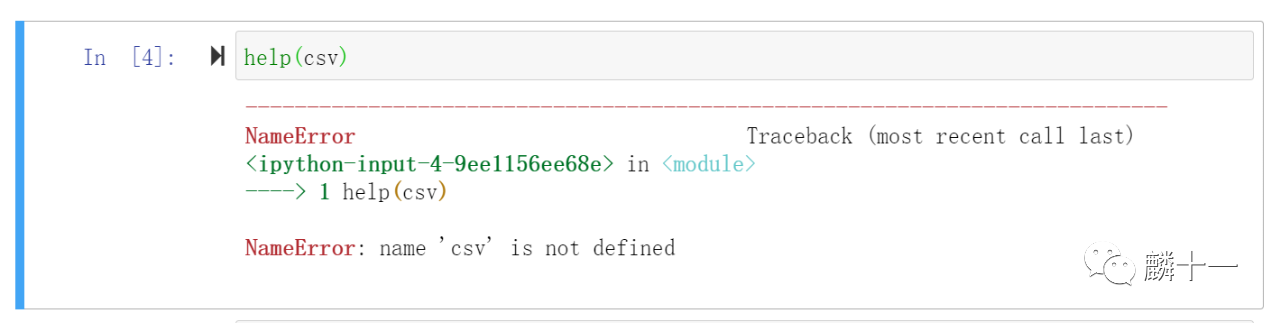
NameError在Python官网中这样定义:Raised when a local or global name is not found。也就是说程序在找不到名称时会引发这个错误,这个名称包括模块名称,变量名称等。简单来说,在代码运行时,遇到任何没有预先定义过的名称,都会引发NameError。
至于其他模块(Modules),功能和类型非常多,有些模块用C语言编写,有些使用Python编写。在SVG那一篇中我们使用的xml库属于结构化标记处理工具(Structured Markup Processing Tools)类型的模块,这一篇使用的csv库属于文件格式(File Formats)类型的模块。所有的模块不需要用pip语句安装,但是需要用“import + 模块名称”语句载入模块。
第三方库需要使用pip命令单独安装,使用时也需要用“import + 模块名称”语句载入模块。第三方库比标准库可实现的功能更多,例如后文用到的pandas库主要是实现对数据的分析和操作,SVG那一篇中提到的svgpathtools,svglib是实现对于SVG文件的操作等。由于第三方库太多了,在此不做过多说明,用到某个库的时候再细说吧
csv库又被称为CSV文件读写库(CSV File Reading and Writing),这个库主要包括了用CSV格式读取和写入数据的类。有关csv标准库的介绍见官方文档:https://docs.python.org/3.7/library/csv.html?highlight=csv#module-csv
有关pandas库的定义,官网上这样说:
pandas is a fast, powerful, flexible and easy to use open source data analysis and manipulation tool, built on top of the Python programming language.
pandas库是建立在Python上的快速且强大的开源数据分析和操作工具,也属于Python的核心数据分析支持库。pandas提供了大量的处理数据的函数或方法,官网地址是:https://pandas.pydata.org/ 。
我在查资料的时候还发现了一个中文pandas网站:https://www.pypandas.cn/。图标超级可爱,界面也非常清晰简洁,对于pandas新手很友好。不过这个网站有的内容还不是很完善,比如一些函数的内容还是英文版(官方声明还在翻译中),有一些函数的使用方法也是直接链接到pandas官网中。整体来说,这个网站可以当作pandas官网的半汉化版使用。

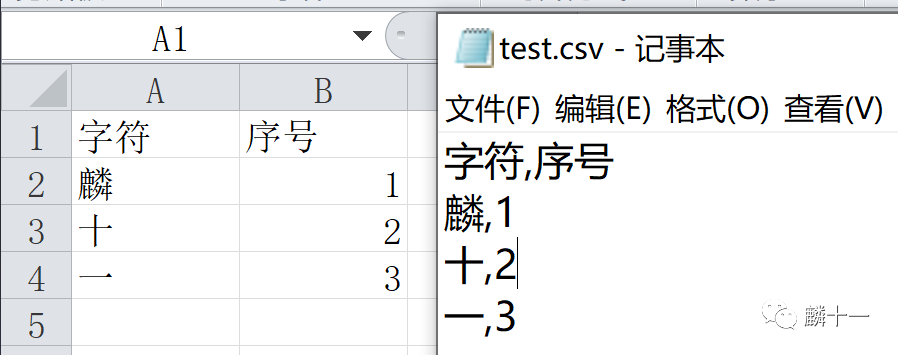
csv库可以使用csv.reader()和csv.DictReader()函数读取CSV文件,pandas库可以使用pandas.read_csv()函数读取文件。先新建一个test.csv文件,里面包含了“麟十一”三个字符和相应的序号。创建完成后,使用CSV和TXT格式分别打开文件,可以发现在记事本中字符串的分隔符是英文逗号:
1import csv
2#1. csv.Reader()
3#1.1 循环列出Reader对象数据
4with open('test.csv', 'r') as f:
5 csvReader = csv.reader(f) #建立Reader对象
6 for i in csvReader:
7 print(i)
8#1.2 将Reader转换成列表输出
9with open('test.csv', 'r') as f:
10 csvReader = csv.reader(f)
11 content_list = list(csvReader)
12 print(content_list)
代码结果如下所示,由于csv.Reader()返回的是一个可迭代对象,所以#1.1可以直接循环输出Reader对象中的内容,每一行都被输出成了一个列表,每一个单元格中的内容都被输出成为列表中的一个元素。#1.2将Reader对象转换成了列表,输出结果相当于#1.1的合并版。
1#1. csv.Reader()
2#1.1 循环列出Reader对象数据
3['字符', '序号']
4['麟', '1']
5['十', '2']
6['一', '3']
7#1.2 将Reader转换成列表输出
8[['字符', '序号'], ['麟', '1'], ['十', '2'], ['一', '3']]
1#2. csv.DictReader()
2#2.1 循环列出DictReader对象中的数据
3with open('test.csv', 'r') as f:
4 csvDictReader = csv.DictReader(f) #建立DictReader对象
5 for i in csvDictReader:
6 print(i) #2.1.1
7 print(i['字符']) #2.1.2
代码有两个输出,#2.1.1是循环列出DictReader对象中的内容,#2.1.2是采用字典关键字(key)的方式输出文档内容,结果如下:
1#2. csv.DictReader()
2#2.1 循环列出DictReader对象中的数据
3{'字符': '麟', '序号': '1'} #2.1.1
4麟 #2.1.2
5{'字符': '十', '序号': '2'} #2.1.1
6十 #2.1.2
7{'字符': '一', '序号': '3'} #2.1.1
8一 #2.1.2
#2.1.1输出的每一行都是一个字典,表头是关键字(key),文档内容是值(value)。#2.1.2只打印了“字符”列中的内容。
相比csv库,pandas读取CSV文件会简单很多,使用pandas. read_csv()函数会直接将文档内容返回为pandas的表格型数据结构:DataFrame:
1import pandas as pd
2#1. read_csv()
3content = pd.read_csv('test.csv', sep=',', encoding='gbk')
4print(content) #1.1 打印所有内容
5content_list = content.values.tolist()
6print(content_list) #1.2 将DataFrame转换为列表
read_csv()函数中的sep参数代表了文档的分隔方式,CSV使用的是英文逗号,如果想要读取TSV文件,则sep需要设置为’\t’。#1.1打印了文档的所有内容,#1.2将DataFrame格式的数据转换成了列表,如果想使用列表操作数据,可以使用这条语句进行数据类型的转换。打印出的结果如下:
1#1. read_csv()
2#1.1 打印所有内容
3 字符 序号
40 麟 1
51 十 2
62 一 3
7#1.2 将DataFrame转换为列表
8[['麟', 1], ['十', 2], ['一', 3]]
csv库中可以写入CSV文件的函数有csv.writer()和csv.DictWriter(),在pandas中需要用到pandas.DataFrame.to_csv()函数。
csv.writer()和csv.DictWriter()都会返回一个Writer对象,前者可以将列表写入文件,后者可以将字典写入文件。另外还有三个函数会用到,一个是writerow()函数,这个函数主要用于写入一行数据,而且会自动加入换行符。另一个是writerows()函数,用来写入多行数据,还有一个有用的函数是writeheader(),主要用于写入表头。先使用csv.writer()示例:
1import csv
2#1. csv.writer()
3#1.1 writerow()
4with open('test_write.csv', 'w', newline='') as f:
5 csvWriter = csv.writer(f) #建立Writer对象
6 csvWriter.writerow(['麟', '十一']) #1.1.1列表写入
7 csvWriter.writerow('公众号') #1.1.2 字符串写入
8#1.2 writerows()
9with open('test_write0.csv', 'w', newline='') as f:
10 csvWriter = csv.writer(f)
11 csvWriter.writerows([['麟', '十一'], '公众号'])
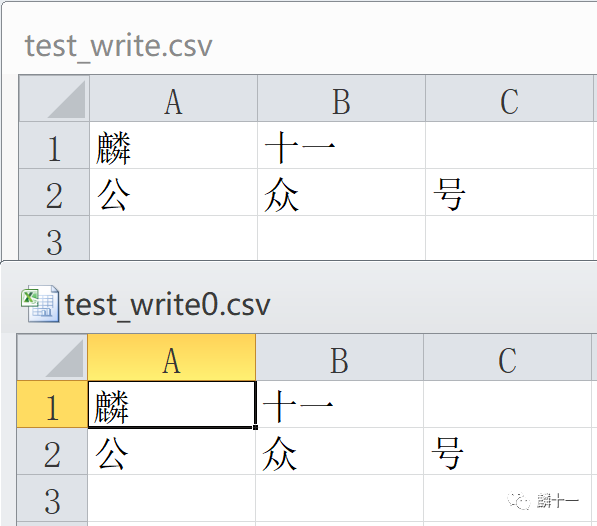
从上图可以发现使用writerow()函数时,如果使用列表写入,则列表中的每一个元素都被写入一个单元格中。如果使用字符串写入,则每一个字符都被写入一个单元格中。在使用writerows()函数时,列表中的每一个元素都会是单独的一行。
csv.DictWriter()函数的语法格式为csv.DictWriter(csvFile,fieldnames = fields),csvFile是打开的文件,fields是包含表头内容的列表,可以使用writeheader()函数将表头写入,示例如下:
1#2. csv.DictWriter()
2content = [{'名称': '麟十一', '类型': '公众号'}] #写入的内容
3with open('test_write1.csv', 'w', newline='') as f:
4 fields = ['名称', '类型'] #表头
5 csvDictWriter = csv.DictWriter(f, fields) #建立Writer对象
6 csvDictWriter.writeheader() #写入表头
7 for i in content:
8 csvDictWriter.writerow(i)
content是一个字典列表,键(key)是表头,值(value)是写入的内容,如果想要写入多行内容,则需要将每一行内容放入一个字典之中。第4行表头fields是一个列表,第5行fields被当作参数传入Writer对象中。第6行使用writeheader()函数将表头fields写入CSV文件第一行中。写入的文档如下图所示:

使用pandas库也可以将列表和字典写入CSV文件,需要使用pandas.DataFrame.to_csv()函数,该函数常用的参数除了sep和encoding之外,还有index。index代表文档是否输出行号,如果index=True代表单独输出一列从0开始的行号,index=False代表不输出行号:
1import pandas as pd
2#1. 列表写入
3content_list0 = ['麟','十','一']
4content_list1 = ['1', '2', '3']
5dataframe = pd.DataFrame({'字符': content_list0, '序号': content_list1})
6dataframe.to_csv('test_write2.csv', index=True, sep=',', encoding='gbk')
7#2. 字典写入
8content_dict = [{'字符': '麟', '序号': '1'}, {'字符': '十', '序号': '2'}, {'字符': '一', '序号': '3'}]
9dataframe0 = pd.DataFrame(content_dict)
10dataframe0.to_csv('test_write3.csv', index=False, sep=',', encoding='gbk')
#1将列表输入CSV文件,并且输出行号。#2将字典输出CSV文件并且不输出行号。从代码中可以发现,不论是将列表还是字典写入文件,都需要先创建DataFrame,之后将DataFrame输出到CSV文件中,创建的两个文件结果如下:
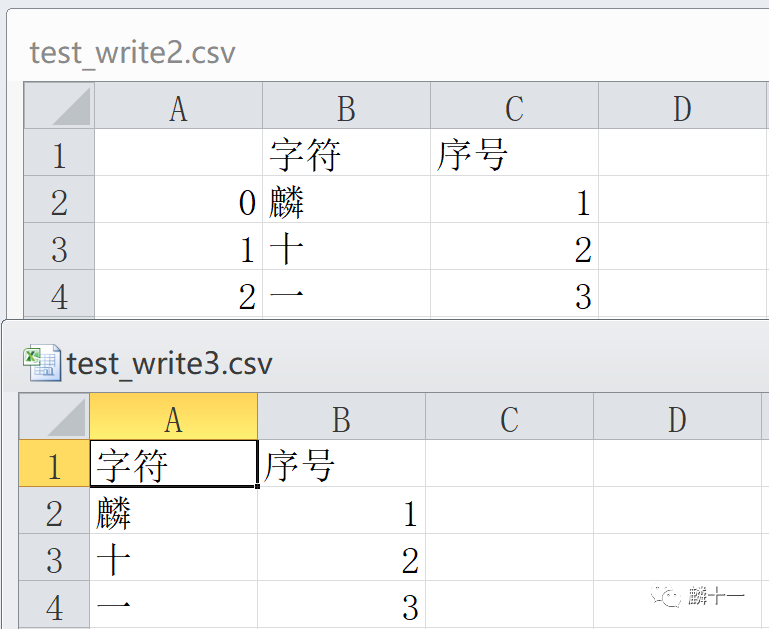
列表写入vs字典写入
 后来在工作中又用到对CSV的读取,就想把这两个都总结一下。但是在写CSV文件读写的时候,发现open()、read()和write()这些对文件的读写操作也是单独的一块内容,所以最后修修补补就成了两篇,目前这个系列应该还有一篇就结束了
后来在工作中又用到对CSV的读取,就想把这两个都总结一下。但是在写CSV文件读写的时候,发现open()、read()和write()这些对文件的读写操作也是单独的一块内容,所以最后修修补补就成了两篇,目前这个系列应该还有一篇就结束了
 挺好的,我又梳理清楚了一小部分内容,继续努力
挺好的,我又梳理清楚了一小部分内容,继续努力
 END
END ~
~
