




点击蓝字关注我们
应用之道
存乎一心

本文承接《【Transformer】从 Seq2Seq 到 Attention》(以下简称“上文”),主要介绍 Self-Attention 机制及其应用。想要了解这部分内容强烈推荐 Jay Alammar 的博客,当然网上也会有很多翻译的版本(现有的翻译版本漏掉了原文很重要的部分内容,强烈建议阅读英文原博)。
前言
在上文中我们讨论了引入注意力机制的 Seq2Seq 模型,但该模型依旧会受到一些潜在问题的制约:
神经网络需要能够将原始语句的所有必要信息压缩成固定长度的向量。这可能使得神经网络难以应付长句子,特别是那些比训练语料库中的句子更长的句子。
每个时间步的输出需要依赖于前面时间的输出,这使得模型没有办法并行计算致使效率低下。
仍然面临对齐问题。
「插点题外话」专用小卡片
仔细研判上述问题,可以发现这些问题存在很大程度是因为它们使用了 RNN 模型:
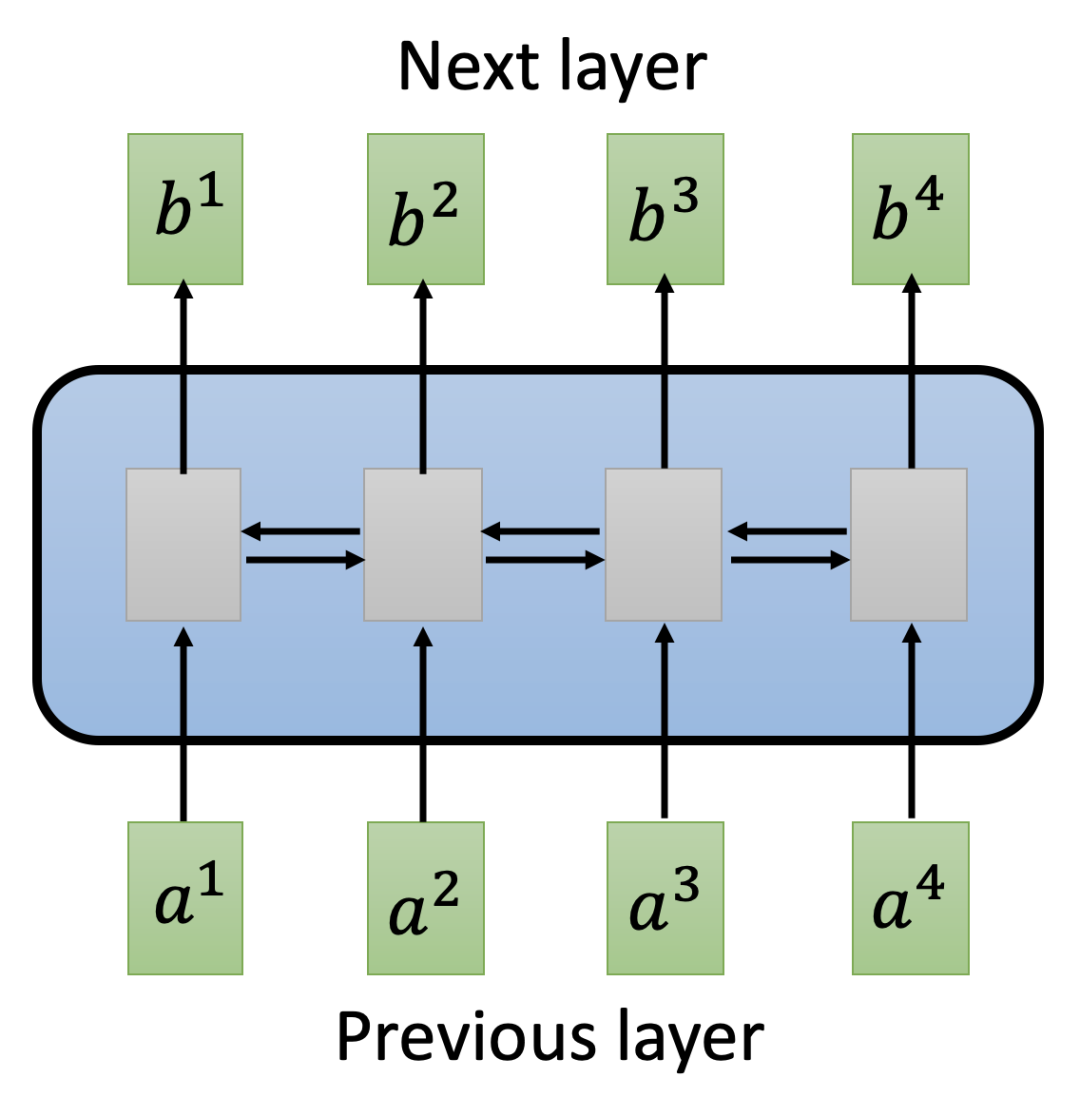
这很像马克思主义里的一个名词「阶级局限性」,翻译成大白话就是“因为你是你,所以你不行”。消除这种「阶级局限性」的方法只能是替换掉 RNN。
随着深度学习技术的发展,卷积神经网络(CNN) 被从计算机视觉引入到自然语言处理中。虽然 CNN 不能直接用于处理变长的序列样本,但它仍然可以实现并行计算。以下图为例,每种颜色的三角形代表一个过滤器,随着三角形的移动执行卷积操作:

可惜的是,完全基于 CNN 的 Seq2Seq 模型虽然可以并行运算但非常占内存,以至于在大数据量上参数调整并不容易。
自注意力(Self-Attention)的创新点就在于它抛弃了之前传统的 Encoder-Decoder 模型必须结合 CNN 或者 CNN 的固有模式,而只使用注意力模型。其主要目的在于减少计算量和提高并行效率,同时不损害最终的实验结果。
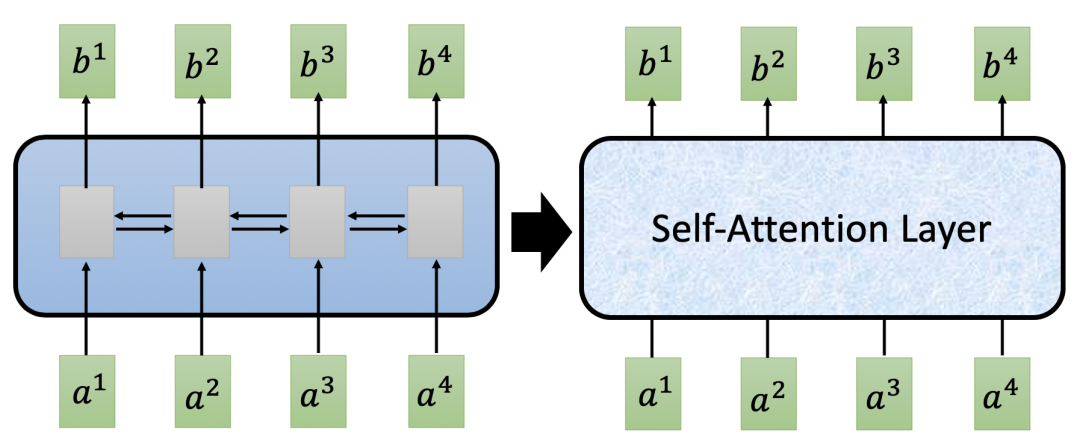
如上图所示,我们可以使用一个自注意力层(Self-Attention Layer)替换掉一个双向 RNN 单元。可以说自注意力提出的目标就是“去他妈的 RNN”。
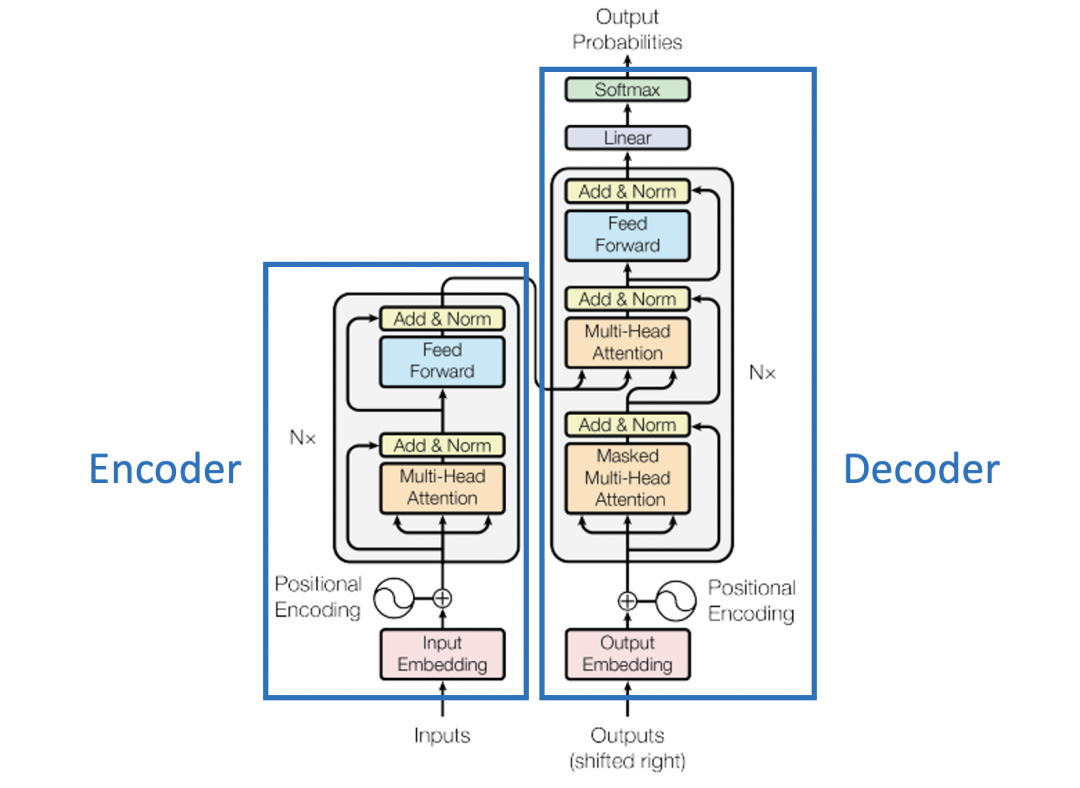
Self-Attention 是 Transformer 中非常重要的一部分,但 Transformer 的结构非常复杂,本文将拆解 Transformer 的各个组件逐一讨论。Transformer 的结构如下图所示:
01
A HIGH_LEVEL LOOK
为了更好的理解 Transformer 的结构,我们采取一种自顶向下、从整体到组件的思路进行分析。首先,我们将其整体抽象成以下的模型:

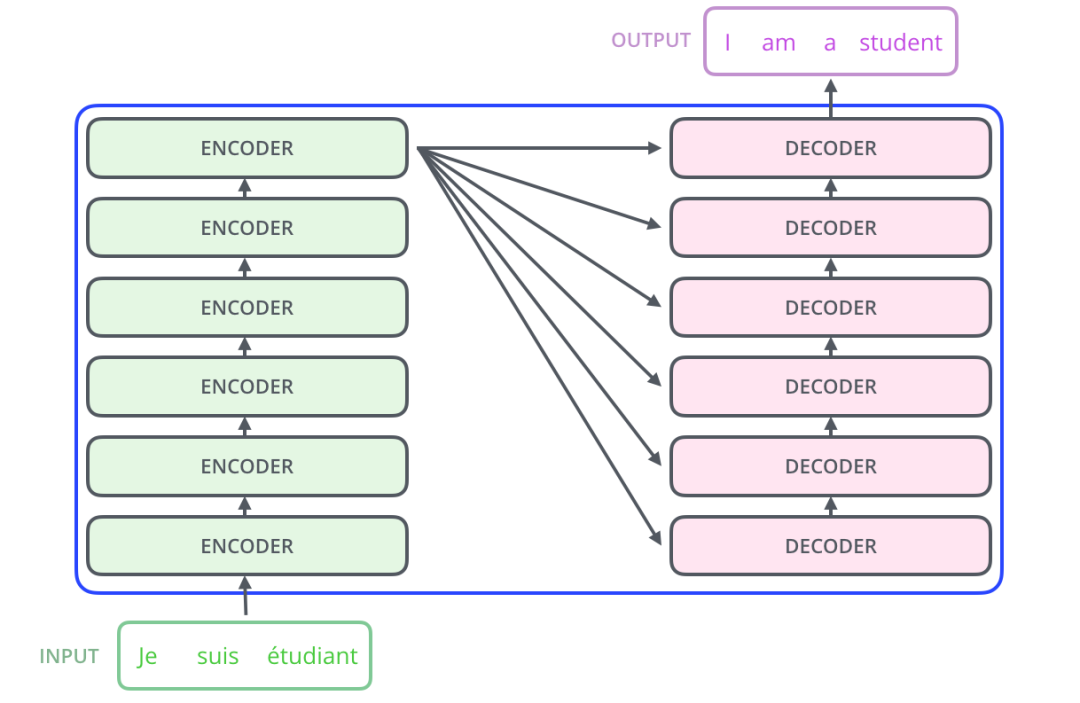
可以看出上图其实就是一个 Seq2Seq 模型,它可以进一步拆解成 Encoders 和 Decoders 的组合。如下图所示,左边 Encoders 输入一串序列,右边 Decoders 输出另一串序列:
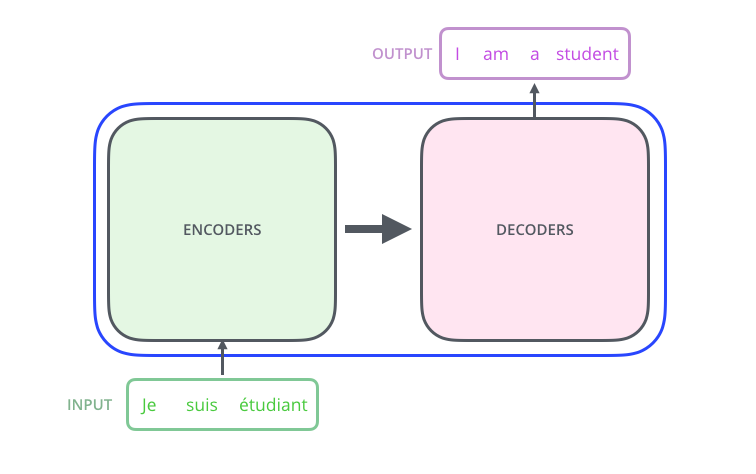
实际上,Encoders 是多个 Encoder 的堆叠(原论文使用的是六个 Encoder 的堆叠),每个 Decoders 使用的是同样数量的 Decoder 的堆叠。
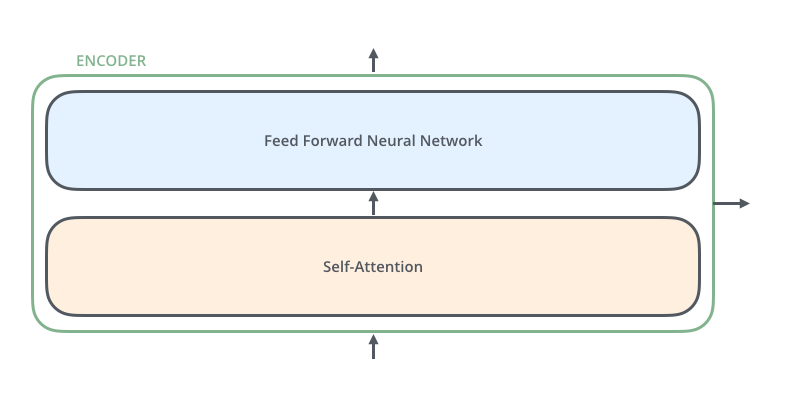
上图 Encoders 中的每个 Encoder 都是完全相同的(它们之间并不会共享参数),每个 Encoder 又可以拆分成两个层——前馈神经网络层(Feedforward Neural Network,FNN)和自注意力模型层(Self-Attention)。
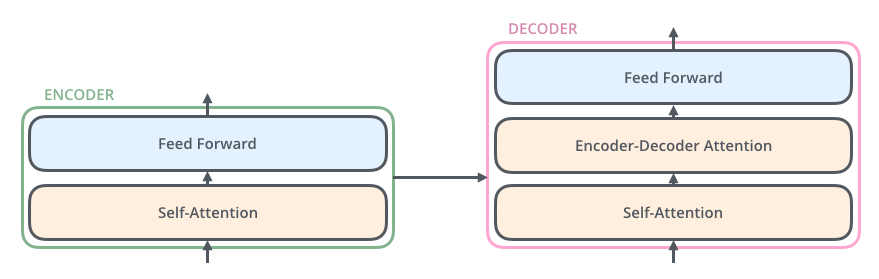
Self-Attention 层帮助 Encoder 在编码输入语料的某个词汇时还能够“看到”输入语料中的其它词汇。Self-Attention 层的输出又会传入一个 FNN 层(Encoder、Decoder 的各个 FCC 是独立的)。
相较于 Encoder,Decoder 多出了一个中间层—— Encoder-Decoder Attention 层。Decoder 中的 Self-Attention 层关注当前翻译词汇和已经翻译的前文之间的关系,而 Encoder-Decoder Attention 层则关注当前翻译词汇和输入的特征向量之间的关系。
02
SELF-ATTENTION IN DETAIL
上一部分我们描述了 Transformer 的两个重要组件—— Encoders 和 Decoders,接下来我们将介绍数据如何在这些组件之间传递。
一般地,我们在自然语言处理过程中,首先会使用词嵌套算法(Word Embedding Algorithm)将输入的文字序列转换成一组特征向量。

对于 Encoders 而言,仅最底层接收输入语料的那个 Encoder 需要运行 Word Embedding Algorithm。它会将输入语料转换为一组特征向量。特征向量的维数是超参数可以自行设定,它通常会被设为训练集中最长语句的长度(论文中使用的是一组512维向量)。其余的 Encoder 只需要处理底层 Encoder 传递过来的特征向量并在处理后输出一个新的特征向量给上层 Encoder 。
输入语料会被 Embedding 成特征向量。每一组特征向量会通过 Encoder 的两个层次——FNN 层和 Self-Attention 层。
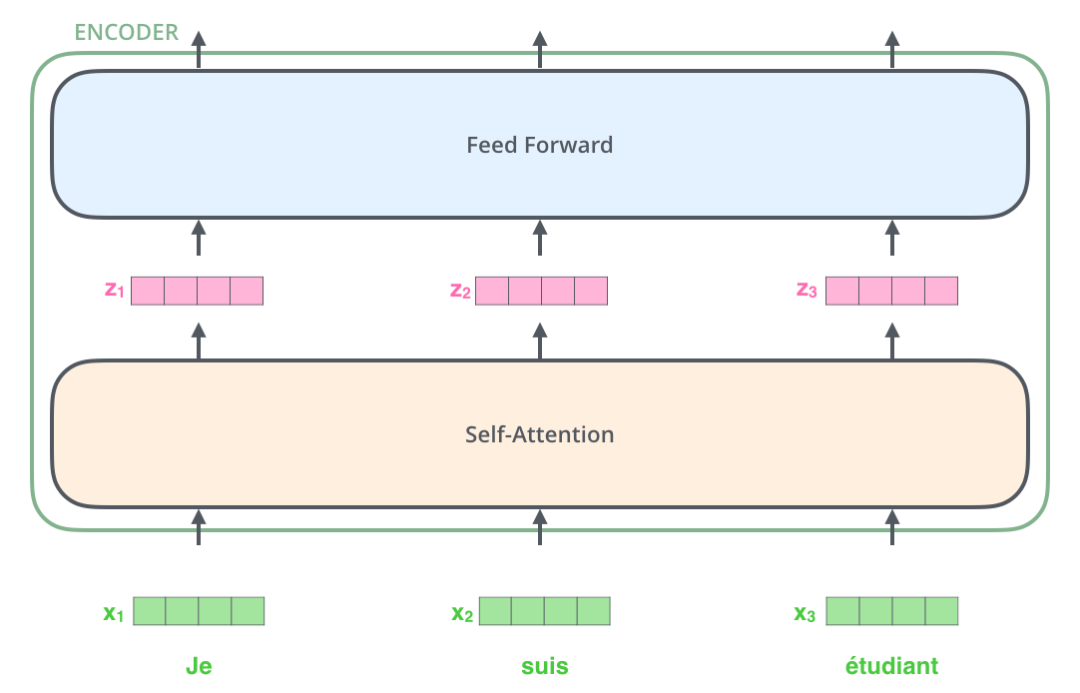
以上图为例,我们说明 Transformer 的一个重要特性。在上图中不同时刻的输入x1、x2、x3 通过 Self-Attention 层,它们之间是有依赖性的(因为 z1 会包含 x1、x2、x3 的信息,z2、z3也是同理),所以这个过程无法并行计算。但 z1、z2、z3 通过 FNN 层并没有这种依赖关系,因此 z1、z2、z3 在通过 FNN 层时可以并行计算。
为了体现“并行计算”这一特点,针对两个时刻的输入,下图将 FNN 层拆分成两个部分,Encoder1 中的特征向量通过 FNN 层后直接传递到 Encoder2。
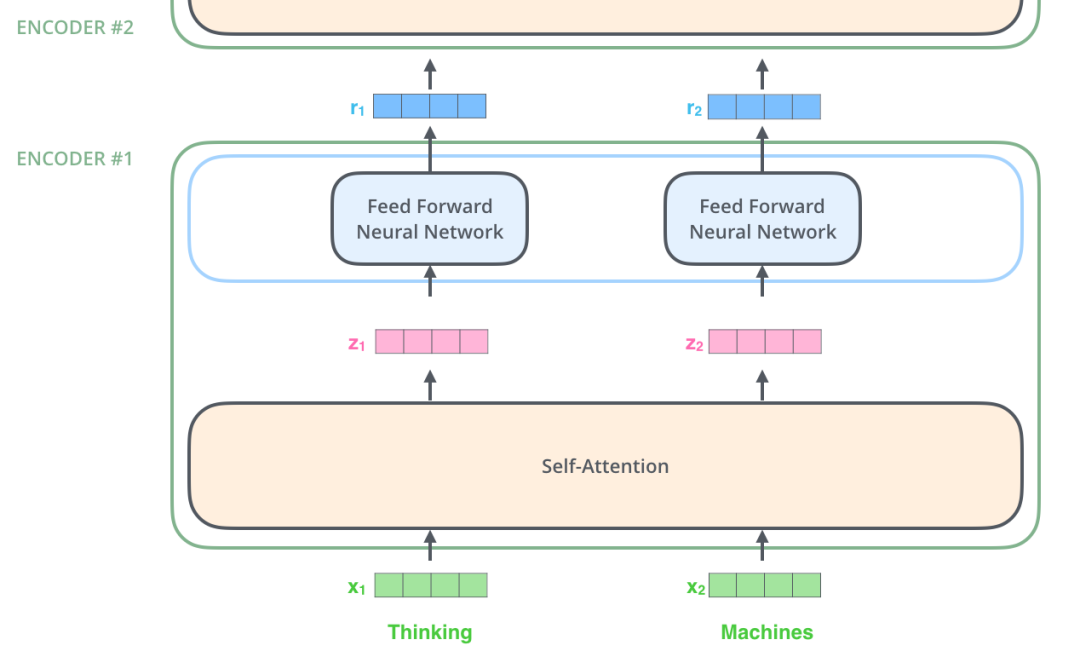
【聊聊 Self-Attention】
在上文中我们已将介绍键值 Attrntion 模型,那 Self-Attention 与 Attention 的区别是什么?
传统的 Attention 是基于源端(Source)和目标端(Target)的隐变量(Hidden state)计算注意力值,其得到的结果是源端的每个词与目标端每个词之间的依赖关系。但 Self-Attention 不同,它分别在源端和目标端进行,仅与源端的输入或者目标端的输入自身相关。Self-Attention 可以捕捉源端或目标端自身的词与词之间的依赖关系,然后再把源端的得到的 Self-Attention 加入到目标端得到的 Self-Attention 中,捕捉源端和目标端词与词之间的依赖关系。
Self-Attention 比传统的 Attention Mechanism 效果要好的主要原因是:传统的 Attention Mechanism 忽略了源端或目标端句子中词与词之间的依赖关系。相对而言,Self-Attention 不仅可以得到源端与目标端词与词之间的依赖关系,同时还可以有效获取源端或目标端自身词与词之间的依赖关系。
Attention 中使用 Key、Value、Query 三个特征向量来计算注意力值,其中 Key 和 Value 来自于输入向量,Query 代表输入向量和目标任务之间的相关信息。例如,我们翻译“I am a teacher”这一句话,Query 就代表输入“I am a teacher”和输出“我是一个老师”之间的相关性。
Self-Attention 同样使用 Key、Value、Query 三个特征向量来计算注意力值,但它的“Self”体现在 Query 的含义上。与 Attention 不同,Self-Attention 的 Query 表示的是输入向量自身的相关信息。例如,我们翻译“I am a teacher”这一句话,Query 就代表“I”、“am”、“a”、“teacher”这几个词之间的相关性。
样例一:Self-Attention 的作用
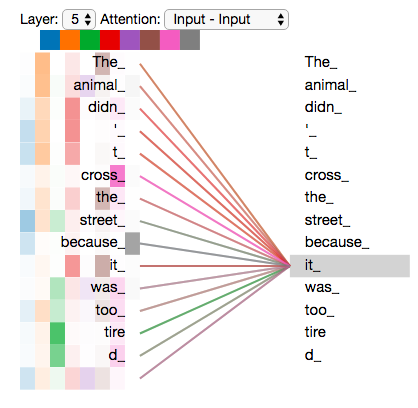
Self-Attention 模型可以帮助梳理输入语料词汇之间的关系。我们以翻译“The animal didn't cross the street because it was too tired”为例。通过 Self-Attention 模型我们可以找到这句话各个词汇之间的关联关系。

在上图中,连线代表两个词汇相关,颜色越深代表词汇之间的相关程度越大。我们可以发现“it”与“animal”、“street”等多个词汇有关,而这恰也好与我们的语言逻辑相符。
总的来说,Self-Attention 的 Key、Value、Query 三个特征向量均来自于输入特征向量。
样例二:自注意力值的计算
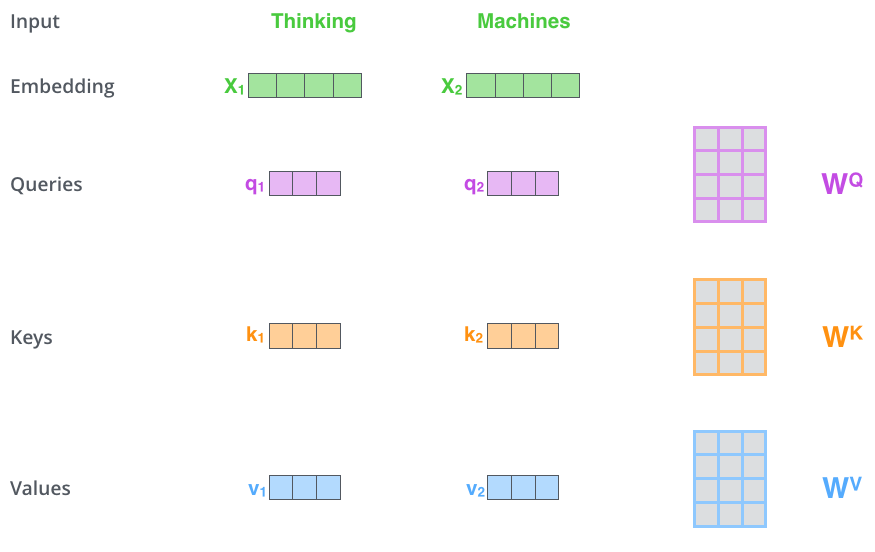
我们以下图为例计算自注意力值。第一步,我们有输入特征向量 xi,权重矩阵 W。xi 乘上 WQ 后得到 qi,xi 乘上 WK 后得到 ki,xi 乘上 WV 后得到 vi。
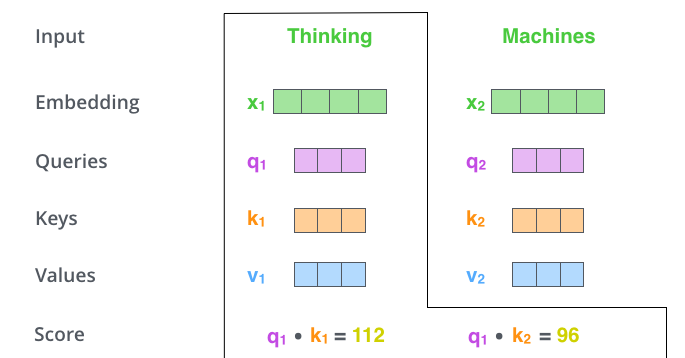
第二步,利用 qi 乘上 ki 计算得分。
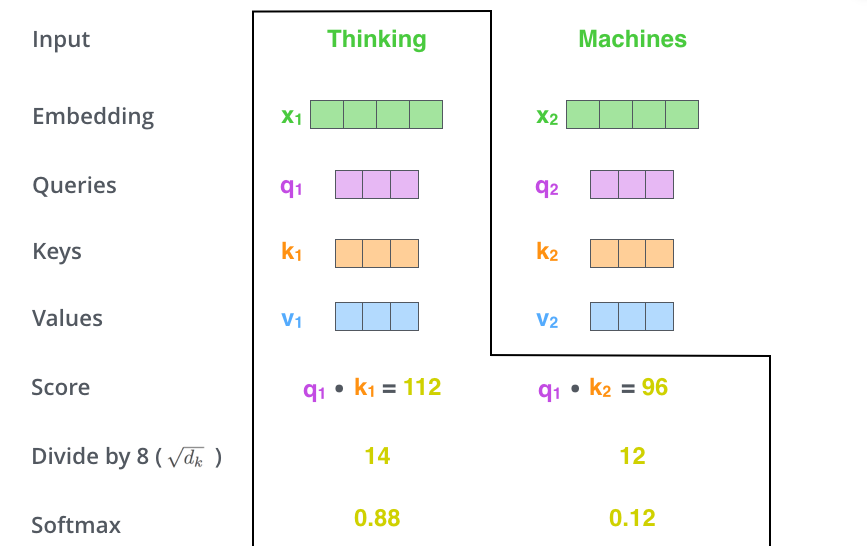
第三步,为了梯度稳定,Transformer 将得分归一化,即除以 √dk(dk 代表特征向量的维数,途中 64 维开放后得到 8)。为了使数值均为正数且和为 1,归一化后的数值将通过一个 SoftMax 激活函数。激活函数的输出表示 xi 对应的 Value 向量在这一时刻的相对重要程度。Value 向量越重要,激活函数的输出数值越大,反之越小。
第四步,SoftMax 激活函数的输出值乘上每个 Value 向量 。这一步是为了让我们保持此刻想关注的 Value 向量(即乘上一个大的 SoftMax 输出值),同时削弱与此刻无关的 Value 向量(即乘上一个小的 SoftMax 输出值,如0.0001)。
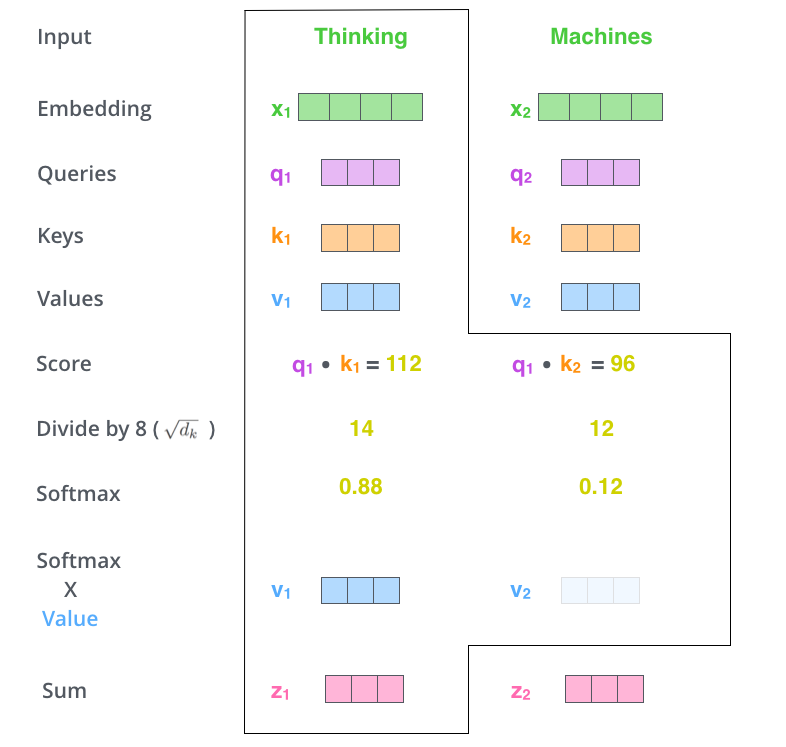
第五步,将加权后的 Value 向量相加后得到这一时刻 Self-Attention 层的输出。
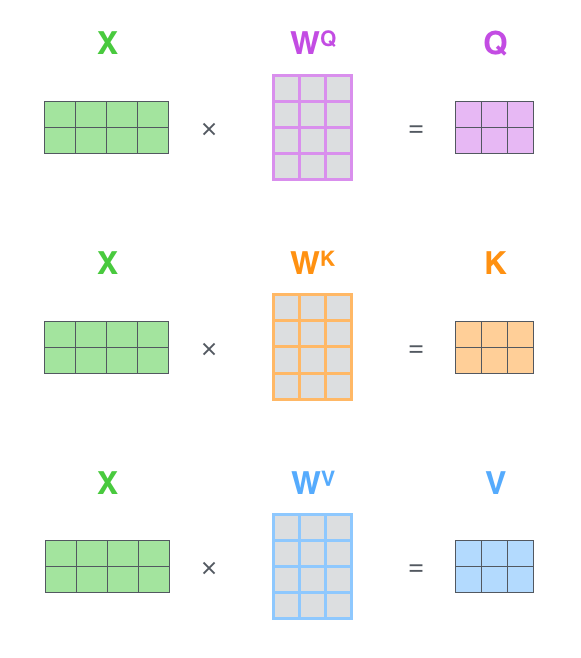
样例二的第一步可以用下图的矩阵运算表示:
其它步骤可以用下图的矩阵运算表示:
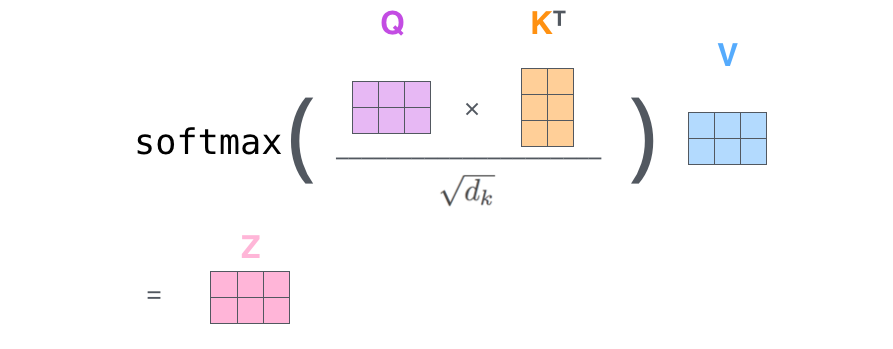
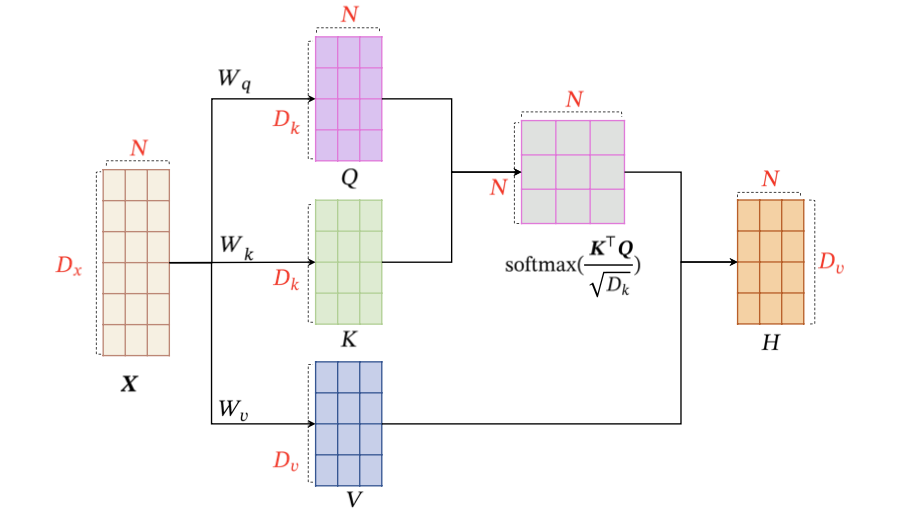
所以,我们可以用一系列矩阵的运算来计算 Self-Attention, 其完整的计算步骤可以用下图表示:
【聊聊 Multi-Head Self-Attention】
Transformer 的原始论文中还介绍了一种 Multi-Head Self-Attention 模型(有点像 CNN 中多个过滤器的效果),它提高了 Self-Attention 的性能:
拓展了模型关注输入序列不同位置词汇的能力。比如,我们在翻译 “The animal didn’t cross the street because it was too tired”这句话时,就可以知道句子中的“it”指的是什么。
为 Attention 层提供了多个表示子空间(Representation Subspaces)。这个理解起来并不困难,1 路 Self-Attention 输出一个表示空间,那 8 路 Self-Attention 自然就可以输出 8 个 表示子空间。
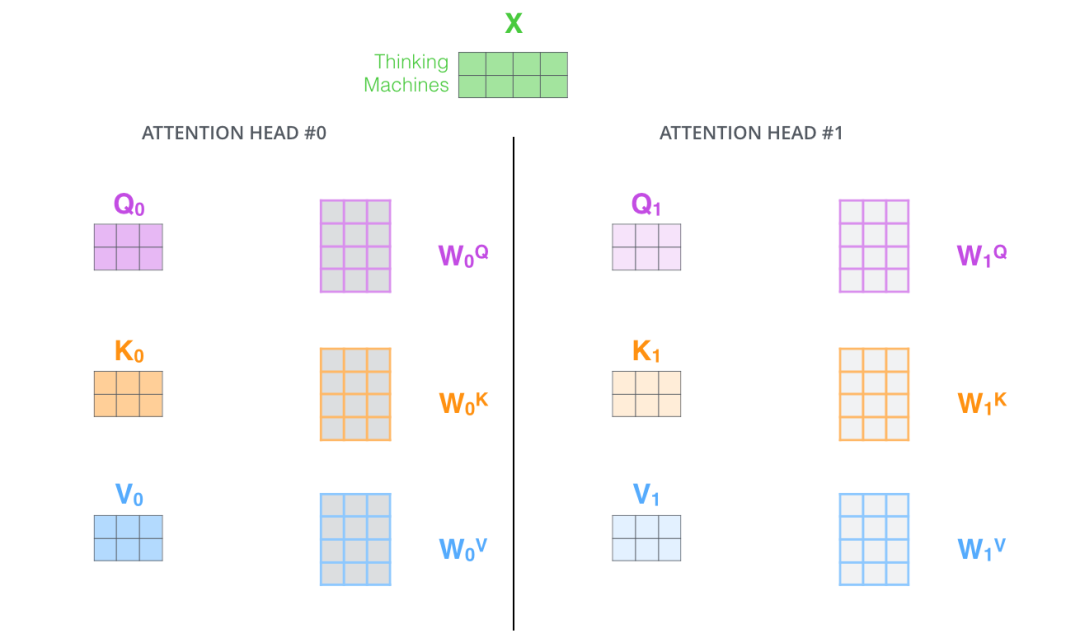
样例三:Multi-Head Self-Attention 计算
我们以 8 路 Self-Attention 为例,我们只需要对于输入特征向量 X 使用 8 个不同的权重矩阵总共计算 8 次,就能得到 8 个不同的 Self-Attention 输出矩阵 Zi。
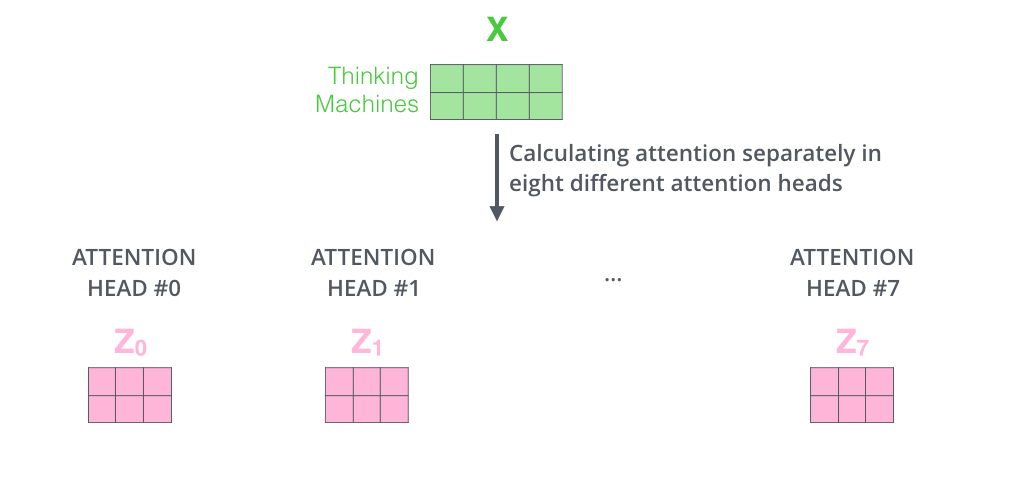
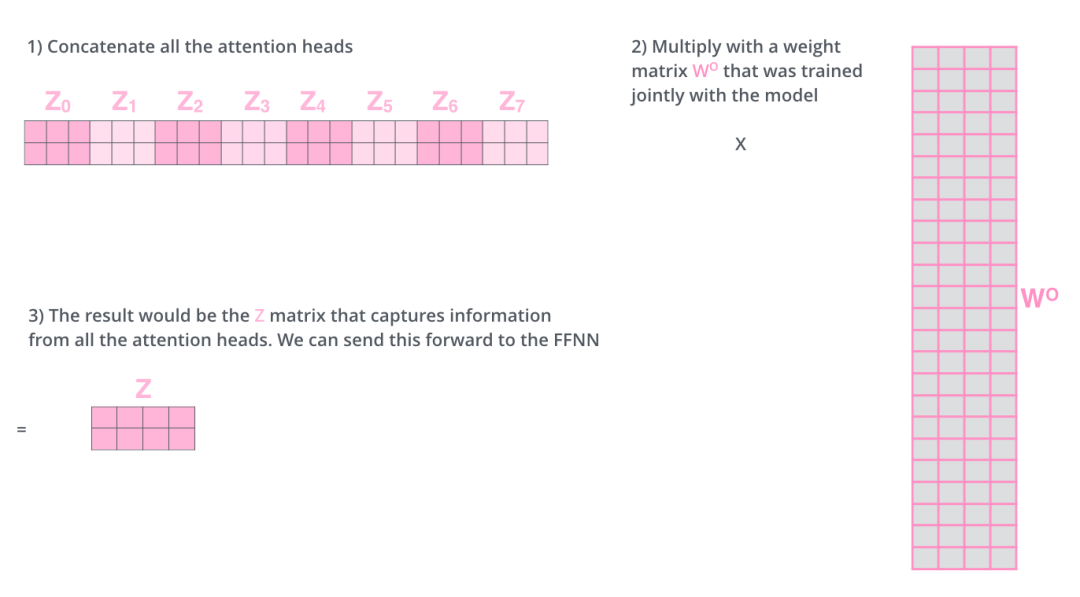
对于 FNN 来说处理 8 个矩阵是比较棘手的。因此,我们需要想个办法让 8 个矩阵变成一个矩阵。
如下图所示,我们首先将 8 个矩阵 Zi 拼接成一个矩阵,然后乘上一个 Wo 矩阵(Wo 矩阵可与模型一同训练得到),最后得到一个新的特征矩阵 Z。
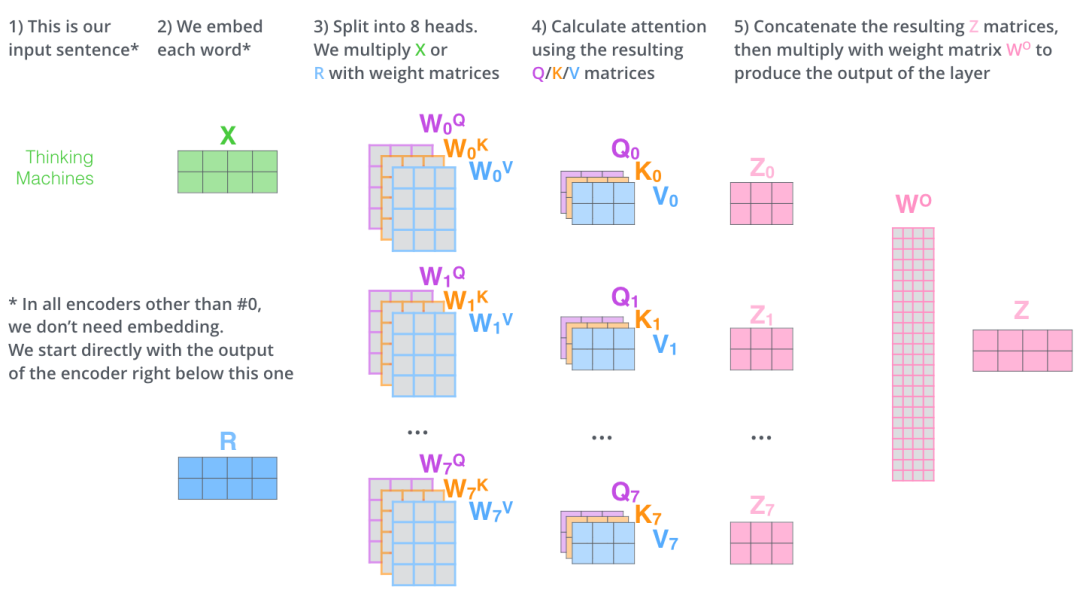
样例三完整计算过程可以用以下矩阵运算表示:
样例五:Multi-Head Self-Attention 的作用
我们还是使用样例一中的翻译任务做例子,只不过本例中使用的是 Multi-Head Self-Attention 模型。
下图我们使用了两路 Self-Attention,其中一路(橙色)反映出“it”与某些词汇有关,另一路(绿色)反映出“it”与其它词汇有关:

下图我们使用了八路 Self-Attention,整体效果与上图类似,只不过变得更加复杂:
03
CONCLUSION
从两篇推文的描述中,我们可以大致感受到注意力机制的作用。我们可以用“带权求和”四个字高度概括这一机制。做个不太恰当的类比,人类学习一门新语言基本经历四个阶段:
死记硬背(通过阅读背诵学习语法练习语感)。
提纲挈领(简单对话靠听懂句子中的关键词汇准确理解核心意思)。
融会贯通(复杂对话懂得上下文指代、语言背后的联系,具备了举一反三的学习能力)。
登峰造极(沉浸地大量练习)。
这也如同注意力机制的发展脉络,RNN 时代是死记硬背的时期,注意力模型学会了提纲挈领,进化到 Transformer 做到了融汇贯通同时也具备优秀的表达学习能力,再到 GPT、BERT 通过多任务大规模学习积累实战经验最终战斗力爆棚。
至此,我们认识了 Transformer 的整体结构和其中的重要概念—— Self-Attention。下一文我们将继续介绍 Transformer 的其它组件,感谢大家的关注,我们下期再见!
应用之道
END
存乎一心

本文作者:Bingunner
一位头发浓郁的信息安全工程师
爱摄影/爱数码/爱跑步的经济学人死忠粉
