




点击蓝字关注我们
应用之道
存乎一心


《Transformer》系列推文将要带大家了解什么是序列和注意力机制。阅读本系列推文需要具备一定的神经网络基础,读者可以参考本公众号的其它推文《【RNN】认识循环神经网络》、《【CNN】认识卷积神经网络》和《【BN】认识批量归一化》。
本系列推文分为三个部分:
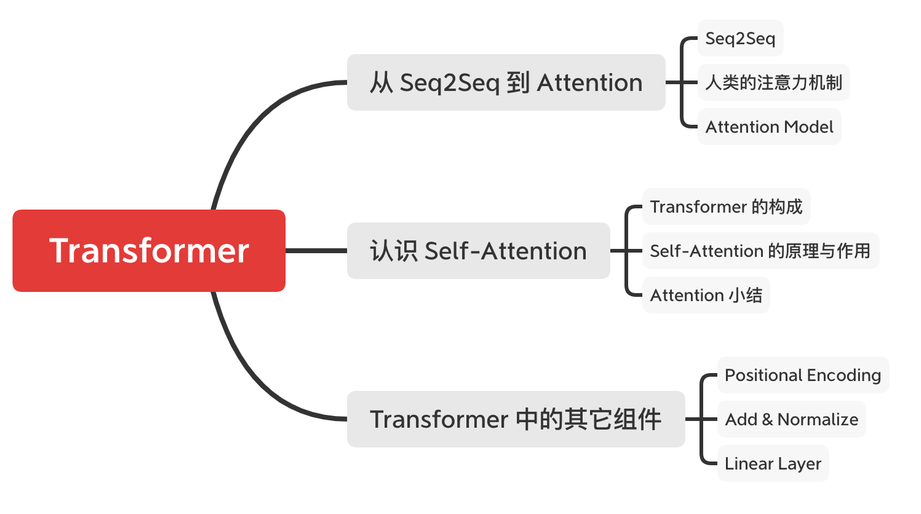
(一)从 Seq2Seq 到 Attention
(二)认识 Self-Attention
(三)认识其它重要组件
参考资料如下:
(一)谷歌 Ashish Vaswani 等 同名论文
(二)台大 李宏毅 《Transformer》
(三)美国 Jay Alammar 博客
(四)复旦 邱锡鹏 《神经网络与深度学习》
(五)谷歌、知乎及其它互联网资料
想要了解本系列推文所介绍的注意力机制,如果直接阅读谷歌论文(即参考资料一)会有很大困难。与之相比,李宏毅老师的课程(参考资料二)和 Jay Alammar 的博客(参考资料三)会更生动易懂,而邱锡鹏老师的著作(参考资料四)公式详尽且脉络清楚。但不同的参考资料的叙述逻辑有着较大差异,需要读者自行梳理。本文中如有错误,欢迎大佬们指正!
前言
注意力模型最近几年在深度学习各个领域被广泛使用。无论是在图像处理、语音识别还是自然语言处理的各种不同类型的任务中,都很容易见到注意力模型的身影。所以了解注意力机制的工作原理对于关注深度学习技术发展的技术人员来说有很大的必要。
以金融业为例,我们可以将客户的行为代表一连串的序列,但要从串行化的客户历程数据中萃取信息是非常困难的,如果能够将 Self-Attention 的概念应用在客户历程并拆解分析,就能探索客户潜在行为背后无限的商机。
然而,笔者翻阅众多资料发现鲜少有文章解释如何从 Seq2Seq 演进至 Attention Model,这一困境促使笔者决定编写本系列推文。
《Transformer》系列推文大量涉及本公众号的另外两个系列推文:《认识卷积神经网络》(以下简称《认识 CNN》)、《认识循环神经网络》(以下简称《认识 RNN》)。笔者建议读者先行阅读这两个系列文章避免知识盲区。
「插点题外话」专用小卡片
以下这段话摘自邱锡鹏的著作,笔者认为贴出这一段话非常有意义:
根据通用近似定理,前馈网络和循环网络都有很强的能力。但由于优化算法和计算能力的限制,在实践中很难达到通用近似的能力。特别是在处理复杂任务时,比如需要处理大量的输入信息或者复杂的计算流程时,目前计算机的计算能力依然是限制神经网络发展的瓶颈。
为了减少计算复杂度,通过部分借鉴生物神经网络的一些机制,我们引入了局部连接、权重共享以及汇聚操作来简化神经网络结构。虽然这些机制可以有效缓解模型的复杂度和表达能力之间的矛盾,但是我们依然希望在不“过度”增加模型复杂度(主要是模型参数)的情况下来提高模型的表达能力。
01
SEQUENCE-TO-SEQUENCE
介绍 Sequence-To-Sequence (简写 Seq2Seq)其实还真的不需要花上多大的篇幅,因为它的功能非常直观,甚至就和它的名字一样:序列转换成序列。

其动态效果如下图所示:

Seq2Seq 作为循环神经网络(RNN)最重要的一个变种,这种结构又被叫做 Encoder-Decoder 模型。
【Encoder-Decoder 模型】
Encoder-Decoder 模型结构如下图所示,主要包含 Encoder 和 Decoder 两个组件,这两个组件实际上都是 RNN 。Encoder-Decoder 模型就是将输入的一串序列进行处理后输出另一串序列。
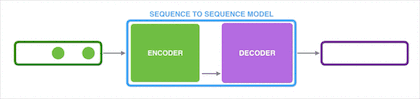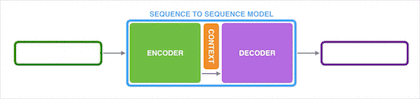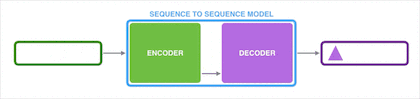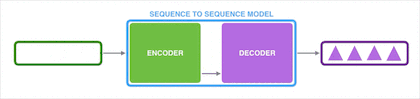
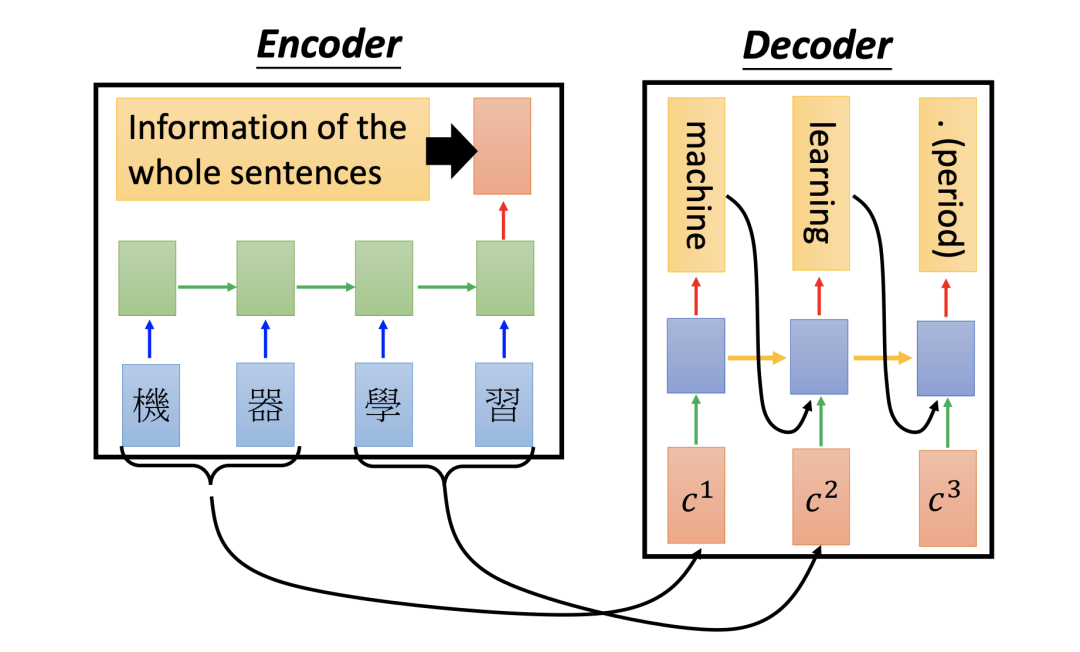
文本处理领域的 Encoder-Decoder 模型可以这么直观地去理解:它是一个可以将输入语句转换成其它语句的通用处理模型。例如,我们使用 Encoder-Decoder 模型去做中英翻译,如果输入序列“机器学习”,就会输出另一个序列“Machine Learning”。
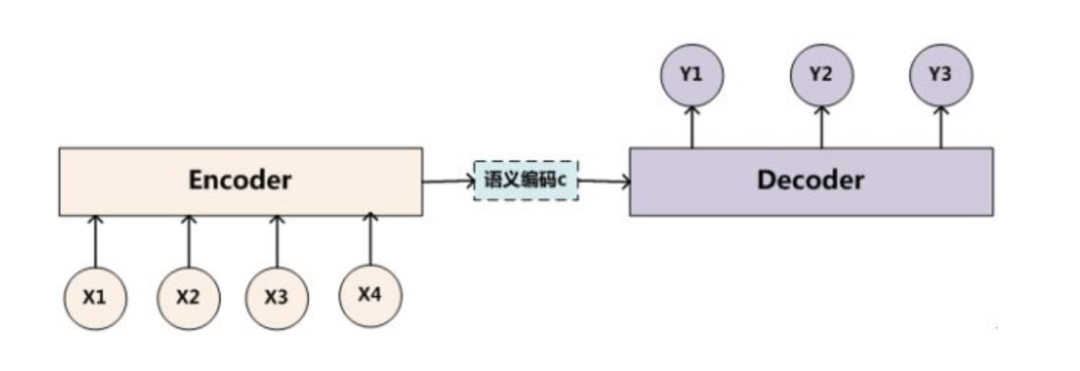
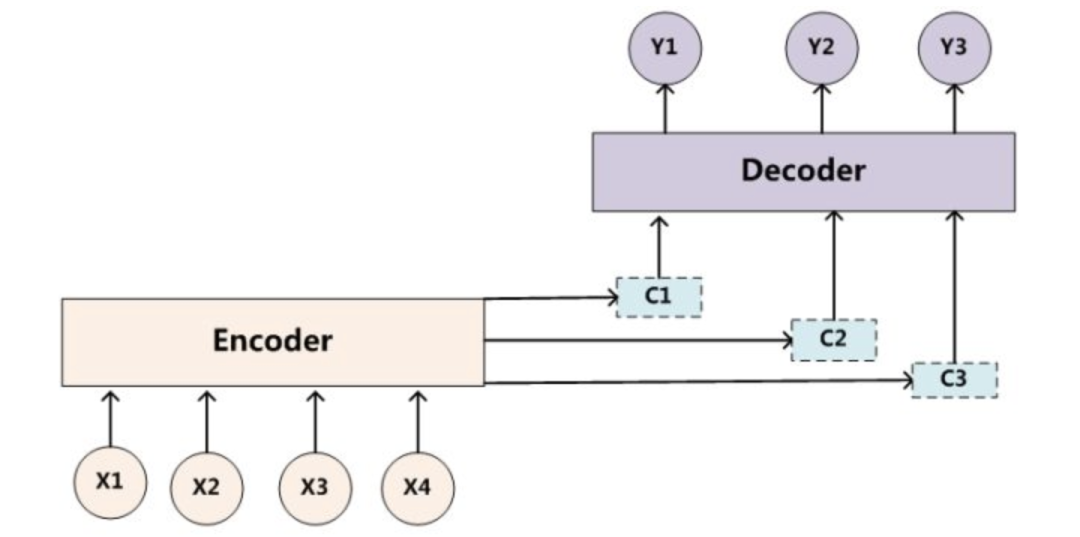
在机器翻译中,原始语言和目标语言的句子长度往往并不相同。为此, Encoder-Decoder 模型会先将输入数据编码成一个上下文向量 c(Contex Vector)。
得到上下文向量 c 的方式多种多样:
最简单的方法就是把 Encoder 的最后一个隐状态赋值给上下文向量 c。
对最后的隐状态做变换后得到上下文向量 c。
对所有的隐状态做变换后得到上下文向量 c。
获得上下文向量 c 之后,再将其通过 Decoder 解码得到输出序列。
【长程依赖问题带来缺陷】
但是上述的 Encoder-Decoder 模型还有些问题:基于卷积或循环网络的序列编码都是一种局部的编码方式,只建模了输入信息的局部依赖关系。虽然循环网络理论上可以建立长距离依赖关系,但是由于信息传递的容量以及梯度消失问题,实际上也只能建立短距离依赖关系。
也就是说,因为循环卷积网络的长程依赖问题,对于较长的句子,我们很难寄希望于将输入的序列转化为定长的向量而保存所有的有效信息。
由于 Encoder 和 Decoder 实际上都是 RNN,RNN 的长程依赖问题自然会影响 Encoder-Decoder 模型。
在 Encoder-Decoder 模型中,Encoder 把所有的输入序列都编码成一个统一的上下文向量 c 再解码,因此上下文向量 c 中必须包含原始序列中的所有信息。这样输入序列的长度就成了限制模型性能的瓶颈。所以随着所需翻译句子的长度增加,一个上下文向量 c 可能存不下那么多的信息,这种结构的效果也就会显著下降。
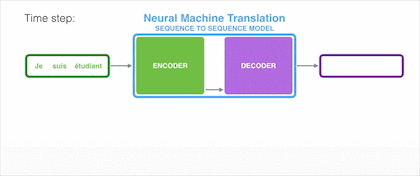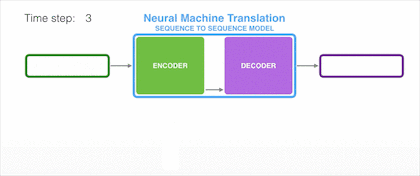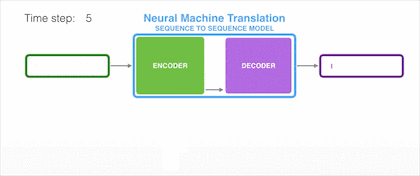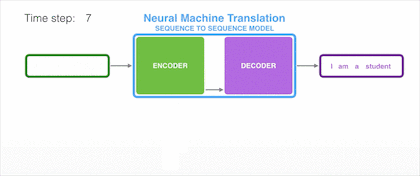
样例一:法语译英语
我们试着用动图演示将一段法语翻译成英语的过程:
上图的输入是每个需要被翻译的词向量,经过 Encoder 后依次产生隐藏状态 Hidden1、Hidden2。最后所有的内容都存放到上下文向量(Context Vector)中,既上图中最后一个隐状态 Hidden3。随后,隐状态 Hidden3 经过 Decoder 解码输出翻译后的语句。
为了解决上述问题,我们引入了注意力机制。
02
人类的注意力机制
神经网络中可以存储的信息量称为网络容量(Network Capacity)。一般来讲,利用一组神经元来存储信息时,其存储容量和神经元的数量以及网络的复杂度成正比。即是说要存储的信息越多,神经元数量就要越多或者网络要越复杂,进而导致神经网络的参数成倍地增加。
我们人脑的生物神经网络同样存在网络容量问题,人脑中的工作记忆大概只有几秒钟的时间,类似于 RNN 中的隐状态。而人脑每个时刻接收的外界输入信息非常多,包括来自于视觉、听觉、触觉的各种各样的信息。单就视觉来说,眼睛每秒钟都会发送千万比特的信息给视觉神经系统。人脑在有限的资源下,并不能同时处理这些过载的输入信息。大脑神经系统有两个重要机制可以解决信息过载问题:注意力和记忆机制。
因此,我们可以借鉴人脑解决信息过载的机制,从两方面来提高神经网络处理信息的能力:
一方面是注意力,通过自上而下的信息选择机制来过滤掉大量的无关信息。
另一方面是引入额外的外部记忆,优化神经网络的记忆结构来提高神经网络存储信息的容量。
视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,也就是一般所说的注意力焦点,而后对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其它无用信息。
这是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,是人类在长期进化中形成的一种生存机制,人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。
样例二:人眼的注意力机制
我们以下图为例:

当你第一眼看到这张图时,你所注意到的绝对是“锦江饭店”四个大字,而不是上方的电话号码又或者是后方的喜运来大酒家。

所以,在我们看一张图片的时候,人眼视觉对应的脑中映射其实是这样的:

上面所说的,就是我们的视觉系统的注意力机制,它将有限的注意力集中在重点信息上,从而快速获得最有效的信息。
深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标也是从众多信息中选择出对当前任务目标更关键的信息。
03
Attention Mechanism
为了解决版块一中所说的“长序列造成的信息损失瓶颈”,我们为 Seq2Seq 模型引入了注意力机制(Attention Mechanism)。
【Seq2Seq Models With Attention】
注意力机制跟人类翻译文章时的思路有些类似,即关注于我们想要翻译部分的上下文。在注意力模型中,当我们翻译某个词语时,我们会寻找源语句中与这个词相对应的词语,并结合之前的已经翻译的部分作出相应的翻译,而忽略其它无关紧要的词句。
样例三:中文翻译英文
如下图所示,当我们翻译“knowledge”时,只需将注意力放在原句中“知识”的部分。而当我们翻译“power”时,只需将注意力集中在"力量“。
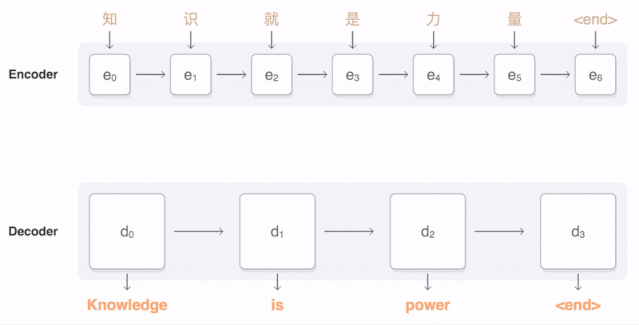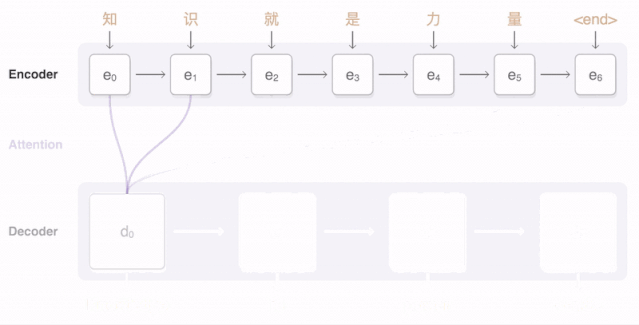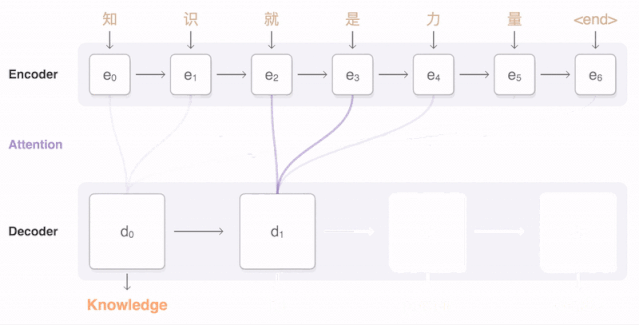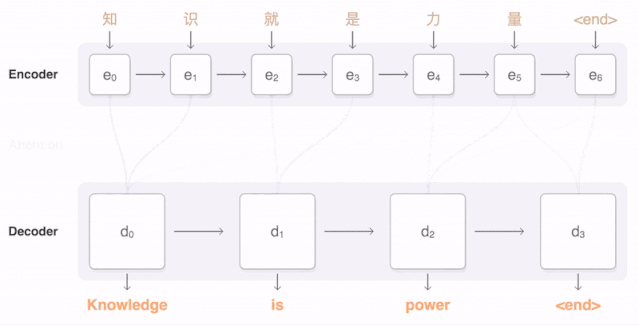
由上图可知,Decoder 做出翻译的时候可以看到 Encoder 的所有信息,而不再仅仅局限于原来模型中定长的隐藏向量,并且不会丧失长程的信息。
Seq2Seq 模型引入注意力机制的改进主要包括以下几个部分:
【Encoder 传递每一个时刻输入对应的隐状态】
注意力机制通过对每个时间的输入 xi 产生不同的上下文向量 ci 来解决输入长度瓶颈问题,下图是引入了注意力机制的 Seq2Seq 模型:
样例四:引入注意力机制的法语翻译英语
引入注意力机制后,Encoder 不再仅仅传输最后一个隐状态 Hidden3 给 Decoder,而是将每个不同时间点的输入产生的隐状态 Hidden1、Hidden2、Hidden3 一同传递给 Decoder。
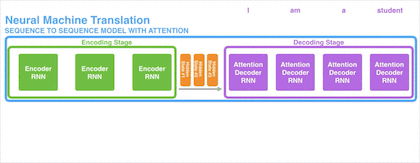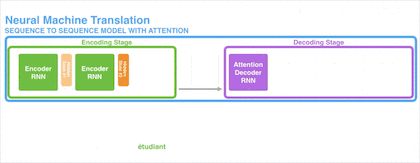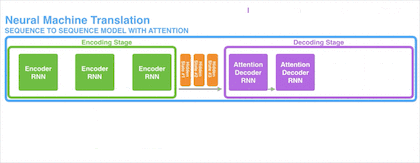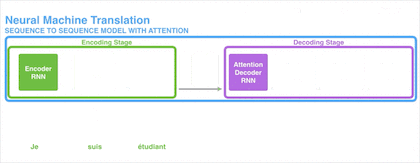
【Decoder 保持专注】
为了关注与此刻解码操作相关的输入信息,引入注意力机制的 Decoder 内部会在产生输出前执行一些额外操作:
Decoder 收到一连串 Encoder 输出的隐状态,这些隐状态都各自对应原输入的某个关键词。
Decoder 根据此刻自身的隐状态为每个 Encoder 输出的隐状态打分。
将上一步的得分使用 SoftMax 函数归一化后得到一组向量。Decoder 为高分向量赋予大权重,为低分向量赋予小权重,然后将这组向量加权求和,最后得到 Decoder 此刻的上下文向量。
这些操作的完整过程如下图所示:
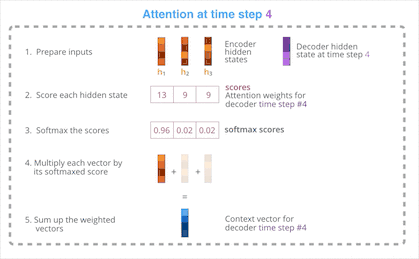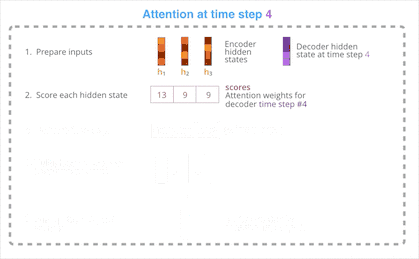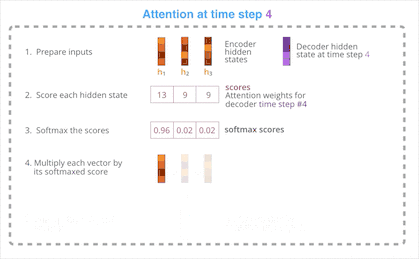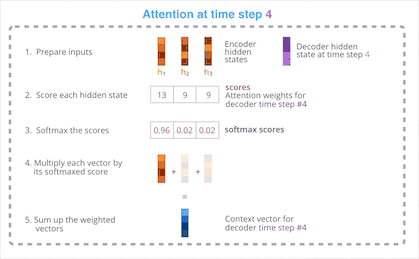
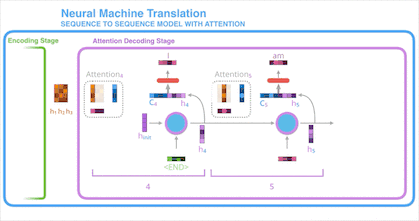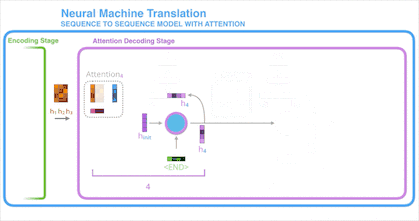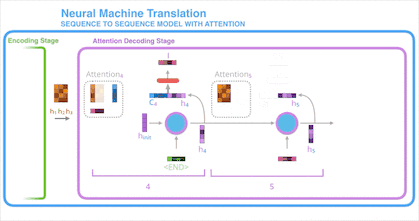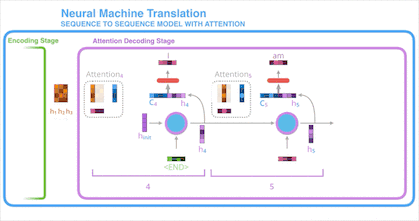
基于上述操作,Seq2Seq Models With Attention 的 Encoder 组件的完整运作方式分为以下几步:
引入注意力机制的 Decoder 中的 RNN 单元一开始会接收到语句终止令牌(<End> token)和一个初始的 Decoder 隐状态。
RNN 单元处理它的输入然后产生一个输出和一个新的隐状态向量(h4),随后将其输出丢弃。
在使用注意力机制这一环节,我们使用 Encoder的隐状态 h1、h2、h3 和 h4 向量去计算出这一时间点的上下文向量 C4。
将 h4 和 C4组合成一个向量并通过一个前馈神经网络,前馈神经网络的输出就代表这一时间点的输出词。
在每个时间点重复以上步骤。
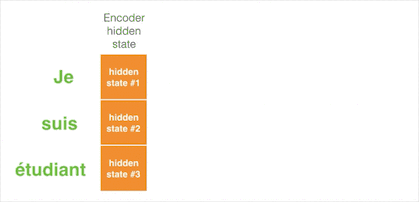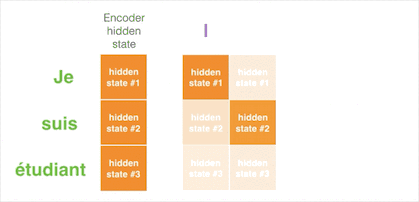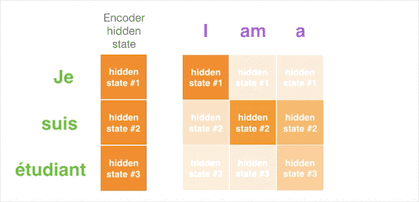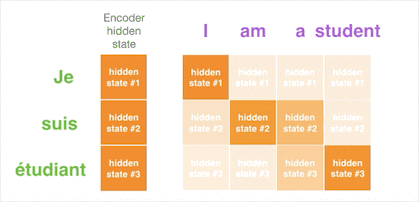
样例五:注意力机制的现实意义
就像人眼会关注重点信息一样,引入注意力机制的翻译器会重点关注与当前阶段相关的输入。如下图所示,我们能很直观的看到输出的单词与所有输入单词有关,但每个输出单词与每个输入单词相关程度不同。注意力机制就是让你在看遍所有信息的前提下,知道输出某个单词的一瞬间最应该关注哪些输入,方块的颜色越深代表输出的单词越关注这个输入单词:
04
MORE ABOUT ATTENTION
自从注意力机制在提出之后,引入注意力机制的 Seq2Seq 模型在各个任务上的效果都有了提升,所以现在的 Seq2Seq 模型指的都是结合 RNN 和注意力机制的模型。
如果把注意力机制从上文讲述例子中的Encoder-Decoder 模型中剥离并做进一步抽象,我们可以更容易看懂注意力机制的本质思想。
【Attention 抽象】
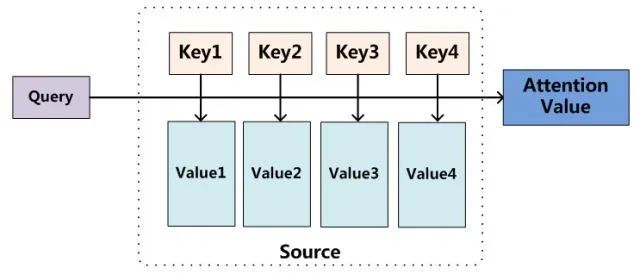
如下图所示,我们可以抽象看待注意力机制:
将输入向量(Source)中的元素想象成是由一系列键值对(Key, Value)构成。
为了从输入向量中选择出和某个特定任务(Target)相关的信息,引入一个和任务相关的表示,称为查询向量(Query),
通过一个打分函数来计算每个输入向量的键(Key)和查询向量之间的相关性,进而得到每个键对应的值( Value)的权重系数。
然后对所有值加权求和,即可得到了最终的注意力数值(Attention Value)。
其本质思想可以改写为如下公式:
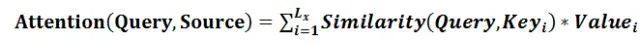
在上文所举的机器翻译的例子里,因为在计算注意力的过程中源向量中的键 Key 和值 Value 合二为一,指向同一个东西——输入单词的上下文向量 。
注意力机制的本质仍然是从大量信息中有选择地筛选出少量重要信息,并聚焦到这些重要信息上,同时忽略大多不重要的信息。聚焦的过程体现在权重系数的计算上,权重越大就越聚焦于其对应值上。即权重代表了信息的重要性,而值就是其对应的信息。
【Attention 计算】
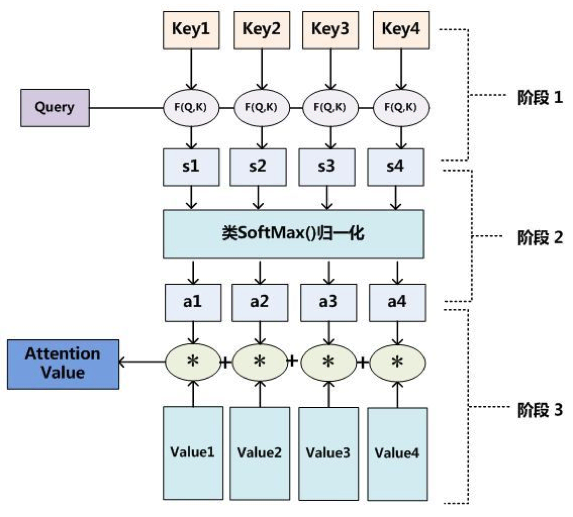
我们对目前大多数注意力计算方法进行抽象,可以将其归纳为三个阶段:
第一个阶段根据查询向量 Query 和键 Key 计算两者的相似性或者相关性,得到相应地分数。
第二个阶段对第一阶段的原始分数利用 SoftMax 进行归一化处理后得到权重系数。
第三个阶段根据权重系数对值进行加权求和。
整个计算过程如下图所示:
至此,本文带领大家初步认识了 Seq2Seq 模型和注意力机制,下一篇推文我们才正式进入正题,后续推文将讲解当前被广为应用的 Transformer 中极为重要的一个概念——自注意力模型(Self-Attention)。感谢大家的支持,我们下期再见!
应用之道
END
存乎一心

本文作者:Bingunner
一位头发浓郁的信息安全工程师
爱摄影/爱数码/爱跑步的经济学人死忠粉
