




点击蓝字关注我们
应用之道
存乎一心


《不服就干--生成对抗网络》一文将带大家了解什么是听起来酷炫用起来牛逼的生成对抗网络(GAN)。阅读本文不需要任何基础哦,大家赶紧搬起小板凳来围观吧!
本文参考资料如下:
(一)台大 李宏毅 《机器学习》
(二)复旦 邱锡鹏 《神经网络与深度学习》
(三)谷歌开发者平台及其它互联网资料
本文中如有错误,欢迎大佬们指正!
前言
生成对抗网络(Generative Adversarial Networks,GAN) 是通过对抗训练的方式来使得生成网络产生的样本服从真实数据分布。在生成对抗网络中,有两个网络进行对抗训练:
一个是判别网络(Discriminator Network),目标是尽量准确地判断一个样本是来自于真实数据还是由生成网络产生。
另一个是生成网络(Generator Network),目标是尽量生成判别网络无法区分来源的样本。
这两个目标相反的网络不断地进行交替训练。当最后收敛时,如果判别网络再也无法判断出一个样本的来源,那么这也就等价于生成网络可以生成符合真实数据分布的样本(听起来有点像图灵测试呢 XD)。
由于本文非常之长长长长长,读者可以按照导图顺序自行取食:
「插点题外话」专用小卡片
神经网络就像是门“玄学”,稀里糊涂地调了某些参数网络的性能可能就变好了,稀里糊涂地调了另一些参数网络的性可能又变差了,因而神经网络的训练过程也经常被戏称为“炼丹”。相比之下,笔者觉得神经网络的训练更像是考试,反复的训练就像是日常模拟,应用实践就像是高考验收。基于这一假设,GAN 的生成网络就像是学生在进行模拟考,判别网络就像是老师在打分。学生根据老师的打分不断提高自身应试能力,老师则根据学生成绩不断提高自身教学能力。
以上这个例子仅仅说明生成网络和判别网络能够互利共赢,但还没有说明两着缺一不可呦!就像好学生完全可以自学成才,好老师也可以圈地自萌一样。很可惜的是,生成网络和判别网络的关系并不完全像师生关系,因为它们有着各自无法忽视的缺点。为此,这里引用李(wo)宏(de)毅(sheng)老(huo)师(jing)的(li)一个例子。
工作过的人都会发现企业之中通常会有这样一种人,他们善于提建议,但眼光仅仅局限于自己的工作范围。这类人通常是下级,他们缺乏大局观,就像生成网络一样。企业之中当然还会有另一类人,他们善于否决建议,指点江山,激扬文字,但让他们提出可行的方法时又一声不吭。而这类人通常是领导,他们缺乏底层实践能力,就像判别网络一样。

如果你已经理解了上面两个例子。那么恭喜你,你可能已经知晓了生成对抗网络的「内涵精神」!
01
BASIC IDEA
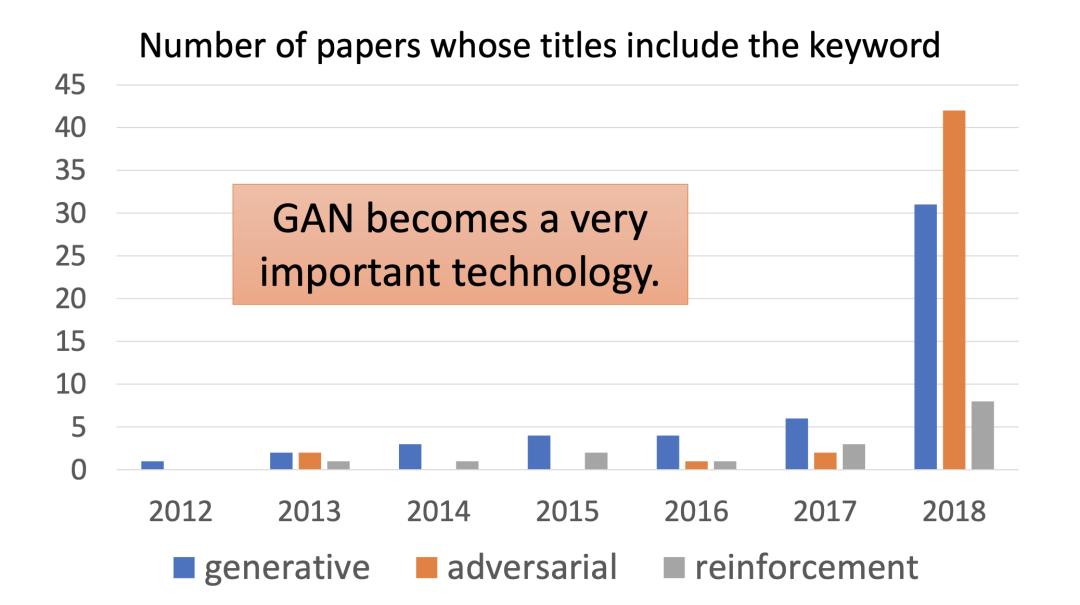
GAN 近些年来可谓是异常火热,我们可以从相关文献的数量对此可见一斑。毫无疑问,GAN 已经成为一项重要的深度学习技术,甚至还有人认为:GAN 是有史以来最酷炫的无监督学习技术!
从前言中我们可以知道 GAN 包含两个重要的组成部分——生成网络和判别网络。两者交替训练得到最后的模型。想要完全理解 GAN 的工作原理还是需要从生成网络和判别网络切入。
生成网络
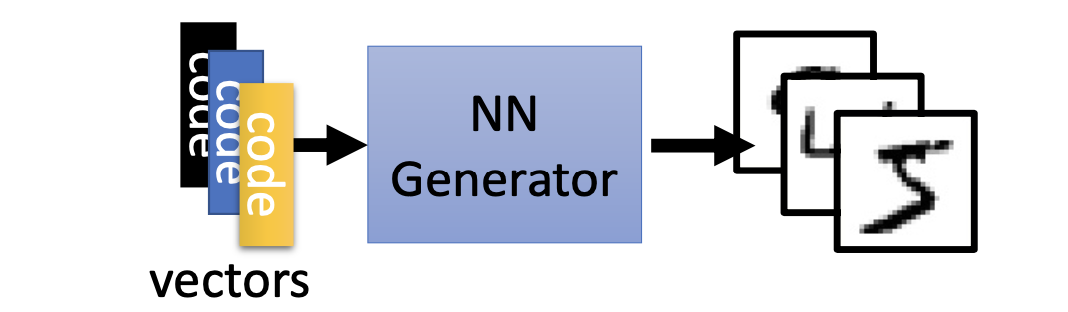
在 GAN 中我们想要训练的东西是生成器(Generator)。生成器其实是一个神经网络,它的输入是一个向量(Vector),输出则是一个更高维的向量,如下图所示:
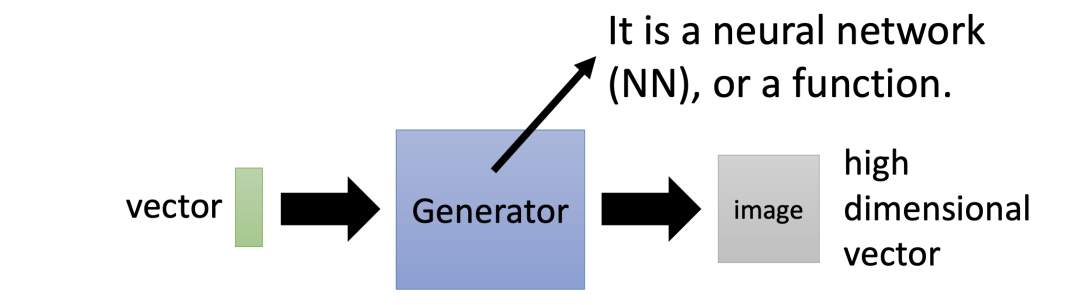
样例一:生成器的应用
对于生成器而言,它的用途是多种多样的。比如,我们可以利用输入向量,经过生成器后得到一组输出图片:

同理,我们也可以利用生成器得到想要的语句:

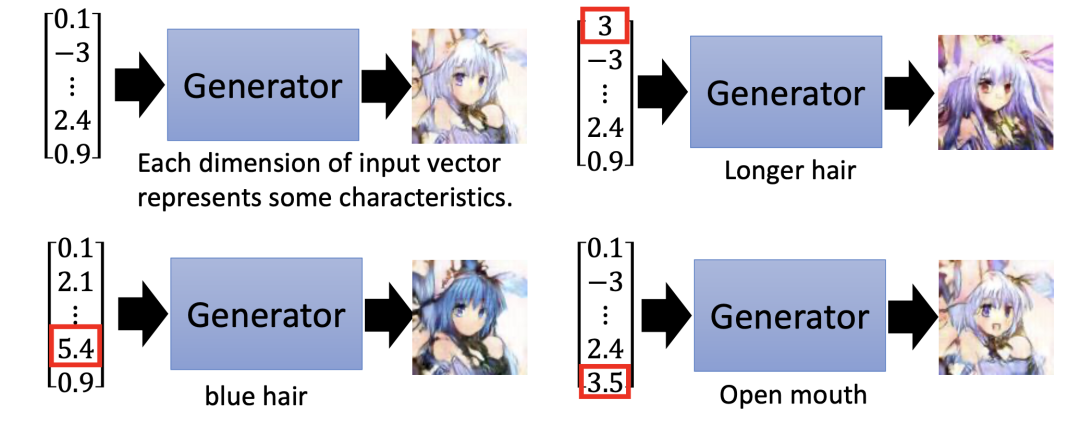
对于输入向量而言,它的每一个维度可以代表图片某种特征,当我们改变这个维度时,这个特征就会发生改变。比如,我们假设向量的第一个维度代表头发,当该维度值改变后,动漫人物头发的颜色就会变化:
判别网络
在 GAN 中还会训练出一个判别器(Discriminator)。判别器也是一个神经网络,它的输入是一个高维向量(如一张图片),输出是一个数值。输出值用于判断输入图片的质量,输出值越高表示输入图片越真实。
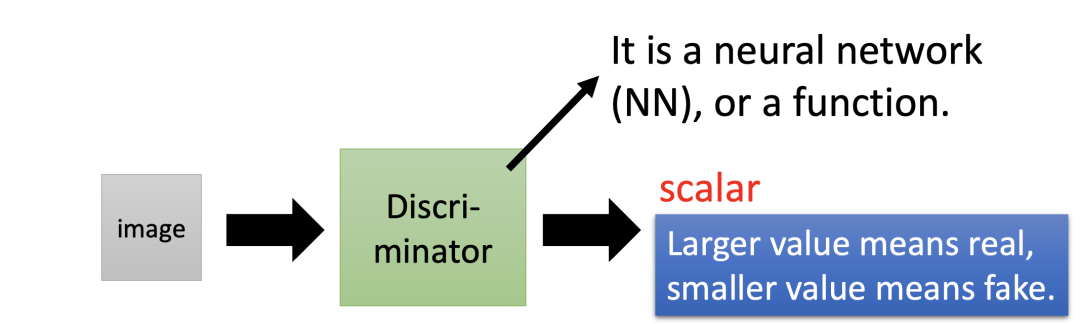
样例二:判别器的应用
假设我们有一组动漫人物头像,并将其丢入到判别器中,然后判别器输出一个 0 到 1 之间的数值。
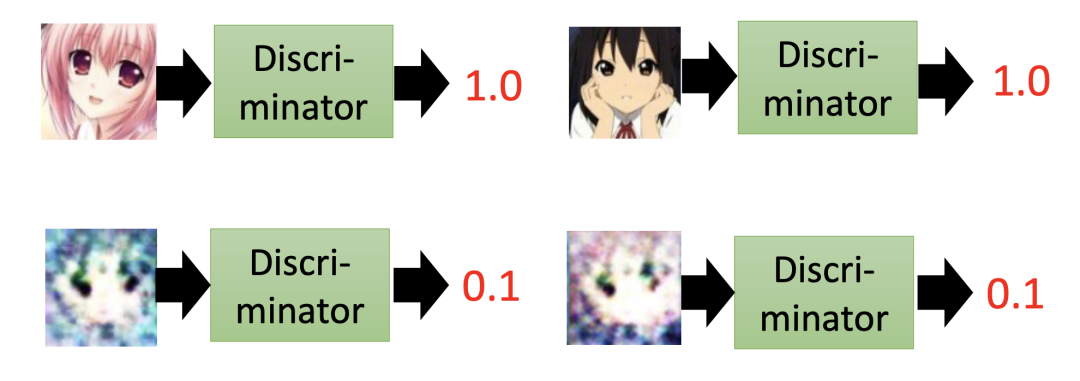
我们可以看到,输入图像越逼真生动,输出数值越大。反之,输出数值越小。
对抗关系
GAN 主要包括了生成器和判别器两个部分,那它们是如何协同工作的呢?
生成器主要用来学习真实图像分布从而让自身生成的图像更加真实,从而骗过判别器。判别器则需要对接收的图片进行真假判别。
在整个“对抗”过程中,生成器努力地让生成的图像更加真实,而判别器则努力地去识别出图像的真假,整个过程都伴随着两者博弈。随着时间的推移,生成器和判别器在不断地进行抗中,最终达到了一个动态均衡:生成器生成的图像接近于真实图像分布,而判别器识别不出真假图像(即对于给定图像的预测为真的概率基本接近 0.5,这就相当于随机猜测类别)。
GAN 的概念,比较像是久远历史中的生物进化。比如,生成器就像是蝴蝶的演化,而判别器更像是蝴蝶的天敌——鸟类的进化 :
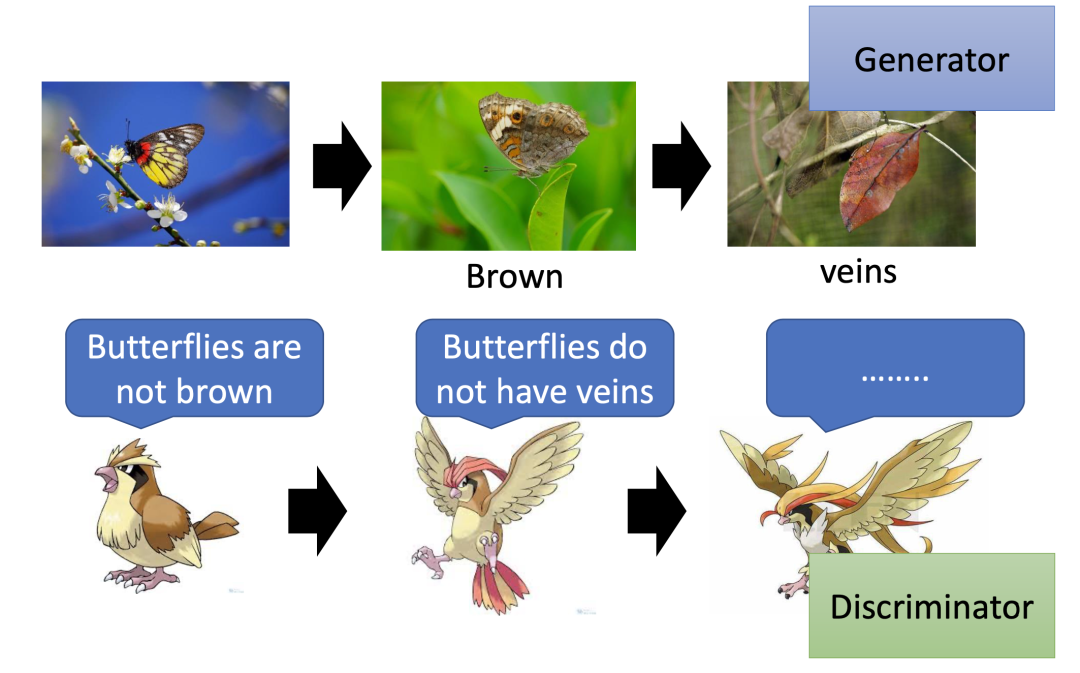
一开始,鸟类认为蝴蝶一定是彩色,因而灰色的蝴蝶得以幸存。后来,鸟类发现蝴蝶也有灰色的,同时认定蝴蝶一定没有树叶的脉络,这就逼得蝴蝶进化出了“枯叶蝶”。类似的相互对抗经历不断上演,最终蝴蝶和鸟类实现了共同进化。
样例三:利用 GAN 生成动漫头像
我们现在需要利用计算机生成动漫人物头像,首先我们要准备一个动漫人物头像数据库。
GAN 的生成器网络和判别网络的初始参数是随机的。生成网络一开始并不知道如何产生动漫头像,于是它只能随便生成一些看起来奇怪的东西。
在判别器训练的每一轮迭代中,GAN 会固定生成器 G 的参数,并根据真实图片(标记为 1)和生成器产生的图片(标记为 0)对比,调整判别器 D 里的参数。
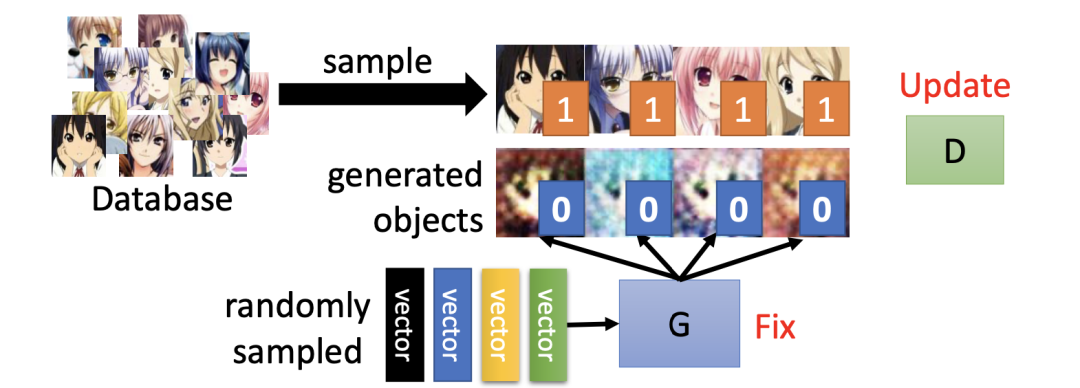
在生成器训练的每一轮迭代中,GAN 会固定判别器 D 的参数,并调整生成器 G 的参数,进而得到新一代的生成器,使新一代生成器生成的图片能够骗过上一代的判别器(即使得判别器的输出为 1)。
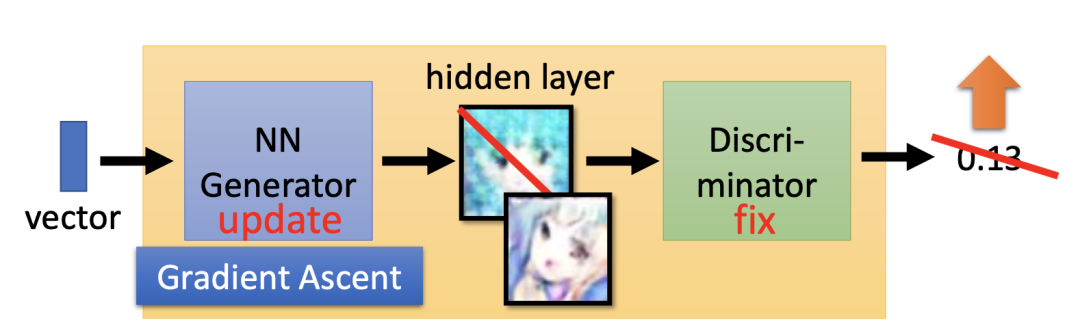
完整的训练过程如下图所示, 我们可以将 V1 生成器和 V1 判别器组合成一个大网络。在固定 V1 判别器的网络参数的同时,利用梯度下降法调整生成器模型参数,使判别器的输出为 1,于是我们就得到了 V2 生成器。
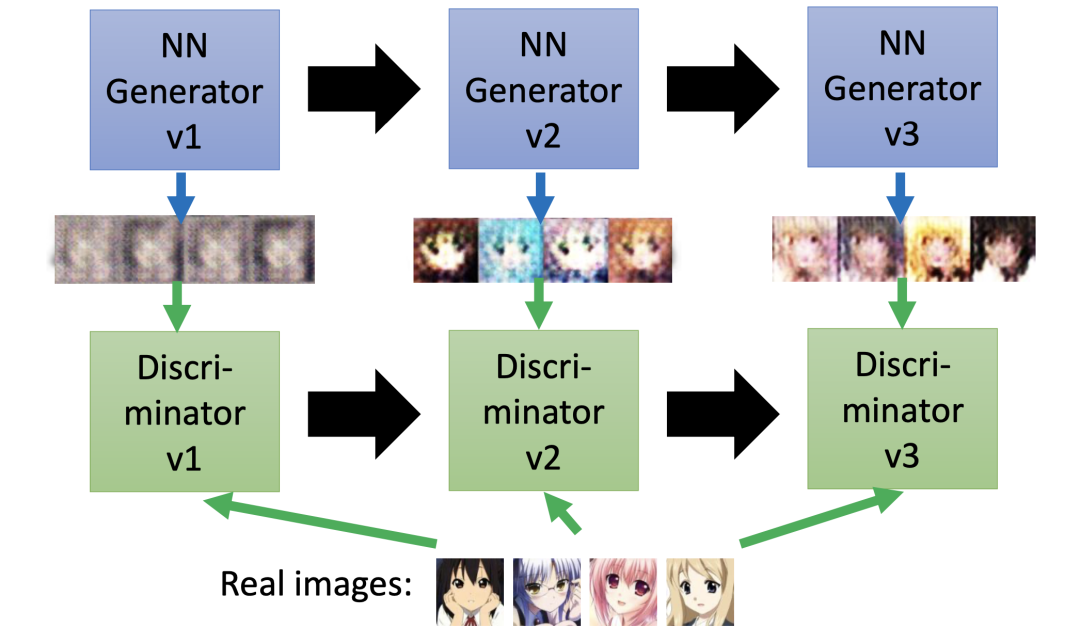
下图给出了不同训练次数生成器生成的效果图,我们可以发现迭代次数越多,生成的图片越逼近真实的动漫图片:




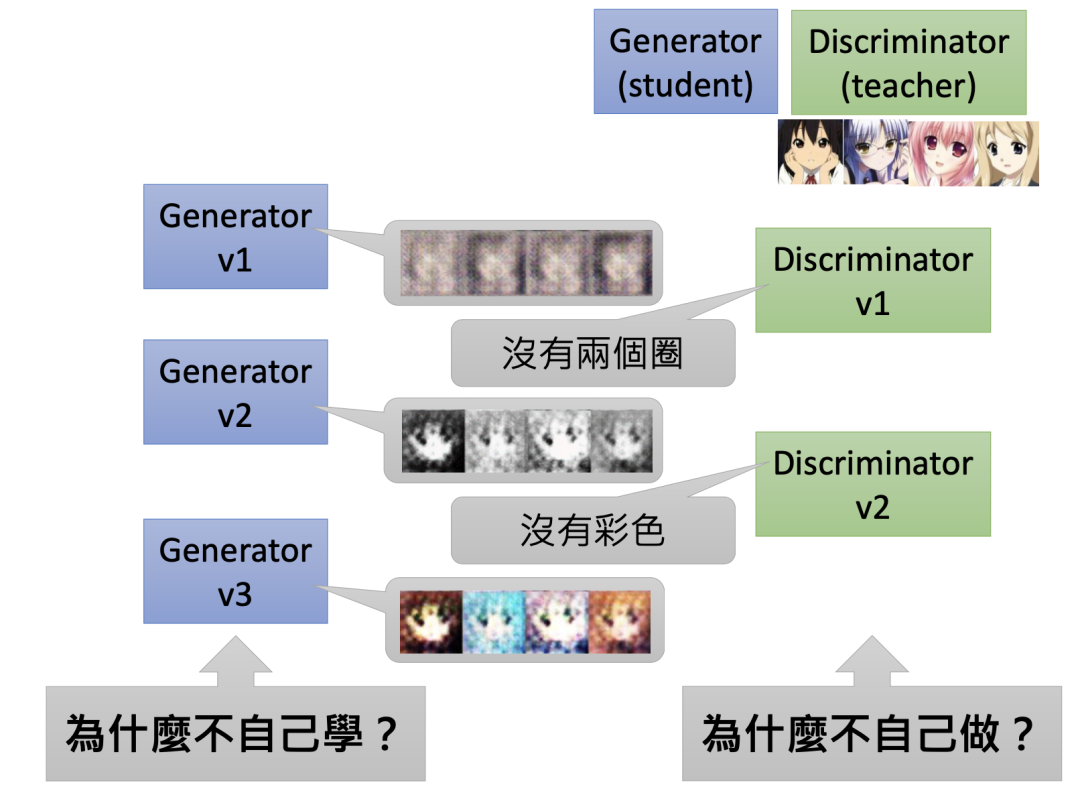
最后,我们抛出前言中说过的灵魂问题,试试看你能否回答?
02
MORE ABOUT GENERATOR
在上一部分我们知道了生成器可以将一个向量转换成一个图像,对于输入不同的向量得到不同的图片。
在传统的监督学习中,我们只需要给神经网络准备好输入输出对,再一直训练下去就能得到不错的结果。
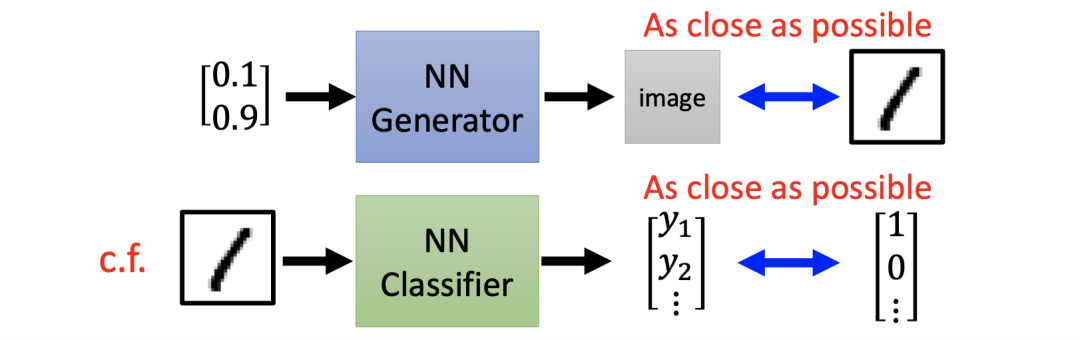
比如,我们有一系列的图片,只需要给定一系列输入然后反复训练使神经网络的输出和标签(Label)越接近越好。但这对于 GAN 来说会有很大的问题。比如下图中的两个 1,当输出图片的内容相类似(都是 1)的时候,由于输入编码是随机的,其输入向量数值上的很差别会很大,以至于很难训练出一个可用的网络。
自动编码器
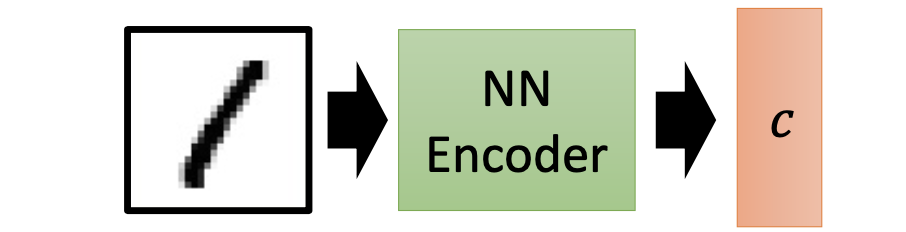
于是我们想要避免这种完全随机的输入向量,取而代之的是使用一个与实际数据相关的输入向量。为此,我们可以训练一个编码器(Encoder),即输入一张图片能够输出一个相应的向量。
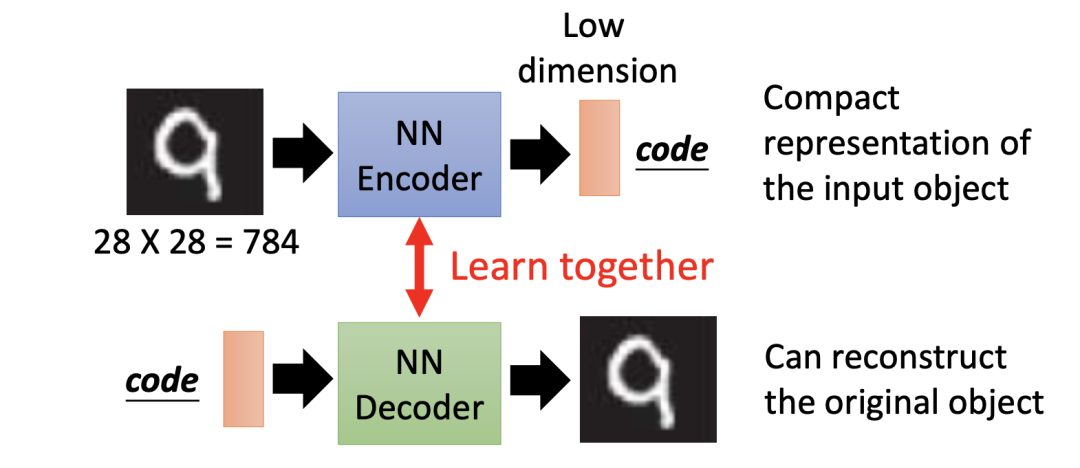
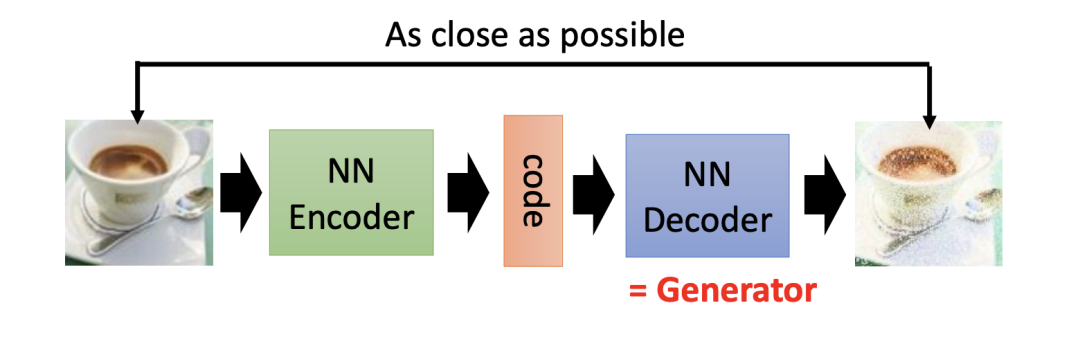
为了确保编码器的输出可靠,我们还要使其输出编码通过一个译码器(Decoder)后得到一张输出图片。通过对比译码器的输出图片和原始图片,反复调整编码器神经网络的参数。在这一过程中,编码器和译码器同步学习,我们将整个结构称为自动编码器(Auto-Decoder)。
更直观地,我们可以将编码器和译码器组合在一起得到下图结构:
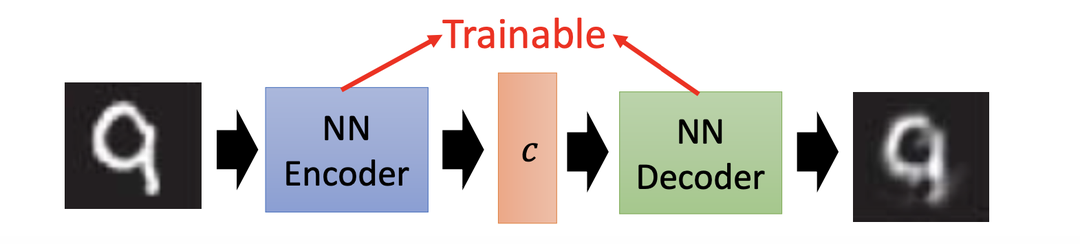
通过反复训练,我们就能得到一个完整的自动编码器。在自动编码器中,它的译码器部分其实就相当于一个生成器。
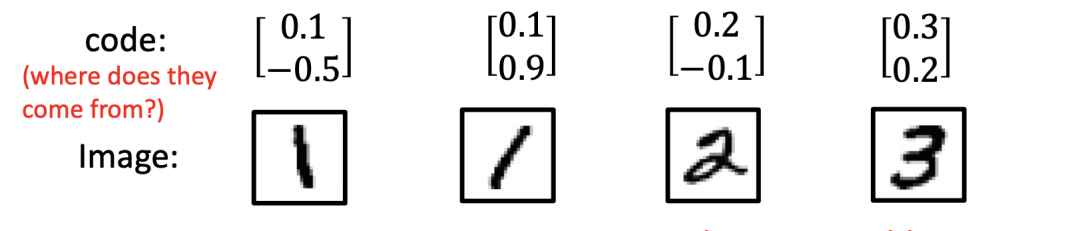
至此我们解决了输入编码问题,但我们将面临一个新的问题:训练数据集里面的图片数量是有限的,假设生成器在看到 a 的情况下会生成偏左的数字图片 1,而在看到 b 的情况下又会生成偏右的数字图片 1,那当输入 a 和 b 的平均值时,生成器会产生怎样的图片?
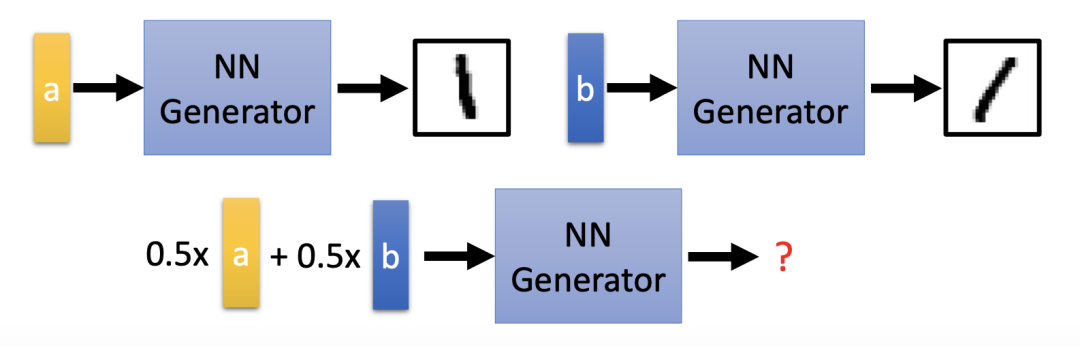
事实上,由于神经网络是非线性的,输入 a 和 b 的平均值并不一定能得到正向垂直的 1,相反它的输出还可能是噪声。
变分自动编码器
为了解决上述问题,我们改进自动编码器得到变分自动编码器(Variational Auto-Encoder,VAE)。VAE 在输出一个编码(m1, m2, m3)的同时还会产生每一个维度的方差(𝜎1, 𝜎2, 𝜎3),然后再将方差和正态分布中抽取的噪声进行相乘,最后与输出的编码叠加得到(c1, c2, c3),这就相当于加上噪声的编码。我们将(c1, c2, c3)送入译码器中就可以得到输出图片。
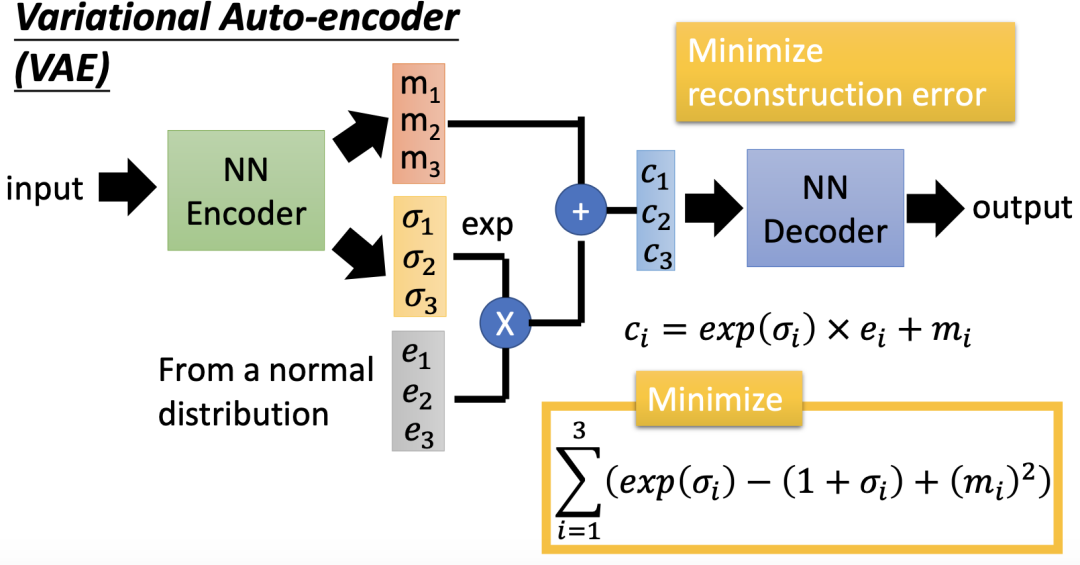
在 VAE 中,译码器不只是看到 a 或 b 时才会产生数字图像,当看到 a 或 b 叠加上一些噪声也会产生数字图像,这就使得译码器部分变得更加鲁邦。
样例四:生成器的局限
我们在生成器训练的时候,往往希望生成器最终生成的图片和我们给定的图片在像素级别上越像越好。但实际上,生成器的输出图片是肯定会产生一些错误。我们以生成数字图片 2 为例:
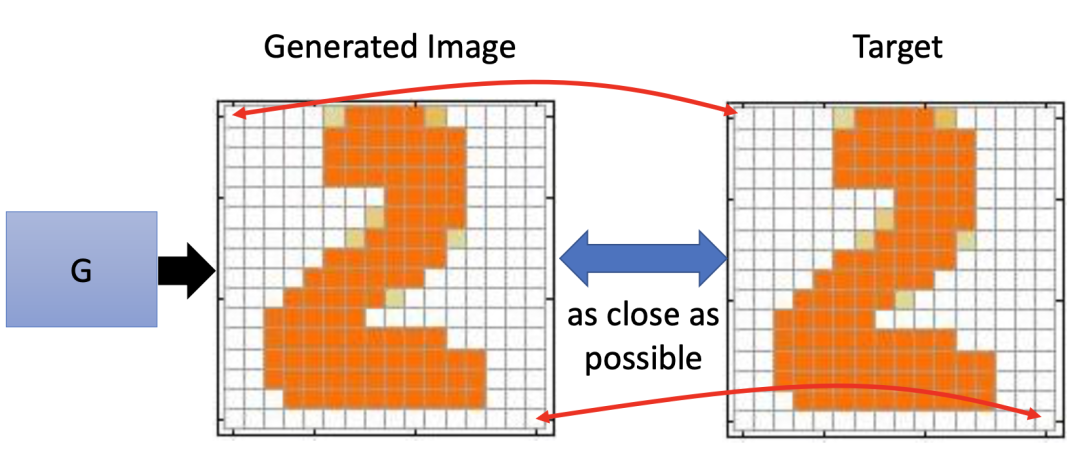
对计算机来说,下图中上面的两个图片误差比较小,下面两张图片的误差比较大。但是对于人眼来说,下面的两张图片只是相当于笔画的延长而已,其效果反而相较上方的两张图更好。

那么既然一个点多出来不好,我们能否把它周围的空白补全呢?
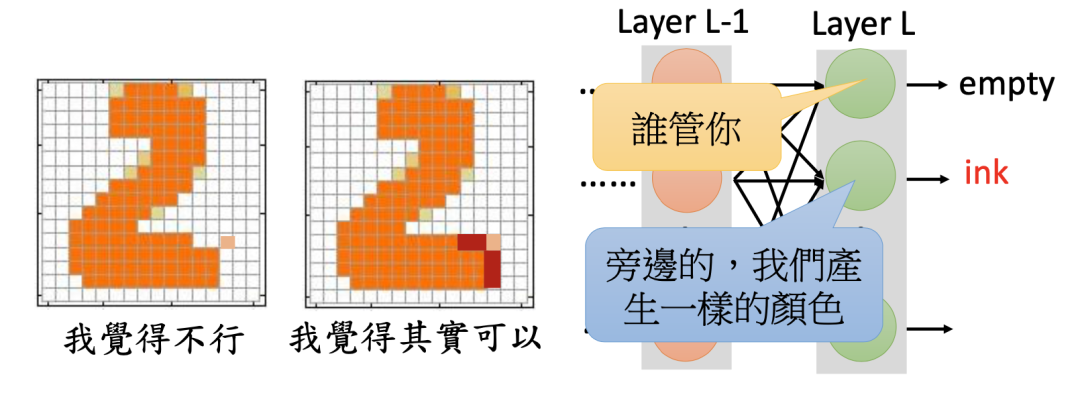
很遗憾,我们做不到!因为在译码器网络中,每一个输出就是图像中每一个像素的值,而各个输出是独立的,无法相互影响。
解决这个问题的办法就是使用更深层的神经网络。比如,添加更多的隐藏层(Hiden Layer)去捕捉这种关联。但是相比于 GAN,想要达到与之相似的效果,单纯使用自动编码器去做生成器往往会需要更大的网络。
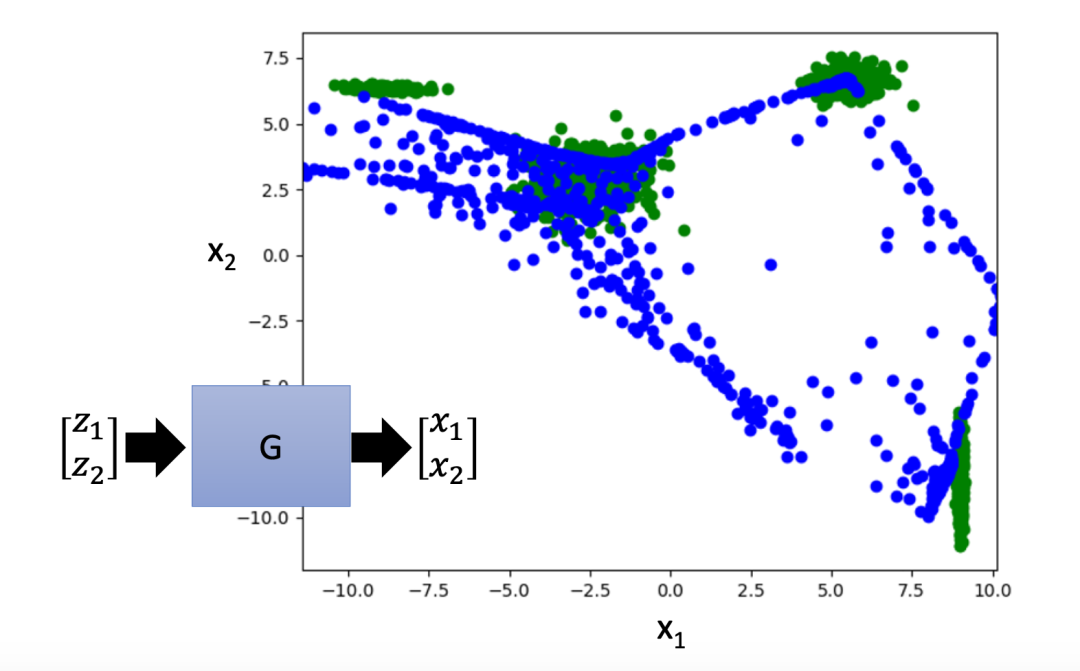
在实际测试中,(变分)自动编码器的生成效果并不算好。以下图为例,绿色部分为真实点,蓝色部分为生成点,由此可见生成点的分布与真实点的分布仍有较大差距:
03
MORE ABOUT DISCRIMINATOR
对于生成器而言,想要去判别不同像素之间的关联关系非常困难。而对与判别器来说,判断一张图片好坏却非常容易。因此,训练时我们会把输出好的图片丢给判别器,并让其评价输入的坏。
事实上,判别器也能够生成图片,但这一过程非常麻烦。假如说,我门已经有了一个判别器,它能够鉴别一个图片的好坏。我们要做的是穷举所有的输入 x,看看判别器给它的分数,并从中找到得分最大的图,这张图就是判别器的生成。

我们可以从数据集中获取到相当多的正样例,但这对于判别器的训练来说还不够,我们需要找到一定数量的负样例。
当然,我们可以直接利用噪声得到负样例,但这时会出现一些“乍一看很逼真但细节上很荒唐的图片”得分很高的怪异现象。比如,动漫头像主人公的两只眼睛颜色不一样,但判别器仍然判其获得高分。

为此,我们需要“好”的负样本去训练出一个判别器,但吊诡的是,我们又需要一个好的判别器才能找出好的负样本(这句话看不懂对吧,此处省略内心一万字……)。

样例五:利用判别器生成图片
首先我们从数据集中获取足够多的正样例:

随机生成一些负样例:

在每一轮迭代过程中,不断更新参数,使得判别器能够区分开正负样例,即给正样例高分,给负样例低分:

在上一步学出一个判别器后,我们需要用判别器去做生成一堆它判定为高分的图片,再将这些图片作为负样本重复整个迭代过程。
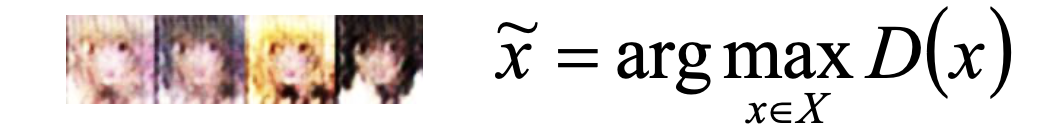
我们还可以从概率分布角度来认识判别器寻找负样例的训练过程:
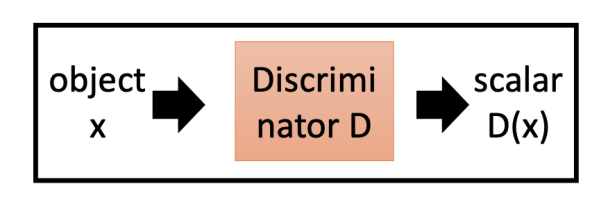
对于不同的输入对象 x,它的分布不同,判别器给出的得分也不同。判别器会判定真实样例(Real Example)高分,而给其它区域低分。
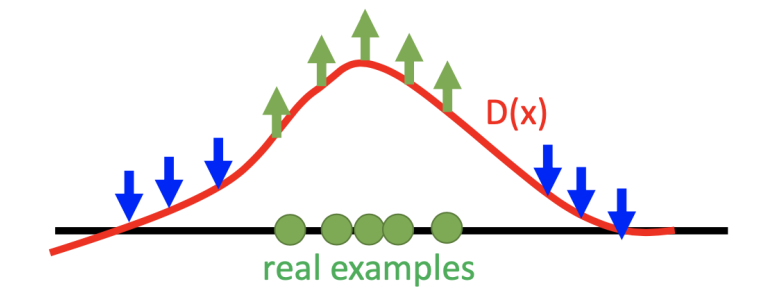
样例六:判别器迭代过程
我们可以更加详细的分析判别器 D(x) 的迭代训练过程,下图用蓝色曲线代表判别器生成图片的分布,用绿色曲线代表真实图片分布。
我们需要做的是让判别器给绿色的点高分,而给蓝色的点低分(如果只训练一次的话,可能有些地方的评数比真实样例对应的评数还高)。
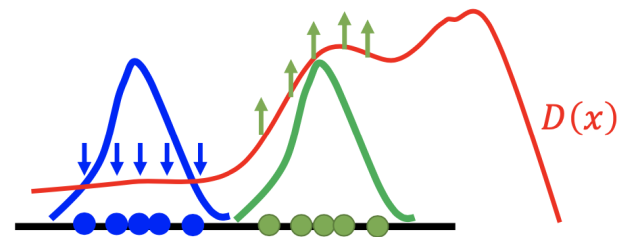
下一步,我们再去寻找出判别器的弱点,即找到那些让非真实样例区域得分最大(如上图右边区域)的样例,并把它们作为负样例。
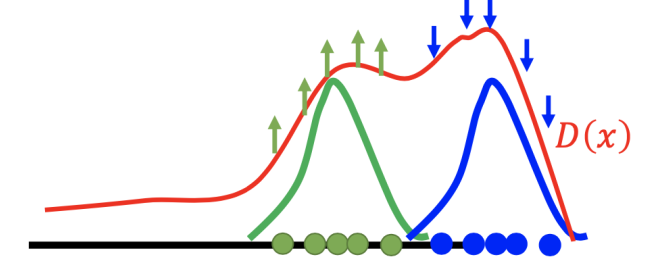
然后,我们训练判别器使其能够将上一步得到的负样例判定低分。
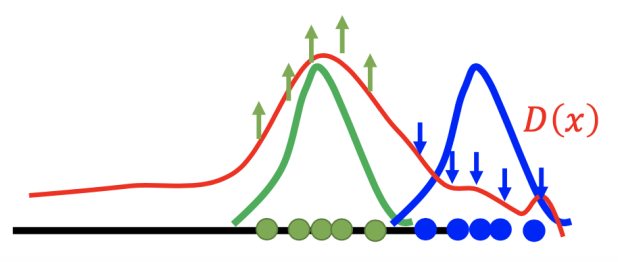
经过反复迭代,最终正样本和负样本就会重合在一起。但生成器最终只会生成完全真实的图片,以至于判别器无法判断输入图片的好坏(类似于过拟合)。
04
CONCLUSION
我们可以将 GAN 的生成器和判别器做一个对比:
类别 | 生成器 | 判别器 |
优点 | 很容易生成图片 | 可以考虑大局,即利用组件之间的关系 |
缺点 | 仅模仿表象 | 很难生成图片(因为需要求解一个 arg max 问题) |
没学到组件(像素点)之间的关联关系,即没有全局观 | 获取负样例不易 |

为什么求解一个 arg max 问题如此困难,以至于判别器很难生成图片呢?
因为想要求解 arg max 问题,我们就需要假设判别器模型是线性的,但“线性假设”又会限制判别器模型解决非线性问题,使其处理能力大打折扣。

再看判别器
在 GAN 中为了避免 arg max 求解问题,我们对于样例六的最后一步进行如下替换:
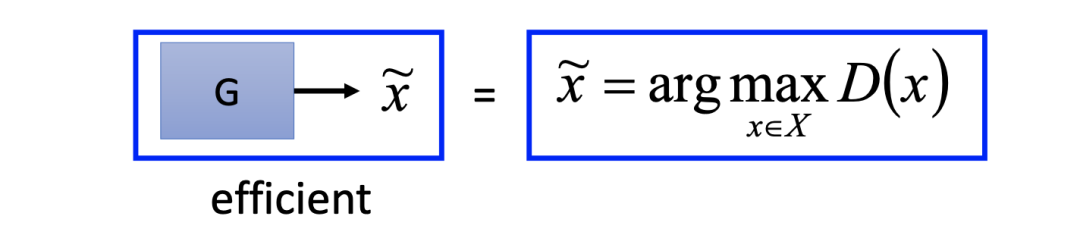
从上图我们可以看出,GAN 就是利用生成器取代判别器 arg max 函数的处理过程。在 GAN 中,生成器可以在训练后能生成一些使得判别器给出高分的图片。于是我们可以利用生成器去获得“好”的负样本来替代 arg max D(x) 过程,从而提高整个网络的训练效率。
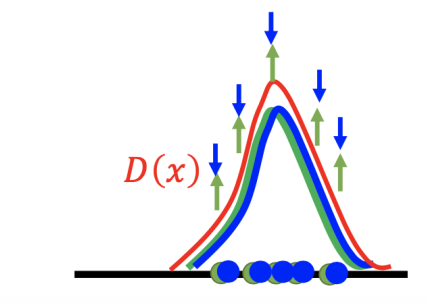
再看生成器
GAN 的生成效果也要比自动编码器好得多。如下图所示,蓝色部分代表真实点,红色部分代表生成点:
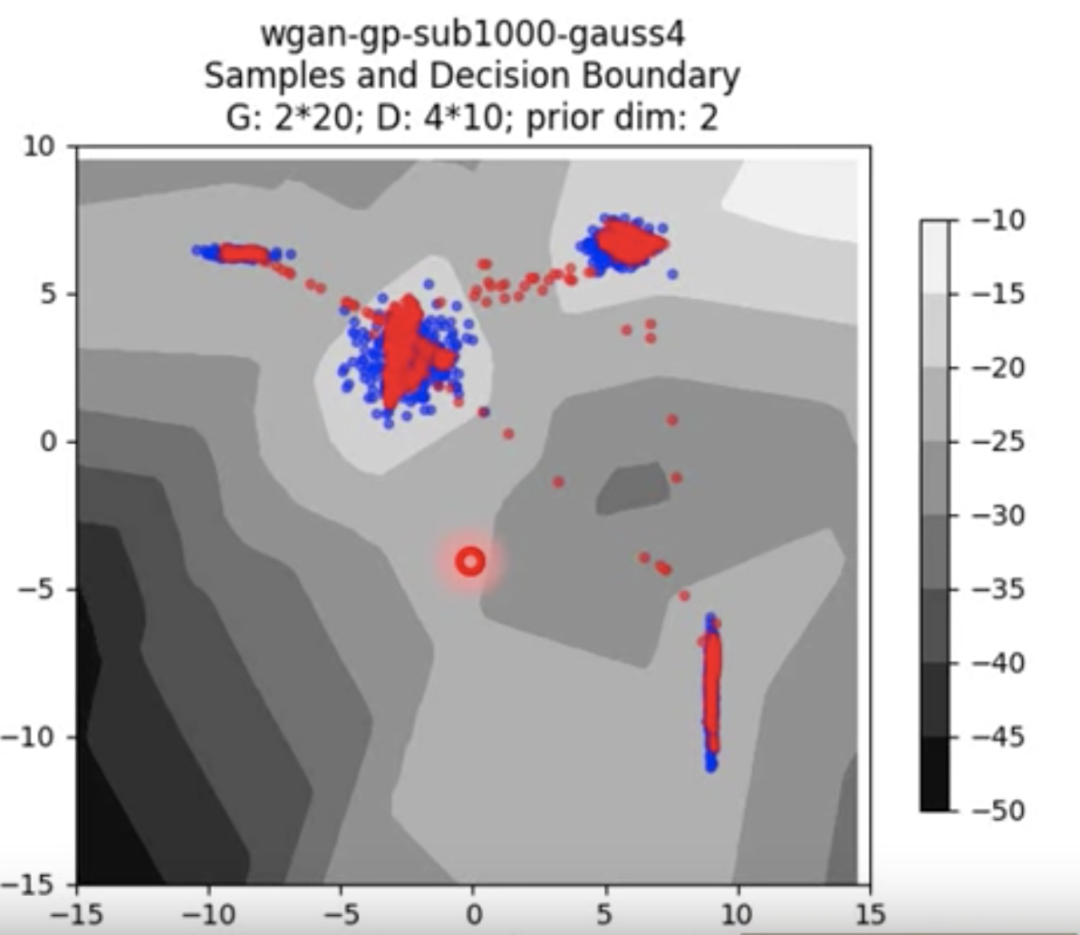
总结一下
通过使用 GAN 组合判别器和生成器, 之前困扰我们的很多问题就能引刃而解:
从判别器角度:过去不知道如何求解 arg max 函数的过程,现在直接由生成器来取代。
从生成器角度:虽然在生成图片过程中各像素之间依然没有联系,但是它的图片好坏可以由拥有大局观的判别器来负责,从而使得最终生成的图片能够“以大局为重”。
05
ONE MORE THING
Lan 在 2014 年提出了朴素 GAN ,它在生成器和判别器在结构上是通过以多层全连接网络为主体的多层感知机(Multi-Layer Perceptron, MLP)实现。然而它的调参难度较大,训练失败相当常见,生成图片质量也相当不佳,尤其是对较复杂的数据集而言。
由于卷积神经网络(Convolutional Neural Network,,CNN)比MLP有更强的拟合与表达能力,并在判别式模型中取得了很大的成果,Alec 等人将 CNN 引入生成器和判别器,得到深度卷积对抗神经网络深度卷积生成对抗网络(Deep Convolutional Generative Adversarial Network,DCGAN)。
网络设计
在 DCGAN 中,判别网络是一个传统的深度卷积网络,几乎完全用卷积层取代了全连接层。但它使用了带步长的卷积来实现下采样操作,不用最大汇聚(Pooling)操作。DCGAN 采用批标准化(Batch Normalization,BN)等技术,将判别模型的发展成果引入到了生成模型中。此外,它还并强调了隐藏层分析和可视化计数对 GAN 训练的重要性和指导作用。
样例:深度卷积生成对抗网络
生成网络使用一个特殊的深度卷积网络来实现。如下所示,使用微步卷积来生成 64 × 64 大小的图像。第一 层是全连接层,输入是从均匀分布中随机采样的 100 维向量 𝒛,输出是 4 × 4 × 1024的向量,重塑为 4 × 4 × 1024 的张量。然后是四层的微步卷积,没有汇聚层。
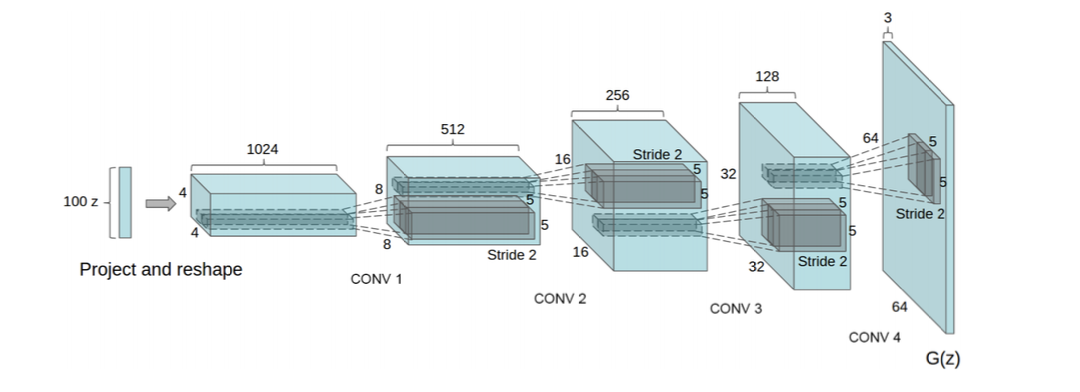
DCGAN 的主要优点是通过一些经验性的网络结构设计使得对抗训练更加稳定,比如:
使用带步长的卷积(在判别网络中)和微步卷积(在生成网络中)代替汇聚操作以免损失信息。
使用批量归一化。
去除卷积层之后的 全连接层。
在生成网络中,除了最后一层使用 Tanh 激活函数外,其余层都使用 ReLU 函数。
在判别网络中,都使用 LeakyReLU 激活函数。
发展状况
DCGAN 虽然没有带来理论上以及 GAN 上的解释性,但是其强大的图片生成效果吸引了更多的研究者关注 GAN。他们证明了其可行性并提供了经验,又给后来的研究者提供了神经网络结构的参考。此外,DCGAN 的网络结构也可以作为基础架构,用以评价不同目标函数 GAN,让不同的 GAN 得以进行优劣比较。DCGAN 的出现极大增强 GAN 的数据生成质量。而如何提高生成数据的质量(如生成图片的质量)也是如今 GAN 研究的热门话题。
至此,本文带领大家初步认识生成对抗网络,后续推文笔者将带大家了解如何训练生成对抗网络。另外本文太长,写完大伤元气都要吐血了……欢迎大家转发、打赏!感谢大家的支持,我们下期再见!
应用之道
END
存乎一心

本文作者:Bingunner
一位头发浓郁的信息安全工程师
爱摄影/爱数码/爱跑步的经济学人死忠粉
