




本文整理磐维租户在使用磐维数据库时10个应用开发案例,供大家参考借鉴。
1.磐维数据库对硬件的最低要求
租户想使用虚拟机搭建单机版测试环境,PanWeiDB 2.0对cpu和内存有最低限制是多大呢。
单机版测试环境1核cpu、2G内存可进行功能测试,同时参考如下几个配置参数:
max_connections=10 max_pred_locks_per_transaction = 10 max_process_memory = 2948MB shared_buffers = 128MB cstore_buffers = 16MB
否则启动数据库时可能提示如下错误:
FATAL: the values of memory out of limit, the database failed to be started, max_process_memory (2048MB) must greater than 2GB + cstore_buffers(64MB) + (udf_memory_limit(200MB) - UDF_DEFAULT_MEMORY(200MB)) + shared_buffers(276MB) + preserved memory(2150MB) = 4538MB, reduce the value of shared_buffers, max_pred_locks_per_transaction, max_connection, wal_buffers..etc will help reduce the size of preserved memory
2.数据类型转换
PanWeiDB 1.0对数据类型检查比较严格,例如下面两基表的字段类型不一样
create table t1(d int,b int,c int,a int);
create table t2(f varchar,k varchar,j varchar,n varchar);
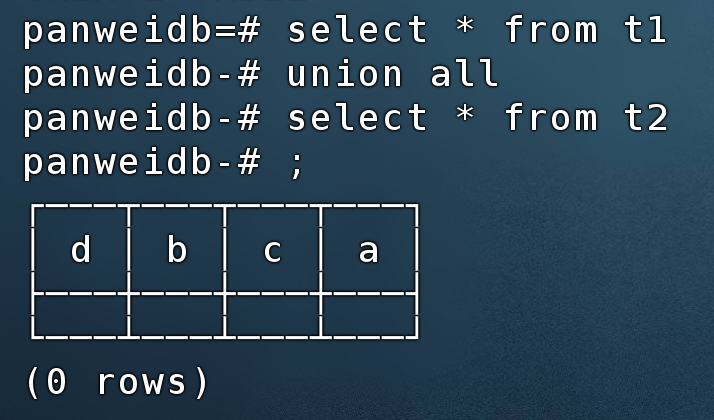
在PanWeiDB 1.0进行union all查询时会报错:
select * from t1
union all
select * from t2
;
错误信息为
ERROR: UNION types integer and character varying cannot be matched
在PanWeiDB 2.0进行union all查询时类型会自动转换匹配,测试截图如下:
3.视图依赖的表结构修改
在PanWeiDB 1.0里,如果表有依赖的视图,则不能直接修改表结构。
示例如下:
create table tab1(id int,info varchar(10));
create view v_tab1 as select id,info from tab1 where id>100;
在PanWeiDB 1.0直接变更表结构会提示如下报错:
ERROR: cannot alter type of a column used by a view or rule
此时可以参考stackoverflow上的处理方式,创建两个函数进行操作。
在PanWeiDB 2.0里语句可以正常执行,测试截图如下:

4.MySQL兼容性下字段含枚举类型及空串
源端MySQL迁移如下表结构:
CREATE TABLE `tab1` (
`b` ENUM('','ANY','X509','SPECIFIED') NOT NULL DEFAULT ''
);
在PanWeiDB 1.0会遇到两个问题:第一个是不直接支持ENUM枚举类型,需要先使用如下语法创建枚举类型,再使用枚举类型
CREATE TYPE ... AS ENUM ...
第二个问题是枚举类型的值长度不能为0,不允许为空串。
PanWeiDB 2.0现已支持创建,测试截图如下:

5.MySQL兼容性下分区键含表达式
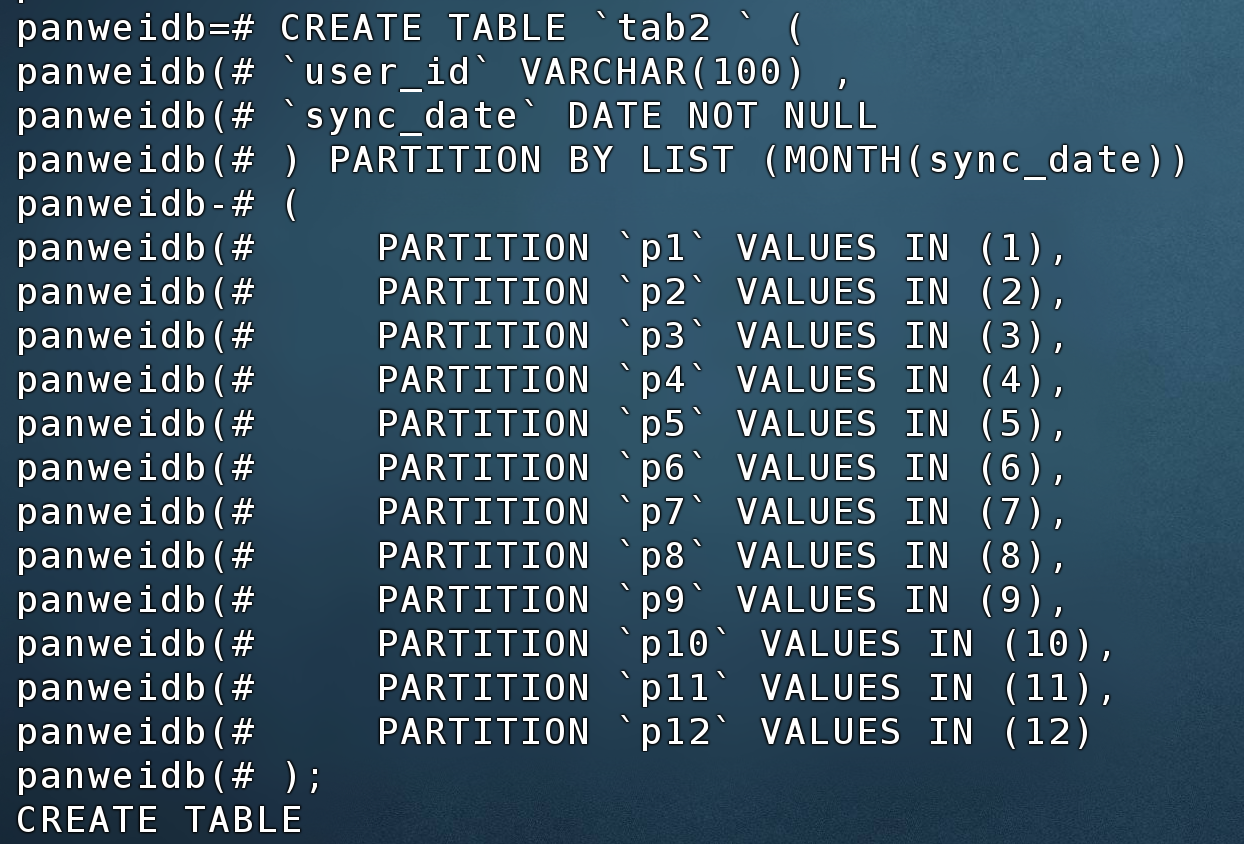
源端MySQL使用LIST分区,如果分区键如果使用了表达式,示例如下:
CREATE TABLE `tab2 ` (
`user_id` VARCHAR(100) ,
`sync_date` DATE NOT NULL
) PARTITION BY LIST (MONTH(sync_date))
(
PARTITION `p1` VALUES IN (1),
PARTITION `p2` VALUES IN (2),
PARTITION `p3` VALUES IN (3),
PARTITION `p4` VALUES IN (4),
PARTITION `p5` VALUES IN (5),
PARTITION `p6` VALUES IN (6),
PARTITION `p7` VALUES IN (7),
PARTITION `p8` VALUES IN (8),
PARTITION `p9` VALUES IN (9),
PARTITION `p10` VALUES IN (10),
PARTITION `p11` VALUES IN (11),
PARTITION `p12` VALUES IN (12)
);
迁移到PanWeiDB 1.0时会提示42601的错误代码,PanWeiDB 2.0现已支持创建,测试截图如下:
6.MySQL兼容性下复合KEY分区
PanWeiDB 1.0迁移MySQL复合KEY分区会提示如下错误:
MySQL-2008: MySQL Not Support SubPart Type KEY.
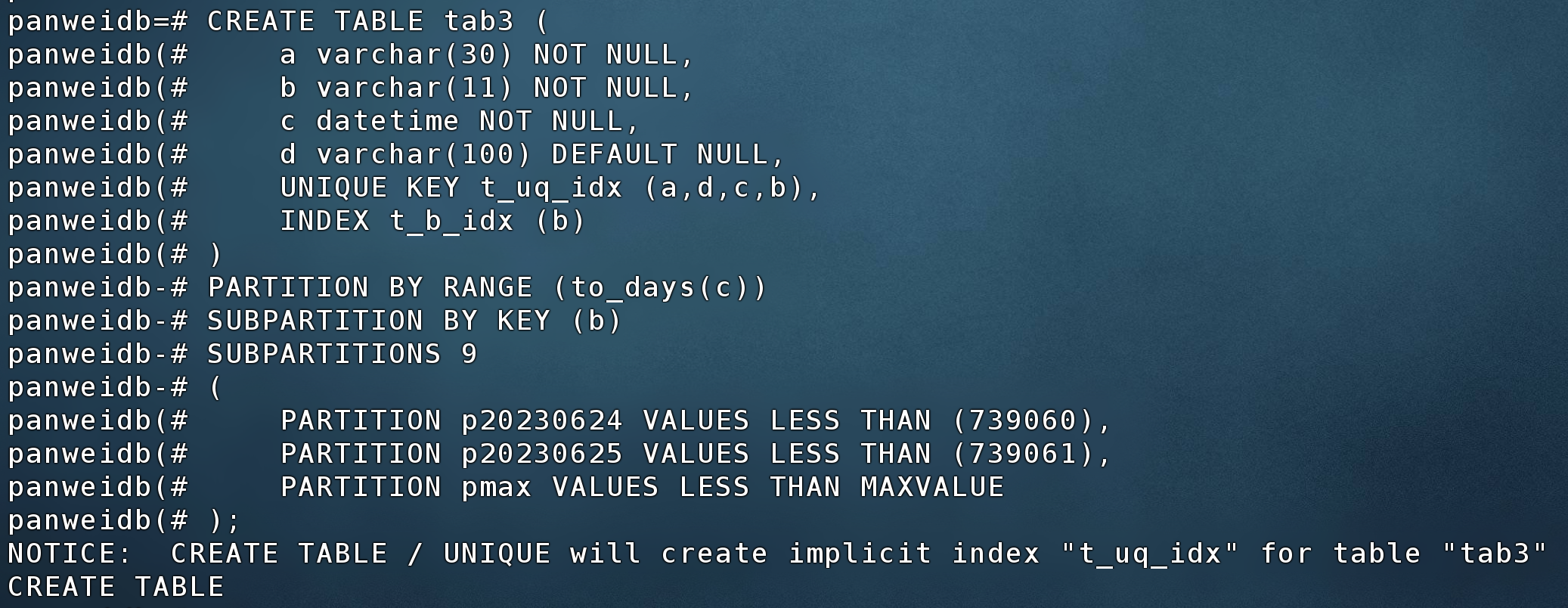
MySQL源端表结构如下:
CREATE TABLE tab3 (
a varchar(30) NOT NULL,
b varchar(11) NOT NULL,
c datetime NOT NULL,
d varchar(100) DEFAULT NULL,
UNIQUE KEY t_uq_idx (a,d,c,b),
INDEX t_b_idx (b)
)
PARTITION BY RANGE (to_days(c))
SUBPARTITION BY KEY (b)
SUBPARTITIONS 9
(
PARTITION p20230624 VALUES LESS THAN (739060),
PARTITION p20230625 VALUES LESS THAN (739061),
PARTITION pmax VALUES LESS THAN MAXVALUE
);
建表语句使用复合分区(range分区与key分区组合)语法SUBPARTITION BY KEY在PanWeiDB 1.0不支持,PanWeiDB 2.0现已支持创建,测试截图如下:
7.MySQL兼容性下字段含zerofill和auto_increment属性
源端MySQL迁移如下表结构:
CREATE TABLE `tab4` (
`id` INT(4) ZEROFILL AUTO_INCREMENT PRIMARY KEY
);
字段包含zerofill属性,用于填充前导零,可确保数字字段具有相同的位数,方便排序和比较。同时包含auto_increment属性,自增值。
迁移到PanWeiDB 1.0会提示语法不支持,PanWeiDB 2.0现已支持创建,测试截图如下:

8.MySQL兼容性下aes加解密
源端MySQL迁移到磐维后,业务原先使用aes_encrypt和aes_decrypt函数进行字段加解密,表结构及使用示例如下:
create table `tab_aes_encrypt`(
`id` bigint not null auto_increment,
`data` varbinary(100),
primary key(`id`)
);
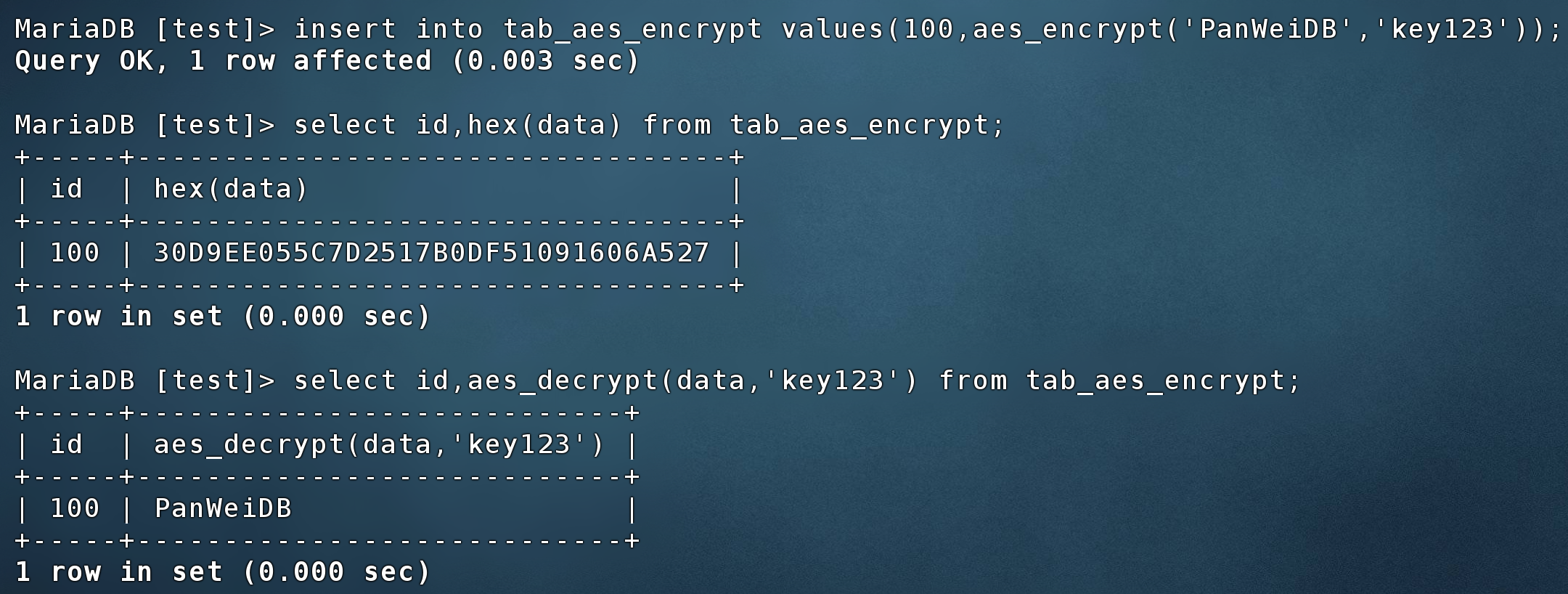
数据插入时使用aes_encrypt函数进行加密,数据查询时使用aes_decrypt函数进行解密
insert into tab_aes_encrypt values(100,aes_encrypt('PanWeiDB','key123'));
select id,aes_decrypt(data,'key123') from tab_aes_encrypt;
源端模拟测试截图如下:
迁移到PanWeiDB 2.0,在MySQL兼容性模式下可以使用my_encrypt_aes128和my_decrypt_aes128函数进行替换。
插入数据时,使用my_encrypt_aes128进行加密:
insert into tab_aes_encrypt values(100,my_encrypt_aes128('PanWeiDB','key123'));

数据查询时使用my_decrypt_aes128函数进行解密
select id,my_decrypt_aes128(data,'key123') from tab_aes_encrypt;

注意使用my_encrypt_aes128和my_decrypt_aes128函数时需要先创建pgcrypto扩展:
create extension pgcrypto ;
否则直接使用会提示如下错误信息
ERROR: extension pgcrypto not found CONTEXT: referenced column: my_decrypt_aes128
9.MySQL兼容性下别名使用大写
PanWeiDB 2.0在MySQL兼容性下可以设置lower_case_table_names来控制对象名大小写是否敏感:
lower_case_table_names = 1
lower_case_table_names设置值为1后,SQL语句里表别名需要使用小写,不能使用大写,否则会报错:

10.PG兼容性下upsert语法与autoGeneratedKeys参数
PanWeiDB 2.0里upsert语法支持两种风格,Oracle语法风格参考如下:
insert into ... ON DUPLICATE KEY update columnN=excluded.columnN;
PG风格语法如下:
insert into ... ON CONFLICT(XXX) do update set columnN=excluded.columnN;
两种风格的upsert都可正常使用,不过在java代码里,upsert同时使用autoGeneratedKeys参数时需要使用兼容PG的风格,参考代码如下:
connection.prepareStatement("insert into tab1(id,name) values(?,?) ON CONFLICT(id) do update set name=excluded.name returning *", Statement.RETURN_GENERATED_KEYS);
如果使用Oracle语法风格则会报错:
connection.prepareStatement("insert into tab1(id,name) values(?,?) ON DUPLICATE KEY update name=excluded.name returning *", Statement.RETURN_GENERATED_KEYS);
报错如下:
ERROR: RETURNING clause is not yet supported within INSERT ON DUPLICATE KEY UPDATE statement.
