




接上一篇使用笔记,针对几个特殊场景进一步分析原因,分布式数据库避免不了分布式事务;因为我们想使用分布式数据库的分布式能力,也势必会存在分布式事务事务,当然Oceanbase可以通过表组来避免分布式事务,但是实际应用场景上还是无法使用表组,比如表组不可以跨用户等等。
我最初做了一个如下测试:
TABLE_A:老系统个人客户信息表;TABLE_B:新系统个人客户信息表,主键都是客户编号cust_id,我们要做的就是把TABLE_A中的数据按照一定逻辑迁移到TABLE_B,数据量是8000多万行。占用磁盘30多个G,我们创建了表组,并且是按照cust_id做hash分区,分区数量是64。
不指定分区执行
insert into TABLE_B(column1,column2......column) select column1,column2......column from table_B;
没有分区的情况下执行这个sql语句用时40分钟左右,上面的sql语句执行计划是分布式执行计划。
指定分区串行执行
for i=0 to 63
insert into TABLE_B(column1,column2......column) select column1,column2......column
from table_B patittion(p[i]);
commit;
end
每一次执行都是本地执行计划,每个分区执行时间在60秒,如果顺序执行则是1个小时左右
多分区并行执行
insert into TABLE_B(column1,column2......column) select column1,column2......column
from table_B patittion(p0,p1,p2,p3);
insert into TABLE_B(column1,column2......column) select column1,column2......column
from table_B patittion(p4,p5,p6,p7);
这样处理仍然是分布式事务,因为涉及到多个分区。之间时间在40分钟左右。
应用控制多线程
当然还有一种是通过程序的多线程执行,通过应用端调用sql语句,每个sql语句执行1个分区,我认为这样是最优的,既保证了本地事务,但是这样就没有利用到数据库的分布式处理事务的能力,当然这种方式的开发成本也相对多一些,还需要开发应用程序。
分布式事务的问题
我从官网上摘取了传统的两阶段提交和OB的两阶段提交对比图,可见OB在参与者发出prepare ok 以后就返回提交了。
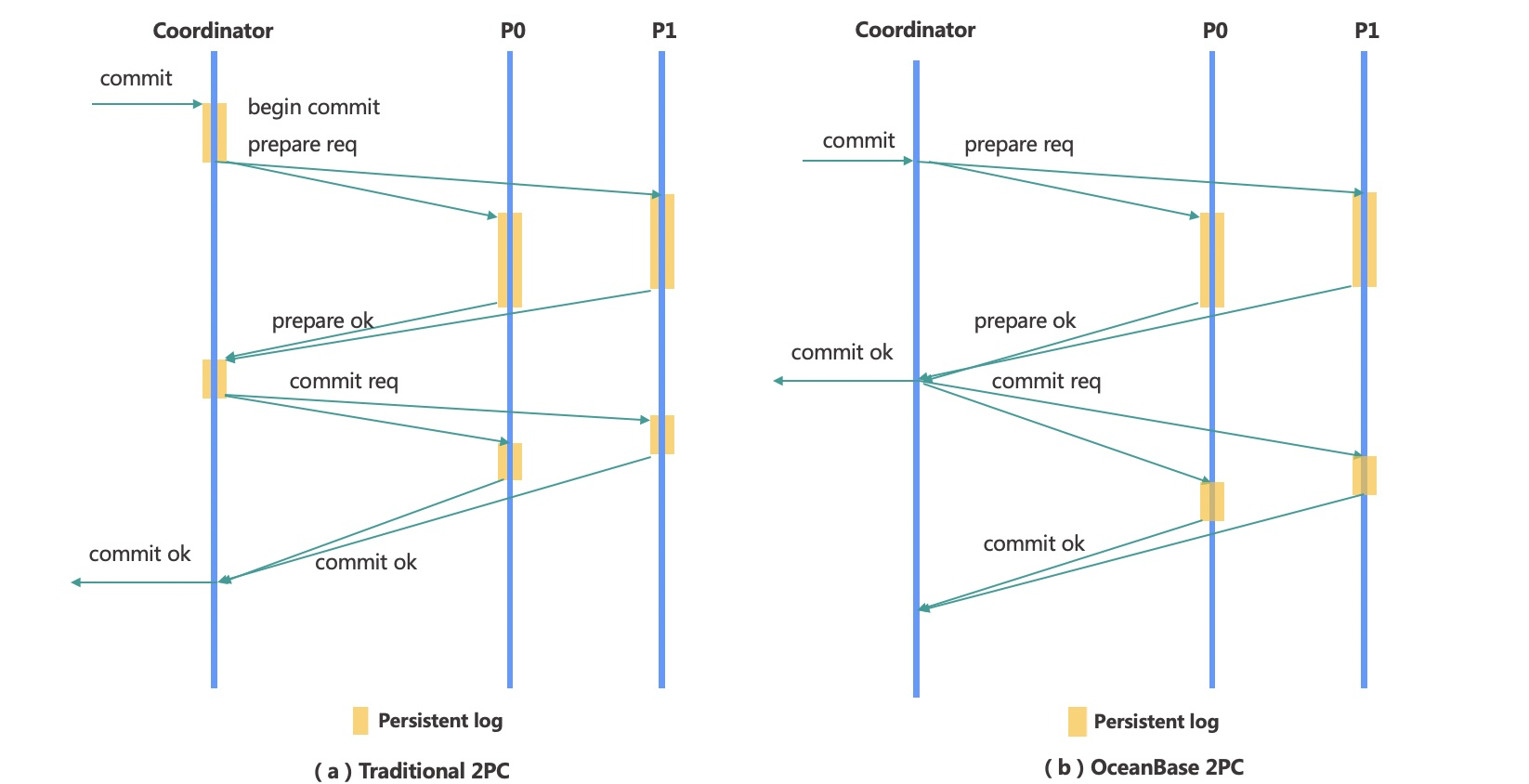
在使用过程中也遇到了一些问题,如果是分布式事务返回提交成功的时候,如果紧接着对这个表执行操作可能会出现错误,可以适当的增加一个dbms_lock.sleep(5)等待一会,我上面有个例子修改以后如下:
insert into TABLE_B(column1,column2......column) select column1,column2......column
from table_B patittion(p0,p1,p2,p3);
call dbms_lock.sleep(5);
insert into TABLE_B(column1,column2......column) select column1,column2......column
from table_B patittion(p4,p5,p6,p7);
call dbms_lock.sleep(5);
还有一些其他场景:比如:1、insert 大量数据以后紧接着进行obdumper;2、truncate 以后紧接着执行大量insert;
