




Friends带有以下索引的表:
Friends ( user_id1 ,user_id2)
user_id1和user_id2是user表的外键。
这些是等价的吗?如果不是,那为什么?
Index(user_id1,user_id2) and Index(user_id2,user_id1)
这些不是等价的,一般来说 index(bar,baz) 对表单的查询效率不高 select * from foo where baz=?
这样的索引确实可以加快查询速度,但这种效果是有限的,并且通常期望索引改进查找的顺序不同 - 它依赖于这样一个事实,即索引的“完整扫描”通常是由于表中没有出现在索引中的额外列,因此比索引表的“完全扫描”更快。
试验台:
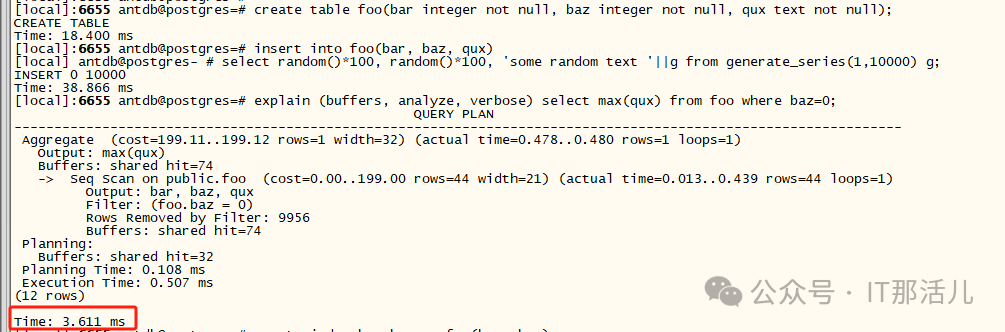
查询 1(无索引,达到74 个缓冲区):
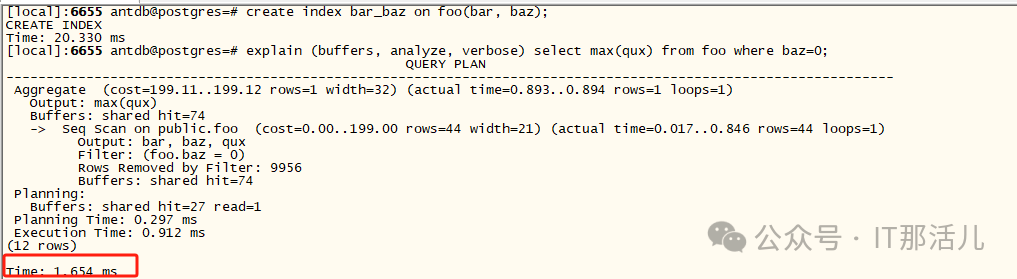
查询 2(使用索引 - 优化器忽略索引 -再次命中74 个缓冲区):
查询 3(使用索引 - 欺骗优化器使用它):
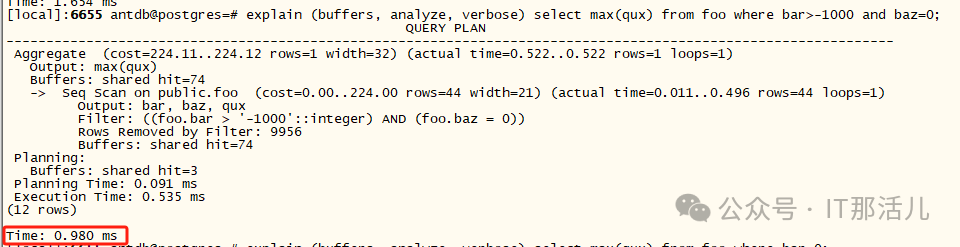
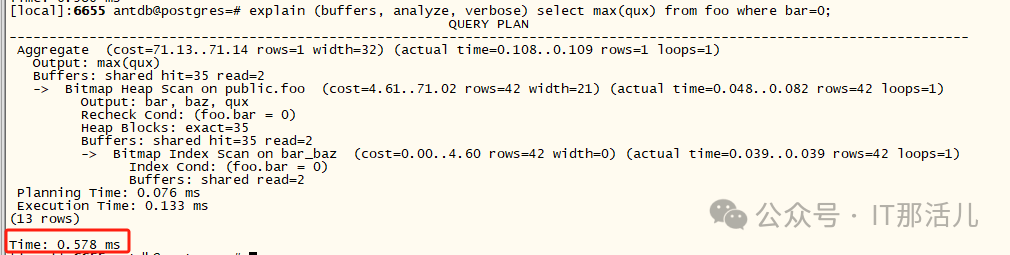
因此,在这种情况下,通过索引的访问速度是30 个缓冲区的两倍——就索引而言,“稍微快一点”!,YMMV 取决于表和索引的相对大小,以及过滤的行数和集群特征表中的数据,相比之下,前导列上的查询使用索引的 btree 结构 - 在这种情况下会命中2 个缓冲区:
结 论:
多列索引可用于非前导列上的查询,但对于选择性条件(结果中的行的百分比很小),加速仅约为 3 倍。较大的元组较高,结果集中表的较大部分较低。
如果性能很重要,则在这些列上创建一个额外的索引。
如果所有涉及的列都包含在索引(覆盖索引)中,并且所有涉及的行(每个块)对所有事务都是可见的,在 pg 9.2 或更高版本中获得“仅索引扫描”。
本文作者:胡祥开(上海新炬中北团队)
本文来源:“IT那活儿”公众号

文章转载自IT那活儿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
